网络爬虫原理1——软件安装
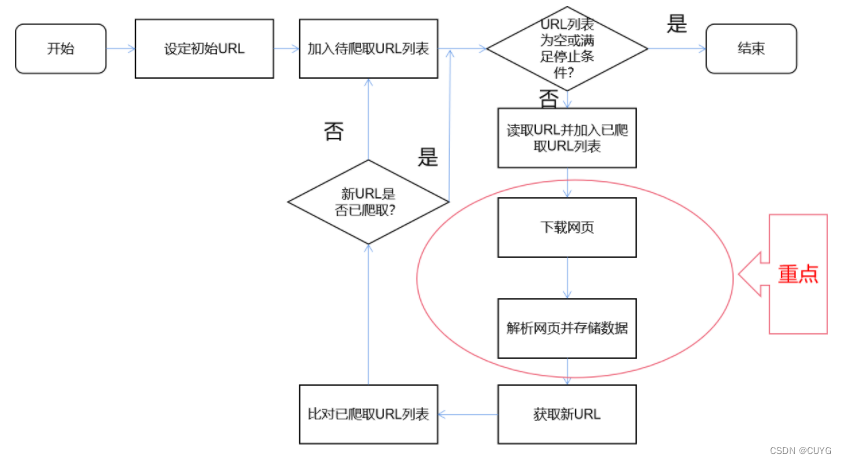
一、网络爬虫原理图
URL:统一资源定位符,是对可以从互联网上得到的资源位置和访问方法的一种简洁表示。
二、网络爬虫分类
1、通用网咯爬虫
目标:从初始设定的URL扩充到全网。
应用:门户网站、搜索引擎、大型网络服务提供商的数据采集。
2、聚焦网络爬虫
目标:与预先定义好的主题相关的网页。
应用:特定领域信息有需求的场景。
3、增量式网络爬虫
目标:有更新的已下载网页和新产生的网页。
应用:网页内容会时常更新的网站,或者有不断有新网页出现的网站。
4、深层网络爬虫
目标:不能通过静态链接获取的,隐藏在搜索表单后的,只有用户提交一些关键词才能获取的网站。
