Go Interview
基础
函数与方法的区别
在Go语言中,函数是指不属于任何结构体、类型的方法,也就是说函数是没有接收者的;而方法是有接收者的。
-
方法
//其中T是自定义类型或者结构体,不能是基础数据类型int等 func (t *T) add(a, b int) int {return a + b } -
函数
func add(a, b int) int {return a + b }
Go方法值接收者和指针接收者的区别?
-
如果方法的接收者是指针类型,无论调用者是对象还是对象指针,修改的都是对象本身,会影响调用者;
-
如果方法的接收者是值类型,无论调用者是对象还是对象指针,修改的都是对象的副本,不影响调用者;
使用指针类型作为方法的接收者的优点
- 使用指针类型能够修改调用者的值。
- 使用指针类型可以避免在每次调用方法时复制该值,在值的类型为大型结构体时,这样做会更加高效。
Go函数返回局部变量的指针是否安全
一般来说,局部变量会在函数返回后被销毁,因此被返回的引用就成为了"无所指"的引用,程序会进入未知状态。
但这在 Go 中是安全的,Go 编译器将会对每个局部变量进行逃逸分析。如果发现局部变量的作用域超出该函数,则不会将内存分配在栈上,而是分配在堆上,因为他们不在栈区,即使释放函数,其内容也不会受影响。
package mainimport "fmt"func add(x, y int) *int {res := 0res = x + yreturn &res
}func main() {fmt.Println(add(1, 2))
}
函数 add 局部变量 res 发生了逃逸。res作为返回值,在 main 函数中继续使用,因此 res 指向的内存不能够分配在栈上,随着函数结束而回收,只能分配在堆上。
go build -gcflags=-m main.go,查看变量逃逸的情况
./main.go:6:2: res escapes to heap:
./main.go:6:2: flow: ~r2 = &res:
./main.go:6:2: from &res (address-of) at ./main.go:8:9
./main.go:6:2: from return &res (return) at ./main.go:8:2
./main.go:6:2: moved to heap: res
./main.go:12:13: ... argument does not escape
0xc0000ae008
Go函数参数传递到底是值传递还是引用传递
Go语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。
参数如果是非引用类型(int、string、struct等这些),这样就在函数中就无法修改原内容数据;如果是引用类型(指针、map、slice、chan等这些),这样就可以修改原内容数据。
是否可以修改原内容数据,和传值、传引用没有必然的关系。在C++中,传引用肯定是可以修改原内容数据的,在Go语言里,虽然只有传值,但是我们也可以修改原内容数据,因为参数是引用类型
- 值传递
将实参的值传递给形参,形参是实参的一份拷贝,实参和形参的内存地址不同。函数内对形参值内容的修改,是否会影响实参的值内容,取决于参数是否是引用类型 - 引用传递
将实参的地址传递给形参,函数内对形参值内容的修改,将会影响实参的值内容。Go语言是没有引用传递的,在C++中,函数参数的传递方式有引用传递。
Go的值类型(int、struct等)、引用类型(指针、slice、map、channel)
-
int类型
形参和实际参数内存地址不一样,证明是值传递;参数是值类型,所以函数内对形参的修改,不会修改原内容数据 -
指针类型
形参和实际参数内存地址不一样,证明是指传递,由于形参和实参是指针,指向同一个变量。函数内对指针指向变量的修改,会修改原内容数据package mainimport "fmt"func main() {var args int64 = 1 // int类型变量p := &args // 指针类型变量fmt.Printf("原始指针的内存地址是 %p", &p) // 存放指针类型变量fmt.Printf("原始指针指向变量的内存地址 %p", p) // 存放int变量modifyPointer(p) // args就是实际参数fmt.Printf("改动后的值是: %v", *p) }func modifyPointer(p *int64) { //这里定义的args就是形式参数fmt.Printf("函数里接收到指针的内存地址是 %p", &p)fmt.Printf("函数里接收到指针指向变量的内存地址 %p", p)*p = 10 }原始指针的内存地址是 0xc000110018 原始指针指向变量的内存地址 0xc00010c008 函数里接收到指针的内存地址是 0xc000110028 函数里接收到指针指向变量的内存地址 0xc00010c008 改动后的值是: 10 -
slice类型
形参和实际参数内存地址一样,不代表是引用类型;slice是值传递,传递的是指针func main() {var s = []int64{1, 2, 3}// &操作符打印出的地址是无效的,是fmt函数作了特殊处理fmt.Printf("直接对原始切片取地址%v", &s)// 打印slice的内存地址是可以直接通过%p打印的,不用使用&取地址符转换fmt.Printf("原始切片的内存地址: %p", s)fmt.Printf("原始切片第一个元素的内存地址: %p", &s[0])modifySlice(s)fmt.Printf("改动后的值是: %v", s) }func modifySlice(s []int64) {// &操作符打印出的地址是无效的,是fmt函数作了特殊处理fmt.Printf("直接对函数里接收到切片取地址%v", &s)// 打印slice的内存地址是可以直接通过%p打印的,不用使用&取地址符转换fmt.Printf("函数里接收到切片的内存地址是 %p", s)fmt.Printf("函数里接收到切片第一个元素的内存地址: %p", &s[0])s[0] = 10 }slice是一个结构体,他的第一个元素是一个指针类型,这个指针指向的是底层数组的第一个元素。当参数是slice类型的时候,fmt.printf通过%p打印的slice变量的地址其实就是内部存储数组元素的地址,所以打印出来形参和实参内存地址一样。
