tf.get_variable()和tf.get_variable_scope()非常详细解释!!!!
当编写程序较长时,文件中定义的函数的输入参数可能会很多,例如神经网络的参数:
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2): 当神经网络的结构更加复杂、参数更多时,就需要一个更好的方式来传递和管理神经网络中的参数。
TensorFlow就提供了通过变量名来创建或获取变量的机制,可以使用tf.get_variable和tf.variable_scope函数来实现。
TensorFlow中除了通过tf.Variable来创建变量,还可以使用tf.get_variable来创建或者获取变量。当创建变量时,两个函数基本是等价的,例如:
#下面两行代码功能相同
v = tf.get_variable("v", shape[1], initializer=tf.constant_initializer(1.0))
v = tf.Variable(tf.constant(1.0, shape=[1]), name="v")1 tf.get_variable()
首 先 讲 一 下 t f . g e t v a r i a b l e ( ) 和 t f . V a r i a b l e ( ) 的 区 别 \color{red}{首先讲一下tf.get_variable()和tf.Variable()的区别} 首先讲一下tf.getvariable()和tf.Variable()的区别
tf.Variable()用于生成一个初始值为initial-value的变量;必须指定初始化值。
tf.get_variable()获取已存在的变量(要求不仅名字,而且初始化方法等各个参数都一样),如果不存在,就新建一个;可以用各种初始化方法,不用明确指定值。
- tf.Variable()
tf.Variable(initial_value=None, trainable=True, collections=None, validate_shape=True, caching_device=None, name=None, variable_def=None, dtype=None, expected_shape=None, import_scope=None
)参数解释:
i n i t i a l v a l u e : \color{red}{initial_value:} initialvalue:Tensor或可转换为Tensor的Python对象,它是Variable的初始值。除非validate_shape设置为False,否则初始值必须具有指定的形状;也可以是一个可调用的,没有参数,在调用时返回初始值。在这种情况下,必须指定dtype。 (请注意,init_ops.py中的初始化函数必须首先绑定到形状才能在此处使用。)
t r a i n a b l e : \color{red}{trainable:} trainable:如果为True,则会默认将变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES中。此集合用于Optimizer类优化的的默认变量列表【可为optimizer指定其他的变量集合】,可就是要训练的变量列表。
c o l l e c t i o n s : \color{red}{collections:} collections:一个图graph集合列表的关键字。新变量将添加到这个集合中。默认为[GraphKeys.GLOBAL_VARIABLES]。也可自己指定其他的集合列表。
v a l i d a t e s h a p e : \color{red}{validate_shape:} validateshape:如果为False,则允许使用未知形状的值初始化变量。如果为True,则默认为initial_value的形状必须已知。
c a c h i n g d e v i c e : \color{red}{caching_device:} cachingdevice:可选设备字符串,描述应该缓存变量以供读取的位置。默认为Variable的设备。如果不是None,则在另一台设备上缓存。典型用法是在使用变量驻留的Ops的设备上进行缓存,以通过Switch和其他条件语句进行重复数据删除。
n a m e : \color{red}{name:} name:变量的可选名称。默认为“Variable”并自动获取。
v a r i a b l e d e f : : \color{red}{variable_def::} variabledef::VariableDef协议缓冲区。如果不是None,则使用其内容重新创建Variable对象,引用图中必须已存在的变量节点。图表未更改。variable_def和其他参数是互斥的。
d t y p e : \color{red}{dtype:} dtype:如果设置,则initial_value将转换为给定类型。如果为None,则保留数据类型(如果initial_value是Tensor),或者convert_to_tensor将决定。
e x p e c t e d s h a p e : \color{red}{expected_shape:} expectedshape:TensorShape。如果设置,则initial_value应具有此形状。
i m p o r t s c o p e : \color{red}{import_scope:} importscope:可选字符串。要添加到变量的名称范围。仅在从协议缓冲区初始化时使用。
