NOIP2011提高组题解
[NOIP2011 提高组] 铺地毯
题目:[NOIP2011 提高组] 铺地毯
题目描述
为了准备一个独特的颁奖典礼,组织者在会场的一片矩形区域(可看做是平面直角坐标系的第一象限)铺上一些矩形地毯。一共有 n n n 张地毯,编号从 1 1 1 到 n n n。现在将这些地毯按照编号从小到大的顺序平行于坐标轴先后铺设,后铺的地毯覆盖在前面已经铺好的地毯之上。
地毯铺设完成后,组织者想知道覆盖地面某个点的最上面的那张地毯的编号。注意:在矩形地毯边界和四个顶点上的点也算被地毯覆盖。
输入格式
输入共 n + 2 n + 2 n+2 行。
第一行,一个整数 n n n,表示总共有 n n n 张地毯。
接下来的 n n n 行中,第 i + 1 i+1 i+1 行表示编号 i i i 的地毯的信息,包含四个整数 a , b , g , k a ,b ,g ,k a,b,g,k,每两个整数之间用一个空格隔开,分别表示铺设地毯的左下角的坐标 ( a , b ) (a, b) (a,b) 以及地毯在 x x x 轴和 y y y 轴方向的长度。
第 n + 2 n + 2 n+2 行包含两个整数 x x x 和 y y y,表示所求的地面的点的坐标 ( x , y ) (x, y) (x,y)。
输出格式
输出共 1 1 1 行,一个整数,表示所求的地毯的编号;若此处没有被地毯覆盖则输出 -1。
样例 #1
样例输入 #1
3
1 0 2 3
0 2 3 3
2 1 3 3
2 2
样例输出 #1
3
样例 #2
样例输入 #2
3
1 0 2 3
0 2 3 3
2 1 3 3
4 5
样例输出 #2
-1
提示
【样例解释 1】
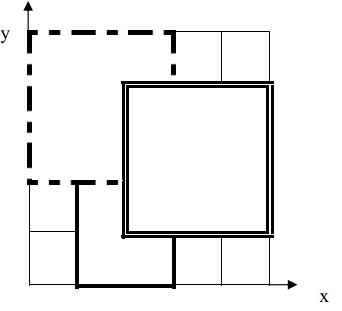
如下图, 1 1 1 号地毯用实线表示, 2 2 2 号地毯用虚线表示, 3 3 3 号用双实线表示,覆盖点 ( 2 , 2 ) (2,2) (2,2) 的最上面一张地毯是 3 3 3 号地毯。
【数据范围】
对于 30 % 30\% 30% 的数据,有 n ≤ 2 n \le 2 n≤2。
对于 50 % 50\% 50% 的数据, 0 ≤ a , b , g , k ≤ 100 0 \le a, b, g, k \le 100 0≤a,b,g,k≤100。
对于 100 % 100\% 100% 的数据,有 0 ≤ n ≤ 1 0 4 0 \le n \le 10^4 0≤n≤104, 0 ≤ a , b , g , k ≤ 10 5 0 \le a, b, g, k \le {10}^5 0≤a,b,g,k≤105。
noip2011 提高组 day1 第 1 1 1 题。
题解
解题思路
本题是一个很简单的模拟题
因为这道题所占用的空间较大,如果进行遍历数组地图的方法无论是空间复杂度还是时间复杂度都会变得很复杂
所以,不妨进行分析,其实每个地毯只需要5个数据就好,这样能大大的加大空间利用率,也不必去遍历那些无用的空间。 每张地毯所需要的数据无非是左下角坐标x,y,右上角坐标x,y和地毯编号。 只要点在地毯范围内,最后取编号最大的输出即可。
一开始开个二维数组去搞,没看到数据范围…MLE… ( Q A Q ) (QAQ) (QAQ),换成结构体数组就 A C AC AC了
考点
模拟 枚举
时间复杂度
O ( N ) O(N) O(N)
AC代码
#pragma GCC optimize(2)
#include [NOIP2011 提高组] 选择客栈
题目:[NOIP2011 提高组] 选择客栈
题目描述
丽江河边有 n n n 家很有特色的客栈,客栈按照其位置顺序从 1 1 1 到 n n n 编号。每家客栈都按照某一种色调进行装饰(总共 k k k 种,用整数 0 ∼ k − 1 0 \sim k-1 0∼k−1 表示),且每家客栈都设有一家咖啡店,每家咖啡店均有各自的最低消费。
