实参形参与指针3——单链表定义与基本操作函数传值
前言
一直忘了说了,记录的代码部分是基于C语言的,一个是C语言确实太适合打基础,另一个是目前工作中接触C语言比较多。
结构体的定义与自引用
单链表结点虽然也使用结构体进行定义,但是单链表不同于数组顺序表,单链表的元素是由无数个互不相同的结构体(结点)组成的,而数组顺序表一般就只一个结构体主体。

而且链表结构体(结点)元素的指针域使用了结构体的自引用特性,需要使用结构体的指针进行引用,这是因为结构体本身定义是没有初始化的,而指针在系统中是有固定大小的,下边展示一个正确定义方法和几个经典错误定义方法。
//正确定义方法
typedef struct Node{int data;struct Node* next;
}LNode,*Linklist;
//错误方法1
typedef struct{int data;struct LNode* next;
}LNode,*Linklist;
//错误方法2
typedef struct Node{int data;struct Node next;
}LNode,*Linklist;
单链表的数据结构
学习数据结构与算法基础一般逃不过两本书,一本是严老师的数据结构与算法,另一本是《大话数据结构》。
在这两本书中都使用了相同的结点定义方式,代码如下:
typedef struct Node{int data;struct Node* next;
}LNode,*Linklist;
但是令人失望的是,两位作者并没有对这种定义方式进行更深入的解读,直接就开始讲了基本操作实现部分,于是我就开始找资料自己解读。
从C语言规范出发,可以把上述代码抽象成一种用于单链表的模板(请结合上方代码比对阅读):
typedef struct [自引用前置命名]{[元素类型] [变量名称1];struct [自引用前置命名]* [变量名称2];
}[结构体变量别名1],[结构体变量别名2],*[结构体指针变量别名1],.........;
其中,[自引用前置命名]用于自引用,也就是定义指针域;花括号外,一般在算法实现过程中会定义一个[结构体变量别名]和一个*[结构体指针变量别名],其中[结构体变量别名]在基本操作中用于代表具体结点;而[结构体指针变量别名]用于代表头指针,这是因为单链表在查找元素的时候都是从头指针开始的,且插入删除修改都离不开查找,所以定义了一个结构体指针能方便理解。
除此之外,结构体指针还方便了功能函数的传参,这点会在下面的函数传值进一步说明。
基于单链表的函数传值
这部分将围绕下方代码进行,分别是一个结构体定义和两个简单的基本操作函数:
typedef struct Node{int data;struct Node* next;
}LNode,*Linklist;int initLNode(Linklist &L) {//初始化函数,不使用头结点L = (Linklist)malloc(sizeof(LNode));L->next = NULL;return 1;
}int isEmpty(Linklist L) {//判空函数if (L->next == NULL) {return 1;}else{return 0;}
}
在单链表的数据结构部分说过,基本操作函数大部分离不开查找,而单链表查找离不开头指针,所以这里定义了一个*Linklist的结构体指针变量,指针对指针方便理解。