一般常用的参数包括初始化值和名称name(是该变量的唯一索引),在使用变量之前必须要进行初始化,初始化的方式有三种:
- 在会话中运行initializer操作。
- 从文件中恢复,如restore from checkpoint。
- 自己通过**tf.assign()**给变量附初值。
- tf.get_variable()
get_variable(name,shape=None,dtype=None,initializer=None,regularizer=None,trainable=True,collections=None,caching_device=None,partitioner=None,validate_shape=True,use_resource=None,custom_getter=None,constraint=None
)参数解释:
n a m e : \color{red}{name:} name:新变量或现有变量的名称。
s h a p e : \color{red}{ shape:} shape:新变量或现有变量的形状。
d t y p e \color{red}{ dtype} dtype:新变量或现有变量的类型(默认为DT_FLOAT)。
i n i n i a l i z e r : \color{red}{ininializer: } ininializer:如果创建了,则用它来初始化变量。
r e g u l a r i z e r \color{red}{regularizer } regularizer:A(Tensor - > Tensor或None)函数;将它应用于新创建的变量的结果将添加到集合tf.GraphKeys.REGULARIZATION_LOSSES中,并可用于正则化。
t r a i n a b l e : \color{red}{ trainable:} trainable:如果为True,还将变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES(参见tf.Variable)。
c o l l e c t i o n s : \color{red}{ collections:} collections:要将变量添加到的图表集合列表。默认为[GraphKeys.GLOBAL_VARIABLES](参见tf.Variable)。
c a c h i n g d e v i c e : \color{red}{caching_device:} cachingdevice:可选的设备字符串或函数,描述变量应被缓存以供读取的位置。默认为Variable的设备。如果不是None,则在另一台设备上缓存。典型用法是在使用变量驻留的Ops的设备上进行缓存,以通过Switch和其他条件语句进行重复数据删除。
p a r t i t i o n e r : \color{red}{ partitioner:} partitioner:可选callable,接受完全定义的TensorShape和要创建的Variable的dtype,并返回每个轴的分区列表(当前只能对一个轴进行分区)。
v a l i d a t e s h a p e \color{red}{ validate_shape} validateshape:如果为False,则允许使用未知形状的值初始化变量。如果为True,则默认为initial_value的形状必须已知。
u s e r e s o u r c e : \color{red}{ use_resource:} useresource:如果为False,则创建常规变量。如果为true,则使用定义良好的语义创建实验性ResourceVariable。默认为False(稍后将更改为True)。在Eager模式下,此参数始终强制为True。
c u s t o m g e t t e r : \color{red}{custom_getter:} customgetter:Callable,它将第一个参数作为true getter,并允许覆盖内部get_variable方法。 custom_getter的签名应与此方法的签名相匹配,但最适合未来的版本将允许更改:def custom_getter(getter,* args,** kwargs)。也允许直接访问所有get_variable参数:def custom_getter(getter,name,* args,** kwargs)。一个简单的身份自定义getter只需创建具有修改名称的变量是:python def custom_getter(getter,name,* args,** kwargs):return getter(name +’_suffix’,* args,** kwargs)。
如果initializer初始化方法是None(默认值),则会使用variable_scope()中定义的initializer,如果也为None,则默认使用glorot_uniform_initializer,也可以使用其他的tensor来初始化,value、和shape与此tensor相同。
正则化方法默认是None,如果不指定,只会使用**variable_scope()**中的正则化方式,如果也为None,则不使用正则化;
常用initializer有:
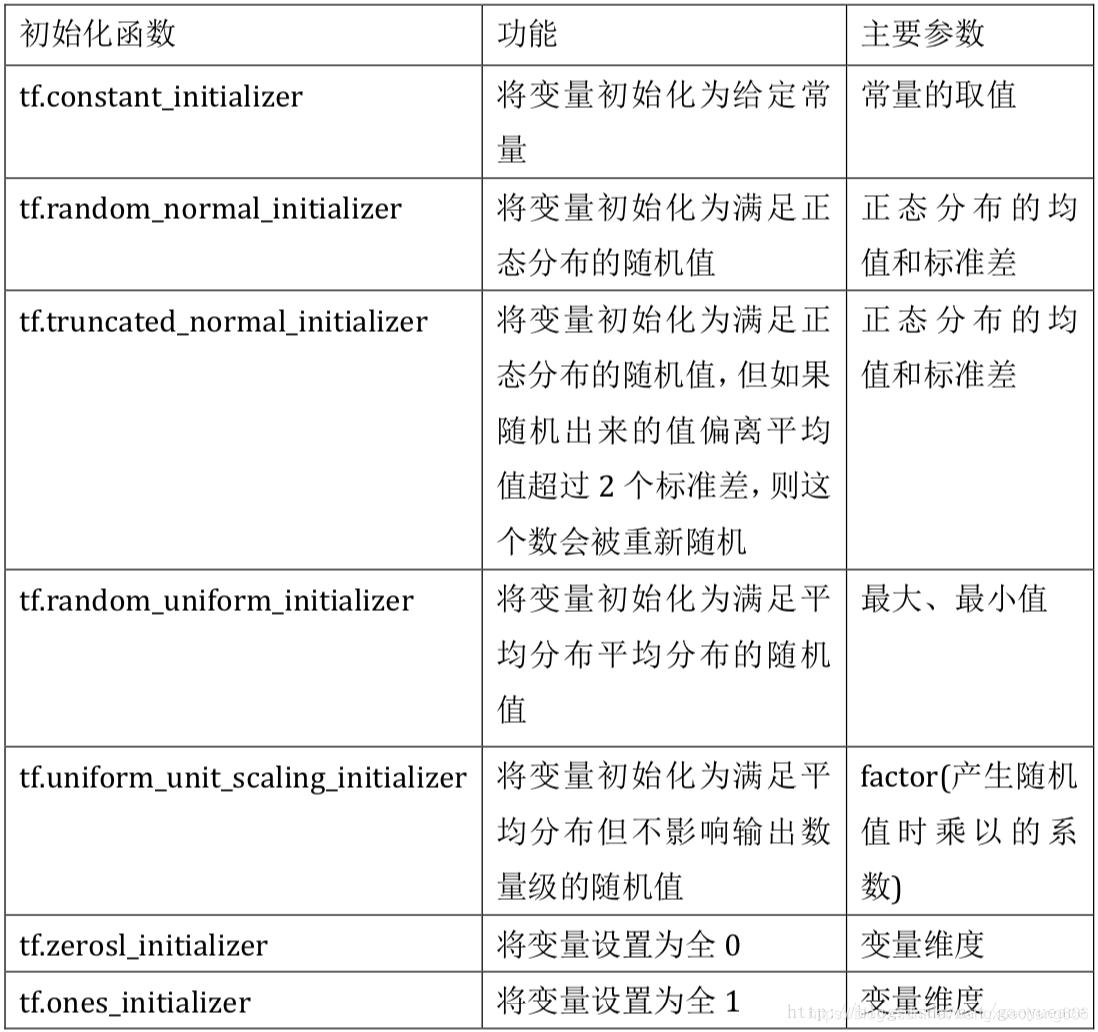
个人推荐使用tf.get_variable(),因为:
