吴恩达 tensorflow2.0 实践系列课程(4):RNN
tensorflow2.0 序列、时间序列和预测
写在前面吧,比较有价值和实用的是根据指标选择超参数。
(1)loss 和 epoch 曲线放大有震荡,一般是由于 batchsize 较小。
(2)loss 和 epoch 曲线看起来没有“继续学习”,可以去除最开始的若干 epoch 再绘制。
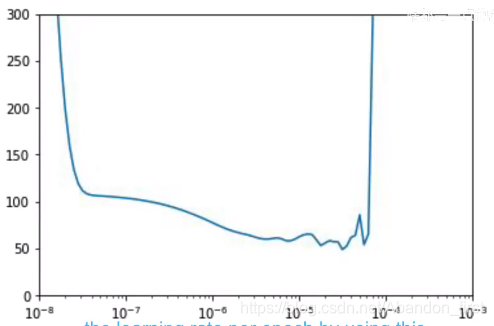
(3)比如,下面选择学习率的方式,选择 loss 较低 且 稳定的 lr。
lr_schedule = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-8 * 10 ** (epoch / 20))optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)model.compile(loss='mse', optimizer=optimizer)
history = model.fit(dataset, epochs=100, callbacks=[lr_schedule])lrs = 1e-8 * (10 ** (np.arange(100) / 20))
plt.semilogx(lrs, history.history["loss"])
plt.axis([1e-8, 1r-3, 0, 300])
0 Introduction
Learn how to builid sequence model and finally practice on sunspot activity data.
1.1 Time series examples
Examples:
- stock prices
- weather forecasts
- historical trends such as Moore’s law.
- the path of a moving car
本章主要集中在序列本身,以及考虑一些问题,比如如何划分训练验证和测试?
How to split time series data into training, validation and test sets.
1.2 Machine learning applied to time series
- 预测未来:forecast
- 推测过去或者补全中间数据:imputation
分析序列数据中的模式,比如使用 RNN 来进行语音识别,识别 words or subwords。

1.3 Common patterns in time series
接着上面的,讨论 patterns 的各种类型,举例可以有下面几种:
- 简单直线上升或下降的
- 周期的
- 上升 + 周期的
- 有随机尖峰然后迅速固定模式 decay 的
然后预测的时候考虑多少数据?我自己的理解是不要太少(说越多越好感觉也是有问题的……)。
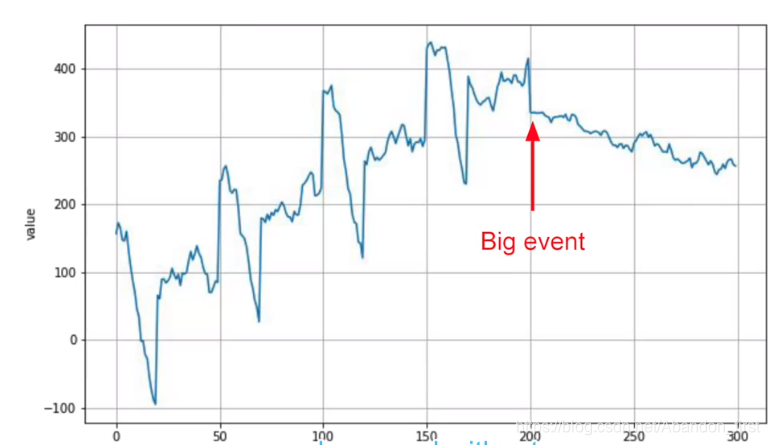
比如下图这个例子,自认为有点像心跳然后出现异常了,那后面会如何呢?