在结构体下方是两个功能函数,其中initNode(Linklist &L)是初始化链表,另一个是判断链表是否为空。显然,判空函数并不需要对单链表本身进行修改,而初始化函数需要修改单链表。本着C语言的函数的值传递与地址传递规范,只需要按规范对判空函数传入变量主体头指针,对初始化函数传入变量主题头指针并取地址就行了。
下面将与静态数组顺序表进行对比,结合图示说明一下我个人的理解方法:
首先,对于一个静态数组顺序表和一个结构体指针变量,它们在内存中的位置、存储内容和关系可以抽象成下方图中内容:
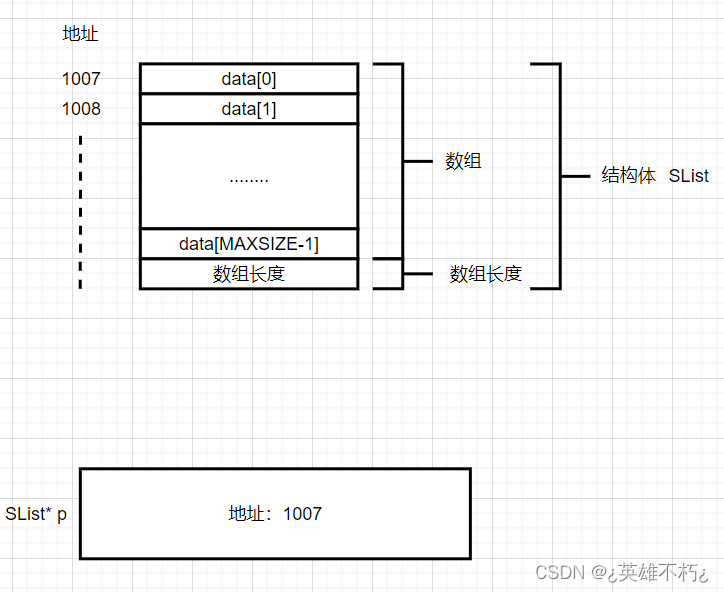
之前部分提到,数组是记录在结构体内部,在定义结构体时就开辟好了空间(静态),所以我们只需要一个结构体指针*p就可以完成对数组的实参传递,即:
Status Func1(SList* p){.......};//需要修改数组,传实参,函数地址传值
Status Func2(SList p){.......};//不需要修改数组,传形参,函数数值传值
而单链表不是这样,单链表的每个元素都是一个独立开辟空间的结构体(结点)变量,如下图:
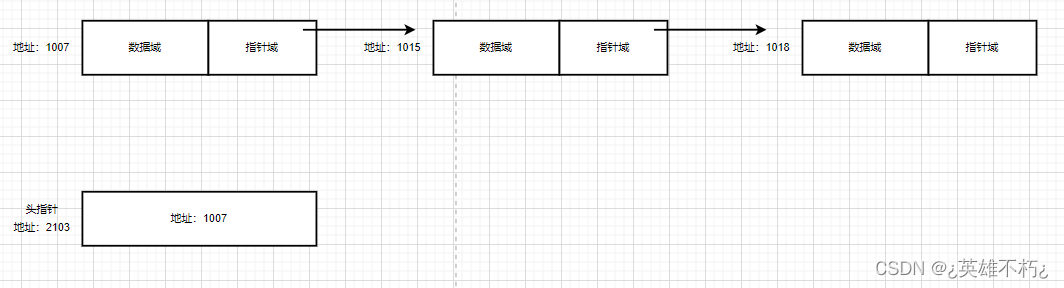
单链表每个结点在内存中是不连续的,因此所有操作都将围绕着头指针进行,对头指针的运用是查找操作的核心,而查找操作时大部分其它操作的核心,所以头指针是单链表基本操作的主体对象,传值也将围绕头指针进行。
typedef struct Node{int data;struct Node* next;
}LNode,*Linklist;
所以一般都会建立一个结构体指针变量,这样形参就是Linklist L,实参就是Linklist &L,对应数值传值和地址传值,下面为例子:
Status getElem(Linklist L, int pos, int &elem){........};
//函数用于获取链表第pos的元素并用elem获取该元素,不涉及修改链表,传入形参
Status initList(Linklist &L){........}
//函数用于初始化链表,需要修改链表,传入实参
可以看到,和静态数组顺序表一样,形参对应的就是对象主体,实参就是对象主体地址,而如果我们没有直接建立结点指针,只有结构体变量,函数传值就要变成二级指针操作,增加了麻烦,代码如下
Status getElem(LNode* L, int pos, int &elem){........};
//函数用于获取链表第pos的元素并用elem获取该元素,不涉及修改链表,传入形参
Status initList(LNode* &L){........}
//函数用于初始化链表,需要修改链表,传入实参
另一种对(单链表)函数传入实参的理解方法是。当我们需要对某个单链表进行查找操作时,如果该链表建立时是以结构体变量(LNode L)为对象主体并取地址,由于没有建立头指针并通过头指针进行操作,查找函数并没有办法找到这条链表。
当使用头指针时,传值对象主体变为头指针,这样查找时可以传入形参(Linklist L or LNode* L)。根据形参的定义,函数内部的头指针实际是链表头指针的复制品,虽然函数内部有p = p->next,但是全局变量下链表的头指针并未有过任何更改。所以当我们需要增删改链表的时候,需要传入头指针的地址,这样放函数内部运行到p = p->next的时候,全局变量对应指向的结点数据也会发生变化。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!