- 初始化更方便
- 方便共享变量
因为tf.get_variable()会检查当前命名空间下是否存在同样name的变量,可以方便共享变量。而tf.Variable每次都会新建一个变量。
需要注意的是tf.get_variable(),要配合reuse和tf.variable_scope() 使用,对于get_variable() 来说,如果已经创建的变量对象,就把那个对象返回,如果没有创建变量对象的话,就创建一个新的。
1 tf.variable_scope
由上文可知,tf.get_variable和tf.Variable最大的不同在于变量名称,tf.Variable中的变量名称是一个可选的参数,通过name=""给出;而在tf.get_variable函数中,变量名称是必填的一个参数。当上述代码tf.get_variable创建名字为v的参数时,若已经有同名的参数,则会创建失败。但是,可以通过tf.get_variable来获取一个已经创建的变量,这是需要使用tf.variable_scope函数实现,tf.variable_scope会生成一个上下文管理器,并明确指定在这个上下文管理器中,tf.get_variable将直接获得已经生成的变量。例如:
import tensorflow as tf#在名字为foo的命名空间内创建名字为v的变量
with tf.variable_scope("foo"):v = tf.get_variable("v", [1], initializer=tf.constant_initializer(1.0))#因为在命名空间foo中已经存在名字为v的变量,所以下面代码会报错
# with tf.variable_scope("foo"):
# v = tf.get_variable("v", [1])#在生成上下文管理器时,将参数reuse设置为True
# 这样tf.get_variable函数将直接获取已经声明的变量
with tf.variable_scope("foo", reuse=True):v1 = tf.get_variable("v", [1])print(v==v1) #输出为True, 代表v,v1是相同的TensorFlow变量>>True 可以看出,当tf.variable_scope使用参数reuse=True生成上下文管理器时,这个上下文管理器内所有的tf.get_variable会直接获取已经创建的变量。如果变量不存在,则会报错;但是若reuse=False或None时,tf.get_variable会创建新的变量,如果同名参数存在则会报错。
TensorFlow中tf.variable_scope函数是可以嵌套的,例如:
with tf.variable_scope("root"):#可以通过tf.get_variable_scope().reuse来获取当前上下文管理器中reuse的取值print(tf.get_variable_scope().reuse)with tf.variable_scope("foo", reuse=True):#新建嵌套的上下文管理器,指定reuseprint(tf.get_variable_scope().reuse)with tf.variable_scope("bar"):#再新建一个嵌套的上下文管理器,若不指定reuse,则和上一层一致print(tf.get_variable_scope().reuse)#退出reuse为True的上下文后,reuse恢复为Falseprint(tf.get_variable_scope().reuse)>>False
True
True
Falsetf.variable_scope函数生成的上下文管理器会创建一个命名空间,可以来管理变量,例如以下代码:
v1 = tf.get_variable("v", [1])
print(v1.name)
#输出v:0, "v"为变量的名称,":0"表示这个变量是生成变量这个运算的第一个结果with tf.variable_scope("foo"):v2 = tf.get_variable("v", [1])print(v2.name)#输出foo/v:0#在tf.variable_scope中创建的变量,会加入命名空间的名称#通过/来分隔命名空间的名称和变量的名称with tf.variable_scope("foo"):with tf.variable_scope("bar"):v3 = tf.get_variable("v", 1)print(v3.name) #命名空间可以嵌套v4 = tf.get_variable("v1", [1])print(v4.name) #当命名空间退出之后,变量名称就不会再加前缀#创建一个名称为空的命名空间
with tf.variable_scope("", reuse=True):v5 = tf.get_variable("foo/bar/v", [1])#可以直接通过带命名空间名称的变量名来获取其他命名空间下的变量print(v5 == v3)v6 = tf.get_variable("foo/v1", [1])print(v6 == v4)>>v:0
foo/v:0
foo/bar/v:0
foo/v1:0
True
True通过tf.variable_scope和tf.get_variable函数,可以对此链接里的神经网络中的计算前向传播结果的函数做一些改进,提高代码的可读性。如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_dataINPUT_NODE = 784 #输入层的节点数,图片为28*28,为图片的像素