如果预测的时候只考虑 big event 之后的序列,那很大概率就预测类似直线下降的模式;如果考虑的是整个图中的,那么可能预测的是下降之后逐渐恢复“心跳”。
1.4 Introduction to time series
本小节就是自己生成一些序列数据。
import numpy as np
import matplotlib.pyplot as pltdef plot_series(time, series, format='-'):plt.figure(figsize=(10, 6))plt.plot(time, series, format)plt.xlabel('time')plt.ylabel('value')plt.grid(True)def trend(time, slope=0):return slope * timetime = np.arange(4 * 365 + 1)
baseline = 10
series = trend(time, 0.1)
plot_series(time, series)
plt.show()def seasonal_pattern(season_time):return np.where(season_time < 0.4, np.cos(season_time * 2 * np.pi), 1 / np.exp(3 * season_time))def seasonality(time, period, amplitude=1, phase=0):season_time = ((time + phase) % period) / periodreturn amplitude * seasonal_pattern(season_time)baseline = 10
amplitude = 40
series = seasonality(time, period=365, amplitude=amplitude)
plot_series(time, series)
plt.show()season
slope = 0.05
series = baseline + trend(time, slope) + seasonality(time, period=365, amplitude=amplitude)
plot_series(time, series)
plt.show()
season + trend
def noise(time, noise_level=1, seed=None):rnd = np.random.RandomState(seed)return rnd.randn(len(time)) * noise_levelnoise_level = 15
noisy_series = series + noise(time, noise_level, seed=42)
plot_series(time, noisy_series)
plt.show()season + trend + noise
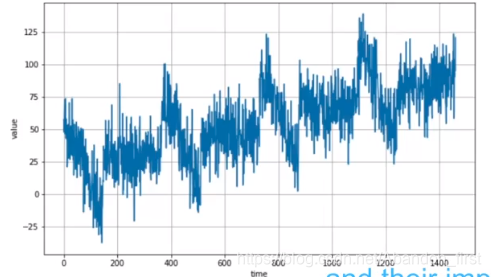
def antocorrelation(time, amplitude, seed=None):rnd = np.random.RandonState(seed)f1 = 0.5f2 = -0.1ar = rnd.randn(len(time) + 50)ar[:50] = 100for step in range(50, len(time) + 50):ar[step] += f1 * ar[step - 50]ar[step] += f2 * ar[step - 33]return ar[50: ] * amplitudedef autocorrelation(time, amplitude, seed=None):rnd = np.random.RandomState(seed)f = 0.8ar = rnd.randn(len(time) + 1)for step in range(1, len(time) + 1)ar[step] += f * ar[step - 1]return ar[1:] * amplitudeseries = autocorrelation(time, 10, seeed=42)
