V8 与NodeJS
V8
HandleScope 与 isolate 以及内存之间的关系
下面一张图片比较全面的展示出来 HandleScope 与内存之间的关系,
该图片来自知乎博客, 原链接: https://zhuanlan.zhihu.com/p/67974515
图中 HandleScopeData 和 HandleScope 指向的是同一个指针位。

-
isolate 可以认为是V8的一个实例,它具有v8运行的完整环境和参数,你可以认为每个线程都有一个isolate, 当然isolate这个名字已经告诉我们,在不同isolate之间的对象,状态,内存等都是不共享的。
-
HandleScope 一个内存管理对象,当他创建时会记录当前可用的下一个内存,而析构时会释放内存。
因此在HandleScope 离开生命周期时,在此期间创建的所有Handle都可以被释放,(实际上是引用关系被清除), 另外很重要的一点是HandleScope 是可嵌套的。- CreateHandle 创建一个Handle,但实际上是将已经存在对象放到内存管理区域。 Handle::New 方法实际上也是调用这CreateHandle。
- Extend 如果当前block块不够用了,创建一个新的block 或者获取当前最后一个可用block.
- CloseScope 清除掉当前 handleScope 管理的所有内存,在HandleScope的析构时调用。
- CloseAndEscape 和上一个相同也是清除 HandleScope 管理的内存,不过它允许在将一个 Handle 返回给上一级的 HandleScope.
下面会分析这一套内存管理机制
-
HandleScopeImplementer 这个名字让人摸不清头脑,但实际上他是一个内存分配器. 同时还管理着后面的Context对象。其持有一个Vector
即真正的对象仍分散在堆上,且由GC管理,这里只是保存这些堆上对象的指针,当block_清空时,也只是修改了对象的到根节点的引用情况,真正的内存释放仍需要等待GC的sweap真实内存是由isolate::factory 分配的内存的分配以block为最小单位,每个block的大小为1022个字节,这个数字明显是为了 4K 对齐, 因为在linux系统中一个内存页的大小是 4K,因此当内存大小超过4k时会引发两个缺页中断。但什么少了两个字节需要进一步研究。
-
GetSpareOrNewBlock 来创建或者获取一块空闲的block, 成员变量 spare_ 记录着当前空闲的block
-
DeleteExtensions 从blocks_尾部删除block
-
SaveContext/RestoreContext Context相关操作,
-
EnterContext/LeaveContext
-
-
HandleScopeData 是Iosolate 的另一个成员, 有两个指针 next 和 limit, 分别指向当前 HandleScopeImplementer 下一个可用内存 以及 当前块的最后一个可用内存, level 记录了 HandleScope 的嵌套层级。
Object 相关
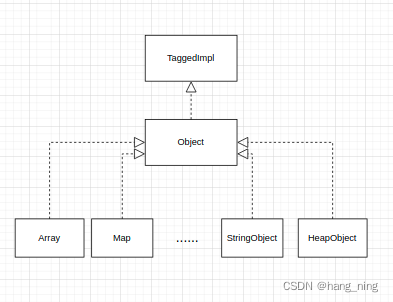
Object 继承结构如下,它继承TaggedImpl模板,而Obejct 又派生出一些具体类,Object的构造函数是protected的,这就意味着Object不能单独实例化。
Object派生类 包括: Smi, Array, ArrayBuffer, NumberObject, BigIntObject, BooleanObject,StringObject,SymbolObject,Date,
Map, Function, Promise, Resolver, Proxy, WasmMemoryObject, WasmModuleObject, SharedArrayBuffer, ArrayBufferView,RegExp, FieldType,TaggedIndex,HeapObject。等
可以看出V8中所有的变量继承自Object,如何将数字和字符串以及其他类型塞到同一个对象里,v8在这块使用了很多技巧,例如为了不生成虚函数表,Object没有virtual方法。
虚函数的调用比普通函数要慢一些,这也看出v8为了效率,不放过每一个优化点,具体解释可以参考 https://www.zhihu.com/question/22958966
TaggedImpl 与 Smi
TaggedImpl 只有一个变量 uintptr_t类型的 ptr_, 也就是一个void* 指针, 在64位机器上占8个字节。v8 把数字 和 指针都合并到了这个 ptr_ 变量中, 这样的数字被称为Smi。
那如何区分一个 ptr_ 是 smi 还是 指针呢?我们知道无论32位还是64位系统,指针的值总是4的倍数,也就是偶数, 我们可以利用这个性质来进行判断。
如果最后一位是0, 则代表这是一个smi, smi只取高32位的bit位,即需要向左移32位, 32 位系统中左移一位,即 使用31bit存储
如果最后一位是1, 则代表储存了指针,但这不是一个有效指针,需要将 ptr-1, 才能得到真实的指针
注意这里的 smi 是数字而不是仅是整数,这就意味着,smi中也可以存储32位的double类型数据,一切可以用32个bit编码的数字和其他类型都可以放到里面