-
map类型
通过make函数创建的map变量本质是一个hmap类型的指针*hmap,所以函数内对形参的修改,会修改原内容数据 -
channel类型
通过make函数创建的chan变量本质是一个hchan类型的指针*hchan,所以函数内对形参的修改,会修改原内容数据 -
struct类型
形参不是引用类型或者指针类型,所以函数内对形参的修改,不会修改原内容数据
defer
defer 能够让我们推迟执行某些函数调用,推迟到当前函数返回前才实际执行。defer与panic和recover结合,形成了Go语言风格的异常与捕获机制。
使用场景:
defer 语句经常被用于处理成对的操作,如文件句柄关闭、连接关闭、释放锁
优点:
方便开发者使用
缺点:
有性能损耗
实现原理:
Go1.14中编译器会将defer函数直接插入到函数的尾部,无需链表和栈上参数拷贝,性能大幅提升。把defer函数在当前函数内展开并直接调用,这种方式被称为open coded defer
Recover
recover只有在defer调用的函数中有效
如果调用了内置函数recover,并且定义该defer语句的函数发生了panic异常,recover会使用程序从panic中恢复,并且返回panic value,导致panic异常的函数不会继续执行,但能正常返回。在未发生panic时调用recover,recover会返回nil。
package mainimport "fmt"func testa(){fmt.Println("aaaaaaa")
}func testb(x int){//设置recover,defer func(){//recover()可以打印panic的错误信息//fmt.Println(recover())if err := recover(); err != nil{ //产生了panic异常fmt.Println(err)}}()var a [10]inta[x] = 111
}func testc(){fmt.Println("ccccccc")
}
func main(){testa()testb(20)testc()
}
Go内置函数make和new的区别
变量初始化,一般包括2步,变量声明 + 变量内存分配,var关键字就是用来声明变量的,new和make函数主要是用来分配内存的
var声明值类型的变量时,系统会默认为他分配内存空间,并赋该类型的零值
比如布尔、数字、字符串、结构体
如果指针类型或者引用类型的变量,系统不会为它分配内存,默认就是nil。此时如果你想直接使用,那么系统会抛异常,必须进行内存分配后,才能使用。
new 和 make 两个内置函数,主要用来分配内存空间,有了内存,变量就能使用了,主要有以下2点区别:
-
使用场景区别:
-
make 只能用来分配及初始化类型为slice、map、chan 的数据。
-
new 可以分配任意类型的数据,并且置零。
-
-
返回值区别:
- make函数原型如下,返回的是slice、map、chan类型本身,这3种类型是引用类型,就没有必要返回他们的指针
func make(t Type, size ...IntegerType) Type- new函数原型如下,返回一个指向该类型内存地址的指针
func new(Type) *Type
面向对象
封装:隐藏内部的实现细节,通过指定的方法对成员进行合法的访问
继承:通过结构体的嵌套进行实现
多态:多态特征是通过接口实现的。可以按照统一的接口来调用不同的实现。这时接口变量就呈现不同的形态。
泛型
基于gcshape和dict实现
泛型通过中括号类型约束实现多种不同类型的参数进行函数调用。
约束条件通过接口实现:接口可以定义类型集合。
指针类型或者相同的底层类型属于同一个gcshape
泛型会让具有相同gcshape的类型共用一套代码。
每次调用函数时会传递一个字典,字典的内容包括:具体参数类型信息,派生类型信息,子字典区间,itab区间。
参考视频
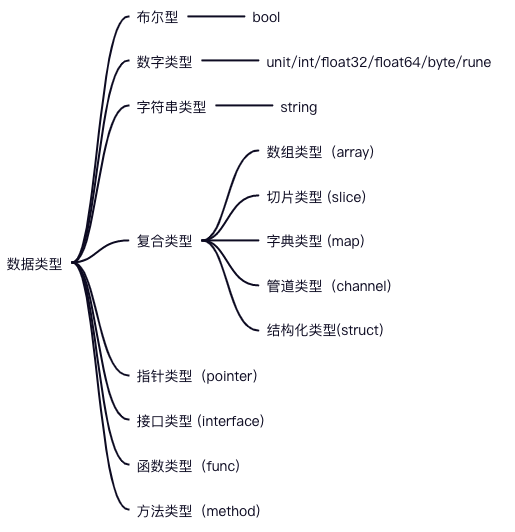
元数据类型
接口
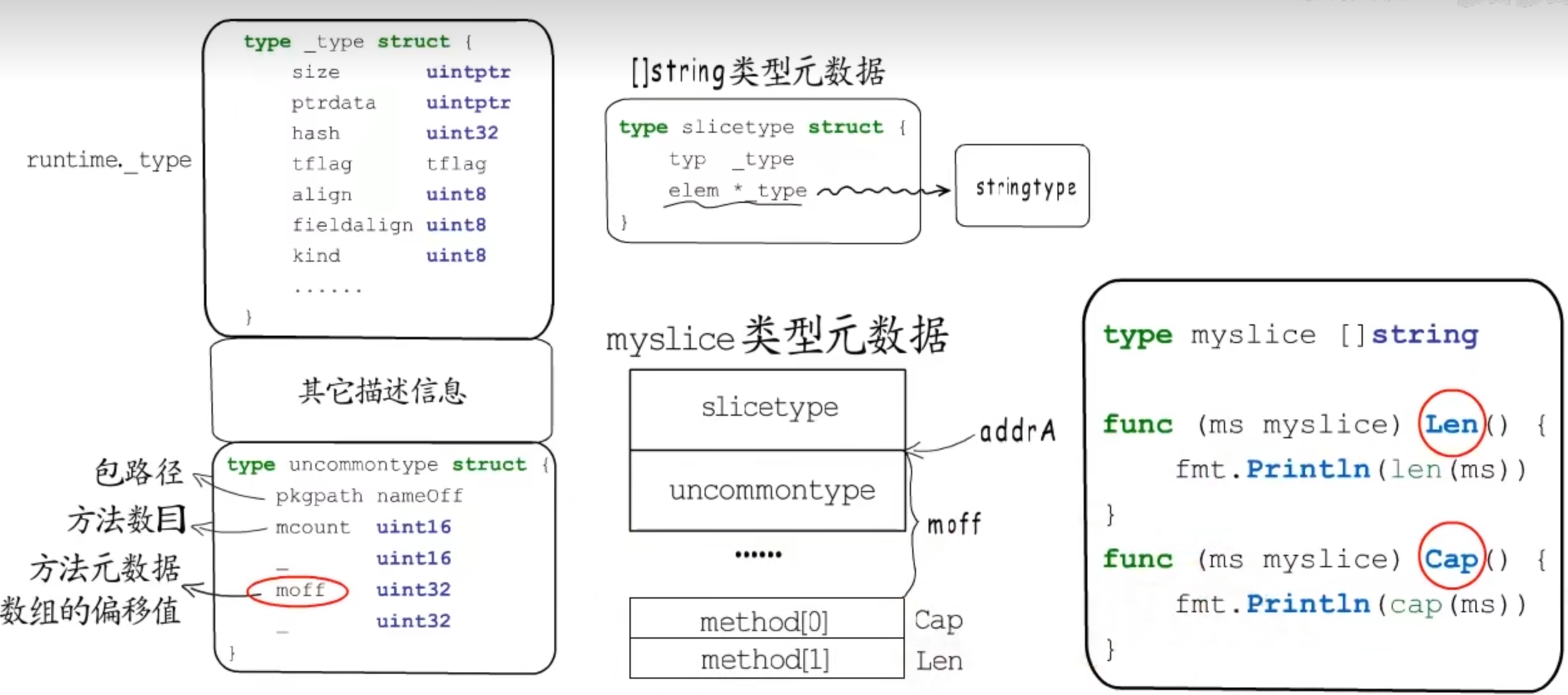
空接口
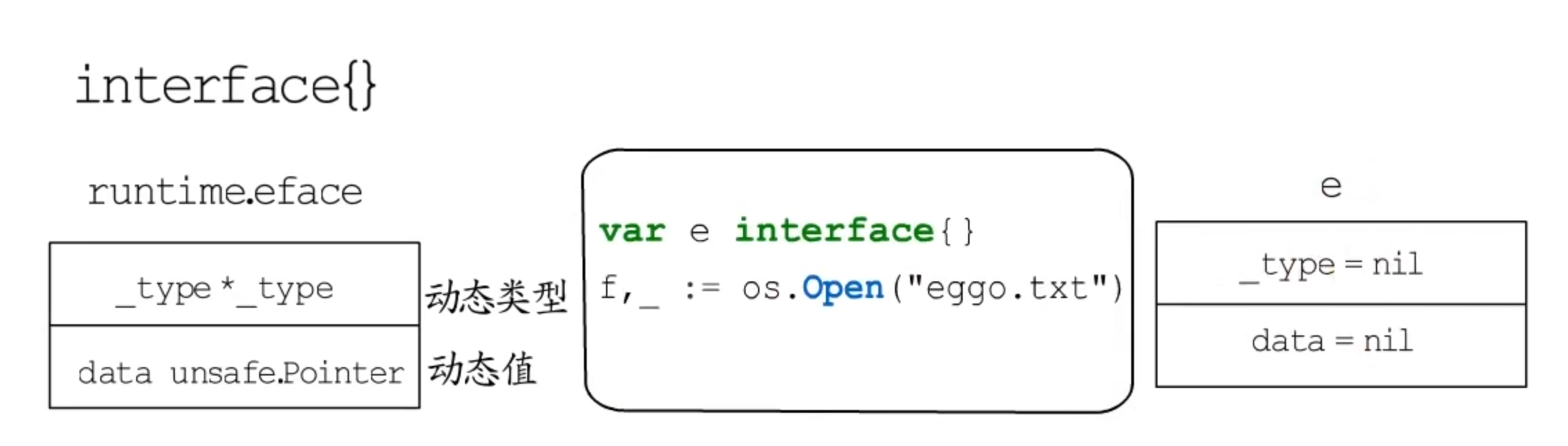
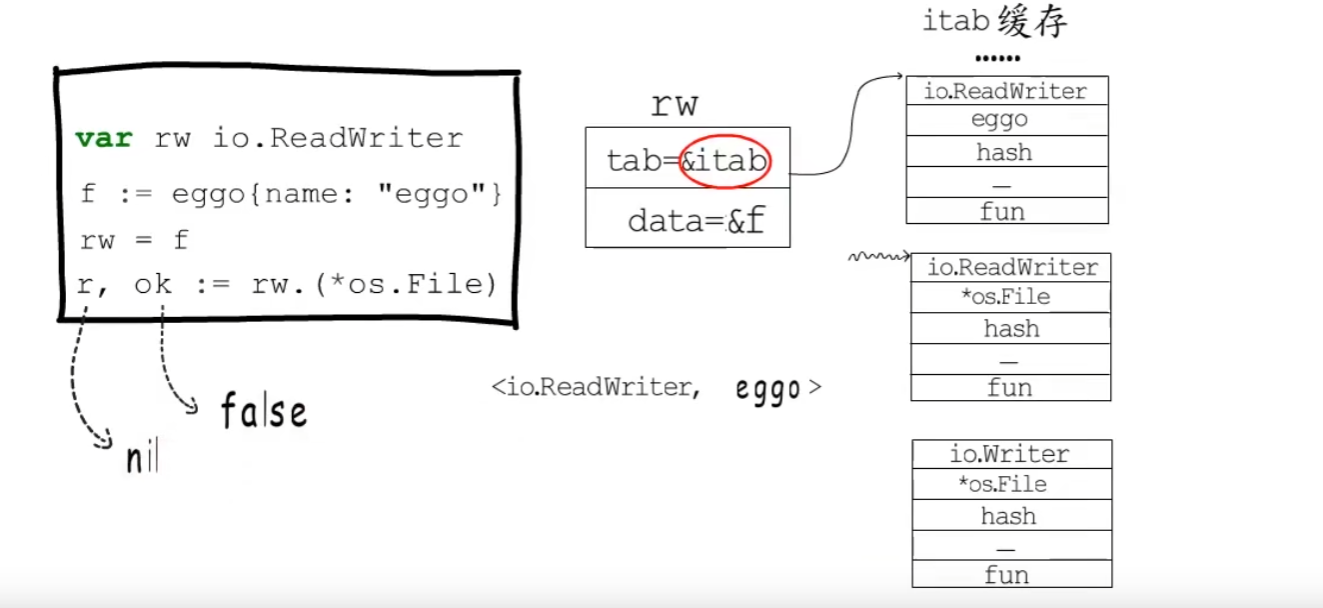
空接口类型变量赋值前后的变化
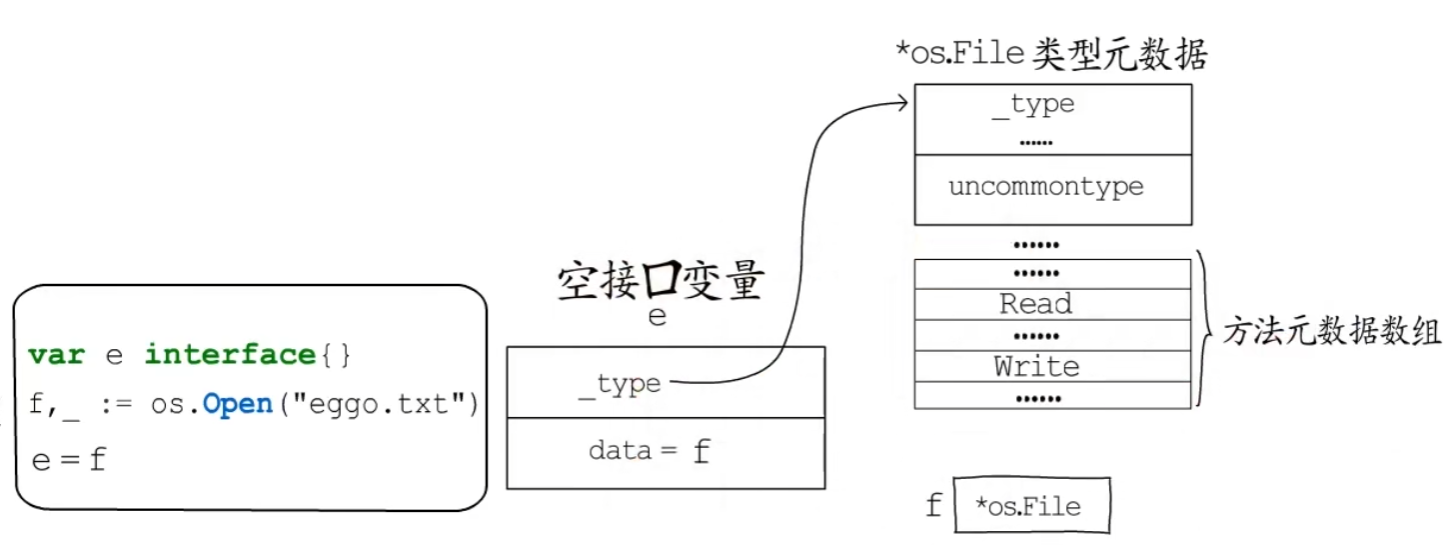
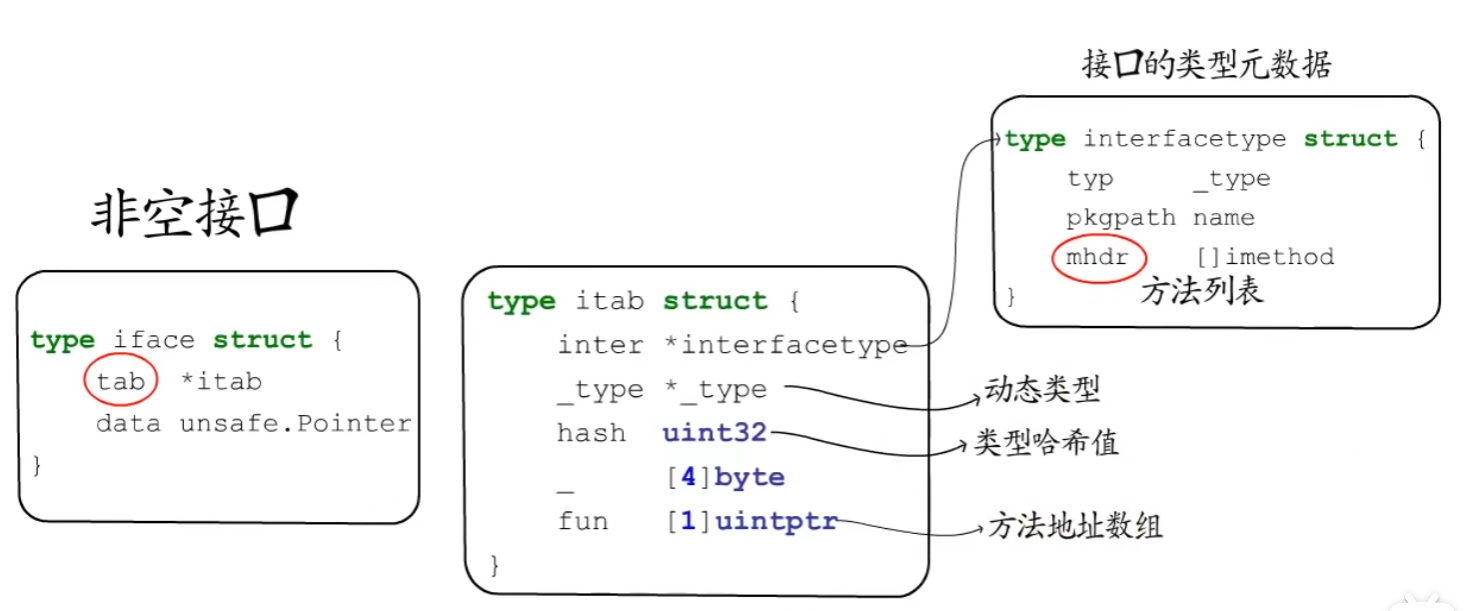
非空接口
有方法列表的接口类型
一个变量要赋值给非空接口类型,必须要实现该接口要求的所有方法。
data指向该接口的动态值
tab 记录接口类型、动态类型和方法列表
Itab缓存
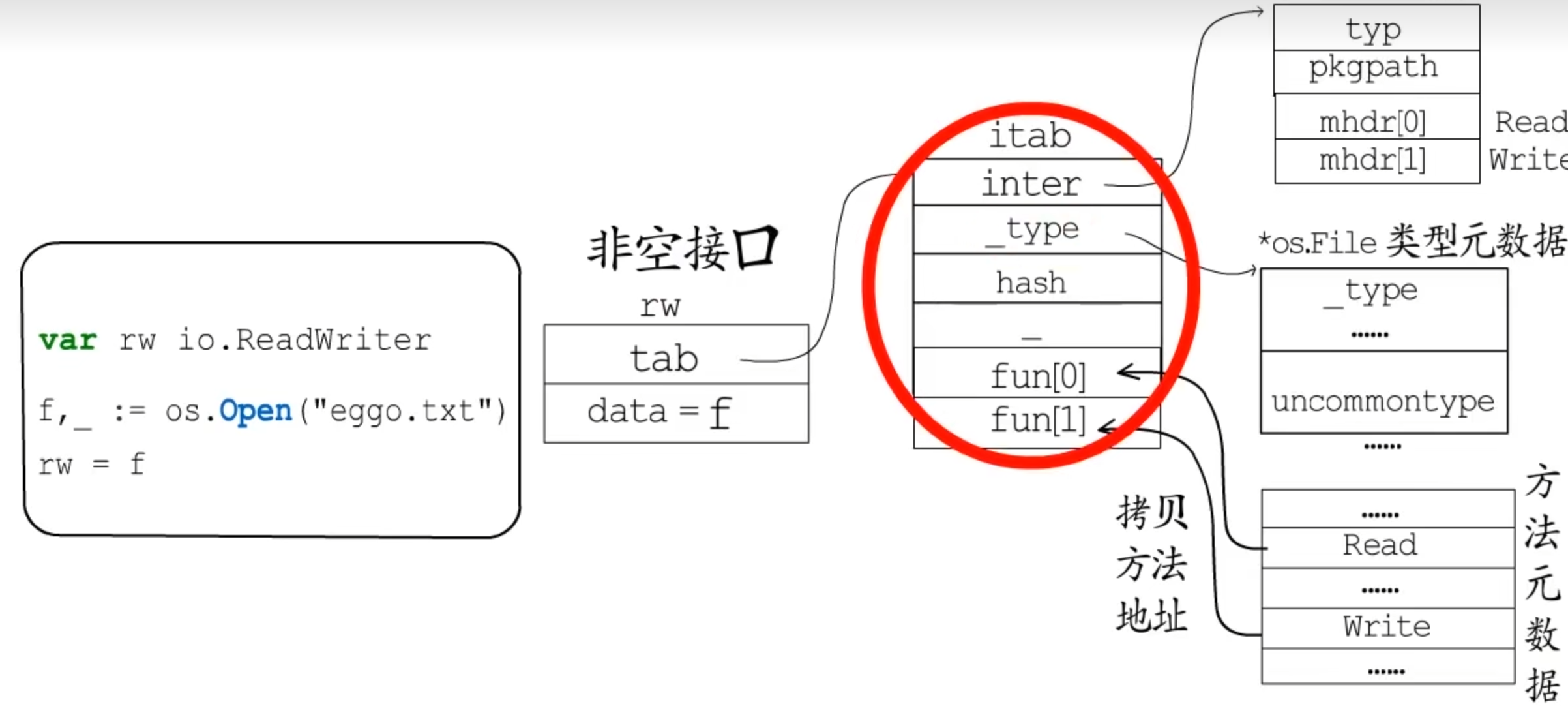
一旦接口类型和动态类型确定,就可以确定一个唯一的itab。
接口类型的hash值与动态类型的hash值做异或运算作为key,itab作为value保存再hash表中。