plot_series(time[:200], series[:200])
plt.show()correlation:序列的前后有关联;下面分别是两个 correlation 函数对应的图像
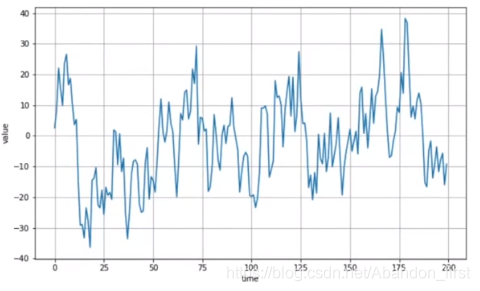
series = noise(time, seed=42)
plot_series(time[:200], series[:200])
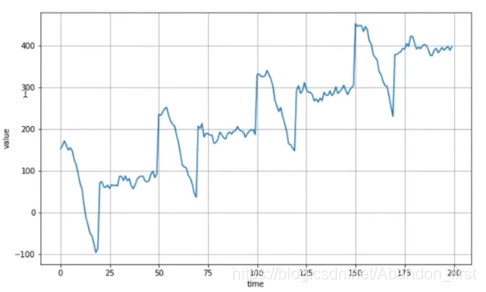
plt.show()series = autocorrelation(time, 10, seed=42) + trend(time, 2)
plot_series(time[:200], series[:200])
plt.show()series = autocorrelation(time, 10, seed=42) + seasonlity(time, period=50, amplitude=150) + trend(time, 2)
plot_series(time[:200], series[:200])
plt.show()
correlation + trend + noise
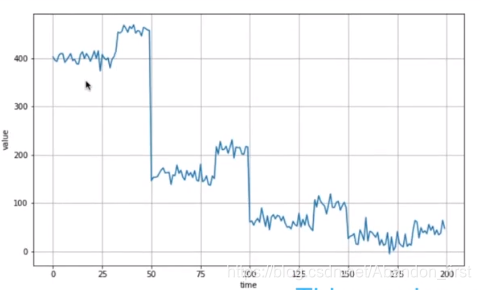
1.5 Train, validation and test sets
以 forecast 预测未来为例,讲解数据集的划分。
Naive Forecasting:假设下一个值和上一个值相等
如何评估模型性能呢?就必须有训练、验证和测试数据集。如果以 season 数据为例,每个部分中都应该至少包含了 whole season 数据(对比随机选择,随机选择可能不能包含整年的数据)。
- 你可以先在训练集上训练,然后使用验证集来验证训练的整体架构或者超参数;
- 确定之后,可以使用训练集和验证集一起来进行训练(不用就浪费了),再在测试集上测试;
- 如果发现在测试集上表现不错,你甚至可以把所有数据用来做训练,然后预测“未知”(因为 test data 此时是最接近“未知”)
Fixed Partitioning
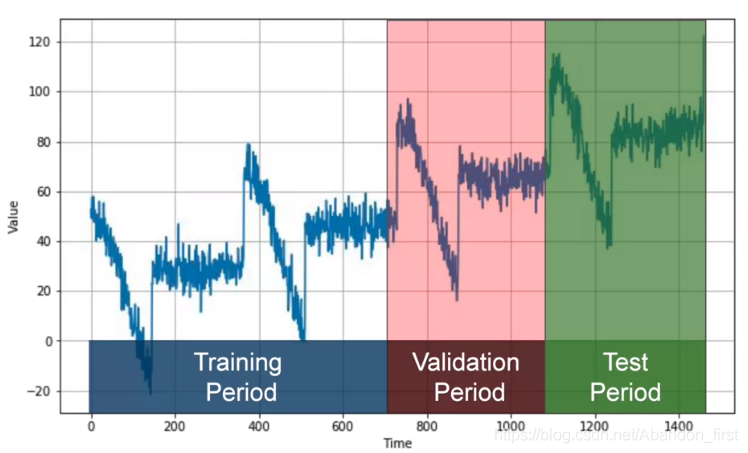
成熟一点的策略可以直接按照下图来分,就是没有检测模型结构或者超参数的过程了,但是会滚动地来进行训练和测试:
Roll-Forward Partitioning
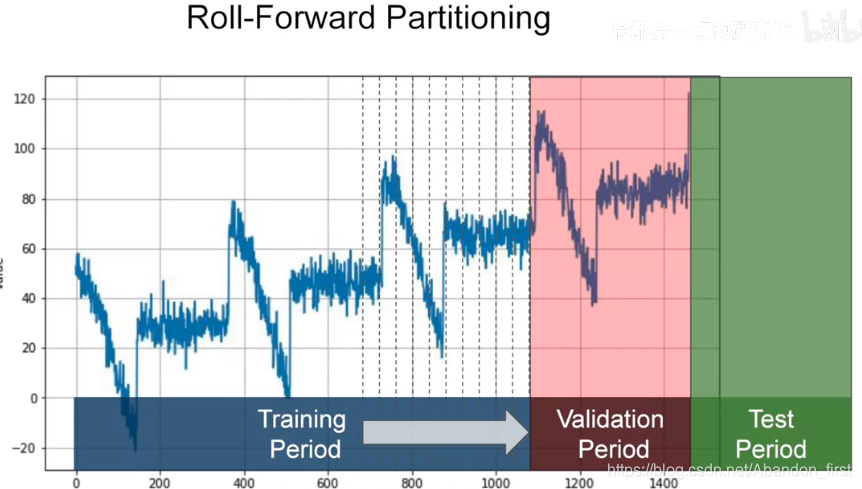
1.6 Metrics for evaluating performance
errors = forecasts - actual # 误差mse = np.square(errors).mean() # 均方误差 mean squared error
rmse = np.sqrt(mse) # 均方根误差 root mean squared error# mae 不会像 mse 一样惩罚较大的误差值
mae = np.abs(errors).mean() # 平均绝对误差 mean absolute error/main absolute deviation/mad mape = np.abs(errors / x_valid).mean() # mean absolute percentage error: mean ratio between the absolute error and the absolute value# 如果使用 mae 可以如下
