比较Causal decoder、Prefix decoder和encoder-decoder
note:不同的语言模型通过attention mask设计,mask取全1就对应双向注意力,mask取下三角矩阵就对应单向注意力,我们可以只使用transformer encoder的情况下,自定义attention mask来兼容不同模型架构(如auto agressive单向注意力、auto encoding 双向注意力、encoder-decoder 解码器用单向注意力 且用交叉注意力连接两者):

如下图:
蓝色:the attention between prefix tokens
绿色:the attention between prefix and target tokens
黄色:the attention betweetn target tokens and masked attention
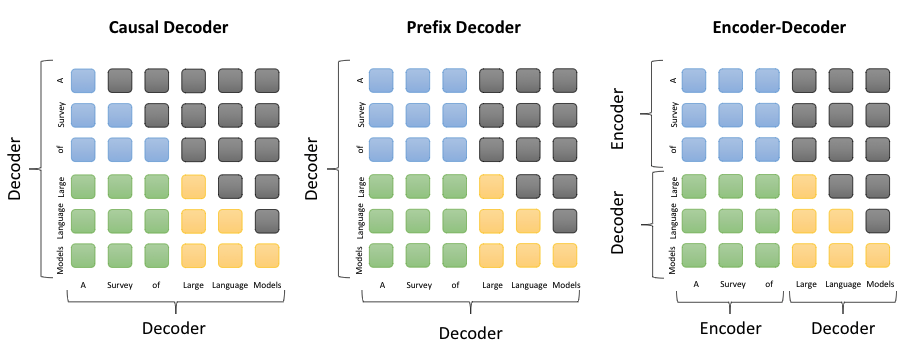
- 因果解码器(causal decoder,当前主流):因果解码器架构采用单向注意力掩码,以确保每个输入标记只能关注过去的标记和它本身。输入和输出标记通过解码器以相同的方式进行处理。
- chatGPT等
- 因果编码器:GPT,BLOOM,Gopher等。
- 前缀解码器(prefix decoder):前缀解码器结构修正了因果编码器的掩码机制,以使其能可对前缀标记执行双向注意力,并仅对生成的标记执行单向注意力。这样,与encoder-decoder类似,可以双向编码前缀序列并自回归低逐个预测输出标记,其中在编码和解码阶段共享相同的参数。现在前缀编码器的大模型包括U-PaLM、GLM-130B等。
- 编码器-解码器(encoder-decoder):传统 Transformer 模型是建立在编码器-解码器架构上的 ,由两个 Transformer 块分别作为编码器和解码器。编码器采用堆叠的多头自注意层对输入序列进行编码以生成其潜在表示,而解码器对这些表示进行交叉注意并自回归地生成目标序列。目前,只有少数大语言模型是基于编码器-解码器架构构建的例如 Flan-T5。
Reference
[1] 为什么现在的LLM都是Decoder only的架构.某乎
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!