pdfbox删除水印
本文采用的是pdfbox 2.0.27版本
org.apache.pdfbox pdfbox 2.0.27 前提:先说一下如果你是第一次开发关于PDF的最好先了解一下PDF的基本结构,可能和开发相关行不大,但最好也要了解一下。pdfbox提供了一种查看PDF结构的方式PDFDebugger,这个为jar包中类,可以直接看出文档结构。如下:
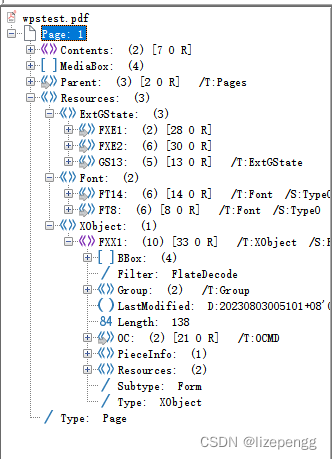
通过这个工具很好的看出来。
pdf 文件格式及对象模型pdf 文件格式及对象模型 对象模型 PDF文件主要是由object组成的, 通过object的内部关系形成如下的逻辑结构 /Catalog /Pages /MediaBox /Count /Kids 其中, /开头的是对象名字, /MediaBox 是页面大小, /Count是页数, /Kids是页对象集合. 页…![]() https://www.rstk.cn/news/614830.html?action=onClick如何识别PDF水印并使用PDFBox将其删除 - IT屋-程序员软件开发技术分享社区How to recognize PDF watermark and remove it using PDFBox(如何识别PDF水印并使用PDFBox将其删除) - IT屋-程序员软件开发技术分享社区
https://www.rstk.cn/news/614830.html?action=onClick如何识别PDF水印并使用PDFBox将其删除 - IT屋-程序员软件开发技术分享社区How to recognize PDF watermark and remove it using PDFBox(如何识别PDF水印并使用PDFBox将其删除) - IT屋-程序员软件开发技术分享社区![]() https://www.it1352.com/1621162.html
https://www.it1352.com/1621162.html
http://t.csdn.cn/KtDip![]() http://t.csdn.cn/KtDip
http://t.csdn.cn/KtDip
http://t.csdn.cn/ynYfA![]() http://t.csdn.cn/ynYfA这些是我看过的一部分,还有很多需要自己去了解pdfbox中一些对象是啥意思(这部分我用了好长时间)。
http://t.csdn.cn/ynYfA这些是我看过的一部分,还有很多需要自己去了解pdfbox中一些对象是啥意思(这部分我用了好长时间)。
Java PDF添加删除水印_java pdf去除水印_半个西瓜、的博客-CSDN博客![]() https://blog.csdn.net/userenoch/article/details/128716465?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-128716465-blog-123109451.235%5Ev38%5Epc_relevant_default_base3&spm=1001.2101.3001.4242.2&utm_relevant_index=4这篇给了我一些启发,让我写了出来。
https://blog.csdn.net/userenoch/article/details/128716465?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-1-128716465-blog-123109451.235%5Ev38%5Epc_relevant_default_base3&spm=1001.2101.3001.4242.2&utm_relevant_index=4这篇给了我一些启发,让我写了出来。
现在开始正题代码如下:
第一种:此种方法为可以获取到对应的xObject对象的方式(水印在内容的下方)
@Testpublic void testTran(){try(PDDocument pdDocument=PDDocument.load(new File("pdftest.pdf"))){final PDResources resources = page.getResources();//获取图像资源等对象的名字final Iterable xObjectNames = resources.getXObjectNames();//获取COSObject对象final COSDictionary cosDictionary = resources.getCOSObject();System.out.println(cosDictionary);for (COSName cosName : xObjectNames) {System.out.println(cosName);//此处需要注意cosDictionary对象的格式,需要先根据COSName.XOBJECT获取器对应的dictionary,// 才能进一步删除final COSDictionary dictionary = cosDictionary.getCOSDictionary(COSName.XOBJECT);//根据cosname来进行删除dictionary.removeItem(cosName);}System.out.println(cosDictionary);}pdDocument.save("pdfWithNoMark.pdf");} catch (IOException e) {e.printStackTrace();}}
第二种:水印在内容的上方,此种方式可能获取不到XObject对象,无法直接删除,可以通过Tj标记来删除。此种方式目前还有点不足,但也可以实现水印的删除功能,内部代码有部分需要结合实际来修改。
public void removeTextWatermark(String inputPdfFilePath, String outputFdfFilePath) throws Exception {{File file = new File(inputPdfFilePath);PDDocument pd = PDDocument.load(file);for (PDPage page : pd.getPages()) {PDFStreamParser pdfsp = new PDFStreamParser(page);pdfsp.parse();List此段代码为原始代码,可以根据自己情况进行修改。其中TJ或是Tj为标记字符串,器前边的部分就是字符串,如果不了解可以使用文本工具打开PDF文件进行了解其结构。
第三种:通过获取文档中内容字体的倾斜度,来过滤水印。通过继承PDFTextStripper来实现。
最后,希望能帮到你们。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!