keras.metrics.mean_absolute_error(x_valid, naive_forecast).numpy()
1.7 Aaverage and differencing
一个很常见的预测方法是计算 moving average 移动平均值,对应的平均窗口就是 averaging window,它可以消除附近的噪声,但是却不能包含整体的趋势信息。在这种情况下,可能会比单纯的 naive forecasting 的结果还要差。
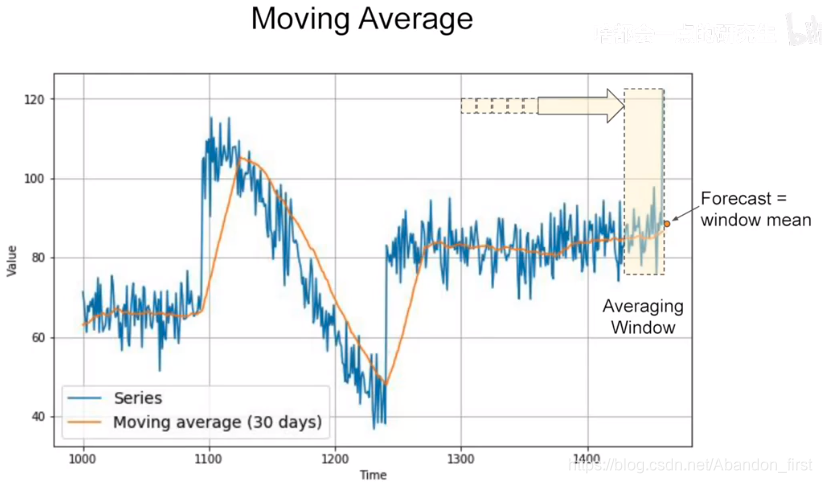
为了解决上面的问题,可以使用 diffencing 差分的方法,用后一年的减去前一年的,这样得到的是年之间的 trend 信息。就会得到下面的预测:
Forecasts = moving average of differences series + series(t - 365) 如下
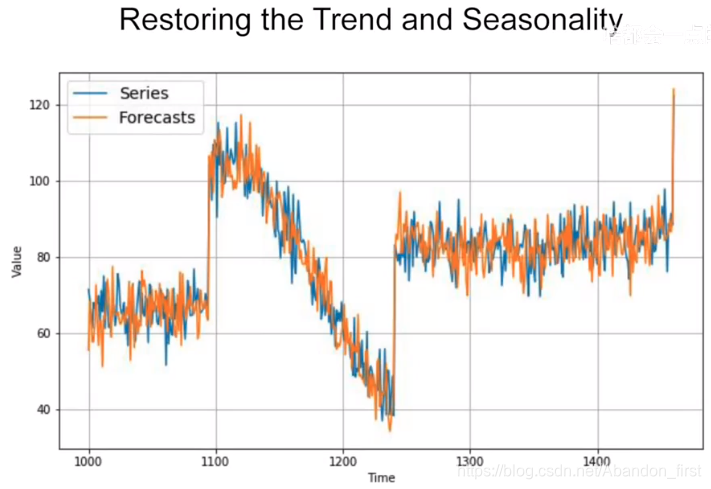
Forecasts = moving average of differences series + moving average of past series(t - 365) 如下
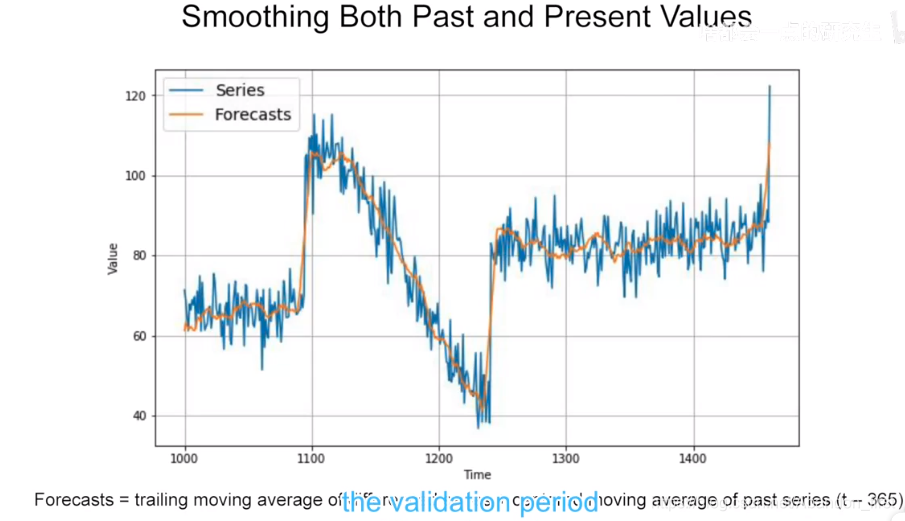
1.8 Trailing versus centered windows
中心窗会比拖尾窗要更合适(那当然了)
centerd windows > trailing windows
1.9 Forecasting
2.1 A conversation with Andrew Ng
用网络来做上面的序列预测。
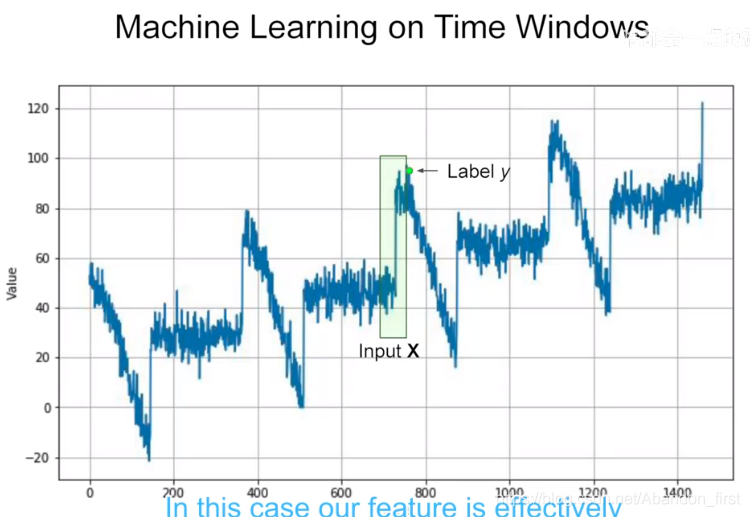
2.2 Preparing features and labels
在应用 ML 或网络之前,同样需要 features 和 labels。
和上一节课中的文字预测有点类似,特征选 0-N-1 个,label 就是第 N 个。这里 feature 用了 N 个点,N 就是 window size。
dataset = tf.data.Dataset.range(10)
dataset = dataset.window(5, shift=1, drop_remainder=True) # 去掉最后的零散数据,所有数据尺寸一致
dataset = dataset.flat_map(lambda window: window.batch(5))
dataset = dataset.map(lambda window: (window[:-1], window[-1:])) # 前 4 个是 feature,最后一个是 label
dataset = dataset.shuffle(buffer_size=10)
dataset = dataset.batch(2).prefetch(1)
for x, y in dataset:print("x = ", x.numpy())print("y = ", y.numpy())
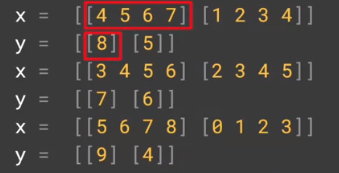
2.3 Preparing features and labels
2.4 Feeding windowed dataset into neural network