OUTPUT_NODE = 10 #输出层的节点数,等于类别的数目,需要区分0-9,所以为10类#配置神经网络的参数
LAYER1_NODE = 500 #隐藏层的节点数,此神经网络只有一层隐藏层
BATCH_SIZE = 100 #一个训练batch中的训练数据个数,数字越小,越接近随机梯度下降,越大越接近梯度下降
LEARNING_RATE_BASE = 0.8 #基础的学习率
LEARNING_RATE_DECAY = 0.99 #学习率的衰减率
REGULARIZATION_RATE = 0.0001 #描述网络复杂度的正则化向在损失函数中的系数
TRAINING_STEPS = 30000 #训练轮数
MOVING_AVERAGE_DECAY = 0.99 #滑动平均衰减率#给定神经网络的输入和所有参数,计算神经网络的前向传播结果,定义了一个使用ReLU的三层全连接神经网络,通过加入隐藏层实现了多层网络结构
def inference(input_tensor, avg_class, reuse=False):#定义第一层神经网络的变量和前向传播结果with tf.variable_scope("layer1", reuse=reuse):#根据传进来的reuse来判断是创建新变量还是使用已经创建好的#在第一次构造网络时需要创建新的变量,以后每次调用这个函数都直接使用reuse=True就不需要每次传入变量了weights = tf.get_variable("weights", [INPUT_NODE, LAYER1_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))biases = tf.get_variable("biases", [LAYER1_NODE], initializer=tf.constant_initializer(0.1))# 若没有提供滑动平均类,则直接使用参数当前的取值if avg_class == None:layer1 = tf.nn.relu(tf.matmul(input_tensor, weights)+biases)else:layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights)) + avg_class.average(biases))#定义第二层神经网络的变量和前向传播过程with tf.variable_scope("layer2", reuse=reuse):weights = tf.get_variable("weights", [LAYER1_NODE, OUTPUT_NODE],initializer=tf.truncated_normal_initializer(stddev=0.1))biases = tf.get_variable("biases", [OUTPUT_NODE], initializer=tf.constant_initializer(0.1))if avg_class == None:layer2 = tf.matmul(layer1, weights)+biaseselse:layer2 = tf.matmul(layer1, avg_class.average(weights))+avg_class.average(biases)#返回最后的前向传播结果return layer2#训练网络的过程
def train(mnist):x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input')#计算在当前参数下神经网络前向传播的结果,这里的用于计算滑动平均的类为None,所以没有使用滑动平均值y = inference(x, None)#在程序中需要使用训练好的神经网络进行推导时,可直接调用inference(new_x, variable_averages, True)#定义存储训练轮数的变量,这个变量不需要被训练global_step = tf.Variable(0, trainable=False)#初始化滑动平均类variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)#在所有代表神经网络参数的变量上使用滑动平均,需要被训练的参数,variable_averages返回的就是GraphKeys.TRAINABLE_VARIABLES中的元素variable_averages_op = variable_averages.apply(tf.trainable_variables())#计算使用了滑动平均之后的前向传播结果,滑动平均不会改变变量本身取值,会用一个影子变量来记录average_y = inference(x, variable_averages, True)#计算交叉熵,使用了sparse_softmax_cross_entropy_with_logits,当问题只有一个正确答案时,可以使用这个函数来加速交叉熵的计算。