两位游客一起去丽江旅游,他们喜欢相同的色调,又想尝试两个不同的客栈,因此决定分别住在色调相同的两家客栈中。晚上,他们打算选择一家咖啡店喝咖啡,要求咖啡店位于两人住的两家客栈之间(包括他们住的客栈),且咖啡店的最低消费不超过 p p p 。
他们想知道总共有多少种选择住宿的方案,保证晚上可以找到一家最低消费不超过 p p p 元的咖啡店小聚。
输入格式
共 n + 1 n+1 n+1 行。
第一行三个整数 n , k , p n, k, p n,k,p,每两个整数之间用一个空格隔开,分别表示客栈的个数,色调的数目和能接受的最低消费的最高值;
接下来的 n n n 行,第 i + 1 i+1 i+1 行两个整数,之间用一个空格隔开,分别表示 $i $ 号客栈的装饰色调 a i a_i ai 和 i i i 号客栈的咖啡店的最低消费 b i b_i bi。
输出格式
一个整数,表示可选的住宿方案的总数。
样例 #1
样例输入 #1
5 2 3
0 5
1 3
0 2
1 4
1 5
样例输出 #1
3
提示
样例解释
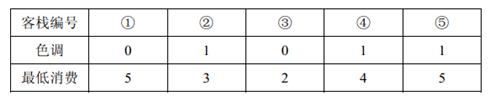
2 人要住同样色调的客栈,所有可选的住宿方案包括:住客栈①③,②④,②⑤,④⑤,但是若选择住 4 , 5 4,5 4,5号客栈的话, 4 , 5 4,5 4,5 号客栈之间的咖啡店的最低消费是 4 4 4 ,而两人能承受的最低消费是 3 3 3 元,所以不满足要求。因此只有前 3 3 3 种方案可选。
数据范围
- 对于 30 % 30\% 30% 的数据,有 n ≤ 100 n \leq 100 n≤100 ;
- 对于 50 % 50\% 50% 的数据,有 n ≤ 1 000 n \leq 1\,000 n≤1000;
- 对于 100 % 100\% 100% 的数据,有 2 ≤ n ≤ 2 × 1 0 5 2 \leq n \leq 2 \times 10^5 2≤n≤2×105, 1 ≤ k ≤ 50 1 \leq k \leq 50 1≤k≤50, 0 ≤ p ≤ 100 0 \leq p \leq 100 0≤p≤100, 0 ≤ b i ≤ 100 0 \leq b_i \leq 100 0≤bi≤100。
题解
解题思路
简单来讲就是在一段一维客栈中,任意选择两个客栈 a 、 b a、b a、b,满足以下两个条件:
1. a 、 b a、b a、b颜色相同,
2. [ a , b ] [a,b] [a,b]闭区间之间必须存在某个客栈的咖啡店的花费小于等于 p p p;
因为我们要找到所有成立的 a 、 b a、b a、b,那么我们就枚举每个 b b b 想办法找到此时符合条件的a有多少个
用一个变量t记录的是当前枚举客栈过程中,离我们枚举到的客栈最近的最低消费小于等于 p p p的客栈的下标(第几个客栈)
开个数组 ( n u m [ ] ) (num[ ]) (num[])实时更新在t前面的各个颜色的客栈有多少个;
当然我们还用了一个 c o l o r color color数组记录每个客栈的颜色,这样我们就得到了答案
考点
递推
时间复杂度
O ( N ) O(N) O(N)
AC代码
#pragma GCC optimize(2)
#include [NOIP2011 提高组] Mayan 游戏
题目:[NOIP2011 提高组] Mayan 游戏
题目描述
Mayan puzzle 是最近流行起来的一个游戏。游戏界面是一个 7 7 7 行 × 5 \times5 ×5 列的棋盘,上面堆放着一些方块,方块不能悬空堆放,即方块必须放在最下面一行,或者放在其他方块之上。游戏通关是指在规定的步数内消除所有的方块,消除方块的规则如下:
- 每步移动可以且仅可以沿横向(即向左或向右)拖动某一方块一格:当拖动这一方块时,如果拖动后到达的位置(以下称目标位置)也有方块,那么这两个方块将交换位置(参见输入输出样例说明中的图 6 6 6 到图 7 7 7);如果目标位置上没有方块,那么被拖动的方块将从原来的竖列中抽出,并从目标位置上掉落(直到不悬空,参见下面图 1 1 1 和图 2 2 2);
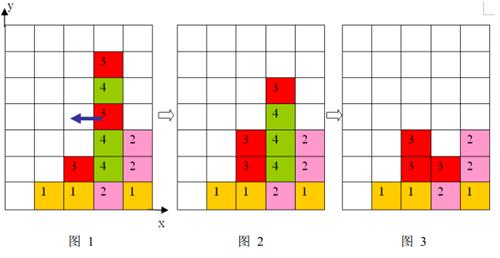