// src/object/tagged-impl-inl.hconstexpr bool IsSmi() const { return HAS_SMI_TAG(ptr_); }// 其中 smiTagMask = 1 smiTag = 0
#define HAS_SMI_TAG(value) \((static_cast<i::Tagged_t>(value) & ::i::kSmiTagMask) == ::i::kSmiTag)// src/include/v8-internal.h
// 其中 kSmiTag = 1 kSmiShiftSize = 31
V8_INLINE static constexpr internal::Address IntToSmi(int value) {return (static_cast<Address>(value) << (kSmiTagSize + kSmiShiftSize)) |kSmiTag;
}// Address 是 uintptr_t的别称
V8_INLINE static int SmiToInt(const internal::Address value) {int shift_bits = kSmiTagSize + kSmiShiftSize;// Shift down and throw away top 32 bits.return static_cast<int>(static_cast<intptr_t>(value) >> shift_bits);
}
对于指针,通过对最后一位加减1即可,这里对于指针的操作可能让你感到困惑。但其实可以这样理解:
在Object中的ptr_是某个指针的储存形态,需要加1用来区别smi,而通过接口获取的Address是指针的调用形态,是直接指向了某个对象实例。 这是需要定义 Address 这个别称的原因。
// Converts an address to a HeapObject pointer.static inline HeapObject FromAddress(Address address) {DCHECK_TAG_ALIGNED(address);return HeapObject(address + kHeapObjectTag);}// Returns the address of this HeapObject.inline Address address() const { return ptr() - kHeapObjectTag; }
HeapObject 与 ObjectType
上一节讲到,Object是没有虚函数和多态机制的,当Object中储存的是一个指针时, **无法通过重载 isXXX ** 的方法来告诉调用者这个HeapObject具体是什么类型,那么Object中众多的使用宏定义的 ISxxxType 方法是如何实现的呢?
实际上是通过向上寻找到root, 然后通过root来判断当前对象是什么类型
// 宏定义bool Object::Is##type_() const { \return IsHeapObject() && HeapObject::cast(*this).Is##type_(); \} bool HeapObject::Is##Type() const { return Is##Type(GetReadOnlyRoots()); }bool HeapObject::Is##Type(ReadOnlyRoots roots) const { \return Object::Is##Type(roots); \} bool Object::Is##Type(ReadOnlyRoots roots) const { \return *this == roots.Value(); \}
从众多宏定义中找到这几个关键定义,可以看出,Object首先通过GetReadOnlyRoots方法获取Root对象,然后通过Root对象的 Is##Type 方法来判断 root 对象属于哪个类型。下面来看看关键的 GetReadOnlyRoots 是如何实现的。
// src/heap/read-only-heap-inl.h
ReadOnlyRoots ReadOnlyHeap::GetReadOnlyRoots(HeapObject object) {
#ifdef V8_COMPRESS_POINTERS_IN_ISOLATE_CAGEreturn ReadOnlyRoots(Isolate::FromRootAddress(GetIsolateRootAddress(object.ptr())));
#else
#ifdef V8_SHARED_RO_HEAP// This fails if we are creating heap objects and the roots haven't yet been// copied into the read-only heap.auto* shared_ro_heap = SoleReadOnlyHeap::shared_ro_heap_;if (shared_ro_heap != nullptr && shared_ro_heap->init_complete_) {return ReadOnlyRoots(shared_ro_heap->read_only_roots_);}