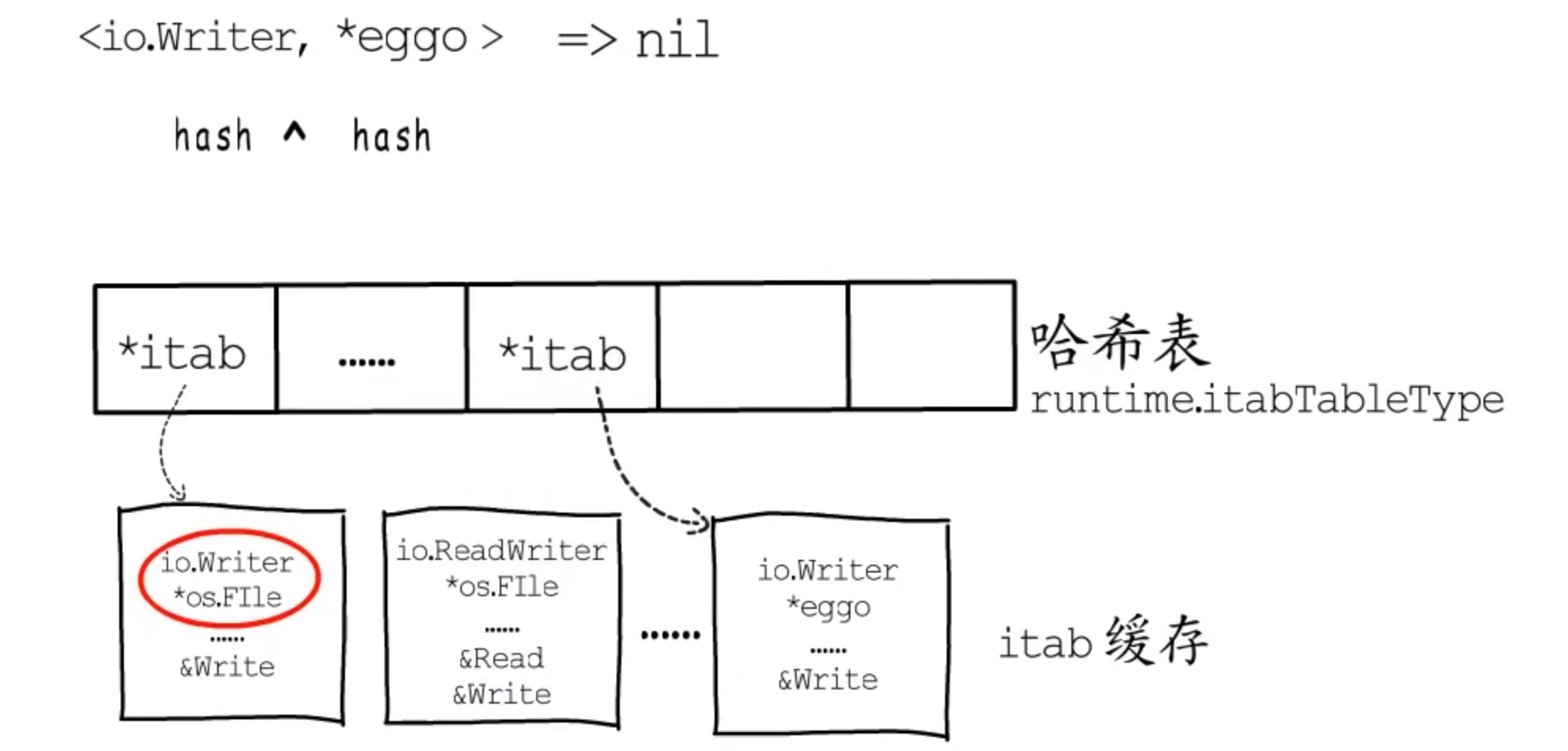
断言
类型断言的关键是明确动态接口的类型,以及对应的类型实现的方法。
空接口.(具体类型)
判断_type是否指向指定类型的元数据
非空接口.(具体类型)
判断tab是否指向对应的itab结构体
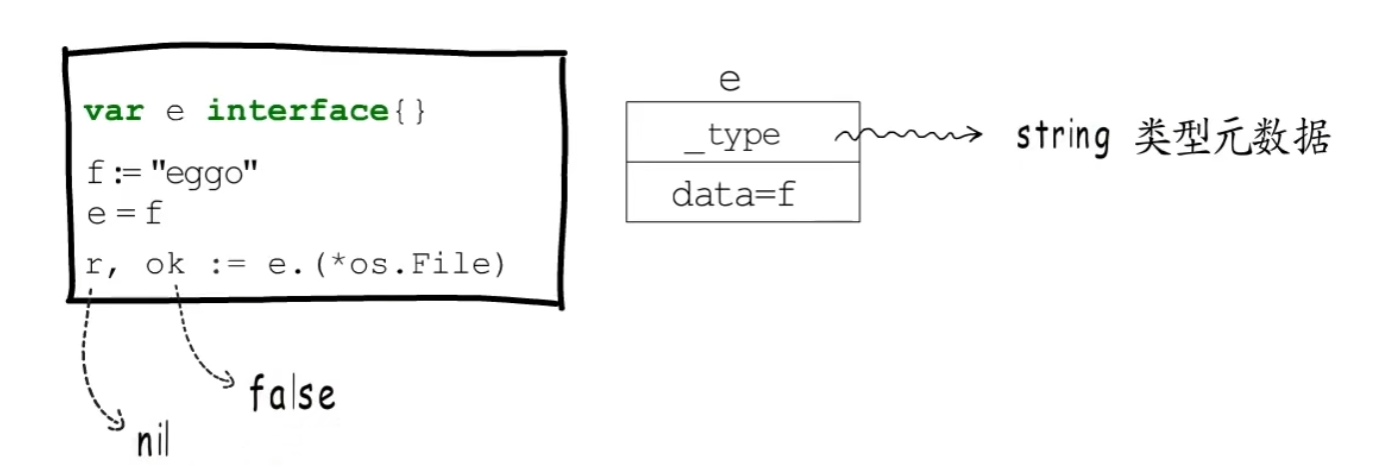
空接口.(非空接口)
判断对应的类型元数据是否实现了对应接口的方法,断言失败会将fun[0]置为0,添加到itab缓存中
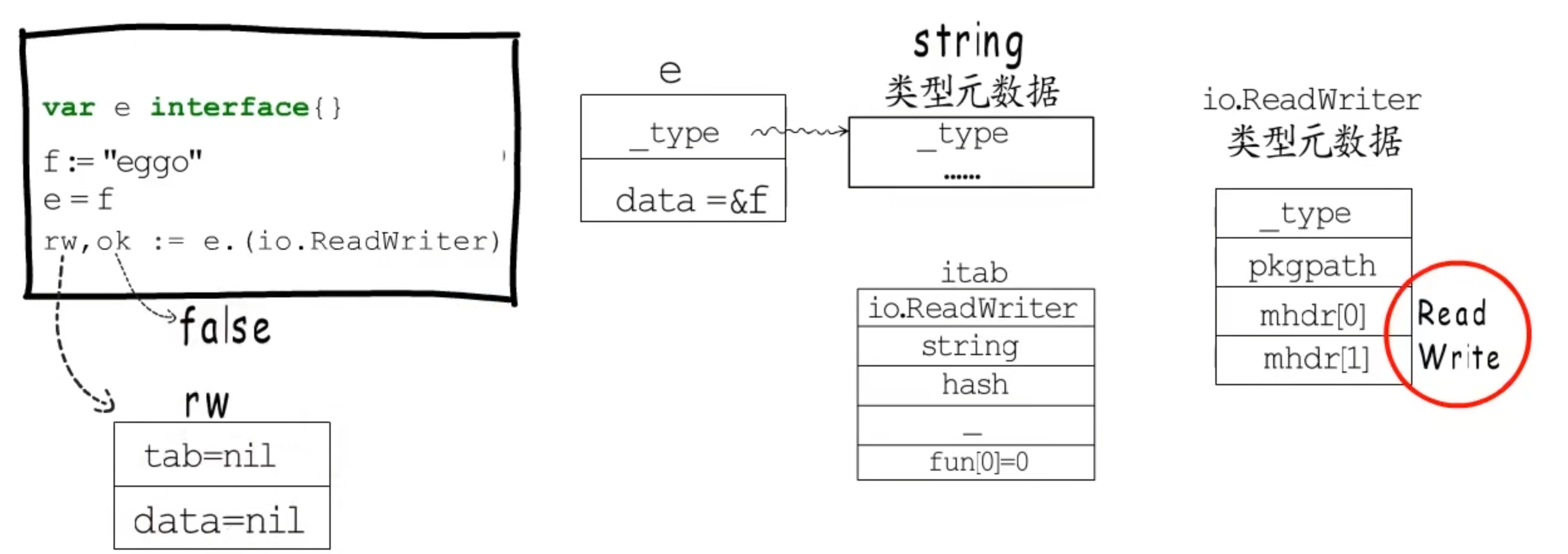
非空接口.(非空接口)
判断对应的tab有没有包含接口需要实现的方法
String
// src/runtime/string.go
type stringStruct struct {str unsafe.Pointerlen int
}
str:一个指针,指向存储实际字符串的内存地址。
len:字符串的长度。与切片类似,在代码中我们可以使用len()函数获取这个值。注意,len存储实际的字节数,而非字符数。
Slice(非线程安全)
type slice struct {array unsafe.Pointerlen intcap int
}
Slice 初始化方式
初始化slice调用的是runtime.makeslice,makeslice函数的工作主要就是计算slice所需内存大小,然后调用mallocgc进行内存的分配
// 初始化方式1:直接声明
var slice1 []int// 初始化方式2:使用字面量
slice2 := []int{1, 2, 3, 4}// 初始化方式3:使用make创建slice
slice3 := make([]int, 3, 5) // 初始化方式4: 从切片或数组“截取”
slcie4 := arr[1:3]
Go array和slice的区别
-
数组长度不同
数组初始化必须指定长度,并且长度就是固定的
切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大
-
函数传参不同
数组是值类型,将一个数组赋值给另一个数组时,传递的是一份深拷贝,函数传参操作都会复制整个数组数据,会占用额外的内存,函数内对数组元素值的修改,不会修改原数组内容。
切片是引用类型,将一个切片赋值给另一个切片时,传递的是一份浅拷贝,函数传参操作不会拷贝整个切片,只会复制len和cap,底层共用同一个数组,不会占用额外的内存,函数内对数组元素值的修改,会修改原数组内容。
-
计算数组长度方式不同
数组需要遍历计算数组长度,时间复杂度为O(n)
切片底层包含len字段,可以通过len()计算切片长度,时间复杂度为O(1)
深拷贝和浅拷贝
-
深拷贝:拷贝的是数据本身,创造一个新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值
- 实现深拷贝的方式:
copy(slice2, slice1)- 遍历append赋值
-
浅拷贝:拷贝的是数据地址,只复制指向的对象的指针,此时新对象和老对象指向的内存地址是一样的,新对象值修改时老对象也会变化
引用类型的变量,默认赋值操作就是浅拷贝
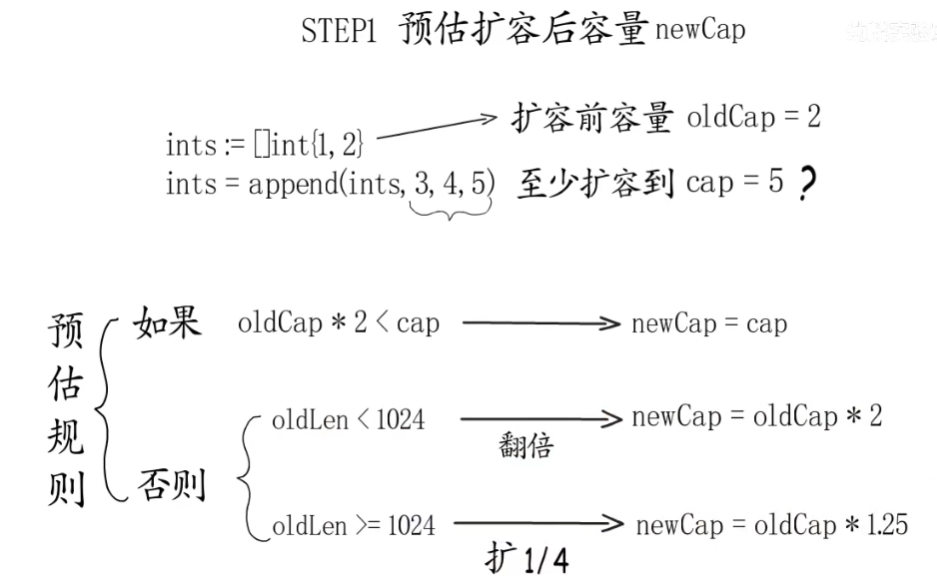
扩容机制
扩容会发生在slice append的时候,当slice的cap不足以容纳新元素,就会进行扩容,扩容规则如下
- 如果新申请容量比两倍原有容量大,那么扩容后容量大小 为 新申请容量
- 如果原有 slice 长度小于 1024, 那么每次就扩容为原来的 2 倍
- 如果原 slice 长度大于等于 1024, 那么每次扩容就扩为原来的 1.25 倍
Map
Go中的map是一个指针,占用8个字节,指向hmap结构体
hmap包含若干个结构为bmap的数组,每个bmap底层都采用链表结构,bmap通常叫其bucket
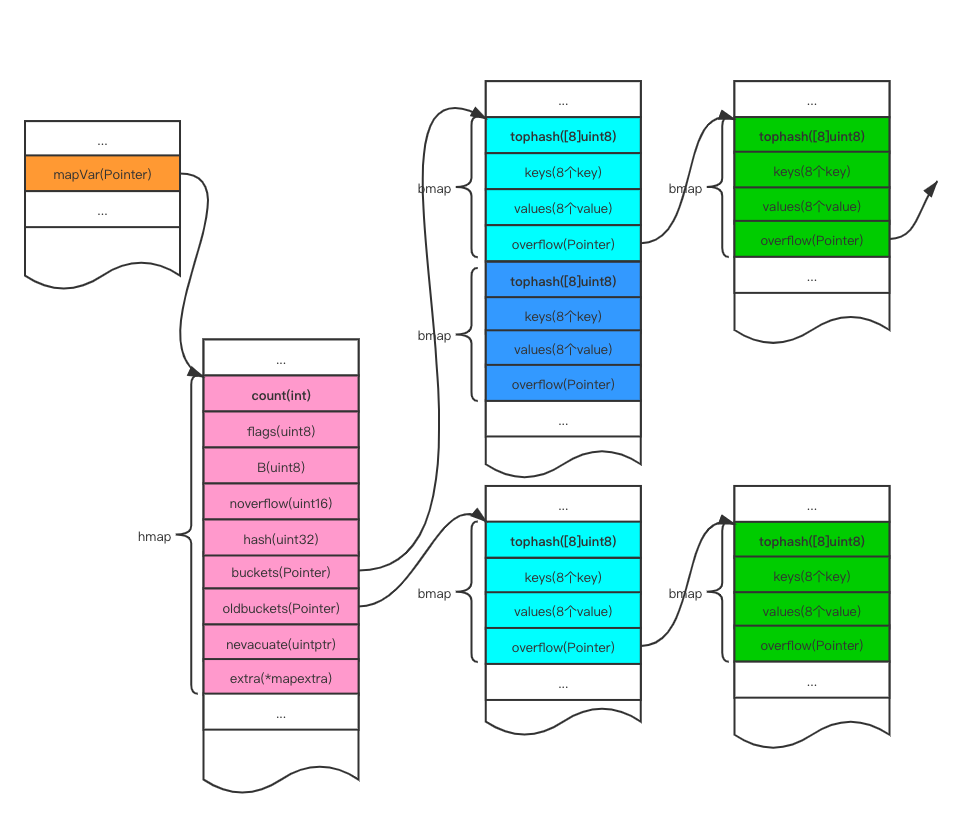
hmap 的结构体
// A header for a Go map.
type hmap struct {count int // 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。flags uint8 // 状态标志(是否处于正在写入的状态等)B uint8 // buckets(桶)的对数// 如果B=5,则buckets数组的长度 = 2^B=32,意味着有32个桶noverflow uint16 // 溢出桶的数量hash0 uint32 // 生成hash的随机数种子buckets unsafe.Pointer // 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。oldbuckets unsafe.Pointer // 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。nevacuate uintptr // 表示扩容进度,小于此地址的buckets代表已搬迁完成。extra *mapextra // 存储溢出桶,这个字段是为了优化GC扫描而设计的,下面详细介绍
}
bmap结构体
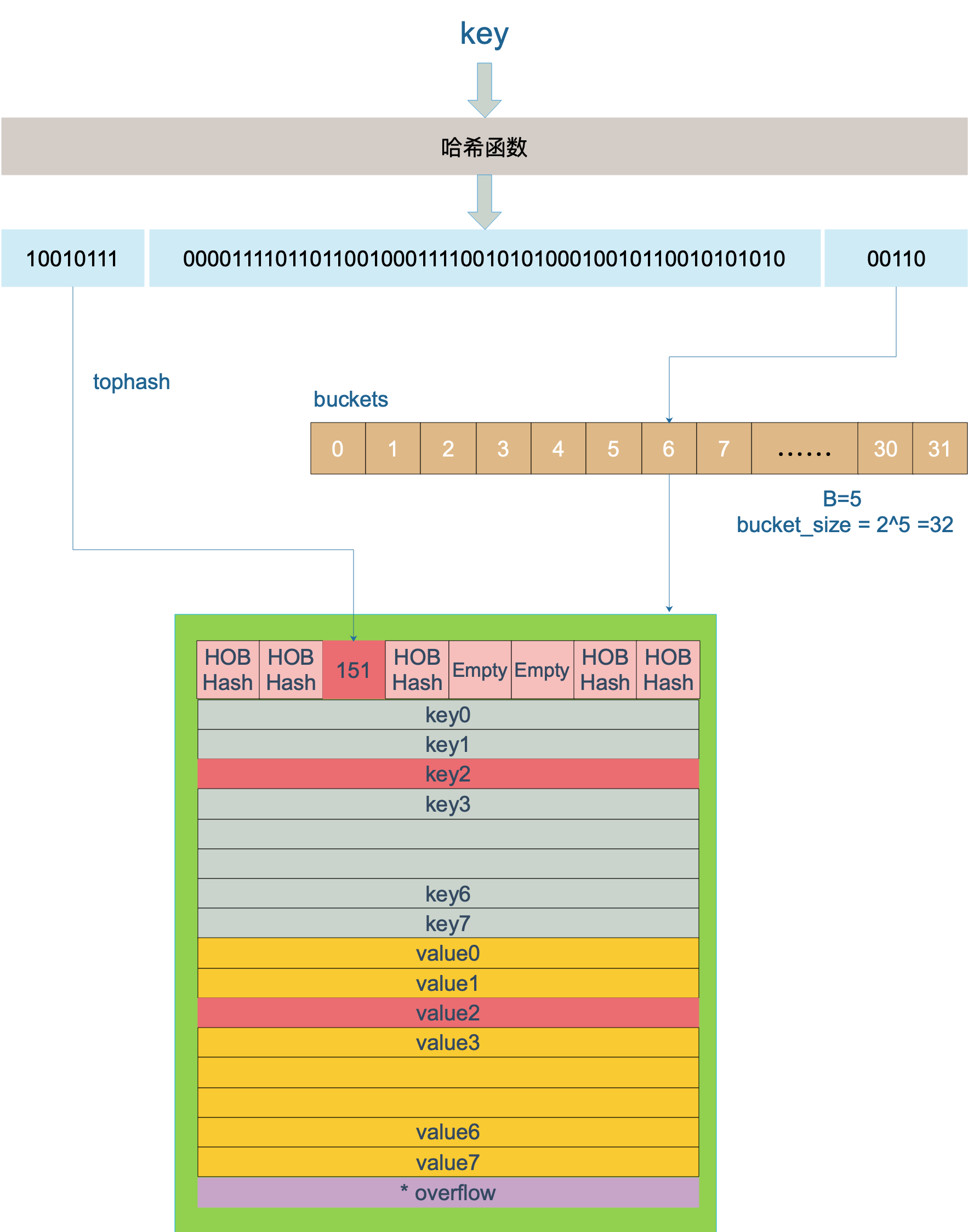
bmap 就是我们常说的“桶”,一个桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果的低B位是相同的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
// A bucket for a Go map.