- 任一时刻,如果在一横行或者竖列上有连续三个或者三个以上相同颜色的方块,则它们将立即被消除(参见图1 到图3)。
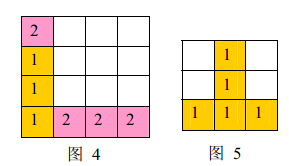
注意:
a) 如果同时有多组方块满足消除条件,几组方块会同时被消除(例如下面图 4 4 4,三个颜色为 1 1 1 的方块和三个颜色为 2 2 2 的方块会同时被消除,最后剩下一个颜色为 2 2 2 的方块)。
b) 当出现行和列都满足消除条件且行列共享某个方块时,行和列上满足消除条件的所有方块会被同时消除(例如下面图5 所示的情形, 5 5 5 个方块会同时被消除)。
- 方块消除之后,消除位置之上的方块将掉落,掉落后可能会引起新的方块消除。注意:掉落的过程中将不会有方块的消除。
上面图 1 1 1 到图 3 3 3 给出了在棋盘上移动一块方块之后棋盘的变化。棋盘的左下角方块的坐标为 ( 0 , 0 ) (0,0) (0,0),将位于 ( 3 , 3 ) (3,3) (3,3) 的方块向左移动之后,游戏界面从图 1 1 1 变成图 2 2 2 所示的状态,此时在一竖列上有连续三块颜色为 4 4 4 的方块,满足消除条件,消除连续 3 3 3 块颜色为 4 4 4 的方块后,上方的颜色为 3 3 3 的方块掉落,形成图 3 3 3 所示的局面。
输入格式
共 6 6 6 行。
第一行为一个正整数 n n n,表示要求游戏通关的步数。
接下来的 5 5 5 行,描述 7 × 5 7 \times 5 7×5 的游戏界面。每行若干个整数,每两个整数之间用一个空格隔开,每行以一个 0 0 0 结束,自下向上表示每竖列方块的颜色编号(颜色不多于 10 10 10 种,从 1 1 1 开始顺序编号,相同数字表示相同颜色)。
输入数据保证初始棋盘中没有可以消除的方块。
输出格式
如果有解决方案,输出 n n n 行,每行包含 3 3 3 个整数 x , y , g x,y,g x,y,g,表示一次移动,每两个整数之间用一个空格隔开,其中 ( x , y ) (x,y) (x,y) 表示要移动的方块的坐标, g g g 表示移动的方向, 1 1 1 表示向右移动, − 1 -1 −1 表示向左移动。注意:多组解时,按照 x x x 为第一关键字, y y y 为第二关键字, 1 1 1 优先于 − 1 -1 −1,给出一组字典序最小的解。游戏界面左下角的坐标为 ( 0 , 0 ) (0,0) (0,0)。
如果没有解决方案,输出一行 -1。
样例 #1
样例输入 #1
3
1 0
2 1 0
2 3 4 0
3 1 0
2 4 3 4 0
样例输出 #1
2 1 1
3 1 1
3 0 1
提示
【输入输出样例说明】
按箭头方向的顺序分别为图 6 6 6 到图 11 11 11
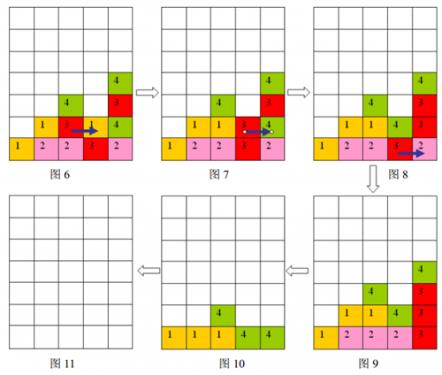
样例输入的游戏局面如上面第一个图片所示,依次移动的三步是: ( 2 , 1 ) (2,1) (2,1) 处的方格向右移动, ( 3 , 1 ) (3,1) (3,1) 处的方格向右移动, ( 3 , 0 ) (3,0) (3,0) 处的方格向右移动,最后可以将棋盘上所有方块消除。
【数据范围】
对于 30 % 30\% 30% 的数据,初始棋盘上的方块都在棋盘的最下面一行;
对于 100 % 100\% 100% 的数据, 0 < n ≤ 5 0
题解
解题思路
此题就相当与是一道大型搜索模拟题,需要耐心,极考验码力;
因为代码比较长,所以建议大家多写函数,尽量不要都写在一起;
核心函数:
1.copy(复制):
我们要把当前的原始状态复制,回溯时要用;但不能使用二维数组了,要定义一个三维数组last[d][i][j],表示第d步时在i行j列的原状态;
2.update(更新游戏的状态):
就是把该掉下去的掉下去,定义一个x为这个这个方块下0的个数,然后模拟一下;
3.remove(消除):
题目要求一定要行或列连续3个才能消除, 但一定不能遇到3个连续的就消;
