【笔记】BN(Batch Normalization)、正则化:BN是在同一批次中逐个的计算同一channel的均值,方差,来进行归一化;正则化作用是 损失精度去调整样本的不足产生的拟合
还是希望大家带着批判的眼光看问题,有的人说L0不是范数。
BN:其能一定程度的起到正则化作用,几乎代替Dropout


注意可训练参数 的维度 等于 批次内 每一个张量的 channels。 如果是R、G、B图像,维度就是3。也就是每一个channel都需要一个
,所以它俩各是1 X 3的列向量。
summary
OrderedDict([('Conv2d-1',OrderedDict([('input_shape', [-1, 3, 418, 418]),('output_shape', [-1, 64, 209, 209]),('trainable', True),('nb_params', tensor(9408))])),('BatchNorm2d-2',OrderedDict([('input_shape', [-1, 64, 209, 209]),('output_shape', [-1, 64, 209, 209]),('trainable', True)]))])
len(summary)
2module.weight.requires_grad
Truemodule.weight
Parameter containing:
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], device='cuda:0',requires_grad=True)module.weight.size()
torch.Size([64])module.bias.size()
torch.Size([64])module.bias
Parameter containing:
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],device='cuda:0', requires_grad=True)module.bias.size()
torch.Size([64])
eg1:
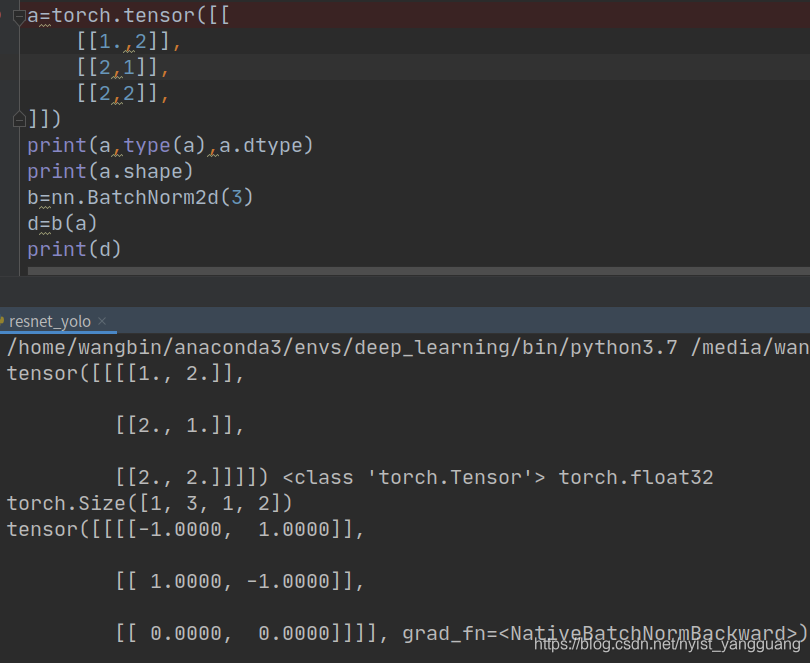

eg2:
import torch.nn as nn
import torcha = torch.tensor([[[[1., 2]],[[2, 1]],[[2, 2]],],[[[2., 2]],[[3, 1]],[[1, 2]],]])
print(a, type(a), a.dtype)
print(a.shape)
b = nn.BatchNorm2d(3)
d = b(a)
print(d)tensor([[[[1., 2.]],[[2., 1.]],[[2., 2.]]],[[[2., 2.]],[[3., 1.]],[[1., 2.]]]]) torch.float32
torch.Size([2, 3, 1, 2])
tensor([[[[-1.7320, 0.5773]],[[ 0.3015, -0.9045]],[[ 0.5773, 0.5773]]],[[[ 0.5773, 0.5773]],[[ 1.5075, -0.9045]],[[-1.7320, 0.5773]]]], grad_fn=) 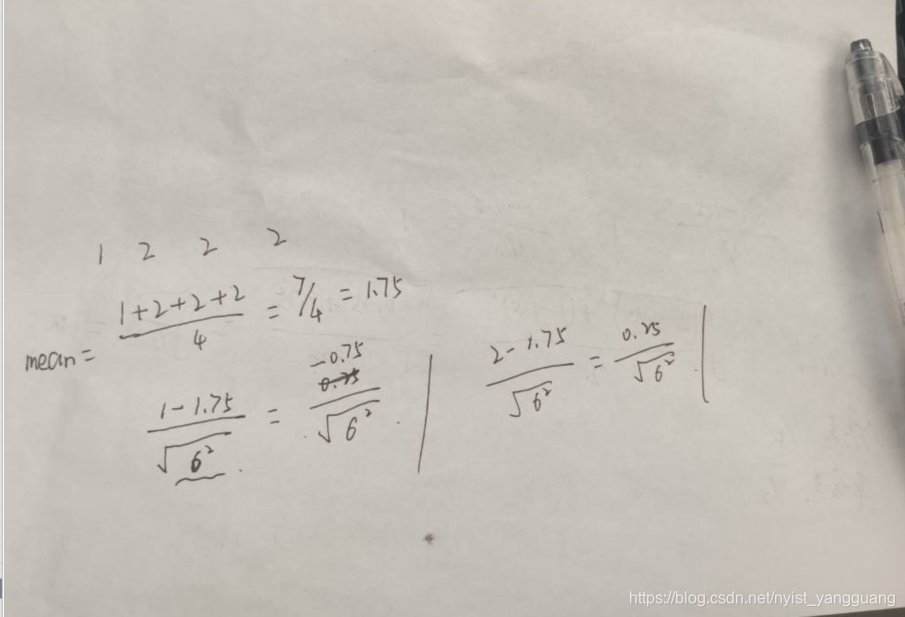
正则化:




本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!