HashMap分析之源码分析(二)
1.链表长度大于8(红色树中至少9各个节点)并且数组长度大于64的情况下将整个链表转换为红黑树:
//链表最大长度8
static final int TREEIFY_THRESHOLD = 8;for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;
}链表达到最大存储容量的结构:

转换为红黑树的最小容量:
static final int MIN_TREEIFY_CAPACITY = 64;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
如果容量小于默认的64会进行扩容,因为扩容可以重新计数计算index值可能导致链表的长度小于8,使数据更加均匀的分布在table中。
并且在符合红黑树装换条件时将链表节点装换为双向链表,为树化(转换为红黑树比较的是hash值)做准备:
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
为什么红黑树要采用双向链表的形式?
作者的原话是needed to unlink next upon deletion
翻译过来就是为了在删除的时候进行断链操作,断链之后找到前面节点指向后面节点。
2.Jdk1.8在扩容的时候重新计算index值,通过原容量(10000形式) & hash值,如果高位与结果相同时新的index就是原index + 原容量,否则还是在原来的index处。这样提高了重新计算下标位置的效率。
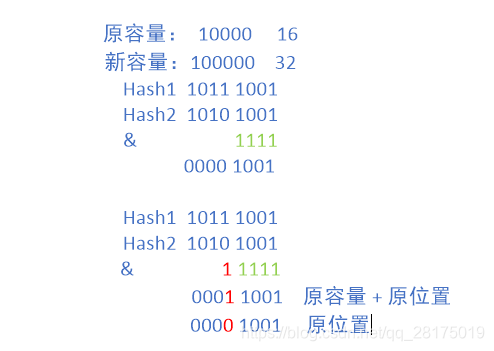
扩容原理图 1
在扩容的时候还会,拆解红黑树:
- 将链表分为高低链表,结合上面图1就可以知道扩容后,loTail链表元素保持原有位置, hiTail链表元素位置左移一位;
- 如果小于等于红黑树阈值,将红黑树链表化;
- 否者树化链表。
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);static final int UNTREEIFY_THRESHOLD = 6;
3.HashMap如何降低Hash冲突概率:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}((p = tab[i = (n - 1) & hash])
为什么需要n-1?
因为n为偶数不减去1的话转换为二进制是0000 0001的形式&hash值时,结果只有两种情况0000 0000和0000 00001。这样不能让我们的数据离散,更加均匀地存储在数据结构中的位置。 当n-1后就是一个奇数0000 1111 & hash时结果才会更多。
4.常见问题
hashmap中modcount作用?
迭代器遍历,fastclass机制,防止并发地操作;
一万条数据存放hashmap怎样效率高?
初始化容量:存储元素个数/负载因子 + 1;
负载因子0.75 :统计学概率:泊松分布是统计学和概率学常见的离散概率分布
HashMap8中为什么需要引入红黑树?
在索引冲突严重的情况下,链表的查询效率很低为O(N);为了优化查询效率在链表长度大于阈值8并且数组长度大于64的情况下将整个链表转换为红黑树,提高了查询效率,时间复杂度是OlongN。
HashMap8与7实现有那些区别:
1.实现的数据结构不同,1.8新增了红黑树,进行存储提高了效率;
2.求hash函数不同,1.7 4次位移或运算得到hash值,1.8高位或运算求值;
3.1.7在链表中插入索引值相同,key不同的时候采用的是头插法,在多线程的情况下会导致死循环,拉死CPU.1.8改进了这种方法采用的头插法;
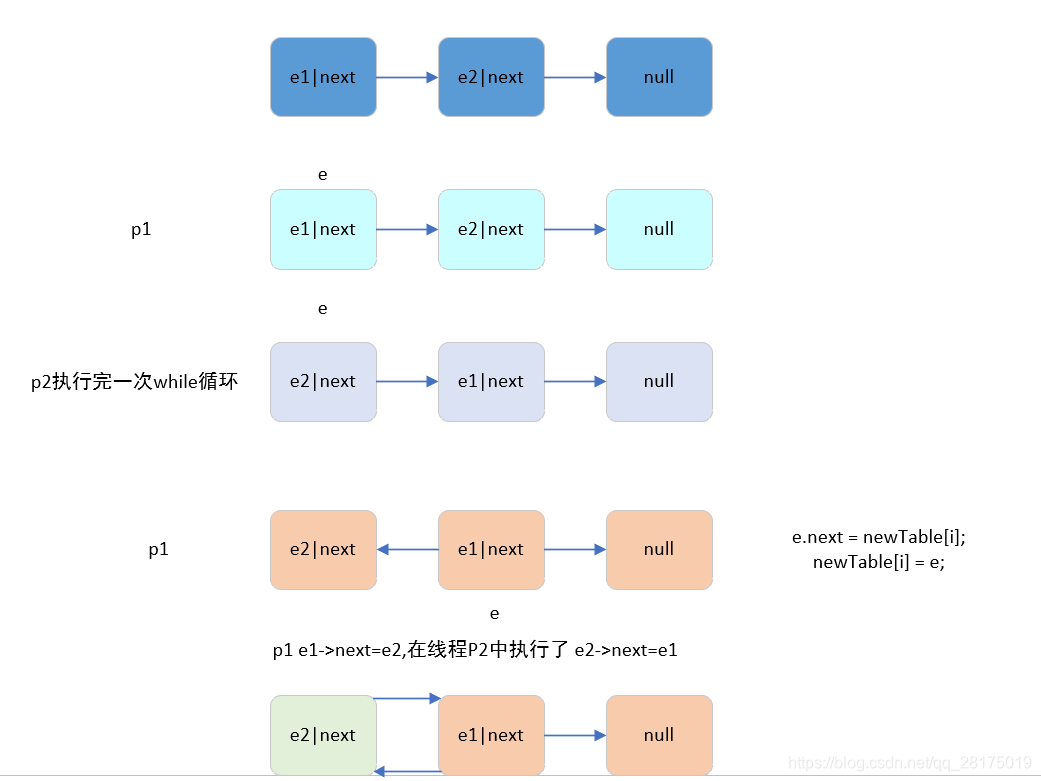
jdk1.7头插法图解2
4.1.7在扩容的时候会重新全部计算索引值,而在1.8中采用是高位与运算,为1则索引值等于原来索引值加原来容量值,为0b表示索引值不变,提高了计算效率。
HashMap是如何将链表转换红:
如果链表节点数大于阈值并且数组长度大于64的时候将链表装换为一个双向链表,然后再基于链表进行红黑树化。
HashMap与HashTable区别:
HashTable是线程安全的,hashMap线程不安全。hashTable不允许空的键值。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!