如何使用神经网络实现最简单的序列预测?
一、内容摘要
神经网络在序列预测任务中具有广泛的应用,它们能够对各种类型的序列数据进行建模和预测,例如时间序列、趋势分析、自然语言和DNA序列等。
在这篇博客中,我们将介绍如何使用神经网络进行简单的序列预测任务,包括数据准备、模型构建、训练和预测等方面。
说明:本文涉及方法均为说明性demo,实际数据应用请使用符合数据特性的模型和方法。
二、版本及环境
Anaconda做环境控制(与项目本身关系不大)
Python
Pytorch
三、结构及方法
1.样例数据准备
样例数据使用了一种非常简单的构造方法,即叠加两种不同频率的波形构成目标数据(参考傅里叶变换),因此得到的数据其实是一种较为理想纯净的、具有明显频率特征的数据,代码如下:
def seq2sets(seq, ws):out = []L = len(seq)for i in range(L - ws):window = seq[i:i + ws]label = seq[i + ws:i + ws + 1]out.append((window, label))return out# Sequence and Datasets
t = np.arange(0, 1, 0.001) # 时刻序列
train_seq = torch.FloatTensor(np.sin(2 * np.pi * 1 * t) + np.sin(2 * np.pi * 300 * t))
train_data = seq2sets(train_seq, WINDOW_SIZE)
plt.plot(train_seq)
plt.show()
该数据序列绘图如下,可以看出由高频和低频两部分组成:

数据集裁剪方式为根据设定的窗口大小进行切片,长序列裁剪成许多短序列(参考代码中的seq2sets函数)。代码仅供说明用途,非最佳处理方式。
序列预测的目标:预测1000~1200位置上的数据。
- 模型输入:一个WINDOW_SIZE大小的输入
- 模型输出:一个单点输出
多步预测可以采用将预测值继续丢进网络进行下一步预测的方法实现。
2.BP神经网络
可以认为是最基本的神经网络结构,能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
BP网络通过反向传播来不断调整网络的权值和阈值,使网络的误差最小。
class BP(nn.Module):def __init__(self, input_dim):super().__init__()self.Linear1 = nn.Linear(input_dim, 50)self.Linear2 = nn.Linear(50, 1)self.relu = nn.ReLU()def forward(self, x):x = self.Linear1(x)x = self.relu(x)x = self.Linear2(x)return x3.CNN(卷积神经网络)
图像识别中经典的网络结构,以局部视野和全局共享为最大特性。
class CNN(nn.Module):def __init__(self):super().__init__()self.conv1d = nn.Conv1d(1, 64, kernel_size=5, stride=3)self.relu = nn.ReLU(inplace=True)self.Linear1 = nn.Linear(64 * 66, 50)self.Linear2 = nn.Linear(50, 1)def forward(self, x):x = self.conv1d(x)x = self.relu(x)x = x.view(-1)x = self.Linear1(x)x = self.relu(x)x = self.Linear2(x)return x4.LSTM(长短期记忆网络)
LSTM是一种特殊的递归神经网络 。被设计用于解决一般递归神经网络中普遍存在的长期依赖问题,使用LSTM可以有效的传递和表达长时间序列中的信息并且不会导致长时间前的有用信息被忽略(遗忘)。
class LSTM(nn.Module):def __init__(self, inp_dim, out_dim, mid_dim, mid_layers):super(LSTM, self).__init__()self.rnn = nn.LSTM(inp_dim, mid_dim, mid_layers) # rnnself.reg = nn.Sequential(nn.Linear(mid_dim, mid_dim),nn.ReLU(),nn.Linear(mid_dim, out_dim),) # regressiondef forward(self, x):y = self.rnn(x)[0] # y, (h, c) = self.rnn(x)seq_len, batch_size, hid_dim = y.shapey = y.view(-1, hid_dim)y = self.reg(y)y = y.view(seq_len, batch_size, -1)return ydef output_y_hc(self, x, hc):y, hc = self.rnn(x, hc) # y, (h, c) = self.rnn(x)seq_len, batch_size, hid_dim = y.size()y = y.view(-1, hid_dim)y = self.reg(y)y = y.view(seq_len, batch_size, -1)return y, hc四、完整代码
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import timeclass BP(nn.Module):def __init__(self, input_dim):super().__init__()self.Linear1 = nn.Linear(input_dim, 50)self.Linear2 = nn.Linear(50, 1)self.relu = nn.ReLU()def forward(self, x):x = self.Linear1(x)x = self.relu(x)x = self.Linear2(x)return xclass CNN(nn.Module):def __init__(self):super().__init__()self.conv1d = nn.Conv1d(1, 64, kernel_size=5, stride=3)self.relu = nn.ReLU(inplace=True)self.Linear1 = nn.Linear(64 * 66, 50)self.Linear2 = nn.Linear(50, 1)def forward(self, x):x = self.conv1d(x)x = self.relu(x)x = x.view(-1)x = self.Linear1(x)x = self.relu(x)x = self.Linear2(x)return xclass LSTM(nn.Module):def __init__(self, inp_dim, out_dim, mid_dim, mid_layers):super(LSTM, self).