type bmap struct {tophash [bucketCnt]uint8 // len为8的数组// 用来快速定位key是否在这个bmap中// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}
上面bmap结构是静态结构,在编译过程中runtime.bmap会拓展成以下结构体:
type bmap struct{tophash [8]uint8keys [8]keytype // keytype 由编译器编译时候确定values [8]elemtype // elemtype 由编译器编译时候确定overflow uintptr // overflow指向下一个bmap,overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
tophash就是用于实现快速定位key的位置,在实现过程中会使用key的hash值的高8位作为tophash值,存放在bmap的tophash字段中
tophash字段不仅存储key哈希值的高8位,还会存储一些状态值,用来表明当前桶单元状态,这些状态值都是小于minTopHash的
为了避免key哈希值的高8位值和这些状态值相等,产生混淆情况,所以当key哈希值高8位若小于minTopHash时候,自动将其值加上minTopHash作为该key的tophash。桶单元的状态值如下:-
emptyRest = 0 // 表明此桶单元为空,且更高索引的单元也是空
emptyOne = 1 // 表明此桶单元为空
evacuatedX = 2 // 用于表示扩容迁移到新桶前半段区间
evacuatedY = 3 // 用于表示扩容迁移到新桶后半段区间
evacuatedEmpty = 4 // 用于表示此单元已迁移
minTopHash = 5 // key的tophash值与桶状态值分割线值,小于此值的一定代表着桶单元的状态,大于此值的一定是key对应的tophash值func tophash(hash uintptr) uint8 {top := uint8(hash >> (goarch.PtrSize*8 - 8))if top < minTopHash {top += minTopHash}return top
}
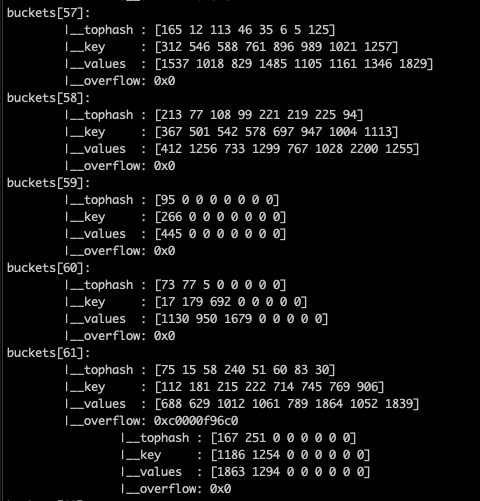
bmap(bucket)内存数据结构可视化如下:
注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/… 这样的形式,当key和value类型不一样的时候,key和value占用字节大小不一样,使用key/value这种形式可能会因为内存对齐导致内存空间浪费,所以Go采用key和value分开存储的设计,更节省内存空间
bmap(bucket)内存数据结构可视化如下:
mapextra结构体
当map的key和value都不是指针类型时候,bmap将完全不包含指针,那么gc时候就不用扫描bmap。bmap指向溢出桶的字段overflow是uintptr类型,为了防止这些overflow桶被gc掉,所以需要mapextra.overflow将它保存起来。如果bmap的overflow是*bmap类型,那么gc扫描的是一个个拉链表,效率明显不如直接扫描一段内存(hmap.mapextra.overflow)
type mapextra struct {overflow *[]*bmap// overflow 包含的是 hmap.buckets 的 overflow 的 bucketsoldoverflow *[]*bma// oldoverflow 包含扩容时 hmap.oldbuckets 的 overflow 的 bucketnextOverflow *bmap // 指向空闲的 overflow bucket 的指针
}
Map 的无序性
- map在遍历时,并不是从固定的0号bucket开始遍历的,每次遍历,都会从一个随机值序号的bucket,再从其中随机的cell开始遍历
- map遍历时,是按序遍历bucket,同时按序遍历bucket中和其overflow bucket中的cell。但是map在扩容后,会发生key的搬迁,这造成原来落在一个bucket中的key,搬迁后,有可能会落到其他bucket中了,从这个角度看,遍历map的结果就不可能是按照原来的顺序了
- 使用
sort.Slice对 key 进行排序,实现Map 的有序性
Map 是非线程安全的
map默认是并发不安全的,同时对map进行并发读写时,程序会panic,fatal error: concurrent map writes
Go 官方在经过了长时间的讨论后,认为 Go map 更应适配典型使用场景(不需要从多个 goroutine 中进行安全访问),而不是为了小部分情况(并发访问),导致大部分程序付出加锁代价(性能),决定了不支持。
实现map线程安全
- 使用读写锁 map + sync.RWMutex
package mainimport (
"fmt"
"sync"
"time"
)func main() {var lock sync.RWMutexs := make(map[int]int)for i := 0; i < 100; i++ {go func(i int) {lock.Lock()s[i] = ilock.Unlock()}(i)}for i := 0; i < 100; i++ {go func(i int) {lock.RLock()fmt.Printf("map第%d个元素值是%d", i, s[i])lock.RUnlock()}(i)}time.Sleep(1 * time.Second)
}
- 使用Go提供的 sync.Map
package mainimport (
"fmt"
"sync"
"time"
)func main() {var m sync.Mapfor i := 0; i < 100; i++ {go func(i int) {m.Store(i, i)}(i)}for i := 0; i < 100; i++ {go func(i int) {v, ok := m.Load(i)fmt.Printf("Load: %v, %v", v, ok)}(i)}time.Sleep(1 * time.Second)
}
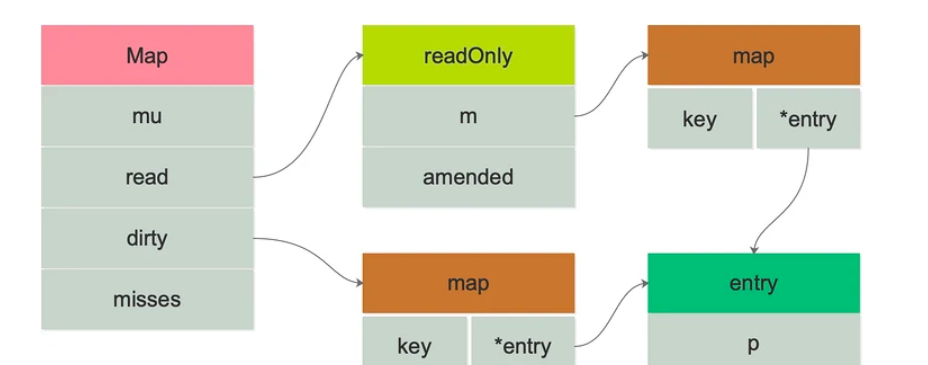
Sync.Map 结构体
type Map struct {mu Mutex// 持有部分map的数据并且并发读不需要持有锁,但是改变指针需要持有锁read atomic.Value // readOnly// 包含部分map数据需要持有锁保护 为了保证dirty map能够快速晋升为read map,// 它还包含所有在read map未清除的数据// expunged数据不会存储在dirty map// 如果dirtymap为nil则下一次写会从read map拷贝一份数据dirty map[interface{}]*entry// 记录从read map中读不到数据,加锁去判断key是否存在的次数// 当misses等于dirty map长度时,dirty map会直接晋升为read map// 下次写操作再从read map拷贝一份数据misses int
}//sync.Map中的 read实际指向的是readOnly结构体对象// readOnly 是一个不可变结构体 自动存储在Map.read字段中
type readOnly struct {m map[interface{}]*entryamended bool // 如果key在dirty不在m中 则为true如果为false则表示dirty为空
}// map中的key 指向的value
type entry struct {// p指向interface{}类型的值// 如果p==nil,表明entry已经被删除并且m.dirty==nil// 如果p==expunged,表明entry已经被删除且m.dirty!=nil 并且entry不在m.dirty中// 否则entry是有效的并且记录m.read.m[key] 并且如果m.dirty!=nil 则也存在m.dirty[key]// 当m.dirty重建的时候被删除的entry会被检测到并自动由nil替换为expunged 并且不会设置m.dirty[key]// 若p!=expunged,则entry关联的值可以通过原子替换来更新// 若p==expunged,则需要先设置m.dirty[key]=e之后才能更新entry关联的值,这样以便使用dirty map查找值p unsafe.Pointer // *interface{}
}
- mu: 互斥锁,保护 read 和 dirty
- read: 只读数据,指出并发读取 (atomic.Value 类型) 。如果需要更新 read,需要加锁保护数据安全。
- read 实际存储的是 readOnly 结构体,内部是一个原生 map,amended 属性用于标记 read 和 dirty 的数据是否一致
- dirty: 读写数据,非线性安全的原生 map。包含新写入的 key,并且包含 read 中所有未被删除的 key。
- misses: 统计有多少次读取 read 没有被命中。每次 read 读取失败后,misses 的计数加 1。
在 read 和 dirty 中,都涉及到的结构体:
type entry struct {p unsafe.Pointer // *interface{}
}
其中包含一个 p 指针,用于指向用户存储的元素(key)所指向的 value 值。
read 和 dirty 各自维护一套 key,key 指向的都是同一个 value。也就是说,只要修改了这个 entry,对 read 和 dirty 都是可见的。这个指针的状态有三种:

-
当 p == nil 时,说明这个键值对已被删除,并且 m.dirty == nil,或 m.dirty[k] 指向该 entry。
-
当 p == expunged 时,说明这条键值对已被删除,并且 m.dirty != nil,且 m.dirty 中没有这个 key。
-
其他情况,p 指向一个正常的值,表示实际 interface{} 的地址,并且被记录在 m.read.m[key] 中。如果这时 m.dirty 不为 nil,那么它也被记录在 m.dirty[key] 中。两者实际上指向的是同一个值。
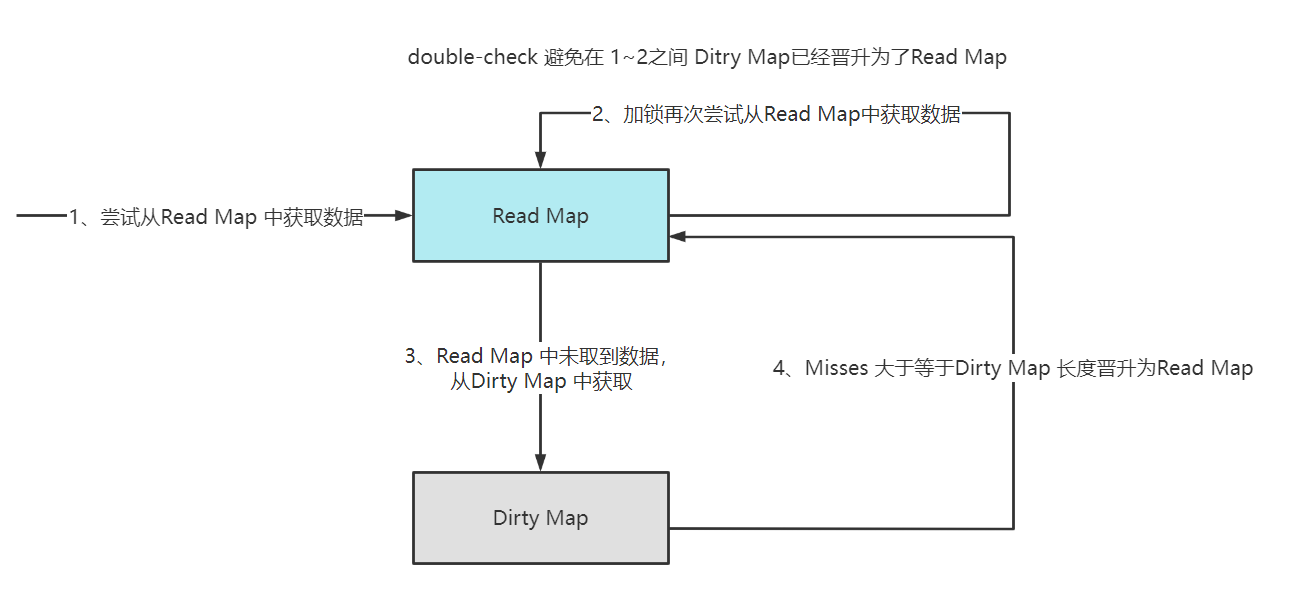
Load 操作
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {read, _ := m.read.Load().(readOnly)e, ok := read.m[key]if !ok && read.amended {m.mu.Lock()// double-check 避免我们获得锁期间 ditry map已经晋升为了read mapread, _ = m.read.Load().(readOnly)e, ok = read.m[key]if !ok && read.amended {//不存在 且map.dirty包含了部分不在read map中的数据e, ok = m.dirty[key]//记录miss 当前这个key会一直执行slow path直到dirty map晋升为read mapm.missLocked()}m.mu.Unlock()}if !ok {return nil, false}return e.load()
}
Store 操作
Store()操作在key存在并且value不处于expunged状态下会覆盖原有的值
// Store sets the value for a key.