4.move (移动):
注意,可能消除后还可以更新,所以要使用while循环;
5.check(判断是否都消除了):
所有方块都掉落了,直接判断最后一行是否都为0;
DFS的剪枝:
相同颜色的方块可以跳过(显而易见);
只有右边有方块才move,左边没有方块才move;
考点
模拟 搜索 剪枝
时间复杂度
O ( N 2 ) O(N^2) O(N2)
AC代码
#pragma GCC optimize(2)
#include [NOIP2011 提高组] 计算系数
题目:[NOIP2011 提高组] 计算系数
题目描述
给定一个多项式 ( b y + a x ) k (by+ax)^k (by+ax)k,请求出多项式展开后 x n × y m x^n\times y^m xn×ym 项的系数。
输入格式
输入共一行,包含 5 5 5 个整数,分别为 a , b , k , n , m a,b,k,n,m a,b,k,n,m,每两个整数之间用一个空格隔开。
输出格式
输出共一行,包含一个整数,表示所求的系数。
这个系数可能很大,输出对 10007 10007 10007 取模后的结果。
样例 #1
样例输入 #1
1 1 3 1 2
样例输出 #1
3
提示
【数据范围】
对于 30 % 30\% 30% 的数据,有 0 ≤ k ≤ 10 0\le k\le 10 0≤k≤10。
对于 50 % 50\% 50% 的数据,有 a = 1 a=1 a=1, b = 1 b=1 b=1。
对于 100 % 100\% 100% 的数据,有 0 ≤ k ≤ 1000 0\le k\le 1000 0≤k≤1000, 0 ≤ n , m ≤ k 0\le n,m\le k 0≤n,m≤k, n + m = k n+m=k n+m=k, 0 ≤ a , b ≤ 1 0 6 0\le a,b\le 10^6 0≤a,b≤106。
noip2011 提高组 day2 第 1 题。
题解
解题思路
本题是一个很简单的数学推理题
根据二项式定理
( a + b ) n = ∑ k = 0 n C n k a k b n − k (a+b)^n=\sum_{k=0}^nC_{n}^{k}a^kb^{n-k} (a+b)n=k=0∑nCnkakbn−k
那么
( a x + b y ) k = ∑ p = 0 k C k p ( a x ) p ( b y ) k − p = ∑ p = 0 k ( C k p a p b k − p ) x p y k − p (ax+by)^k=\sum_{p=0}^kC_{k}^p(ax)^p(by)^{k-p}=\sum_{p=0}^k(C_{k}^pa^pb^{k-p})x^py^{k-p} (ax+by)k=p=0∑kCkp(ax)p(by)k−p=p=0∑k(Ckpapbk−p)xpyk−p
算 a n , b m a^n,b^m an,bm需要用快速幂
1、可以根据组合式的递推公式算组合数
C n m = C n − 1 m + C n − 1 m − 1 C_n^m=C_{n-1}^m+C_{n-1}^{m-1} Cnm=Cn−1m+Cn−1m−1
2、或者是利用组合数的定义式,但是因为有取余, 所以要用逆元
C n m = n ! m o d 10007 m ! ( n − m ) ! m o d 10007 = n ! × [ m ! ( n − m ) ! ] − 1 m o d 10007 C_n^m=\frac{n!\mod 10007}{m!(n-m)!\mod 10007}=n!\times [m!(n-m)!]^{-1}\mod 10007 Cnm=m!(n−m)!mod10007n!mod10007=n!×[m!(n−m)!]−1mod10007
其中 [ m ! ( n − m ) ! ] − 1 [m!(n-m)!]^{-1} [m!(n−m)!]−1为逆元, 可以直接用费马小定理,最后求得 a n s ans ans的值
考点
数学
时间复杂度
O ( N ! ) O(N!) O(N!)