应用:用户注册后才可显示的内容的网站。
三、Robots协议
全称“网络爬虫排除标准”
robots.txt文件里列出哪些链接不允许爬虫程序获取
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-45RjtUmd-1676974268856)(C:\Users\yt\AppData\Roaming\marktext\images\2023-02-21-15-17-23-image.png)]](https://img-blog.csdnimg.cn/a04497074b1a483eb88efe8b60ed2ffd.png)
四、软件的安装
1、
ANACONDA软件链接:
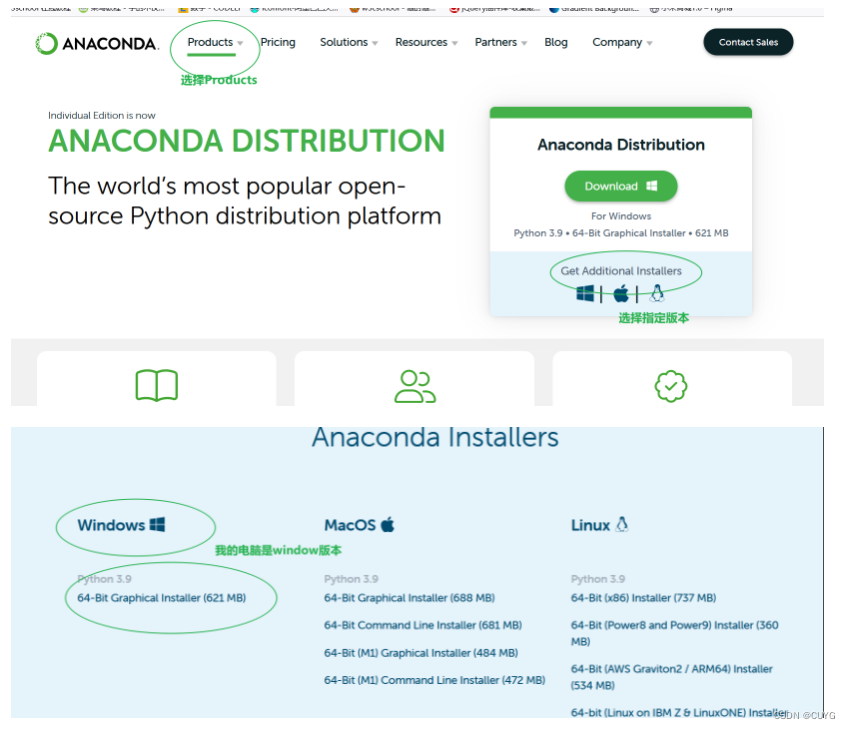
2、点击下载成功,并点击以下程序:
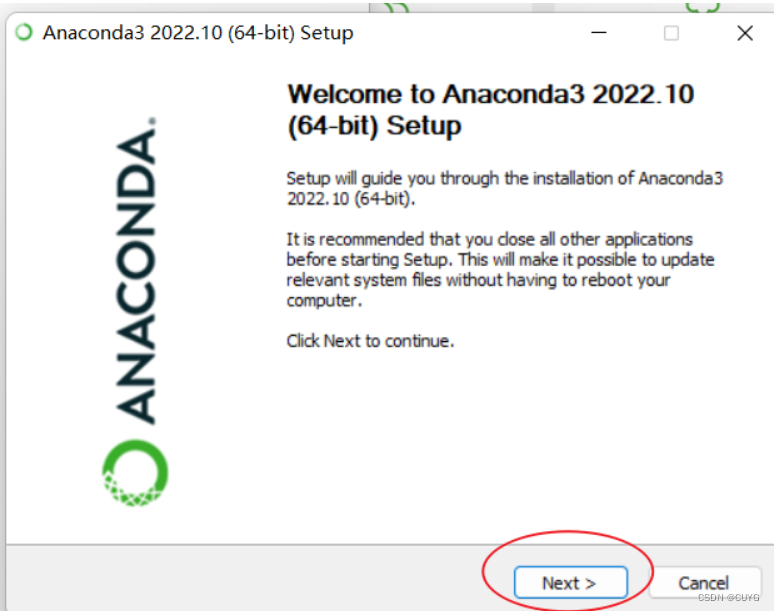
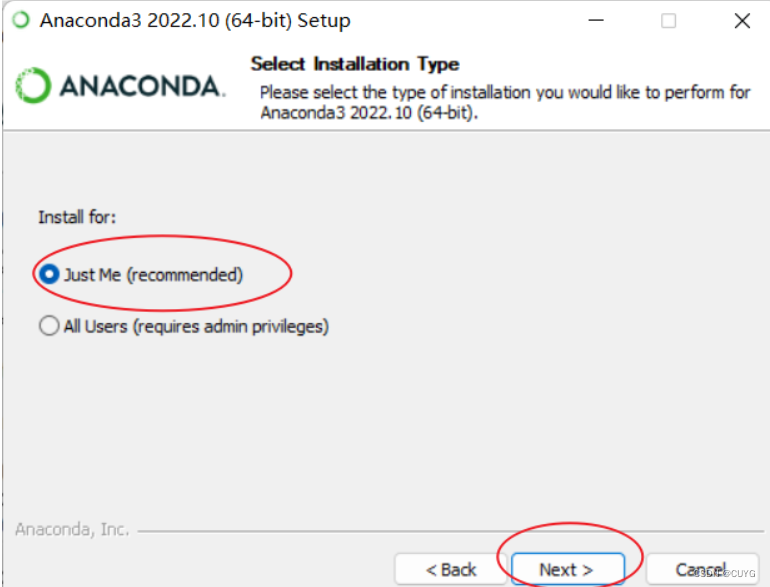
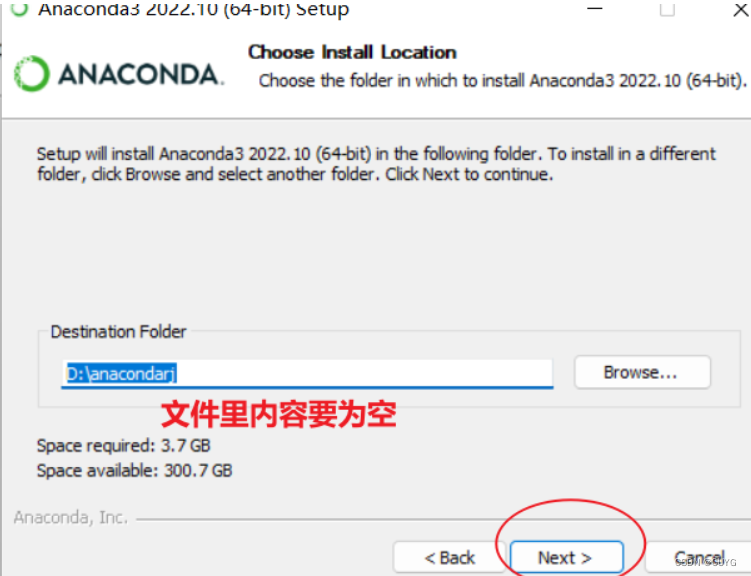
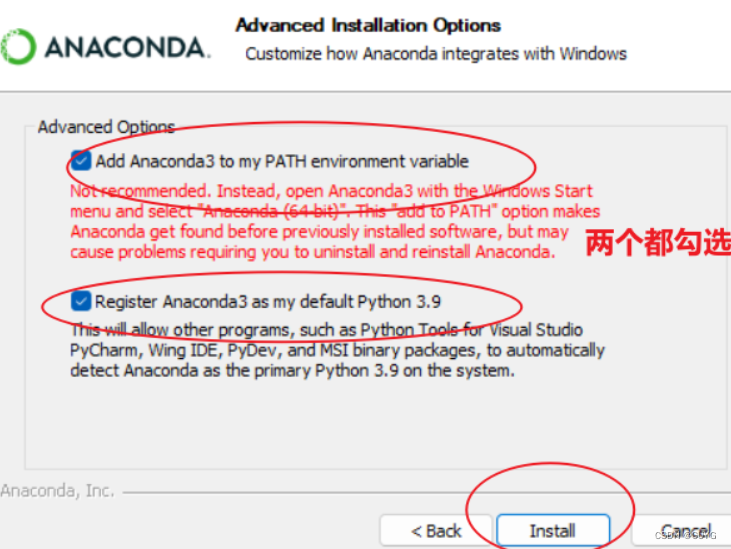
3、点击next:
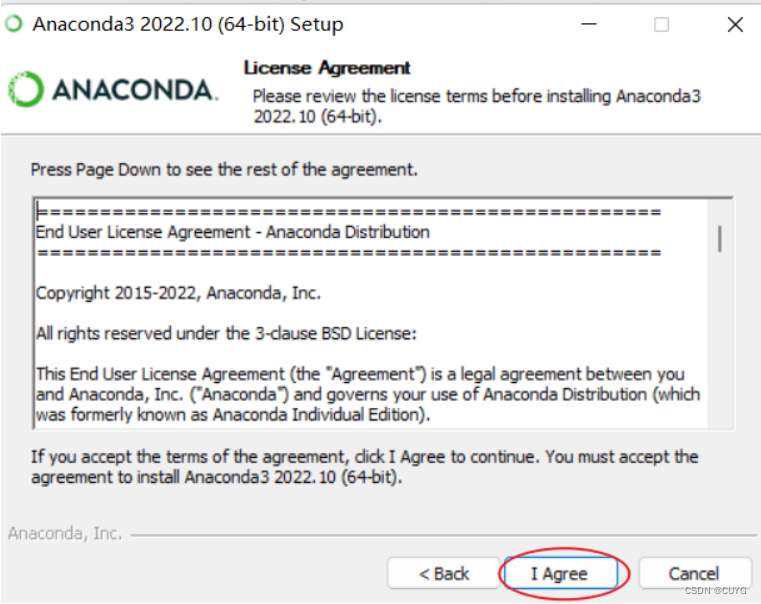
4、点击I Agree
 测试Anaconda是否安装 成功
测试Anaconda是否安装 成功