__init__()self.rnn = nn.LSTM(inp_dim, mid_dim, mid_layers) # rnnself.reg = nn.Sequential(nn.Linear(mid_dim, mid_dim),nn.ReLU(),nn.Linear(mid_dim, out_dim),) # regressiondef forward(self, x):y = self.rnn(x)[0] # y, (h, c) = self.rnn(x)seq_len, batch_size, hid_dim = y.shapey = y.view(-1, hid_dim)y = self.reg(y)y = y.view(seq_len, batch_size, -1)return ydef output_y_hc(self, x, hc):y, hc = self.rnn(x, hc) # y, (h, c) = self.rnn(x)seq_len, batch_size, hid_dim = y.size()y = y.view(-1, hid_dim)y = self.reg(y)y = y.view(seq_len, batch_size, -1)return y, hcdef seq2sets(seq, ws):out = []L = len(seq)for i in range(L - ws):window = seq[i:i + ws]label = seq[i + ws:i + ws + 1]out.append((window, label))return outdef train(model, optimizer, criterion, epoch):model.train()for seq_i, y_train in train_data:optimizer.zero_grad()y_pred = model(seq_i.reshape(1, 1, -1))loss = criterion(y_pred, y_train)loss.backward()optimizer.step()print(f'Epoch: {epoch:2} Loss: {loss.item():10.8f}')def predict(model, future_step):model.eval()# 选取序列最后WINDOW_SIZE个值开始预测preds = train_seq[-WINDOW_SIZE:].tolist()# 循环的每一步表示向时间序列向后滑动一格for i in range(future_step):seq_i = torch.FloatTensor(preds[-WINDOW_SIZE:])with torch.no_grad():preds.append(model(seq_i.reshape(1, 1, -1)).item())return preds[-future_step:]if __name__ == '__main__':# ConfigurationsWINDOW_SIZE = 200FUTURE_STEP = 200EPOCH_MAX = 20LEARNING_RATE = 0.0001MODEL_DICT = {'method_index': [0, 1, 2, 3],'method_name': ['BP', 'CNN', 'LSTM'],'model': [BP(input_dim=WINDOW_SIZE),CNN(),LSTM(inp_dim=WINDOW_SIZE, out_dim=1, mid_dim=20, mid_layers=3)],}# Sequence and Datasetst = np.arange(0, 1, 0.001) # 时刻序列train_seq = torch.FloatTensor(np.sin(2 * np.pi * 1 * t) + np.sin(2 * np.pi * 300 * t))# train_seq = torch.FloatTensor(np.load('frequence.npz')['arr_0'])train_data = seq2sets(train_seq, WINDOW_SIZE)plt.plot(train_seq)plt.show()# Model settingfor model_index, model in enumerate(MODEL_DICT['method_name']):model = MODEL_DICT['model'][model_index]criterion = nn.MSELoss() # loss function: mseoptimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE) # optimizer and lrstart_time = time.time()for epoch in range(EPOCH_MAX):train(model, optimizer, criterion, epoch)print(f'\nDuration: {time.time() - start_time:.0f} seconds')preds = predict(model, future_step=WINDOW_SIZE)# 对比真实值和预测值plt.grid()plt.plot(train_seq)plt.plot(np.arange(len(train_seq), len(train_seq) + FUTURE_STEP, 1), preds)# x = np.arange('2018-02-01', '2019-02-01', dtype='datetime64[M]').astype('datetime64[D]')plt.show()
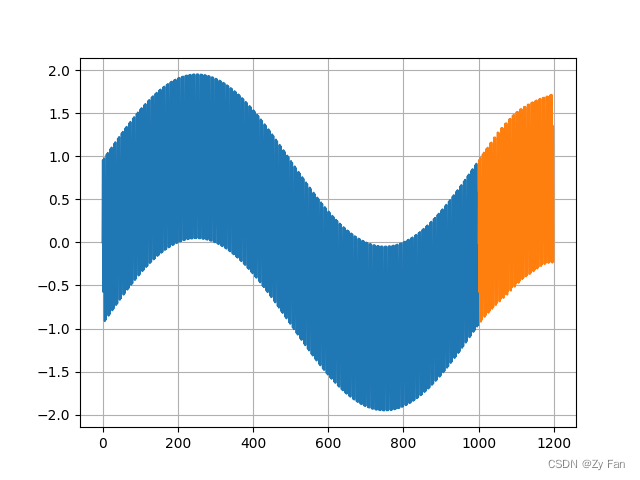
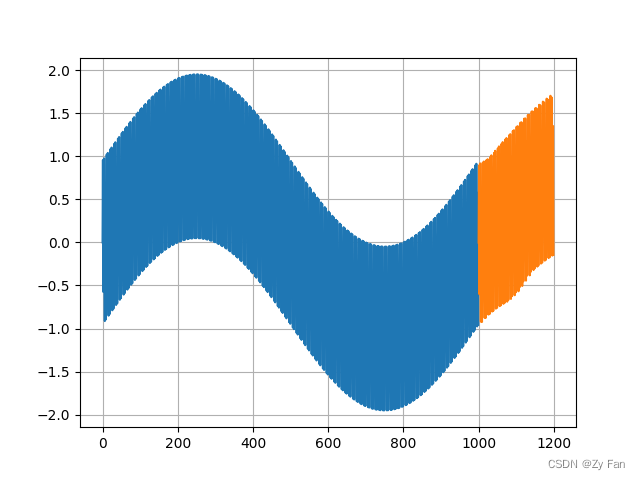
五、部分运行结果
三种方法的结果展示:
说明:该结果仅基于极短时间的训练。并且由于数据非常简单,因此BP体现出较好的效果。
但本结果并不能表明三种模型在实际应用中的性能,一般来说,LSTM和Transformer类型的网络能对序列数据处理更好。

可能的额外工作
1.数据加噪/去噪
2.结合数据特性进行频域分析
3.选择适当的窗口大小和步长
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!