AC代码
#pragma GCC optimize(2)
#include [NOIP2011 提高组] 聪明的质监员
题目:[NOIP2011 提高组] 聪明的质监员
题目描述
小T 是一名质量监督员,最近负责检验一批矿产的质量。这批矿产共有 n n n 个矿石,从 1 1 1 到 n n n 逐一编号,每个矿石都有自己的重量 w i w_i wi 以及价值 v i v_i vi 。检验矿产的流程是:
1 、给定$ m$ 个区间 [ l i , r i ] [l_i,r_i] [li,ri];
2 、选出一个参数 W W W;
3 、对于一个区间 [ l i , r i ] [l_i,r_i] [li,ri],计算矿石在这个区间上的检验值 y i y_i yi:
y i = ∑ j = l i r i [ w j ≥ W ] × ∑ j = l i r i [ w j ≥ W ] v j y_i=\sum\limits_{j=l_i}^{r_i}[w_j \ge W] \times \sum\limits_{j=l_i}^{r_i}[w_j \ge W]v_j yi=j=li∑ri[wj≥W]×j=li∑ri[wj≥W]vj
其中 j j j 为矿石编号。
这批矿产的检验结果 y y y 为各个区间的检验值之和。即: ∑ i = 1 m y i \sum\limits_{i=1}^m y_i i=1∑myi
若这批矿产的检验结果与所给标准值 s s s 相差太多,就需要再去检验另一批矿产。小T 不想费时间去检验另一批矿产,所以他想通过调整参数 W W W 的值,让检验结果尽可能的靠近标准值 s s s,即使得 ∣ s − y ∣ |s-y| ∣s−y∣ 最小。请你帮忙求出这个最小值。
输入格式
第一行包含三个整数 n , m , s n,m,s n,m,s,分别表示矿石的个数、区间的个数和标准值。
接下来的 n n n 行,每行两个整数,中间用空格隔开,第 i + 1 i+1 i+1 行表示 i i i 号矿石的重量 w i w_i wi 和价值 v i v_i vi。
接下来的 m m m 行,表示区间,每行两个整数,中间用空格隔开,第 i + n + 1 i+n+1 i+n+1 行表示区间 [ l i , r i ] [l_i,r_i] [li,ri] 的两个端点 l i l_i li 和 r i r_i ri。注意:不同区间可能重合或相互重叠。
输出格式
一个整数,表示所求的最小值。
样例 #1
样例输入 #1
5 3 15
1 5
2 5
3 5
4 5
5 5
1 5
2 4
3 3
样例输出 #1
10
提示
【输入输出样例说明】
当 W W W 选 4 4 4 的时候,三个区间上检验值分别为 20 , 5 , 0 20,5 ,0 20,5,0 ,这批矿产的检验结果为 25 25 25,此时与标准值 S S S 相差最小为 10 10 10。
【数据范围】
对于 10 % 10\% 10% 的数据,有 1 ≤ n , m ≤ 10 1 ≤n ,m≤10 1≤n,m≤10;
对于 30 % 30\% 30%的数据,有 1 ≤ n , m ≤ 500 1 ≤n ,m≤500 1≤n,m≤500 ;
对于 50 % 50\% 50% 的数据,有 1 ≤ n , m ≤ 5 , 000 1 ≤n ,m≤5,000 1≤n,m≤5,000;
对于 70 % 70\% 70% 的数据,有 1 ≤ n , m ≤ 10 , 000 1 ≤n ,m≤10,000 1≤n,m≤10,000 ;
对于 100 % 100\% 100% 的数据,有 1 ≤ n , m ≤ 200 , 000 1 ≤n ,m≤200,000 1≤n,m≤200,000, 0 < w i , v i ≤ 1 0 6 0 < w_i,v_i≤10^6 0<wi,vi≤106, 0 < s ≤ 1 0 12 0 < s≤10^{12} 0<s≤1012, 1 ≤ l i ≤ r i ≤ n 1 ≤l_i ≤r_i ≤n 1≤li≤ri≤n 。