#endif // V8_SHARED_RO_HEAPreturn ReadOnlyRoots(GetHeapFromWritableObject(object));
#endif // V8_COMPRESS_POINTERS
}V8 初始化时会为每一个类型的Object 生成一个根对象地址, GC时就从这个根节点检查可达性。
获取根节点这部分代码使用了两个宏三种模式来处理,这说明v8的开发者们对这块使用什么样的实现方案还没有达到共识。
V8_COMPRESS_POINTERS_IN_ISOLATE_CAGE 这个宏暂时是关闭的, 这个方案主要思想是将 指针分为两部分,高32位是根对象的地址,低32位储存当前指向对象的地址。
下面我们来看看 GetHeapFromWritableObject 实现
V8_INLINE Heap* GetHeapFromWritableObject(HeapObject object) {// Avoid using the below GetIsolateFromWritableObject because we want to be// able to get the heap, but not the isolate, for off-thread objects.#if defined V8_ENABLE_THIRD_PARTY_HEAPreturn Heap::GetIsolateFromWritableObject(object)->heap();
#elif defined V8_COMPRESS_POINTERS_IN_ISOLATE_CAGEIsolate* isolate =Isolate::FromRootAddress(GetIsolateRootAddress(object.ptr()));DCHECK_NOT_NULL(isolate);return isolate->heap();
#elseheap_internals::MemoryChunk* chunk =heap_internals::MemoryChunk::FromHeapObject(object);return chunk->GetHeap();
#endif // V8_COMPRESS_POINTERS_IN_ISOLATE_CAGE, V8_ENABLE_THIRD_PARTY_HEAP
}// src/heap/heap-write-barrier-inl.h
V8_INLINE static heap_internals::MemoryChunk* FromHeapObject(HeapObject object) {DCHECK(!V8_ENABLE_THIRD_PARTY_HEAP_BOOL);// 其中 kPageAlignmentMask 是 0x0003ffff 即低18位都是1,取反即取高46位return reinterpret_cast<MemoryChunk*>(object.ptr() & ~kPageAlignmentMask);
}V8_INLINE Heap* GetHeap() {Heap* heap = *reinterpret_cast<Heap**>(reinterpret_cast<Address>(this) +kHeapOffset); // 16DCHECK_NOT_NULL(heap);return heap;}V8_INLINE bool IsMarking() const { return GetFlags() & kMarkingBit; } //右数第19位V8_INLINE uintptr_t GetFlags() const {return *reinterpret_cast<const uintptr_t*>(reinterpret_cast<Address>(this) +kFlagsOffset);//8}V8_INLINE bool InYoungGeneration() const {if (V8_ENABLE_THIRD_PARTY_HEAP_BOOL) return false;constexpr uintptr_t kYoungGenerationMask = kFromPageBit | kToPageBit;return GetFlags() & kYoungGenerationMask;}这一部分和GC的设计比较紧密,思想是相同的,也是将ptr的高低位分成两个部分,高位保存一些状态值,低位才是真正的指针。 由 kPageAlignmentMask = 1<<18-1 以及命名来说,我们大致可以猜测出v8的内存回收是按照页式储蓄结构,一个页大概是 1<<18 = 256k, MemoryChunk 可能指向的就是当前页的页首位置。
对于这一部分的代码我们虽然没有太深入分析,但总体可以得出两个结论:
1 某些宏开启时,其存储的ptr_指针不完全是指针, 其高位的一部分比特位是有特殊用处的。
2 默认模式下,GC堆内存可能是按照页式储存和管理的,即可以通过某些位运算方法从 object.ptr 获取到页首指针位置。而且根据 IsMaring 的实现方案, v8的内存回收机制很有可能是按页回收的(猜想)。
3 无论那种方法,判断Object类型的方法是通过其ptr_的特征向上寻找到根对象,使用根对象的地址来判断当前Object是什么类型。