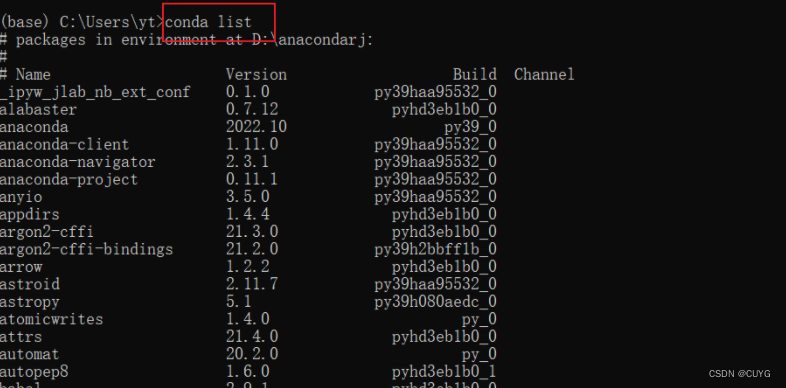
输入代码conda list
1、下载PyCharm
Download PyCharm: Python IDE for Professional Developers by JetBrains
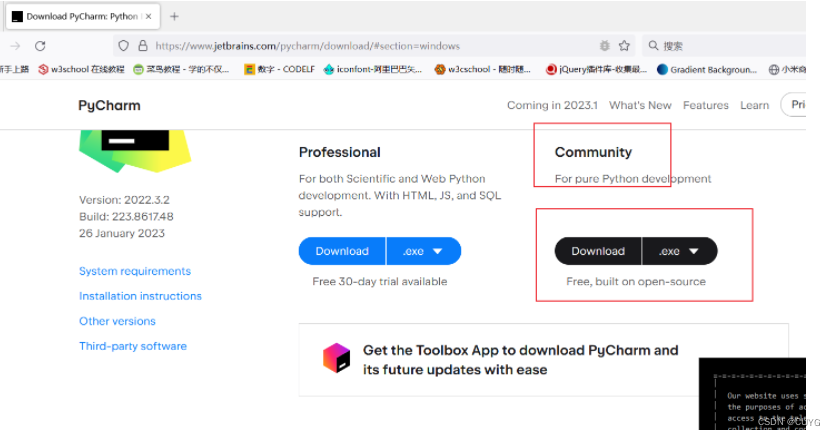 下载成功后,双击软件安装包
下载成功后,双击软件安装包
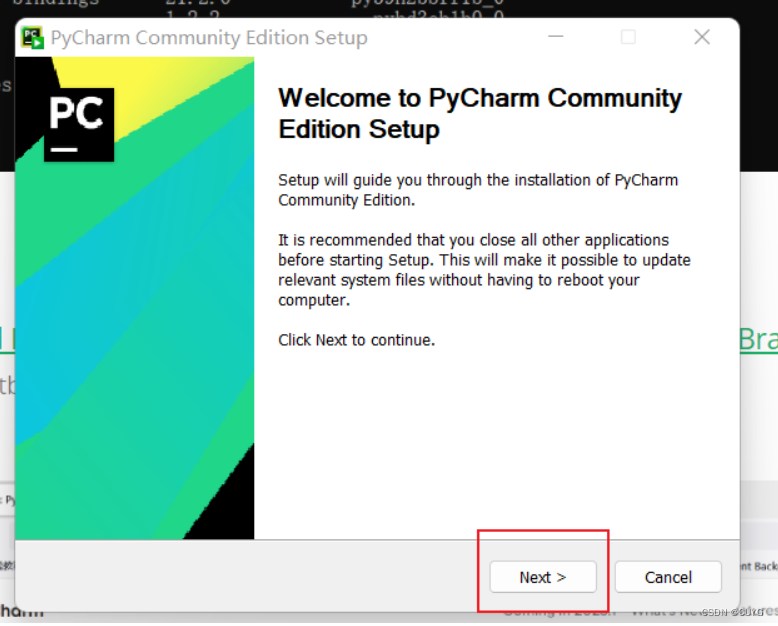
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mtAqH5t5-1676975368805)()]](https://