题解
解题思路
这个题很明显的二分枚举,但是还有一个前缀和有点坑人。
这题题其实点不多,就两个关键点:
1、二分的判断。
可以看到:在W取0时,所有的区间内的矿石都可以选上,而在W大于最大的质量时,所有的矿石都选不上。
然后简单算一下就发现:
W越大,矿石选的越少,W越小,矿石选的越多。
所以,随着W增大,Y值减小;
二分的判断条件出来了:
当 Y > s Y>s Y>s时,需要增大 W W W来减小 Y Y Y,从而 ∣ Y − s ∣ ∣Y−s∣ ∣Y−s∣变小;
当 Y = = s Y==s Y==s时, ∣ Y − s ∣ = = 0 ∣Y−s∣==0 ∣Y−s∣==0;
当 Y < s YY<s时,需要减小 W W W来增大 Y Y Y,从而 ∣ Y − s ∣ ∣Y−s∣ ∣Y−s∣变大;
2、前缀和。
我们在计算一个区间的和时(虽然这里是两个区间和再相乘,但没关系)
通常是用前缀和的方法来缩减时间,直接模拟是 n 2 n^2 n2的,而前缀和成了 2 × 2\times 2× n n n,这样大大的优化了时间
很显然:
w [ i ] ≥ W w[i]≥W w[i]≥W时这个 i i i矿石会在统计里(若 w [ i ] < W w[i]
矿石价值和是: p r e v [ i ] = p r e v [ i − 1 ] + v [ i ] pre_v[i]=pre_v[i-1]+v[i] prev[i]=prev[i−1]+v[i],前面的和加上当前这一个i矿石;
矿石数量和是: p r e n [ i ] = p r e n [ i − 1 ] + 1 pre_n[i]=pre_n[i-1]+1 pren[i]=pren[i−1]+1
最后算的时候用 r − ( l − 1 ) r-(l-1) r−(l−1)就可以了
考点
数学 二分 前缀和
时间复杂度
O ( N ) O(N) O(N)
AC代码
#pragma GCC optimize(2)
#include [NOIP2011 提高组] 观光公交
题目:[NOIP2011 提高组] 观光公交
题目背景
感谢 @Transhumanist 提供的一组 Hack 数据
题目描述
风景迷人的小城 Y 市,拥有 n n n 个美丽的景点。由于慕名而来的游客越来越多,Y 市特意安排了一辆观光公交车,为游客提供更便捷的交通服务。观光公交车在第 0 0 0 分钟出现在 1 1 1 号景点,随后依次前往 2 , 3 , 4 , ⋯ , n 2,3,4,\cdots,n 2,3,4,⋯,n 号景点。从第 i i i 号景点开到第 i + 1 i+1 i+1 号景点需要 D i D_i Di 分钟。任意时刻,公交车只能往前开,或在景点处等待。
设共有 m m m 个游客,每位游客需要乘车 1 1 1 次从一个景点到达另一个景点,第 i i i 位游客在 T i T_i Ti 分钟来到景点 A i A_i Ai,希望乘车前往景点 B i B_i Bi( A i < B i A_i
假设乘客上下车不需要时间。一个乘客的旅行时间,等于他到达目的地的时刻减去他来到出发地的时刻。因为只有一辆观光车,有时候还要停下来等其他乘客,乘客们纷纷抱怨旅行时间太长了。于是聪明的司机 ZZ 给公交车安装了 k k k 个氮气加速器,每使用一个加速器,可以使其中一个 D i − 1 D_i-1 Di−1。对于同一个 D i D_i Di 可以重复使用加速器,但是必须保证使用后 D i ≥ 0 D_i\ge0 Di≥0。
那么 ZZ 该如何安排使用加速器,才能使所有乘客的旅行时间总和最小?