其它
RootsTable 保存着全部类型Object的根对象,其被isolate持有。
新对象的接口在 V8.h中,但实际创建的是使用 factory 对象的接口, factory同样被isolate持有。最终会调用到 Heap::AllocateRawWith (以Array类型的对象为例)。Heap对象寻找自己管理的空间中第一个位置,然后使用 CreateFillerObjectAt 方法对申请的内存进行初始化。
template <Heap::AllocationRetryMode mode>
HeapObject Heap::AllocateRawWith(int size, AllocationType allocation,AllocationOrigin origin,AllocationAlignment alignment) {DCHECK(AllowHandleAllocation::IsAllowed());DCHECK(AllowHeapAllocation::IsAllowed());DCHECK_EQ(gc_state(), NOT_IN_GC);Heap* heap = isolate()->heap();if (allocation == AllocationType::kYoung &&alignment == AllocationAlignment::kWordAligned &&size <= MaxRegularHeapObjectSize(allocation) && !FLAG_single_generation) {Address* top = heap->NewSpaceAllocationTopAddress();Address* limit = heap->NewSpaceAllocationLimitAddress();if ((*limit - *top >= static_cast<unsigned>(size)) &&V8_LIKELY(!FLAG_single_generation && FLAG_inline_new &&FLAG_gc_interval == 0)) {DCHECK(IsAligned(size, kTaggedSize));HeapObject obj = HeapObject::FromAddress(*top);*top += size;heap->CreateFillerObjectAt(obj.address(), size, ClearRecordedSlots::kNo);MSAN_ALLOCATED_UNINITIALIZED_MEMORY(obj.address(), size);return obj;}}switch (mode) {case kLightRetry:return AllocateRawWithLightRetrySlowPath(size, allocation, origin,alignment);case kRetryOrFail:return AllocateRawWithRetryOrFailSlowPath(size, allocation, origin,alignment);}UNREACHABLE();
}
PS : V8在Object 和 内存分配这块使用了海量的宏定义,导致很难梳理出准确的逻辑关系,因此上述中包含一定的个人猜测,不保证正确。
NodeJS NAPI
NAPI 是 nodeJS 开发出来的一组接口,目的是为了让第三方开发者可以比较便捷的开发插件,而不需要知道v8或者其他js引擎的细节。首先给出一个简单的例子#include // js 调用 demovar addon = require("./build/Release/hello");console.log(addon.hello());// 输出 world
我们在cpp文件中定义并注册了一个模块叫做 hello, 他的对外暴露一个叫做 hello 的js方法,绑定的是cpp中的 HelloMethod 方法。当调用hello方法时,我们返回"world"字符串。
下面我们先按照顺序分析下NAPI的部分实现细节:
napi_value
typedef struct napi_env__* napi_env;
typedef struct napi_value__* napi_value;
typedef struct napi_ref__* napi_ref;
typedef struct napi_handle_scope__* napi_handle_scope;
typedef struct napi_escapable_handle_scope__* napi_escapable_handle_scope;
typedef struct napi_callback_info__* napi_callback_info;
typedef struct napi_deferred__* napi_deferred;
NAPI类型的宏定义,其中 napi_env_ 是一个context的包装。而其他的类型如napi_value_, 你会发现翻遍整个项目也没有这个类的定义,这是因为 C语言允许使用一个未定义的结构体指针,由于该结构体尚未定义,因此没有具体的指针类型,也就是 void* , 实际上上述 napi_value, napi_ref 等类型其实都是 void*.