img-blog.csdnimg.cn/4e94d2ca6fd64258a7c09926cca539ee.png)
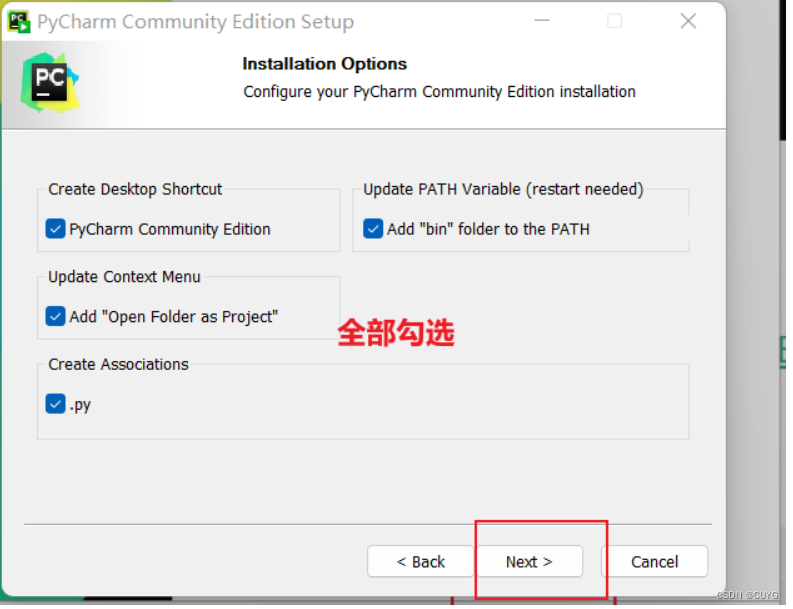
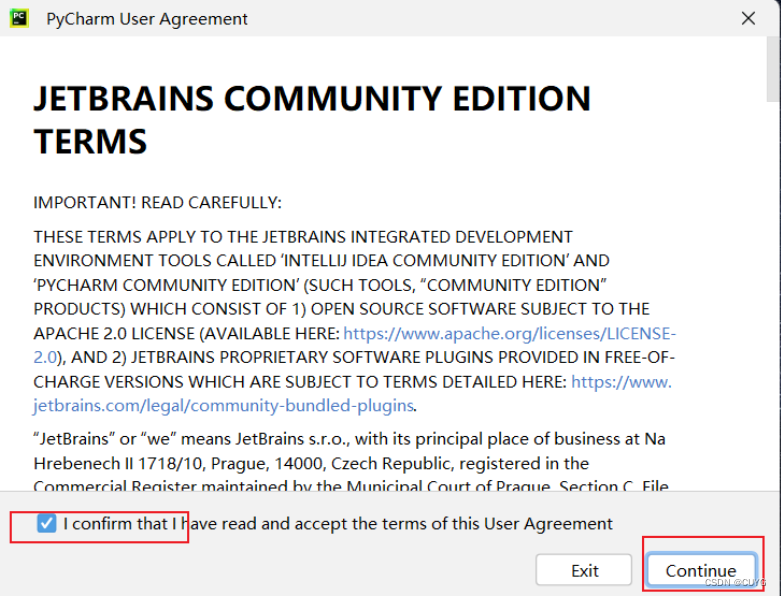
按提示选择,最后点击完成
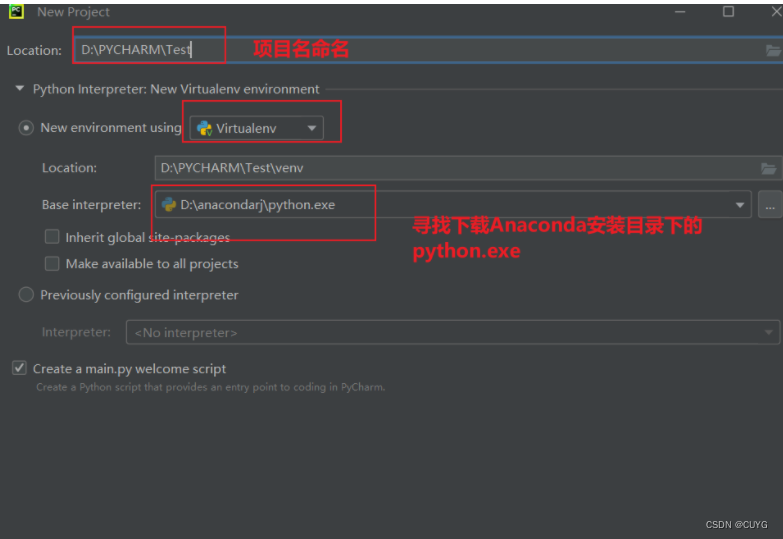
测试是否安装成功
点击Test-New-Python File
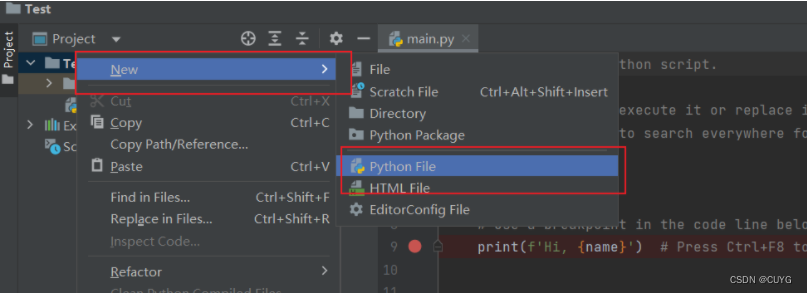 弹出NewPython file 对话框,文件命名为HelloWord,接着双击Python file