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):dataset = tf.data.Dataset.from_tensor_slices(series)dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))dataset = dataset.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1]))dataset = dataset.batch(batch_size).prefetch(1)return dataset
2.5 Single layer nural network
split_time = 1000
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]window_size = 20
batch_size = 32
shuffle_buffer_size = 1000# 只有一层且只有一个单元的网络
dataset = windowed_dataset(series, window_size, batch_size, shuffle_buffer_size)
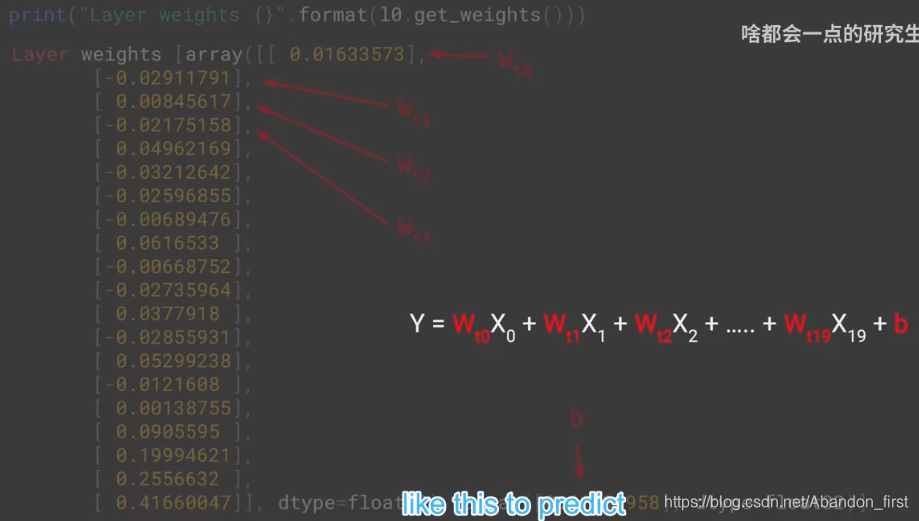
l0 = tf.keras.layers.Dense(1, input_shape=[window_size])
model = tf.keras.models.Sequential([10])model.compile(loss="mse", optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.fit(dataset, epochs=100, verbose=0)print("Layer weights {}".format(l0.get_weights()))
# 会有 window size 个 w 和 1 个 b 一共 window size + 1 个参数
2.6 Machine learning on time windows
2.7 Prediction
print(series[1:21])
model.predict(series[1:21][np.newaxis])forecast = []
for time in range(len(series) - window_size):forecast.append(model.predict(series[time: time + window_size][np.newaxis]))forecast = forecast[split_time = window_size:]
results = np.array(forecast)[:, 0, 0]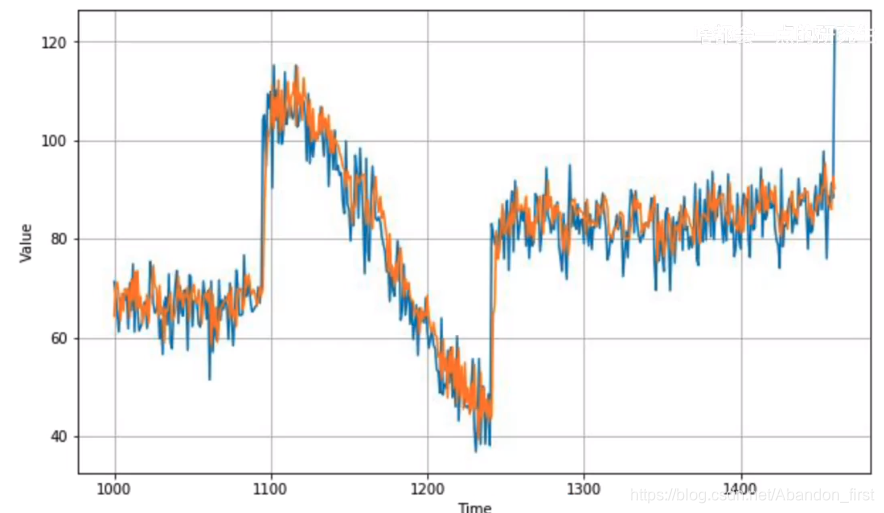
2.8 More on single layer neural network
2.9 Deep neural network training, tuning and prediction
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)model = tf.keras.models.Sequential([tf.karas.layers.Dense(10, input_shape=[window_size], activation='relu'),tf.keras.layers.Dense(10, activation='relu'),tf.keras.layers.Dense(1)
])model.compile(loss='mse', optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.fit(dataset, epochs=100, verbose=0)
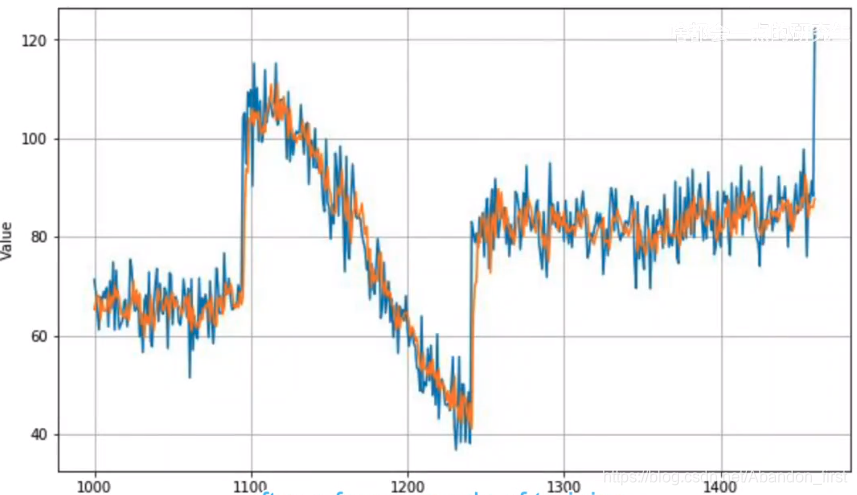
如果使用更好的学习率,那么能进行更加快速且有效的训练。那么如何找所谓更好的学习率呢?
