OLAP ——Druid简介
目录
背景
特性
基本概念
设计原则
数据格式
数据摄入
数据查询
适用场景
背景
Druid是一个分布式的支持实时分析的数据存储系统。通俗点说:就是一个高性能实时分析数据库。2011年,由美国广告技术公司MetaMarkets创建,并于2012年开源。官网地址是:http://druid.io/。目前Druid已基于Apache License 2.0协议开源,正在由Apache孵化,代码托管于Github。最新官网地址为:https://druid.apache.org/
(注意:阿里曾开源过一个项目叫做Druid是一个数据库连接池。与这里讲的Driud仅仅是名字一样而已,并没有什么关联。)
特性
1.快速查询
内存化的数据存储提高了druid的查询速度,提供了快速的聚合能力以及快速OLAP查询能力,多租户的设计,是面向用户分析应用最理想的方式。druid的数据聚合粒度可以是1分钟,5分钟,1小时或者1天等。
2.实时数据注入
druid支持实时流式数据的注入,并提供了数据的事件驱动,保证在实时和离线环境下事件的时效性和统一性。典型的 Lambda 架构,不改变历史数据,实时接入实时数据。
3.可扩展的PB级存储
可扩展的分布式架构,druid集群可以很方便的扩容到PB的数据量,每秒百万级别的数据注入。即便在加大数据规模的情况下,也能保证其时效性。druid可以按照时间范围把聚合数据进行分区处理。
4.云原生架构,高容错性:
druid既可以运行在商业的硬件上,也可以运行在云上。它可以从多种数据系统中注入数据,包括hadoop,spark,kafka,storm和samza等。
基本概念
设计原则
1.快速查询(Fast Query) : 部分数据聚合(Partial Aggregate) + 内存化(In-Memory) + 索引(Index)
2.水平拓展能力(Horizontal Scalability):分布式数据(Distributed data)+并行化查询(Parallelizable Query)
3.实时分析(Realtime Analytics):Immutable Past , Append-Only Future
数据格式
druid在数据摄入之前,首先需要定义一个数据源也就是Datasource,这个dataSource的结构是 时间列(TimeStamp),维度列(Dimension)和指标列(Metric)。
时间列:druid会将时间相近的一些数据聚合在一起,查询的时候指定时间范围。
维度列:作为标识一些统计的维度,比如各种类型。
指标列:就是用于聚合和计算的列,包括count,sum等等。
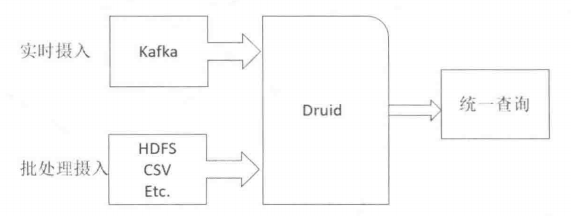
数据摄入
druid提供了两种数据摄入方式,实时和批处理。
数据查询
druid支持两种查询,原生和sql
适用场景
根据Druid的特性可知,druid适合的数据场景:
-
查询多修改很少
-
查询以聚合或分组为主
-
快速查询
-
需要支持离线和实时的数据源·
具体的业务场景:
-
用户行为分析
-
服务性能指标实时监测
-
数字营销
-
商业智能/ OLAP
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!