func (m *Map) Store(key, value interface{}) {// 情况1read, _ := m.read.Load().(readOnly)if e, ok := read.m[key]; ok && e.tryStore(&value) {return}m.mu.Lock()read, _ = m.read.Load().(readOnly)if e, ok := read.m[key]; ok {if e.unexpungeLocked() {//情况2// The entry was previously expunged, which implies that there is a// non-nil dirty map and this entry is not in it.m.dirty[key] = e}e.storeLocked(&value) // 情况3 e.unexpungeLocked()为false的情况} else if e, ok := m.dirty[key]; ok {//情况4e.storeLocked(&value)} else {//情况5if !read.amended {// We're adding the first new key to the dirty map.// Make sure it is allocated and mark the read-only map as incomplete.m.dirtyLocked()m.read.Store(readOnly{m: read.m, amended: true})}m.dirty[key] = newEntry(value)}m.mu.Unlock()
}
- 如果key已经在read map存在了 且dirty map中未被删除
通过调用e.tryStore(&value)直接无锁情况下,更新对应值。 - 如果key存在于read map,不在dirty map中
先将key-value放到dirty map中,然后直接更新value,因为read map和dirty map持有的是相同的引用 - 如果key同时存在于read map和dirty map
接更新read map的值即可 - 如果key不在read map但存在于dirty map
这种情况直接更新即可,因为已经拿到锁了 所以是协程安全的 - 如果key不在read map也不存在于dirty map
首先判断read.amended若为false 则表明dirty map刚刚晋升为read map,此时dirty map为nil。然后调用m.dirtyLocked()
将read map中的数据引用拷贝一份后,针对新来的数据 m.dirty[key] = newEntry(value)新建并插入
Delete 操作
- key存在于read map则直接调用e.delete()将其置为nil
- key不在read map但存在于dirty map,则直接调用内建delete方法从map中删除元素
- key都不存在 直接返回
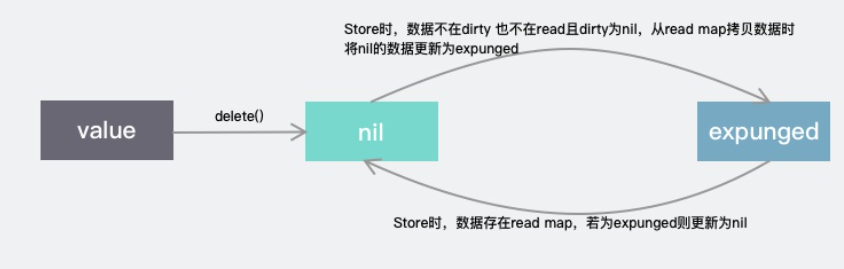
expunged是一个标记,表示dirty map中对应的值已经被干掉了。
Map 查找
Go 语言中读取 map 有两种语法:带 comma 和 不带 comma。当要查询的 key 不在 map 里,带 comma 的用法会返回一个 bool 型变量提示 key 是否在 map 中;而不带 comma 的语句则会返回一个 value 类型的零值。如果 value 是 int 型就会返回 0,如果 value 是 string 类型,就会返回空字符串。
// 不带 comma 用法
value := m["name"]
fmt.Printf("value:%s", value)// 带 comma 用法
value, ok := m["name"]
if ok {
fmt.Printf("value:%s", value)
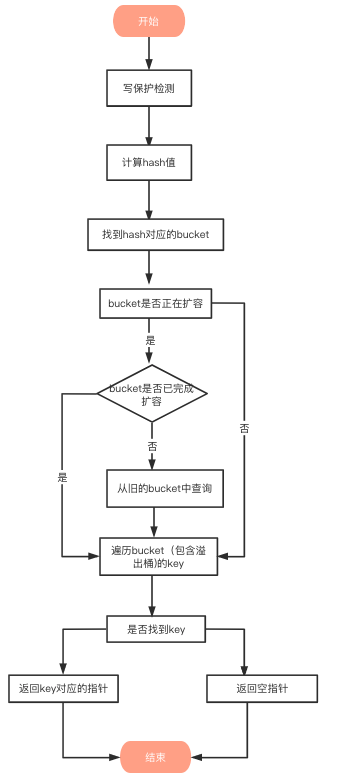
-
写保护监测
函数首先会检查 map 的标志位 flags。如果 flags 的写标志位此时被置 1 了,说明有其他协程在执行“写”操作,进而导致程序 panic,这也说明了 map 不是线程安全的if h.flags&hashWriting != 0 {throw("concurrent map read and map write") } -
计算 hash
key经过哈希函数计算后,得到的哈希值如下(64位机器共 64 个 bit 位), 不同类型的key会有不同的hash函数10010111 | 000011110110110010001111001010100010010110010101010 | 01010 -
找到hash对应的bucket
bucket定位:哈希值的低B个bit 位,用来定位key所存放的bucket
如果当前正在扩容中,并且定位到的旧bucket数据还未完成迁移,则使用旧的bucket(扩容前的bucket) -
遍历 Bucket查找
tophash值定位:哈希值的高8个bit 位,用来快速判断key是否已在当前bucket中(如果不在的话,需要去bucket的overflow中查找)
用步骤2中的hash值,得到高8个bit位,也就是10010111,转化为十进制,也就是151top := tophash(hash) func tophash(hash uintptr) uint8 {top := uint8(hash >> (goarch.PtrSize*8 - 8))if top < minTopHash {top += minTopHash}return top }上面函数中hash是64位的,sys.PtrSize值是8,所以top := uint8(hash >> (sys.PtrSize*8 - 8))等效top = uint8(hash >> 56),最后top取出来的值就是hash的高8位值
在 bucket 及bucket的overflow中寻找tophash 值(HOB hash)为 151 的 槽位,即为key所在位置。
-
返回key对应的指针
上面的步骤找到了key对应的槽位下标 i
bucket 里 keys 的起始地址就是 unsafe.Pointer(b)+dataOffset第 i 个下标 key 的地址就要在此基础上跨过 i 个 key 的大小;
而我们又知道,value 的地址是在所有 key 之后,因此第 i 个下标 value 的地址还需要加上所有 key 的偏移。
// keys的偏移量 dataOffset = unsafe.Offsetof(struct{b bmapv int64 }{}.v)// 一个bucket的元素个数 bucketCnt = 8// key 定位公式 k :=add(unsafe.Pointer(b),dataOffset+i*uintptr(t.keysize))// value 定位公式 v:= add(unsafe.Pointer(b),dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
Map 冲突解决的方式
Go map也采用链地址法解决冲突,具体就是插入key到map中时,当key定位的桶填满8个元素后(这里的单元就是桶,不是元素),将会创建一个溢出桶,并且将溢出桶插入当前桶所在链表尾部。
Map 扩容
扩容时机
当 map存储的元素个数大于或等于 6.5 * 桶个数 时,就会触发扩容行为。
扩容条件:
在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容
-
超过负载:map元素个数 > 6.5 * 桶个数
func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactor*bucketShift(B) }其中 bucketCnt = 8,一个桶可以装的最大元素个数 loadFactor = 6.5,负载因子,平均每个桶的元素个数 bucketShift(B): 桶的个数 -
溢出桶太多
- 当桶总数 < 2 ^ 15 时,如果溢出桶总数 >= 桶总数,则认为溢出桶过多。
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {// If the threshold is too low, we do extraneous work.// If the threshold is too high, maps that grow and shrink can hold on to lots of unused memory.// "too many" means (approximately) as many overflow buckets as regular buckets.// See incrnoverflow for more details.if B > 15 {B = 15}// The compiler does not see here that B < 16; mask B to generate shorter shift code.return noverflow >= uint16(1)<<(B&15) }- 当桶总数 >= 2 ^ 15 时,直接与 2 ^ 15 比较,当溢出桶总数 >= 2 ^ 15 时,即认为溢出桶太多了。
扩容机制:
-
双倍扩容:针对条件1,新建一个buckets数组,新的buckets大小是原来的2倍,然后旧buckets数据搬迁到新的buckets。该方法我们称之为双倍扩容
-
等量扩容:针对条件2,并不扩大容量,buckets数量维持不变,重新做一遍类似双倍扩容的搬迁动作,把松散的键值对重新排列一次,使得同一个 bucket 中的 key 排列地更紧密,节省空间,提高 bucket 利用率,进而保证更快的存取。该方法我们称之为等量扩容。
扩容函数:
上面说的 hashGrow() 函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。
func hashGrow(t *maptype, h *hmap) {// If we've hit the load factor, get bigger.// Otherwise, there are too many overflow buckets,// so keep the same number of buckets and "grow" laterally.bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}//记录之前的 bucketsoldbuckets := h.buckets// 申请新的buckets空间newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}// commit the grow (atomic wrt gc)h.B += biggerh.flags = flagsh.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0// 如果发现hmap是通过extra字段 来存储 overflow buckets时if h.extra != nil && h.extra.overflow != nil {// Promote current overflow buckets to the old generation.if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}// the actual copying of the hash table data is done incrementally// by growWork() and evacuate().
}真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在 mapassign 和 mapdelete 函数中。也就是插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil
由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,因此 Go map 的扩容采取了一种称为渐进式的方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。
func growWork(t *maptype, h *hmap, bucket uintptr) {// 为了确认搬迁的 bucket 是我们正在使用的 bucket// 即如果当前key映射到老的bucket1,那么就搬迁该bucket1。evacuate(t, h, bucket&h.oldbucketmask())// 如果还未完成扩容工作,则再搬迁一个bucket。if h.growing() {evacuate(t, h, h.nevacuate)}
}
Context
context用于 goroutines 间传递上下文信息。
- 跨携程传递共享数据
- 截止时间管理
- 取消信号
type Context interface {Deadline() (deadline time.Time, ok bool)Done() <-chan struct{}Err() errorValue(key interface{}) interface{}
}
-
Deadline()返回一个完成工作的截止时间,表示上下文应该被取消的时间。如果 ok==false 表示没有设置截止时间。
-
Done()返回一个 Channel,这个 Channel 会在当前工作完成时被关闭,表示上下文应该被取消。如果无法取消此上下文,则 Done 可能返回 nil。多次调用 Done 方法会返回同一个 Channel。
-
Err()返回 Context 结束的原因,它只会在 Done 方法对应的 Channel 关闭时返回非空值。如果 Context 被取消,会返回context.Canceled 错误;如果 Context 超时,会返回context.DeadlineExceeded错误。
-
Value()从 Context 中获取键对应的值。如果未设置 key 对应的值则返回 nil。以相同 key 多次调用会返回相同的结果。
创建顶层context、传递、派生子context、取消context
- emptyCtx
context.Background()
context.TODO()
- WithCancel
parent := context.Background()
ctx, cancel := context.WithCancel(parent)
cancel()
- WithTimeout
//1s后取消
ctx, cancel := context.WithTimeout(parent, time.Second)
defer cancel()
- WithDeadline
//一个期限
ctx, cancel := context.WithDeadline(parent, time.Now().Add(time.Second))
defer cancel()
- valueCtX
ctx := context.WithValue(parent, "key", "value")
ctx.Value("key")
泛型
Channel
概念
Go中的channel 是一个队列,遵循先进先出的原则,负责协程之间的通信(Go 语言提倡不要通过共享内存来通信,而要通过通信来实现内存共享,CSP(Communicating Sequential Process)并发模型,就是通过 goroutine 和 channel 来实现的)
使用场景
-
停止信号监听
-
定时任务
-
生产方和消费方解耦
-
控制并发数
数据结构
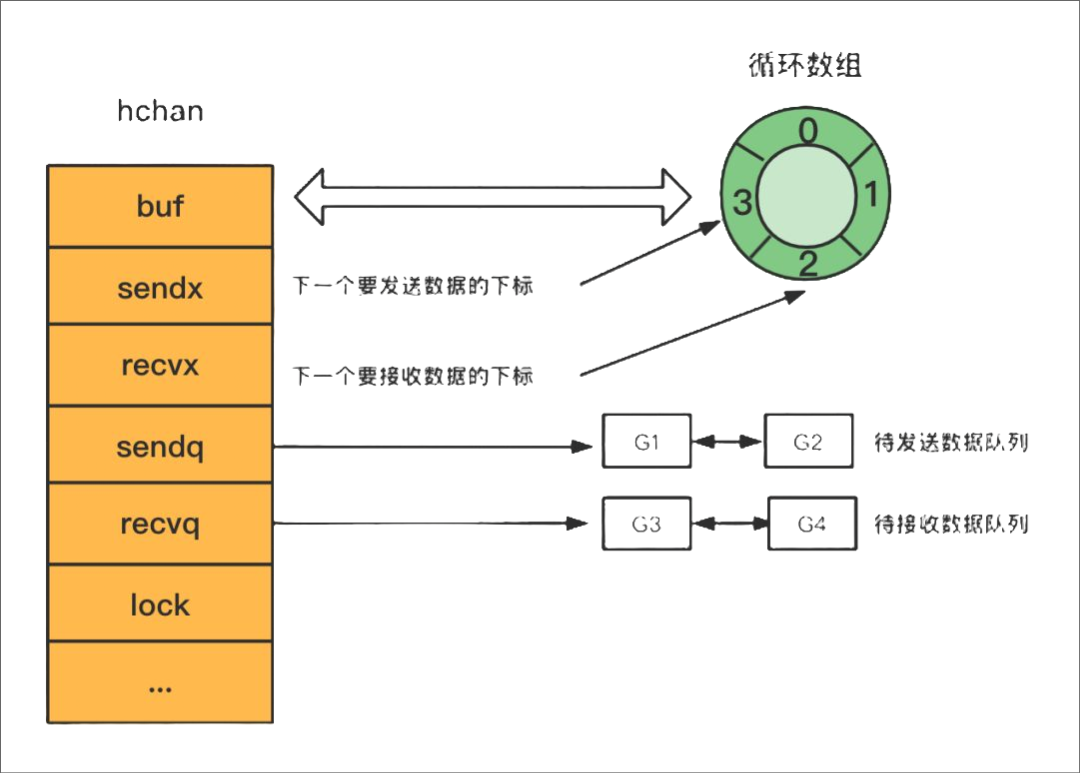
hchan
type hchan struct {closed uint32 // channel是否关闭的标志elemtype *_type // channel中的元素类型// channel分为无缓冲和有缓冲两种。// 对于有缓冲的channel存储数据,使用了 ring buffer(环形缓冲区) 来缓存写入的数据,本质是循环数组// 为啥是循环数组?普通数组不行吗,普通数组容量固定更适合指定的空间,弹出元素时,普通数组需要全部都前移// 当下标超过数组容量后会回到第一个位置,所以需要有两个字段记录当前读和写的下标位置buf unsafe.Pointer // 指向底层循环数组的指针(环形缓冲区)qcount uint // 循环数组中的元素数量dataqsiz uint // 循环数组的长度elemsize uint16 // 元素的大小sendx uint // 下一次写下标的位置recvx uint // 下一次读下标的位置// 尝试读取channel或向channel写入数据而被阻塞的goroutinerecvq waitq // 读等待队列sendq waitq // 写等待队列lock mutex //互斥锁,保证读写channel时不存在并发竞争问题
}
等待队列
双向链表,包含一个头结点和一个尾结点
type waitq struct {first *sudoglast *sudog
}
基本操作
创建
使用 make(chan T, cap) 来创建 channel,make 语法会在编译时,转换为 makechan64 和 makechan
创建channel 有两种,一种是带缓冲的channel,一种是不带缓冲的channel
// 带缓冲
ch := make(chan int, 3)
// 不带缓冲
ch := make(chan int)
| 写操作模式 | 读操作模式 | 读写操作模式 |
|---|---|---|
| 创建 make(chan<- int) | make(<-chan int) | make(chan int) |
有缓冲和无缓冲的区别
无缓冲:一个送信人去你家送信,你不在家他不走,你一定要接下信,他才会走。
有缓冲:一个送信人去你家送信,扔到你家的信箱转身就走,除非你的信箱满了,他必须等信箱有多余空间才会走。
| 无缓冲 | 有缓冲 | |
|---|---|---|
| 创建方式 | make(chan TYPE) | make(chan TYPE, SIZE) |
| 发送阻塞 | 数据接收前发送阻塞 | 缓冲满时发送阻塞 |
| 接收阻塞 | 数据发送前接收阻塞 | 缓冲空时接收阻塞 |
先消费后生产原则
package mainimport ("fmt""time"
)func loop(ch chan int) {for {select {case i := <-ch:fmt.Println("this value of unbuffer channel", i)}}
}func main() {ch := make(chan int)ch <- 1go loop(ch)time.Sleep(1 * time.Millisecond)
}fatal error: all goroutines are asleep - deadlock!