仍然使用 SGD ,学习率变小为 1e-8,使用早先学的回调函数,每个 epoch 之后会回调 lr_schedule,产生的效果是根据 epoch 修改学习率。Epoch 1 ~ 1 e − 8 × 1 0 1 / 20 1e-8 × 10^{1/20} 1e−8×101/20;Epoch 100 ~ 1 e − 8 × 1 0 100 / 20 1e-8 × 10^{100/20} 1e−8×10100/20
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)# 3 层的全连接网络
model = tf.keras.models.Sequential([tf.karas.layers.Dense(10, input_shape=[window_size], activation='relu'),tf.keras.layers.Dense(10, activation='relu'),tf.keras.layers.Dense(1)
])lr_schedule = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-8 * 10 ** (epoch / 20))optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)model.compile(loss='mse', optimizer=optimizer)
history = model.fit(dataset, epochs=100, callbacks=[lr_schedule])lrs = 1e-8 * (10 ** (np.arange(100) / 20))
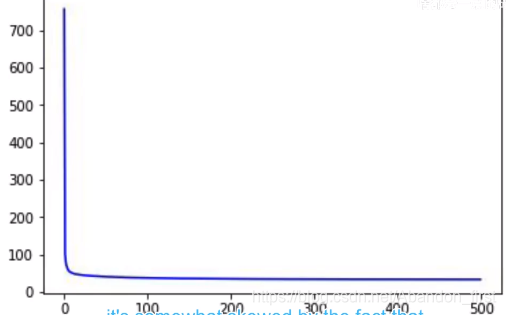
plt.semilogx(lrs, history.history["loss"])
plt.axis([1e-8, 1r-3, 0, 300])
如下图,横坐标是 lrs,纵坐标是 loss。选择 lr 的原则是,稳定 + 相对低的 loss,老师选择了 7e-6,接下来把学习率更新再进行训练试一下。
model.compile(loss='mse', optimizer=tf.keras.optimizers.SGD(lr=7e-6, momentum=0.9))
history = model.fit(dataset, epochs=500)loss = history.history['loss']
epochs = range(len(acc))
# 横轴 epoch 纵轴 loss
plt.plot(epochs, loss, 'b', label='Training Loss')
plt.show()
绘制出来如下图,可以看到,好像我们在“无效训练”。但是这里主要是因为最开始的那几轮的 loss 太高了(似曾相识),所以把前面 loss 扔掉,从 epoch 10 开始画,就可以看到在正常训练了。
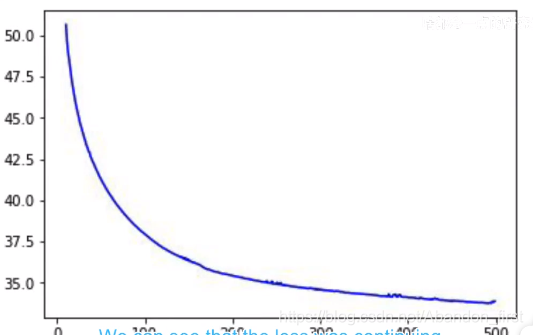
2.10 Deep neural network
本章节的内容中,主要使用 DNN,DNN虽然“可以”处理这些序列,但是却不能很好地 attention,也就是说,window 内的值都对当前值产生一样的影响,但是肯定是离得更近的 impact 更强。所以后面章节会使用 RNNs 来处理序列。
3.1 A conversation with Andrew Ng
本章主要应用 RNNs 来处理序列数据,效果会比 DNN 要好,因为相对较近的数据对当前影响更大。LSTM 中的 cell state or L/Long state 能够携带上下文信息。Lambda layer 能够将预处理“糅合到网络”当中去,很便利。
3.2 Conceptual overview
所谓的一层 Recurrent Layer 看起来有很多 cell,其实就只有一个,下图是单个 cell 在不同时刻的“展开”图,输入数据 window size 是 30,所以这里就有 30 个。