弹出NewPython file 对话框,文件命名为HelloWord,接着双击Python file
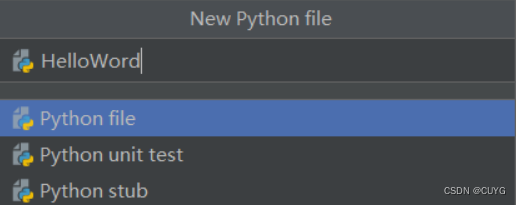
进入HelloWord.py编辑界面
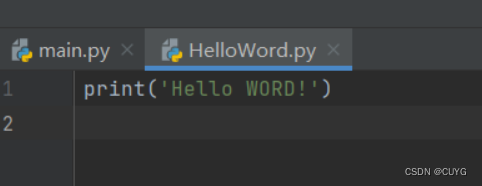
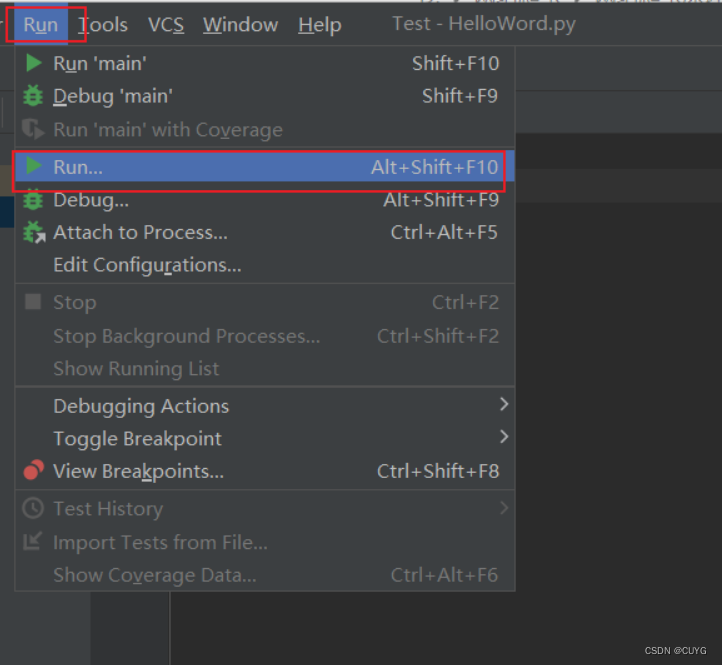
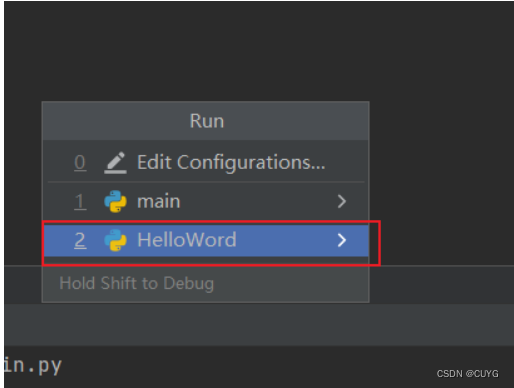
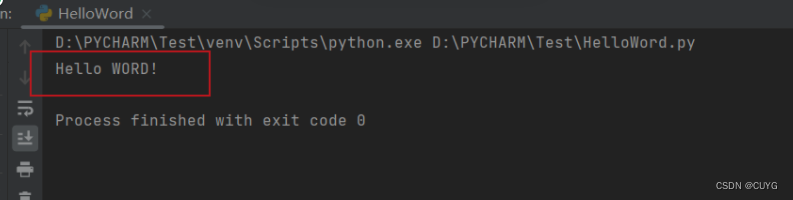
运行程序
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!