channel如何控制 goroutine 并发执行顺序
package mainimport ("fmt""sync""time"
)var wg sync.WaitGroupfunc main() {ch1 := make(chan struct{}, 1)ch2 := make(chan struct{}, 1)ch3 := make(chan struct{}, 1)ch1 <- struct{}{}wg.Add(3)start := time.Now().Unix()go print("gorouine1", ch1, ch2)go print("gorouine2", ch2, ch3)go print("gorouine3", ch3, ch1)wg.Wait()end := time.Now().Unix()fmt.Printf("duration:%d", end-start)
}func print(gorouine string, inputchan chan struct{}, outchan chan struct{}) {// 模拟内部操作耗时time.Sleep(1 * time.Second)select {case <-inputchan:fmt.Printf("%s", gorouine)outchan <- struct{}{}}wg.Done()
}
Go channel共享内存优劣势
不要通过共享内存来通信,我们应该使用通信来共享内存

无论是通过共享内存来通信还是通过通信来共享内存,最终我们应用程序都是读取的内存当中的数据,只是前者是直接读取内存的数据,而后者是通过发送消息的方式来进行同步。而通过发送消息来同步的这种方式常见的就是 Go 采用的 CSP(Communication Sequential Process) 模型以及 Erlang 采用的 Actor 模型,这两种方式都是通过通信来共享内存。
优点:使用 channel 可以帮助我们解耦生产者和消费者,可以降低并发当中的耦合
缺点:容易出现死锁的情况
Channel 死锁场景
- 非缓存channel只写不读
- 非缓存channel读在写后面
- 缓存channel写入超过缓冲区数量
- 空读
- 多个协程互相等待
锁的实现
数据结构
type Mutex struct { state int32 sema uint32
}
state表示锁的状态,有锁定、被唤醒、饥饿模式等,并且是用state的二进制位来标识的,不同模式下会有不同的处理方式
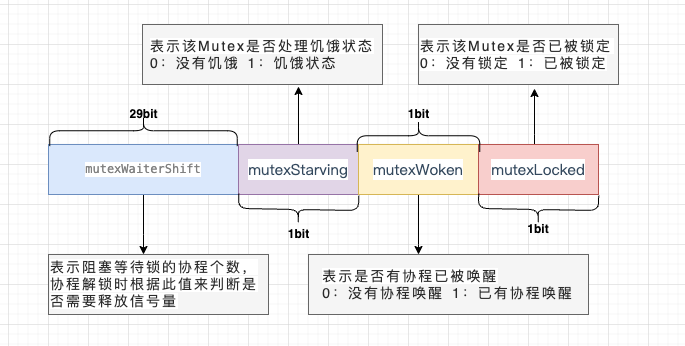
sema表示信号量,mutex阻塞队列的定位是通过这个变量来实现的,从而实现goroutine的阻塞和唤醒
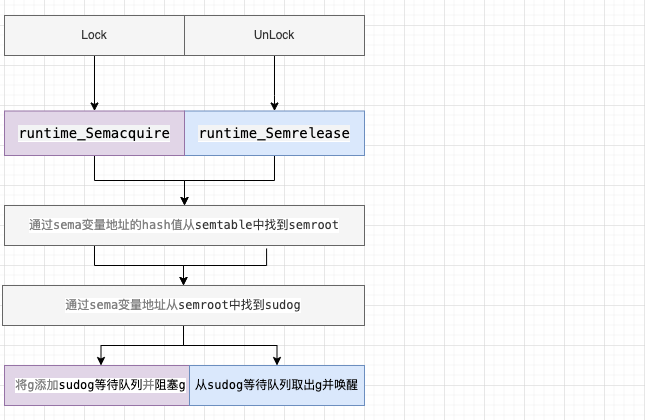
操作
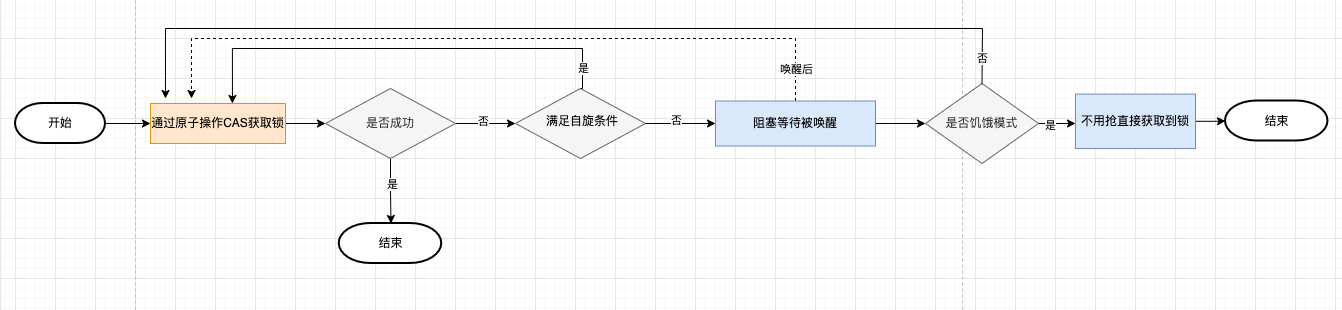
加锁
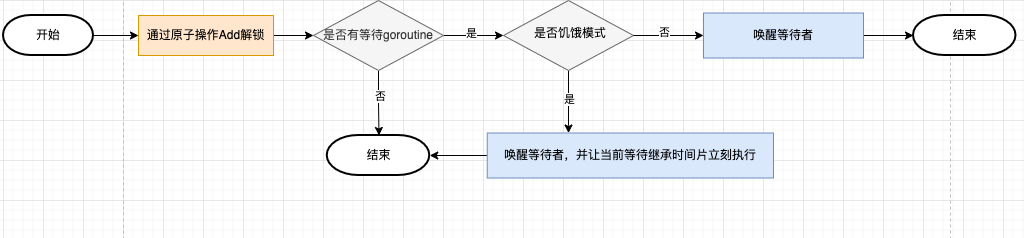
解锁
正常模式和饥饿模式
- 正常模式(非公平锁)
在刚开始的时候,是处于正常模式(Barging),也就是,当一个G1持有着一个锁的时候,G2会自旋的去尝试获取这个锁
当自旋超过4次还没有能获取到锁的时候,这个G2就会被加入到获取锁的等待队列里面,并阻塞等待唤醒
正常模式下,所有等待锁的 goroutine 按照 FIFO(先进先出)顺序等待。唤醒的goroutine 不会直接拥有锁,而是会和新请求锁的 goroutine 竞争锁。新请求锁的 goroutine 具有优势:它正在 CPU 上执行,而且可能有好几个,所以刚刚唤醒的 goroutine 有很大可能在锁竞争中失败,长时间获取不到锁,就会切换到饥饿模式 - 饥饿模式(公平锁)
当一个 goroutine 等待锁时间超过 1 毫秒时,它可能会遇到饥饿问题。
饥饿模式下,直接把锁交给等待队列中排在第一位的goroutine(队头),同时饥饿模式下,新进来的goroutine不会参与抢锁也不会进入自旋状态,会直接进入等待队列的尾部,这样很好的解决了老的goroutine一直抢不到锁的场景。
对于两种模式,正常模式下的性能是最好的,goroutine 可以连续多次获取锁,饥饿模式解决了取锁公平的问题,但是性能会下降
读写锁
数据结构
type RWMutex struct {w Mutex // 控制 writer 在 队列B 排队writerSem uint32 // 写信号量,用于等待前面的 reader 完成读操作readerSem uint32 // 读信号量,用于等待前面的 writer 完成写操作readerCount int32 // reader 的总数量,同时也指示是否有 writer 在队列A 中等待readerWait int32 // 队列A 中 writer 前面 reader 的数量
}// 允许最大的 reader 数量
const rwmutexMaxReaders = 1 << 30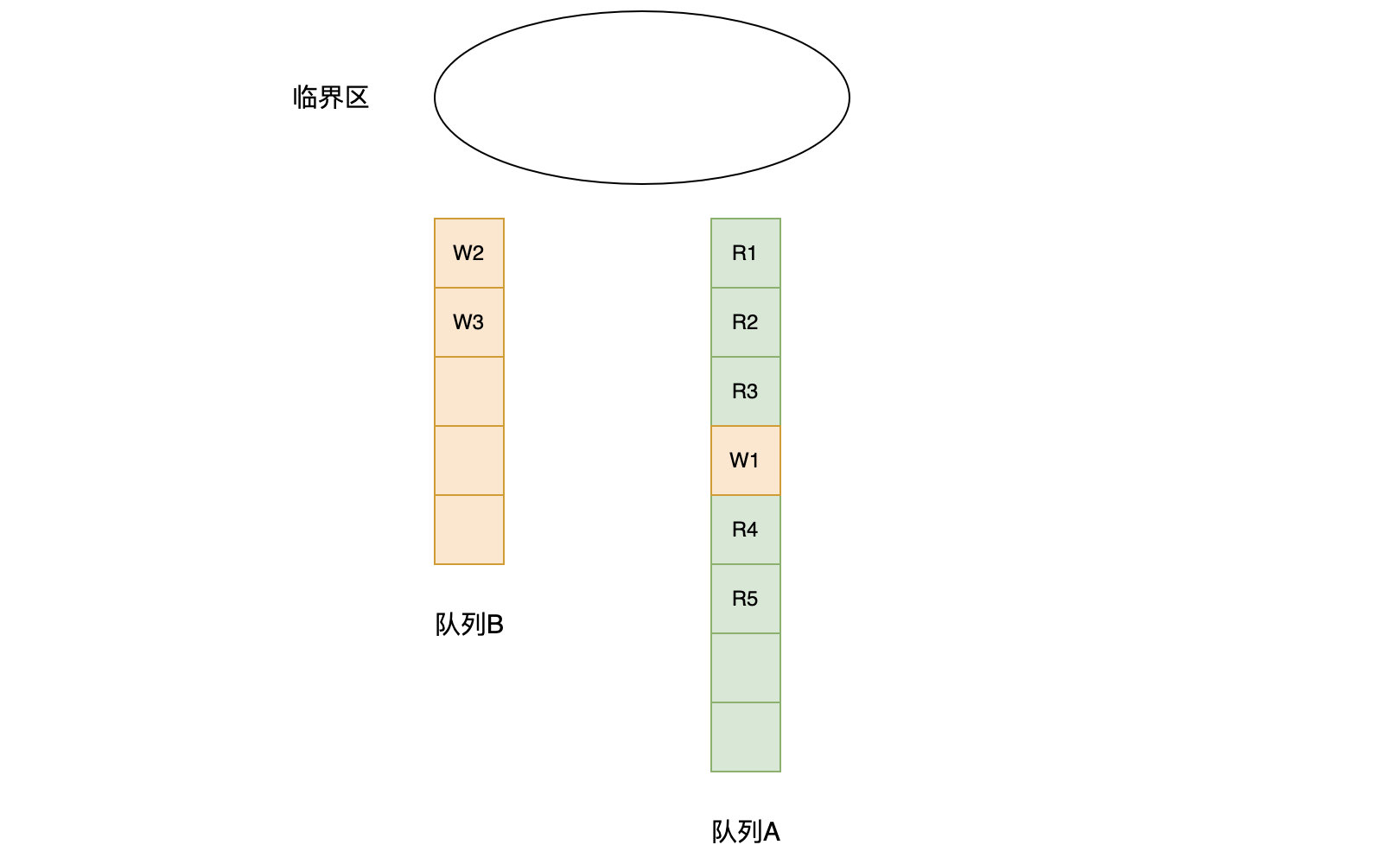
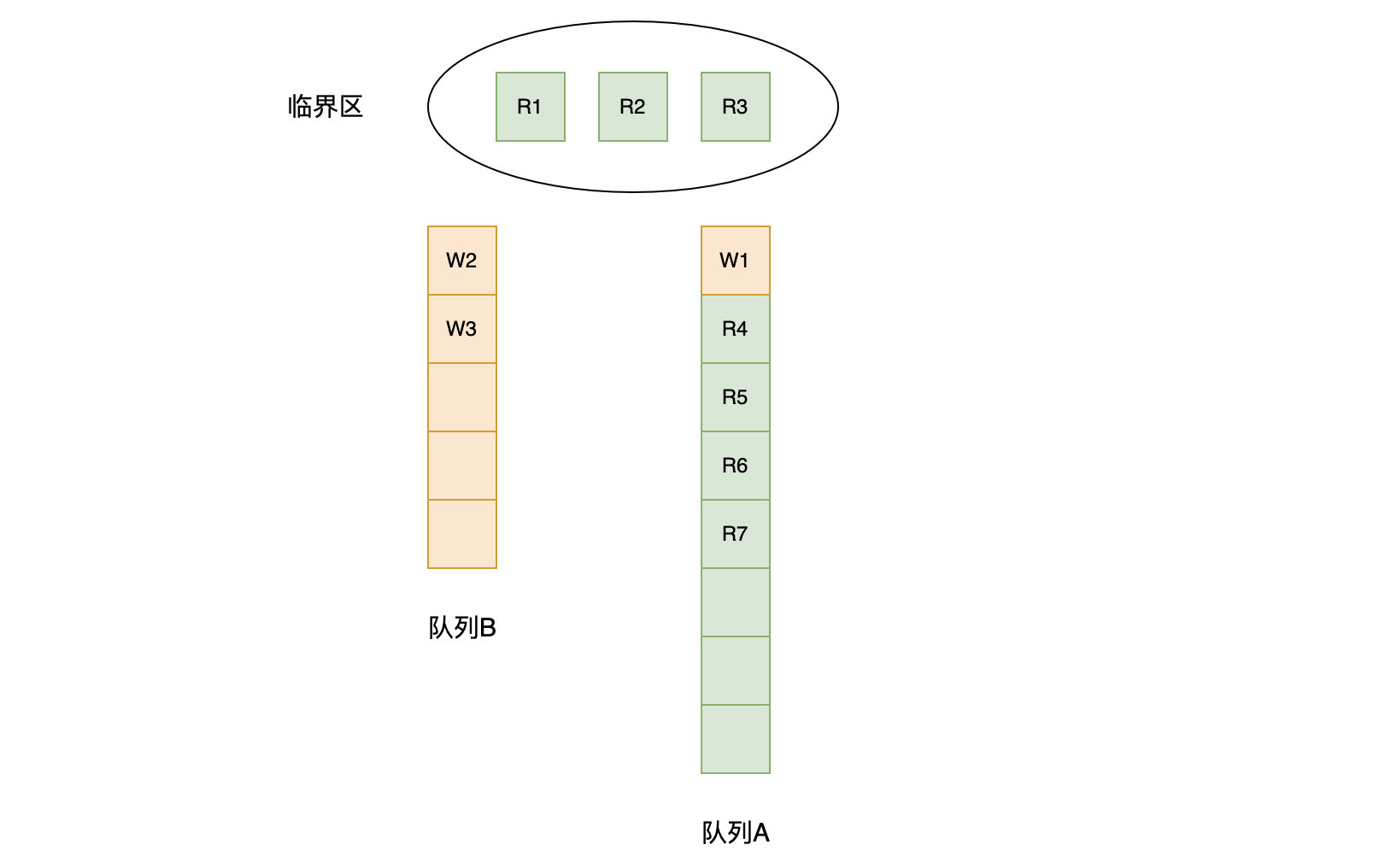
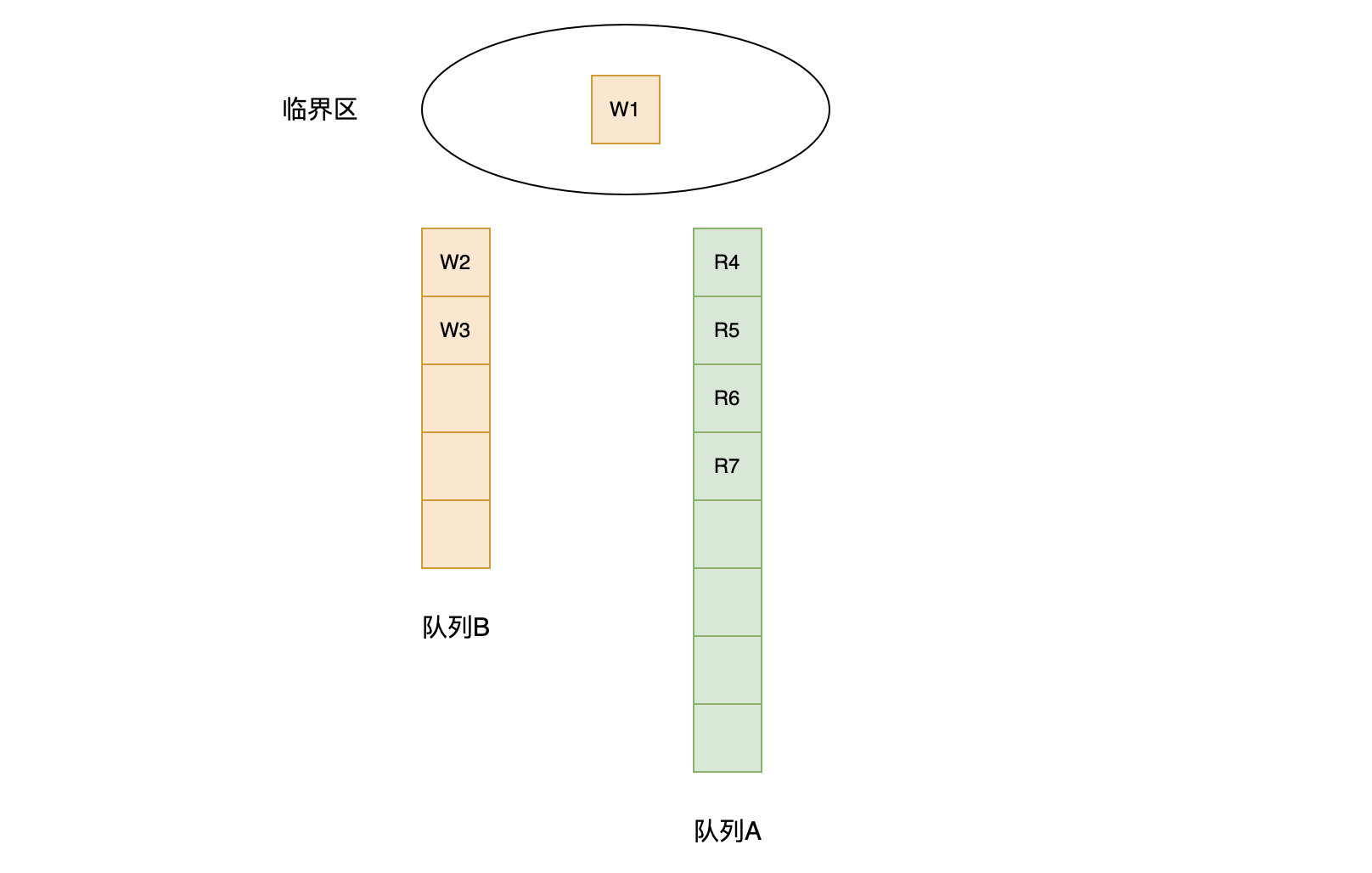
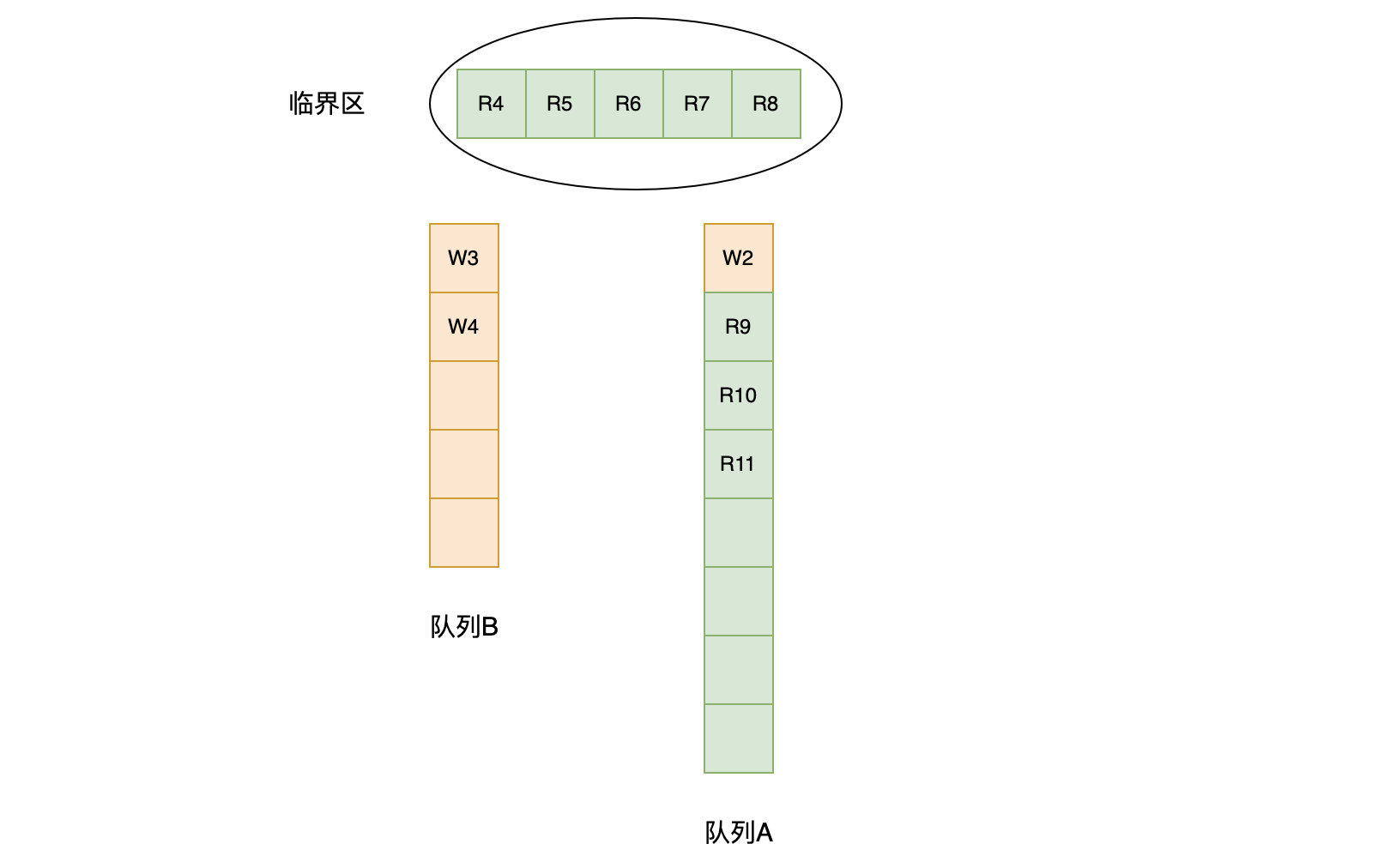
操作
读锁的加锁与释放
func (rw *RWMutex) RLock() // 加读锁
func (rw *RWMutex) RUnlock() // 释放读锁
- 加读锁
func (rw *RWMutex) RLock() {// reader 加锁,将 readerCount 加一,表示多了个 readerif atomic.AddInt32(&rw.readerCount, 1) < 0 {// 如果 readerCount<0,说明有 writer 在自己前面等待,排队等待读信号量runtime_SemacquireMutex(&rw.readerSem, false, 0)}
}atomic.AddInt32(&rw.readerCount, 1) 调用这个原子方法,对当前在读的数量加1,如果返回负数,那么说明当前有其他写锁,这时候就调用 runtime_SemacquireMutex 休眠当前goroutine, 等待被唤醒
- 释放读锁
func (rw *RWMutex) RUnlock() {// reader 释放锁,将 readerCount 减一,表示少了个 readerif r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {// 如果readerCount<0,说明有 writer 在自己后面等待,看是否要让 writer 运行rw.rUnlockSlow(r)}
}func (rw *RWMutex) rUnlockSlow(r int32) {// 将 readerWait 减一,表示前面的 reader 少了一个if atomic.AddInt32(&rw.readerWait, -1) == 0 {// 如果 readerWait 变为了0,那么自己就是最后一个完成的 reader// 释放写信号量,让 writer 运行runtime_Semrelease(&rw.writerSem, false, 1)}
}被阻塞的准备读的 goroutine 的数量减1,readerWait 为 0,就表示当前没有正在准备读的 goroutine 这时候调用 runtime_Semrelease 唤醒写操作
func (rw *RWMutex) rUnlockSlow(r int32) {// A writer is pending.if atomic.AddInt32(&rw.readerWait, -1) == 0 {// The last reader unblocks the writer.runtime_Semrelease(&rw.writerSem, false, 1)}
}
写锁的加锁与释放
func (rw *RWMutex) Lock() // 加写锁
func (rw *RWMutex) Unlock() // 释放写锁