在早先 NLP 的例子中,单词能够携带它所在位置的上下文信息。此处对于数字序列,相对近距离的数据对当前造成的影响会比远处的大。
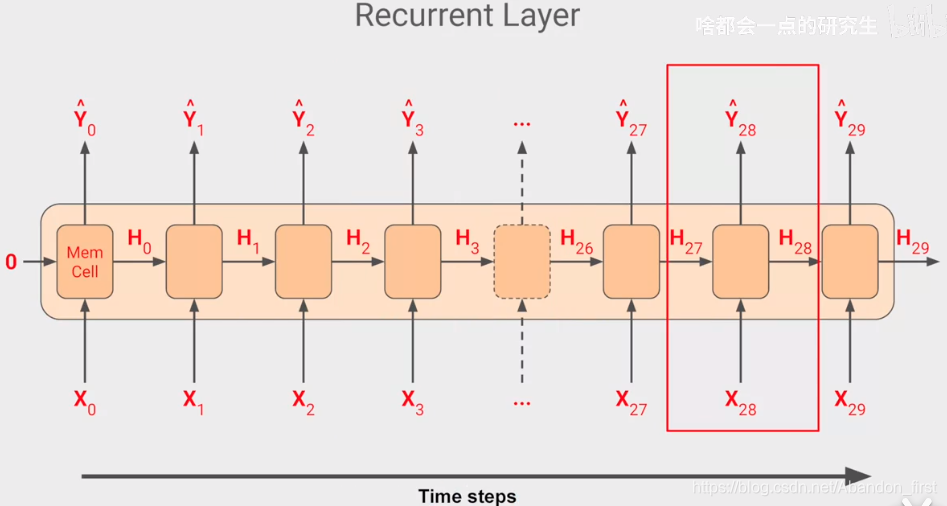
3.3 Shape of the inputs to the RNN
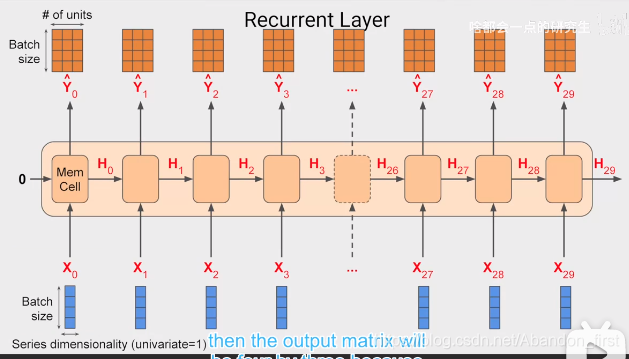
如果 window size 是 30,batchsize 为 4,series dimensionality 是 1,这层 RNN 有 3 个神经元。
那么每个时刻,RNN 输出的维度是 4 × 3;对于普通的 RNN 来说,到下个时刻的状态输入 Ht 就是上个时刻的输出 Yt-1。
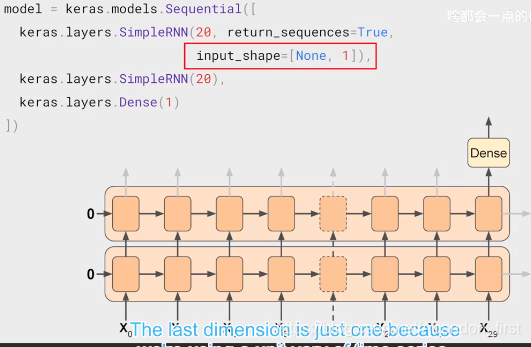
tf 中默认 LSTM 层输出只有最后的 Y29,如果你想要叠两层 RNN,第一层的输出也得是 sequence,需要设置 return_sequences=True。
3.4 Outputting a sequence
这里,叠了两层 RNN,每个 RNN 都有 20 个神经单元,序列长度是 30。第一层设置了 return_sequences 为 True,所以它可以输出 sequence 到第二层;而第二层默认返回一个,最后接一层 Dense。input_shape 参数,tf 默认其第一维为 batchsize,此处设置为 None。
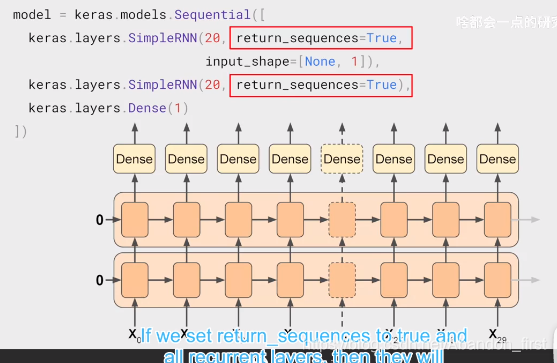
如果把两层的 return_sequences 都设置为 True,第二层也会输出 sequence。这就有 sequence to sequence 那味儿了~
3.5 Lambda layers
如果使用 lambda layer 可以比较简洁。

3.6 Adjusting the learning rate dynamically
仍然是绘制 lr 曲线来寻找比较好的学习率。
train_set = windowed_dataset(x_train, window_size, batch_size=128, shuffle_buffer=shuffle_buffer_size)model = tf.keras.models.Sequential([tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1, input_shape=[None])),tf.keras.layers.SimpleRNN(40, return_sequences=True),tf.keras.layers.SimpleRNN(40),tf.keras.layers.Dense(1),tf.keras.layers.Lambda(lambda x: x * 100.0)
])lr_schedule = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-8 * 10 ** (epoch / 20))optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)model.compile(loss=tf.keras.losses.Huber(), optimizer=optimizer, metrics=['mae'])history = model.fit(train_set, epochs=100, callbacks=[lr_schedule])lrs = 1e-8 * (10 ** (np.arange(100) / 20))
plt.semilogx(lrs, history.history["loss"])
plt.axis([1e-8, 1r-3, 0, 300])
根据下图,选择 loss 低 + 稳定的 lr,选择 5e-5。
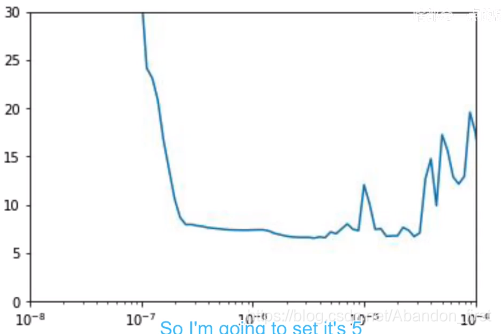