输入格式
第 1 1 1 行是 3 3 3 个整数 n , m , k n,m,k n,m,k,每两个整数之间用一个空格隔开。分别表示景点数、乘客数和氮气加速器个数。
第 2 2 2 行是 n − 1 n-1 n−1 个整数,每两个整数之间用一个空格隔开,第 i i i 个数表示从第 i i i 个景点开往第 i + 1 i+1 i+1 个景点所需要的时间,即 D i D_i Di。
第 3 3 3 行至 m + 2 m+2 m+2 行每行 3 3 3 个整数 T i , A i , B i T_i,A_i,B_i Ti,Ai,Bi,每两个整数之间用一个空格隔开。第 i + 2 i+2 i+2 行表示第 i i i 位乘客来到出发景点的时刻,出发的景点编号和到达的景点编号。
输出格式
一个整数,表示最小的总旅行时间。
样例 #1
样例输入 #1
3 3 2
1 4
0 1 3
1 1 2
5 2 3
样例输出 #1
10
提示
【输入输出样例说明】
对 D 2 D_2 D2 使用 2 2 2 个加速器,从 2 2 2 号景点到 3 3 3 号景点时间变为 2 2 2 分钟。
公交车在第 1 1 1 分钟从 1 1 1 号景点出发,第 2 2 2 分钟到达 2 2 2 号景点,第 5 5 5 分钟从 2 2 2 号景点出发,第 7 7 7 分钟到达 3 3 3 号景点。
第 1 1 1 个旅客旅行时间 7 − 0 = 7 7-0=7 7−0=7 分钟。
第 2 2 2 个旅客旅行时间 2 − 1 = 1 2-1=1 2−1=1 分钟。
第 3 3 3 个旅客旅行时间 7 − 5 = 2 7-5=2 7−5=2 分钟。
总时间 7 + 1 + 2 = 10 7+1+2=10 7+1+2=10 分钟。
【数据范围】
对于 10 % 10\% 10% 的数据, k = 0 k=0 k=0。
对于 20 % 20\% 20% 的数据, k = 1 k=1 k=1。
对于 40 % 40\% 40% 的数据, 2 ≤ n ≤ 50 2 \le n \le 50 2≤n≤50, 1 ≤ m ≤ 1 0 3 1 \le m \le 10^3 1≤m≤103, 0 ≤ k ≤ 20 0 \le k \le 20 0≤k≤20, 0 ≤ D i ≤ 10 0 \le D_i \le 10 0≤Di≤10, 0 ≤ T i ≤ 500 0 \le T_i \le 500 0≤Ti≤500。
对于 60 % 60\% 60% 的数据, 1 ≤ n ≤ 100 1 \le n \le 100 1≤n≤100, 1 ≤ m ≤ 1 0 3 1 \le m \le 10^3 1≤m≤103, 0 ≤ k ≤ 100 0 \le k \le 100 0≤k≤100, 0 ≤ D i ≤ 100 0 \le D_i \le 100 0≤Di≤100, 0 ≤ T i ≤ 1 0 4 0 \le T_i \le 10^4 0≤Ti≤104。
对于 100 % 100\% 100% 的数据, 1 ≤ n ≤ 1 0 3 1 \le n \le 10^3 1≤n≤103, 1 ≤ m ≤ 1 0 4 1 \le m \le 10^4 1≤m≤104, 0 ≤ k ≤ 1 0 5 0 \le k \le 10^5 0≤k≤105, 0 ≤ D i ≤ 100 0 \le D_i \le 100 0≤Di≤100, 0 ≤ T i ≤ 1 0 5 0 \le T_i \le 10^5 0≤Ti≤105。
题解
解题思路
这个题看起来可以用dp做,但是能不能做就是另一回事了,但是现在知道它可以用贪心做。它是怎么做的呢?实际上非常好考虑
首先,每使用一次氮气加速时,目前在车上的有些人旅行时间会变短,有些人会不变,因为乘客上车的时间是不会改变的,所以可能会在后面的某一站整车人都需要等一个乘客上车(判断这个东西可以通过判断从上一个点到达它的时间,和最晚的乘客到达它的时间,通过预处理完成这些操作])
在这之前下车的人旅行时间会变短,因此实际上这次氮气加速只对不会受到等人上车影响的人有效,也就是在它们上车之后直到下车都不会在某个站等别人上车的人是氮气加速的受益者
因此想要快速处理这些问题,我们需要一个站最近的需要等人的站,一个站被到达的时间和在这个站接完所有乘客的时间,因为一次加速的受益者是在加速后和到达需要等人的站之间下车的人数,那么还需要通过前缀和快速求出在某段时间下车的人数(其实就是在等人站下车及其之前下车的人数减去加速之前下车的人数)
然后在每次加速之后,两个站之间的行驶时间被改变了,那么其它站被到达(并且接到所有乘客)的时间也可能被改变了,所以需要重新更新一下一个站被到达的时间和接完人的时间
考点
贪心 递推
时间复杂度
O ( N 2 ) O(N^2) O(N2)
AC代码
#pragma GCC optimize(2)
#include 本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!