- 加写锁
func (rw *RWMutex) Lock() {// 利用互斥锁,如果前面有 writer,那么就需要等待互斥锁,即在队列B 中排队等待;如果没有,可以直接进入 队列A 排队rw.w.Lock()// atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) 将 readerCount 变成了负数// 再加 rwmutexMaxReaders,相当于 r = readerCount,r 就是 writer 前面的 reader 数量r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders// 如果 r!= 0 ,表示自己前面有 reader,那么令 readerWait = r,要等前面的 reader 运行完if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {runtime_SemacquireMutex(&rw.writerSem, false, 0)}}首先调用互斥锁的 lock,获取到互斥锁之后,如果计算之后当前仍然有其他 goroutine 持有读锁,那么就调用 runtime_SemacquireMutex 休眠当前的 goroutine 等待所有的读操作完成
这里readerCount 原子性加上一个很大的负数,是防止后面的协程能拿到读锁,阻塞读
- 释放写锁
func (rw *RWMutex) Unlock() {// Announce to readers there is no active writer.r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)// Unblock blocked readers, if any.for i := 0; i < int(r); i++ {runtime_Semrelease(&rw.readerSem, false)}// Allow other writers to proceed.rw.w.Unlock()
}
解锁的操作,会先调用 atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders) 将恢复之前写入的负数,然后根据当前有多少个读操作在等待,循环唤醒
Go goroutine的底层实现原理
数据结构
type g struct {goid int64 // 唯一的goroutine的IDsched gobuf // goroutine切换时,用于保存g的上下文stack stack // 栈gopc // pc of go statement that created this goroutinestartpc uintptr // pc of goroutine function...
}type gobuf struct {sp uintptr // 栈指针位置pc uintptr // 运行到的程序位置g guintptr // 指向 goroutineret uintptr // 保存系统调用的返回值...
}type stack struct {lo uintptr // 栈的下界内存地址hi uintptr // 栈的上界内存地址
}
状态流转
| 状态 | 含义 |
|---|---|
| 空闲中_Gidle | G刚刚新建, 仍未初始化 |
| 待运行_Grunnable | 就绪状态,G在运行队列中, 等待M取出并运行 |
| 运行中_Grunning | M正在运行这个G, 这时候M会拥有一个P |
| 系统调用中_Gsyscall | M正在运行这个G发起的系统调用, 这时候M并不拥有P |
| 等待中_Gwaiting | G在等待某些条件完成, 这时候G不在运行也不在运行队列中(可能在channel的等待队列中) |
| 已中止_Gdead | G未被使用, 可能已执行完毕 |
| 栈复制中_Gcopystack | G正在获取一个新的栈空间并把原来的内容复制过去(用于防止GC扫描) |
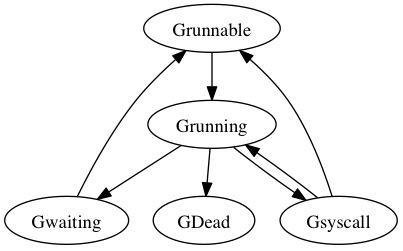
创建
通过go关键字调用底层函数runtime.newproc()创建一个goroutine
当调用该函数之后,goroutine会被设置成runnable状态
创建好的这个goroutine会新建一个自己的栈空间,同时在G的sched中维护栈地址与程序计数器这些信息。
每个 G 在被创建之后,都会被优先放入到本地队列中,如果本地队列已经满了,就会被放入到全局队列中。
调度时机
- 新起一个协程和协程执行完毕
- 会阻塞的系统调用,比如文件io、网络io
- channel、mutex等阻塞操作
- time.sleep
- 垃圾回收之后
- 主动调用runtime.Gosched()
- 运行过久或系统调用过久等等
阻塞
channel的读写操作、等待锁、等待网络数据、系统调用等都有可能发生阻塞,会调用底层函数runtime.gopark(),会让出CPU时间片,让调度器安排其它等待的任务运行,并在下次某个时候从该位置恢复执行。
唤醒
处于waiting状态的goroutine,在调用runtime.goready()函数之后会被唤醒,唤醒的goroutine会被重新放到M对应的上下文P对应的runqueue中,等待被调度。
当调用该函数之后,goroutine会被设置成runnable状态
退出
当goroutine执行完成后,会调用底层函数runtime.Goexit()
当调用该函数之后,goroutine会被设置成dead状态
线程与协程的区别
| goroutine | 线程 | |
|---|---|---|
| 内存占用 | 创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容 | 创建一个线程 的栈内存消耗为 1 MB |
| 创建和销毀 | goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。 | 线程 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池 |
| 切换 | goroutines 切换只需保存三个寄存器:PC、SP、BP goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。 | 当线程切换时,需要保存各种寄存器,以便恢复现场。线程切换会消耗 1000-1500 ns,相当于 12000-18000 条指令。 |
进程
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
线程
线程有时被称为轻量级进程( Lightweight Process, LWP),是操作系统执行的最小单位。一个标准的线程由线程ID、当前指令指针(PC)、寄存器集合和堆栈组成。
协程
协程是一种比线程更加轻量级的一种函数。一个线程可以拥有多个协程。协程是非抢占式的,由协程主动交出控制权,go function把函数交给调度器运行,调度器会在合适的时机进行切换,协程不是被操作系统内核所管理的,而是完全由程序所控制的,即在用户态执行。 这样带来的好处是:性能有大幅度的提升,因为不会像线程切换那样消耗资源。
Goroutine可以理解为一种Go语言的协程(轻量级线程),是Go支持高并发的基础,属于用户态的线程,由Go runtime管理而不是操作系统。
对比
- 协程既不是进程也不是线程,协程仅是一个特殊的函数。协程、进程和线程不是一个维度的。
- 一个进程可以包含多个线程,一个线程可以包含多个协程。虽然一个线程内的多个协程可以切换但是这多个协程是串行执行的,某个时刻只能有一个线程在运行,没法利用CPU的多核能力。
- 协程与进程一样,也存在上下文切换问题。
- 进程的切换者是操作系统,切换时机是根据操作系统自己的切换策略来决定的,用户是无感的。进程的切换内容包括页全局目录、内核栈和硬件上下文,切换内容被保存在内存中。进程切换过程采用的是“从用户态到内核态再到用户态”的方式,切换效率低。