optimizer = tf.keras.optimizers.SGD(lr=5e-5, momentum=0.9)model.compile(loss=tf.keras.losses.Huber(), optimizer=optimizer, metrics=['mae'])history = model.fit(train_set, epochs=500, callbacks=[lr_schedule])
这里训练的时候发现 400 epoch 之后开始震荡了,所以在 400 停止即可。
3.7 RNN
3.8 LSTM
3.9 Coding LSTMs
tf.keras.backend.clear_session()
dataset = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)model = tf.keras.models.Sequential([tf.keras.layers.Lambda(lambda x: tf.expand_dims(x, axis=-1), input_shape=[None]),tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),tf.keras.layers.Dense(1),tf.keras.layers.Lambda(lambda x: x * 100.0)])model.compile(loss='mse', optimizer=tf.keras.optimizers.SGD(lr=1e-6, momentum=0.9))
model.fit(dataset, epochs=100)
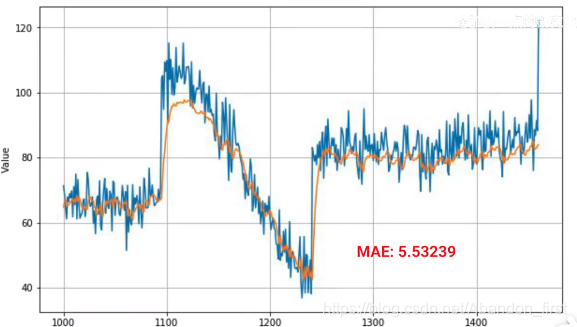
3.10 More on LSTM
4.1 A conversation with Andrew Ng
在 RNN 之前,加一层 Conv1D 处理数据。
4.2 Convolutions
tf.keras.layers.Conv1D(filters=32, kernel_size=5, strides=1, padding='casual', activation='relu', input_shape=[None, 1])
4.3 Bi-directional LSTMs
model = tf.keras.models.Sequential([tf.keras.layers.Conv1D(filters=32, kernel_size=5, strides=1, padding='casual', activation='relu', input_shape=[None, 1])tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)), tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32, return_sequences=True)),tf.keras.layers.Dense(1),tf.keras.layers.Lambda(lambda x: x * 200)
])
然后过拟合了,但是这里的过拟合表现是 MAE 和 loss 随着 epoch 的增加表现出来震荡。这里由于 batchsize 大小不合适,提出的解决方式是修改 batchsize(最后老师在 workbook 中将 32 改成了 128)。
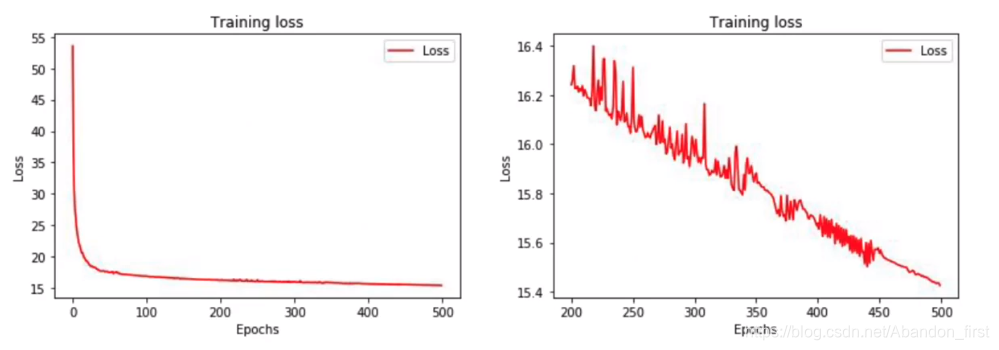
4.4 LSTM
后面老师调参也没有调处来很好的结果哈哈哈。
4.5 Real data sunspots
4.6 Train and tune the model
4.7 Prediction
4.8 Sunspots
4.9 Combining our tools for analysis
4.10 Congratulations
4.11 Specialization wrap up
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!