#这个函数的第一个参数是神经网络不包括softmax层的前向传播结果,第二个是训练数据的正确答案,argmax返回最大值的位置cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))#计算在当前batch中所有样例的交叉熵平均值cross_entropy_mean = tf.reduce_mean(cross_entropy)#计算L2正则化损失regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)with tf.variable_scope("", reuse=True):weights1 = tf.get_variable("layer1/weights", [INPUT_NODE, LAYER1_NODE])weights2 = tf.get_variable("layer2/weights", [LAYER1_NODE, OUTPUT_NODE])#计算网络的正则化损失regularization = regularizer(weights1) + regularizer(weights2)#总损失为交叉熵损失和正则化损失之和loss = cross_entropy_mean + regularization#设置指数衰减的学习率learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,mnist.train.num_examples/BATCH_SIZE, LEARNING_RATE_DECAY)#LEARNING_RATE_BASE为基础学习率,global_step为当前迭代的次数#mnist.train.num_examples/BATCH_SIZE为完整的过完所有的训练数据需要的迭代次数#LEARNING_RATE_DECAY为学习率衰减速度#使用GradientDescentOptimizer优化算法优化损失函数train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)#在训练神经网络的时候,每过一遍数据都要通过反向传播来更新参数以及其滑动平均值# 为了一次完成多个操作,可以通过tf.control_dependencies和tf.group两种机制来实现# train_op = tf.group(train_step, variable_averages_op) #和下面代码功能一样with tf.control_dependencies([train_step, variable_averages_op]):train_op = tf.no_op(name = 'train')#检验使用了滑动平均模型的神经网络前向传播结果是否正确#f.argmax(average_y, 1)计算了每一个样例的预测答案,得到的结果是一个长度为batch的一维数组#一维数组中的值就表示了每一个样例对应的数字识别结果#tf.equal判断两个张量的每一维是否相等。如果相等返回True,反之返回Falsecorrect_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))#首先将一个布尔型的数组转换为实数,然后计算平均值#平均值就是网络在这一组数据上的正确率accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))#初始会话并开始训练过程with tf.Session() as sess:tf.global_variables_initializer().run() #参数初始化#准备验证数据,在神经网络的训练过程中,会通过验证数据来大致判断停止的条件和评判训练的效果validate_data = {x: mnist.validation.images, y_:mnist.validation.labels}#准备测试数据test_data = {x:mnist.test.images, y_:mnist.test.labels}#迭代的训练神经网络for i in range(TRAINING_STEPS):#每1000轮输出一次在验证数据集上的测试结果if i%1000==0:#计算滑动平均模型在验证数据上的结果,因为MNIST数据集较小,所以可以一次处理所有的验证数据validate_acc = sess.run(accuracy, feed_dict=validate_data)print("After %d training steps, validation accuracy using average model is %g"%(i, validate_acc))# 产生训练数据batch,开始训练xs, ys = mnist.train.next_batch(BATCH_SIZE) # xs为数据,ys为标签sess.run(train_op, feed_dict={x:xs, y_:ys})test_acc = sess.run(accuracy, feed_dict=test_data)print("After %d training steps, validation accuracy using average model is %g"%(TRAINING_STEPS, test_acc))#程序主入口
def main(argv=None):# 声明处理MNIST数据集的类,one_hot=True将标签表示为向量形式mnist = input_data.read_data_sets("/Users/gaoyue/文档/Program/tensorflow_google/chapter5", one_hot=True)train(mnist)#TensorFlow提供程序主入口,tf.app.run会调用上面定义的main函数
if __name__ =='__main__':tf.app.run()本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!