GSANet-全局自注意力网络 | GLOBAL SELF-ATTENTION NETWORKS FOR IMAGE RECOGNITION
论文地址:https://arxiv.org/pdf/2010.03019.pdf

ABSTRACT:
近来,计算机视觉领域的一系列工作已经显示出在各种图像和视频理解任务上利用self-attention的卓越成果。但是,由于self-attention的二次计算和存储复杂性,这些工作要么仅将注意力应用于深层网络后期的低分辨率特征图,要么将每层的注意力感受野限制在较小的局部区域。为了克服这些限制,这项工作引入了一个新的全局自注意模块,称为GSA模块,该模块足够高效,可以用作深度网络的骨干组件。该模块由两个并行层组成:一个内容注意力层,仅基于像素的内容对其进行关注;一个位置注意力层,其基于像素的空间位置进行关注。该模块的输出是两层输出的总和。基于提出的GSA模块,我们提出了新的独立的,基于全局注意力的深度网络,该网络使用GSA模块而非卷积来建模像素交互。由于所提出的GSA模块的全局范围,GSA网络具有对整个网络中的远程像素交互进行建模的能力。我们的实验结果表明,在使用更少的参数和计算量的情况下,GSA网络在CIFAR 100和ImageNet数据集上的性能明显优于相应的基于卷积的网络。提出的GSA网络在ImageNet数据集上也胜过各种现有的基于注意力的网络。
GSA:
A. Motivation:
传统self-attention由于其二次的计算量,导致其无法在CNN中的所有层应用,一般只应用在网络尾部特征分辨率比较小的位置,这就无法充分挖掘self-attention的全部潜力。
B. GSA module:
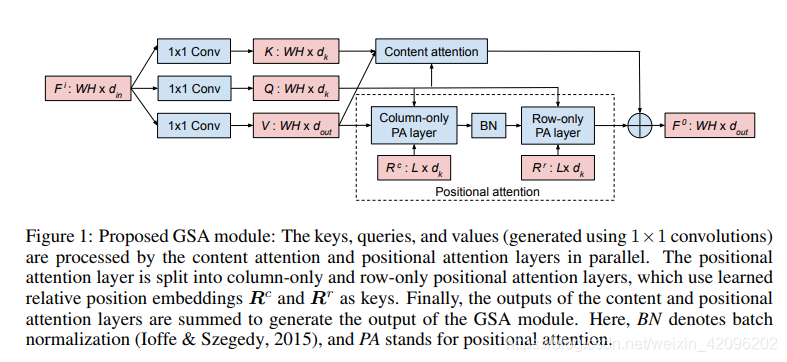
本文提出的全局自注意力模块(GSA模块)如上图所示,主要包含两个并行分支:
1.内容注意力层:

与常规的self-attention操作类似,公式中的ρ表示对每行分别应用softmax归一化的操作。 可以将这种注意力操作解读为首先使用ρ中的权重将V中的像素特征聚合为dk长度的全局上下文向量,然后使用Q中的权重将全局上下文向量重新分配回单个像素。此操作的计算和存储复杂度为O (N)。
2.位置注意力层:
由于内容注意力层未考虑像素的空间位置,因此与像素混洗等效。 因此,就其本身而言,它并不是最适合处理空间结构数据(例如图像)的任务。
对于每个像素,位置注意层都遵循其L×L空间相邻元素,受轴向公式的启发,将该关注层实现为仅列注意力层,然后是仅行注意力层。 在仅列注意力层中,输出像素仅沿其列关注输入像素,而在仅行注意层中,输出像素仅沿其行关注输入像素。 这种先后按行和列注意力层的叠加,实际上会导致整个L×L邻域中的信息传播。
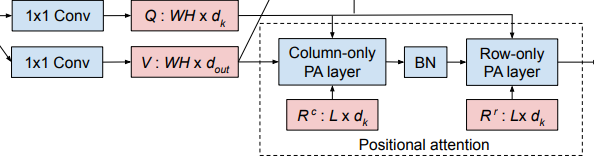

对于WH x d的特征图上,像素点(a,b)的仅列注意力公式如上图所示:
V:表示在Value特征图的(a,b)像素点的同一列上取L长度的矩阵(-L/2 到 L/2),尺寸为L x dout
R:表示对应于沿着列的L个空间偏移可学习的相对位置嵌入的矩阵?感觉是学习Query上(a,b)上的L个相对位置偏移?
q:Query特征图(a,b)像素点的值
3.现有注意力特性:
可以看出GSA是全局+内容+位置3个注意力的集合
C. GSANet:
GSA-ResNet-50:该网络是通过使用提出的GSA模块替换ResNet-50中的所有3×3卷积层获得。网络采用224×224的输入大小,并且为了减小空间尺寸,在第二,第三和第四残差组中的第一个GSA模块之后立即使用2×2个平均池化层(步长为2)。 每个GSA模块中K,Q,V的通道数设置为与相应的输入特征相同。网络使用多头注意机制,每个GSA模块中都有8个head。 相对位置嵌入在模块内的所有head之间共享,但在模块间不共享。 所有1×1卷积和GSA模块之后均进行批处理归一化
EXPERIMENTS:
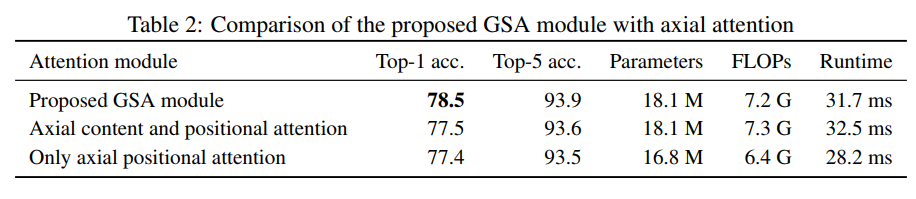
1.与现有轴向注意力比较:
2.ImageNet: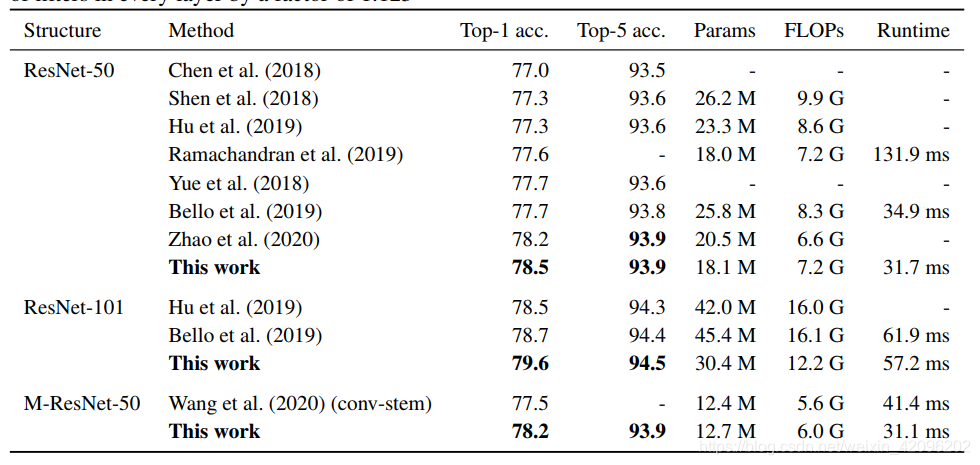
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!