之所以给他们进行封装,是为了不同指针之间的区别,虽然代表的都是void指针,但是在 napi_value 和 napi_ref之间是不能进行隐式转换的。
napi_property_descriptor
napi_property_descriptor 是一个属性的描述符,他可以是一个普通函数,绑定method函数指针, 也可以是一个属性接受一个get 方法和 setter方法 对data进行处理, 甚至也可以直接暴露一个变量value。
napi_property_attributes 是该属性的一些标志位,例如可读可写等。
typedef napi_value (*napi_callback)(napi_env env,napi_callback_info info);typedef struct {// One of utf8name or name should be NULL.const char* utf8name;napi_value name;napi_callback method;napi_callback getter;napi_callback setter;napi_value value;napi_property_attributes attributes;void* data;
} napi_property_descriptor;napi_define_properties
CHECK_TO_OBJECT 将传入参数object 转成Local,接下来遍历传入的properties数组,依次给这个obj对象添加属性。可以看出这里属性分为三类:1 setter getter 2 普通函数 3 变量。
最终通过 V8::PropertyDescriptor 和 DefineProperty 注册到obj对象中。
NAPI_MODULE
最后通过NAPI_MOUDULE的模板将这个自定义模块进行加载。
#define NAPI_MODULE(modname, regfunc) \NAPI_MODULE_X(modname, regfunc, NULL, 0) // NOLINT (readability/null_usage)
#endif#define NAPI_MODULE_X(modname, regfunc, priv, flags) \EXTERN_C_START \static napi_module _module = \{ \NAPI_MODULE_VERSION, \flags, \__FILE__, \regfunc, \#modname, \priv, \{0}, \}; \NAPI_C_CTOR(_register_ ## modname) { \napi_module_register(&_module); \} \EXTERN_C_END......typedef napi_value (*napi_addon_register_func)(napi_env env,napi_value exports);typedef struct napi_module {int nm_version;unsigned int nm_flags;const char* nm_filename;napi_addon_register_func nm_register_func;const char* nm_modname;void* nm_priv;void* reserved[4];
} napi_module;NAPI_MODULE_X 首先定义一个_module对象,由于是 static, 作用域仅在当前文件 所以不存在重名问题。
且整个代码段处在 extern c作用域里,因此定义的函数可以生成符号表。
// NAPI_C_CTOR(_register_ ## modname) { \
// napi_module_register(&_module); \
// } #define NAPI_C_CTOR(fn) \static void fn(void) __attribute__((constructor)); \static void fn(void)
#endifvoid napi_module_register(napi_module* mod) {node::node_module* nm = new node::node_module(node::napi_module_to_node_module(mod));node::node_module_register(nm);
}// node_bindings.cc
extern "C" void node_module_register(void* m) {struct node_module* mp = reinterpret_cast<struct node_module*>(m);// 内建模块分支,头插法if (mp->nm_flags & NM_F_INTERNAL) {mp->nm_link = modlist_internal;modlist_internal = mp;} else if (!node_is_initialized) {// "Linked" modules are included as part of the node project.// Like builtins they are registered *before* node::Init runs.mp->nm_flags = NM_F_LINKED;mp->nm_link = modlist_linked;modlist_linked = mp;} else {// 插件情况,走这个分支thread_local_modpending = mp;}
}最后这一段,定义了一个名为 register ## MODE_NAME 的导出函数,作用是将刚才定义好的 module对象通过 napi_module_register对象设置到
thread_local_modepending.
需要特别注意的是NAPI_C_CTOR宏里面的 constructor 修饰, 这个标示代表当so加载时就会自动调用的函数,同样的还有一个destructor的修饰,表示so关闭前会自动调用的函数。
再次回到调用的js
var addon = require("./build/Release/hello");console.log(addon.hello());
require 实际上就是寻找对应的路径下的so, 最终通过 DLOpen 函数对对应的so 进行加载,加载时会自动调用 register ## modname 包装的 napi_module_register 方法, 将_module对象设置到
全局变量 thread_local_modpending 中。
// node_bindings.cc
void DLOpen(const FunctionCallbackInfo<Value>& args) {......env->TryLoadAddon(*filename, flags, [&](DLib* dlib) {Mutex::ScopedLock lock(dlib_load_mutex);const bool is_opened = dlib->Open();node_module* mp = thread_local_modpending;thread_local_modpending = nullptr;.....if (mp != nullptr) {mp->nm_dso_handle = dlib->handle_;dlib->SaveInGlobalHandleMap(mp);}Mutex::ScopedUnlock unlock(lock);if (mp->nm_context_register_func != nullptr) {mp->nm_context_register_func(exports, module, context, mp->nm_priv);} else if (mp->nm_register_func != nullptr) {mp->nm_register_func(exports, module, mp->nm_priv);} else {dlib->Close();THROW_ERR_DLOPEN_FAILED(env, "Module has no declared entry point.");return false;}return true;});}
}DLOpen 先根据文件路径load 对应so,(自动调用__register_xxx) 并将mp保存至全局。调用mp中保存的
nm_context_register_func函数指针, 通过 napi_module_register_cb -> napi_module_register_by_symbol, 最终调用我们自己的Init函数。并在module上添加exports成员,exports成员里绑定了我们自己实现的函数和成员。而这个module就是在DLOpen中传入的context.
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!