- 线程的切换者是操作系统,切换时机是根据操作系统自己的切换策略来决定的,用户是无感的。线程的切换内容包括内核栈和硬件上下文。线程切换内容被保存在内核栈中。线程切换过程采用的是“从用户态到内核态再到用户态”的方式,切换效率中等。
- 协程的切换者是用户(编程者或应用程序),切换时机是用户自己的程序来决定的。协程的切换内容是硬件上下文,切换内存被保存在用自己的变量(用户栈或堆)中。协程的切换过程只有用户态(即没有陷入内核态),因此切换效率高。
Go goroutine泄露的场景
泄露原因
- Goroutine 内进行channel/mutex 等读写操作被一直阻塞。
- Goroutine 内的业务逻辑进入死循环,资源一直无法释放。
- Goroutine 内的业务逻辑进入长时间等待,有不断新增的 Goroutine 进入等待
泄露场景
- channel 忘记初始化,那么无论你是读,还是写操作,都会造成阻塞。
- channel 发送前不先接收
- 接收不发送
- http request body未关闭
- 互斥锁忘记解锁
- sync.WaitGroup使用不当
排查
-
单个函数:调用 runtime.NumGoroutine 方法来打印 执行代码前后Goroutine 的运行数量,进行前后比较,就能知道有没有泄露了。
-
生产/测试环境:使用PProf实时监测Goroutine的数量
package mainimport ( "net/http" _ "net/http/pprof" )func main() {for i := 0; i < 100; i++ {go func() {select {}}()}go func() {http.ListenAndServe("localhost:6060", nil)}()select {} }分析goroutine文件
go tool pprof -http=:1248 http://127.0.0.1:6060/debug/pprof/goroutine
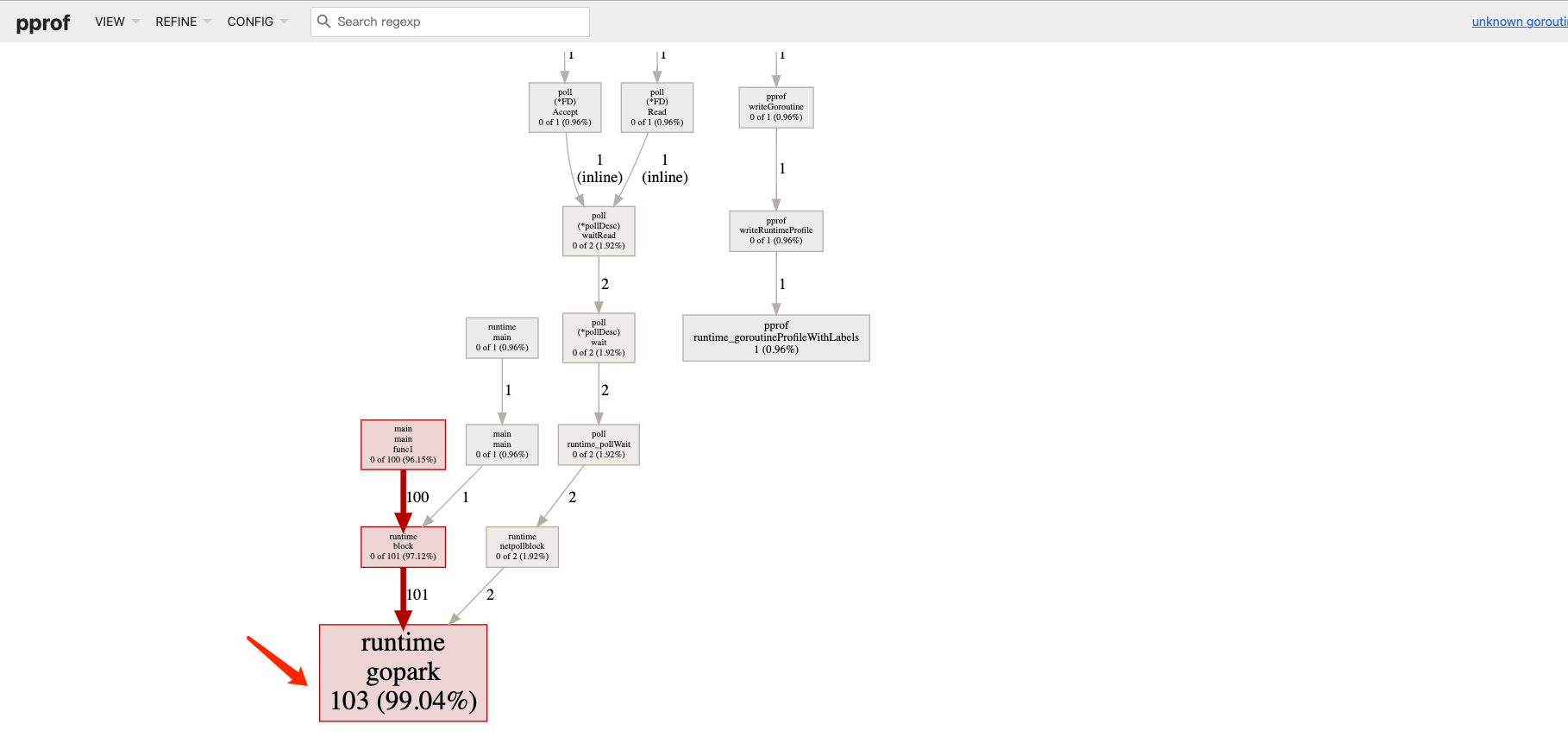
可以清晰的看到goroutine的数量以及调用关系,可以看到有103个goroutine
线程模型
Go实现的是两级线程模型(M:N),准确的说是GMP模型,是对两级线程模型的改进实现,使它能够更加灵活地进行线程之间的调度。
线程实现模型主要分为:内核级线程模型、用户级线程模型、两级线程模型,他们的区别在于用户线程与内核线程之间的对应关系。
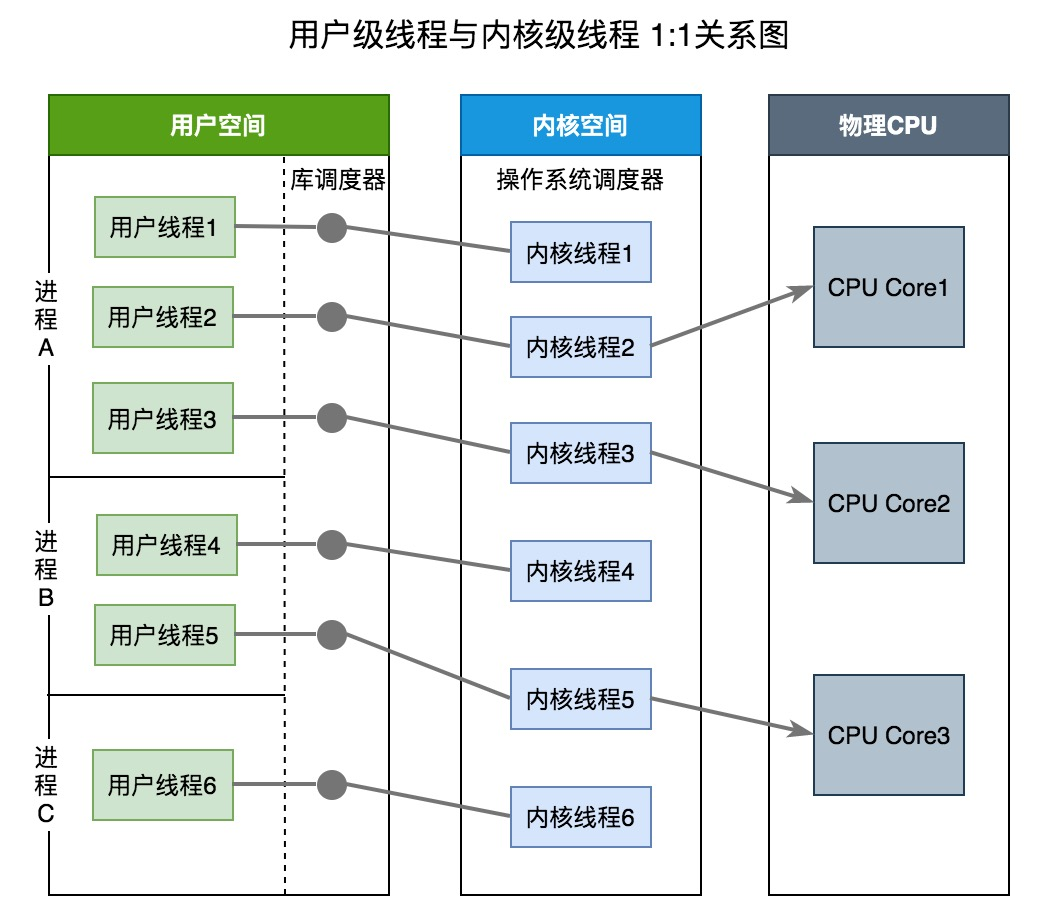
内核级线程模型(1:1)
1个用户线程对应1个内核线程,上下文切换成本高
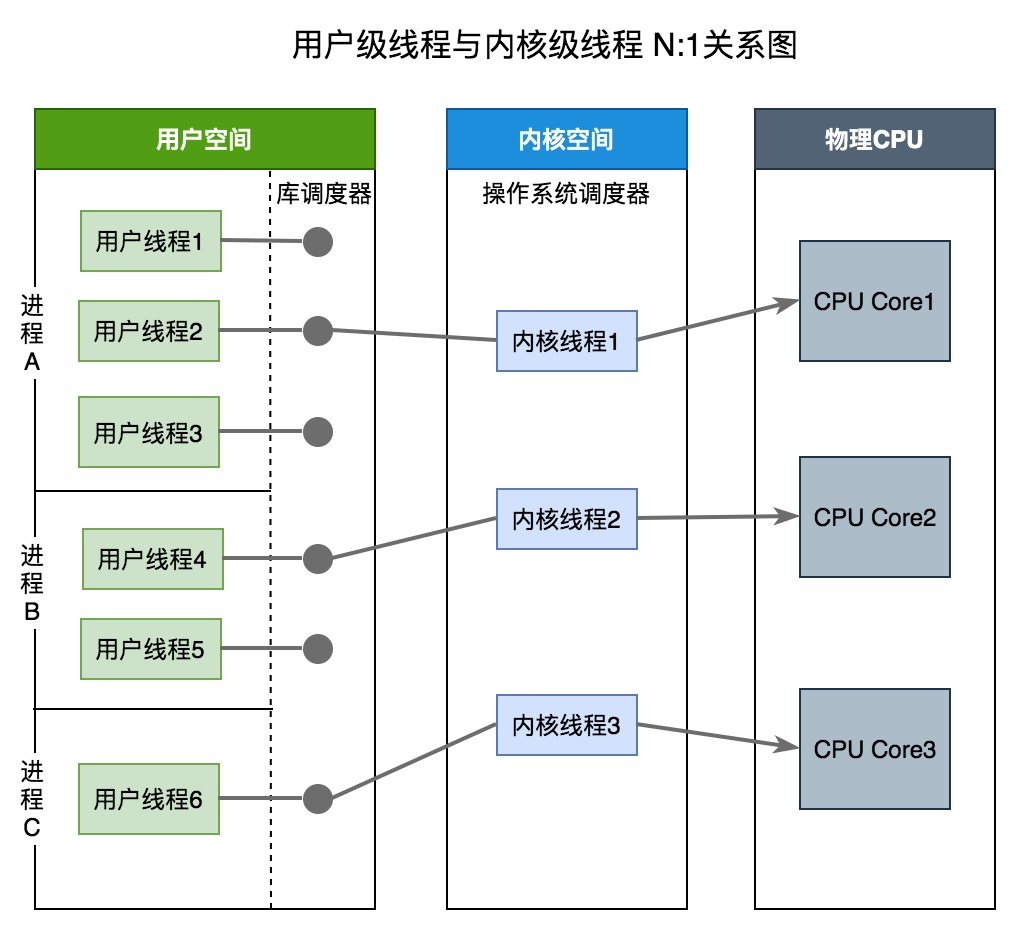
用户级线程模型(N:1)
1个进程中的所有线程对应1个内核线程。
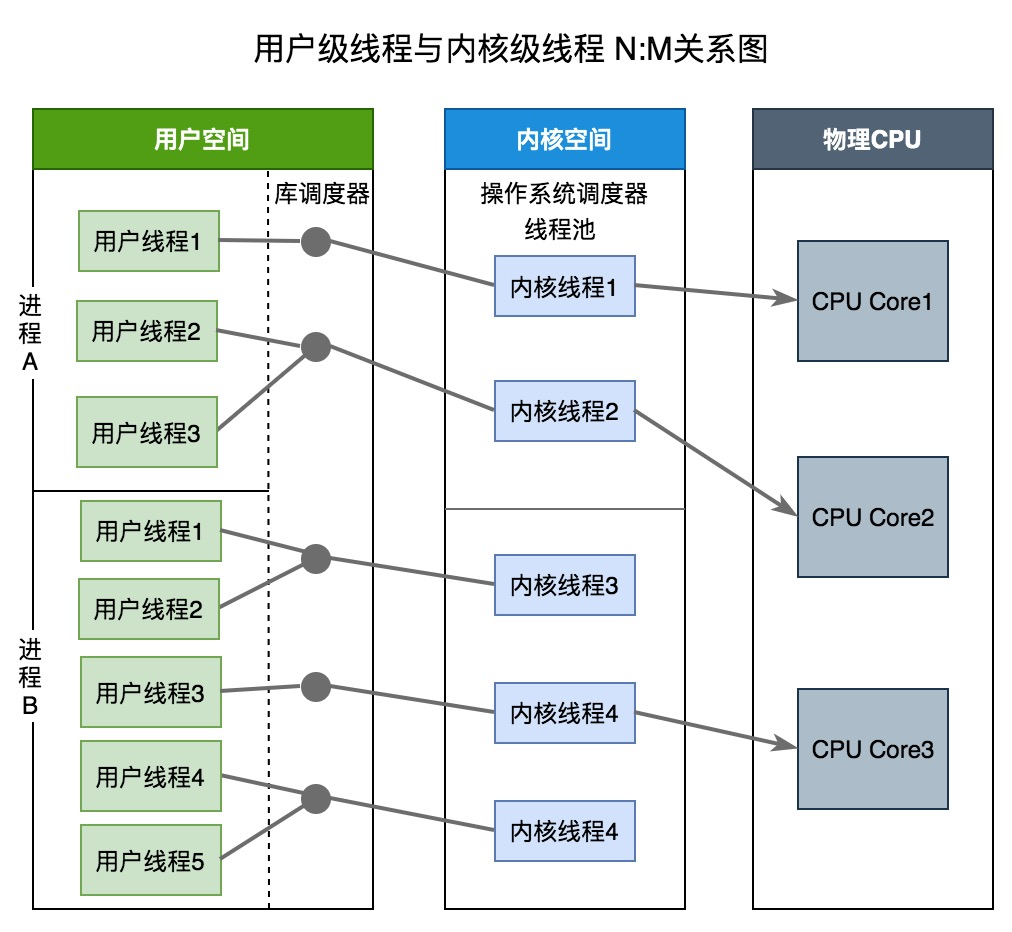
两级线程模型(M:N)
M个线程对应N个内核线程
GMP
Go采用了GMP模型(对两级线程模型的改进实现),使它能够更加灵活地进行线程之间的调度。
GMP是Go运行时调度层面的实现,包含4个重要结构,分别是G、M、P、Sched
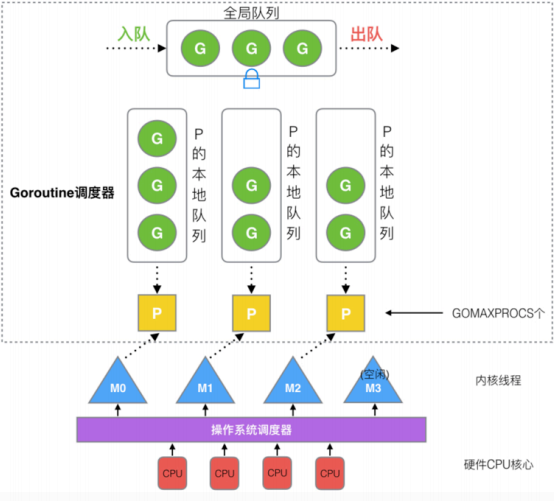
- G(Goroutine):代表Go 协程Goroutine,存储了 Goroutine 的执行栈信息、Goroutine 状态以及 Goroutine 的任务函数等。G的数量无限制,理论上只受内存的影响,创建一个 G 的初始栈大小为2-4K,配置一般的机器也能简简单单开启数十万个 Goroutine ,而且Go语言在 G 退出的时候还会把 G 清理之后放到 P 本地或者全局的闲置列表 gFree 中以便复用。
- M(Machine): Go 对操作系统线程(OS thread)的封装,可以看作操作系统内核线程,想要在 CPU 上执行代码必须有线程,通过系统调用 clone 创建。M在绑定有效的 P 后,进入一个调度循环,而调度循环的机制大致是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。M的数量有限制,默认数量限制是 10000,可以通过 debug.SetMaxThreads() 方法进行设置,如果有M空闲,那么就会回收或者睡眠。
- P(Processor):虚拟处理器,M执行G所需要的资源和上下文,只有将 P 和 M 绑定,才能让 P 的 runq 中的 G 真正运行起来。P 的数量决定了系统内最大可并行的 G 的数量,P的数量受本机的CPU核数影响,可通过环境变量$GOMAXPROCS或在runtime.GOMAXPROCS()来设置,默认为CPU核心数。
核心数据结构
//src/runtime/runtime2.go
type g struct {goid int64 // 唯一的goroutine的IDsched gobuf // goroutine切换时,用于保存g的上下文stack stack // 栈gopc // pc of go statement that created this goroutinestartpc uintptr // pc of goroutine function...
}type p struct {lock mutexid int32status uint32 // one of pidle/prunning/...// Queue of runnable goroutines. Accessed without lock.runqhead uint32 // 本地队列队头runqtail uint32 // 本地队列队尾runq [256]guintptr // 本地队列,大小256的数组,数组往往会被都读入到缓存中,对缓存友好,效率较高runnext guintptr // 下一个优先执行的goroutine(一定是最后生产出来的),为了实现局部性原理,runnext中的G永远会被最先调度执行...
}type m struct {g0 *g // 每个M都有一个自己的G0,不指向任何可执行的函数,在调度或系统调用时,M会切换到G0,使用G0的栈空间来调度curg *g // 当前正在执行的G...
}type schedt struct {...runq gQueue // 全局队列,链表(长度无限制)runqsize int32 // 全局队列长度...
}
GMP模型的实现算是Go调度器的一大进步,但调度器仍然有一个令人头疼的问题,那就是不支持抢占式调度,这导致一旦某个 G 中出现死循环的代码逻辑,那么 G 将永久占用分配给它的 P 和 M,而位于同一个 P 中的其他 G 将得不到调度,出现“饿死”的情况。
当只有一个 P(GOMAXPROCS=1)时,整个 Go 程序中的其他 G 都将“饿死”。于是在 Go 1.2 版本中实现了基于协作的“抢占式”调度,在Go 1.14 版本中实现了基于信号的“抢占式”调度。
调度原理
概念
goroutine调度的本质就是将 Goroutine按照一定算法放到CPU上去执行。
CPU感知不到Goroutine,只知道内核线程,所以需要Go调度器将协程调度到内核线程上面去,然后操作系统调度器将内核线程放到CPU上去执行
M是对内核级线程的封装,所以Go调度器的工作就是将G分配到M
设计思想
-
线程复用(work stealing 机制和hand off 机制)
-
利用并行(利用多核CPU)
-
抢占调度(解决公平性问题)
调度对象
Go 调度器是属于Go runtime中的一部分,Go runtime负责实现Go的并发调度、垃圾回收、内存堆栈管理等关键功能
被调度对象
G的来源
- P的runnext(只有1个G,局部性原理,永远会被最先调度执行)
- P的本地队列(数组,最多256个G)
- 全局G队列(链表,无限制)
- 网络轮询器network poller(存放网络调用被阻塞的G)
P的来源
- 全局P队列(数组,GOMAXPROCS个P)
M的来源
- 休眠线程队列(未绑定P,长时间休眠会等待GC回收销毁)
- 运行线程(绑定P,指向P中的G)
- 自旋线程(绑定P,指向M的G0)
其中运行线程数 + 自旋线程数 <= P的数量(GOMAXPROCS),M个数 >= P个数
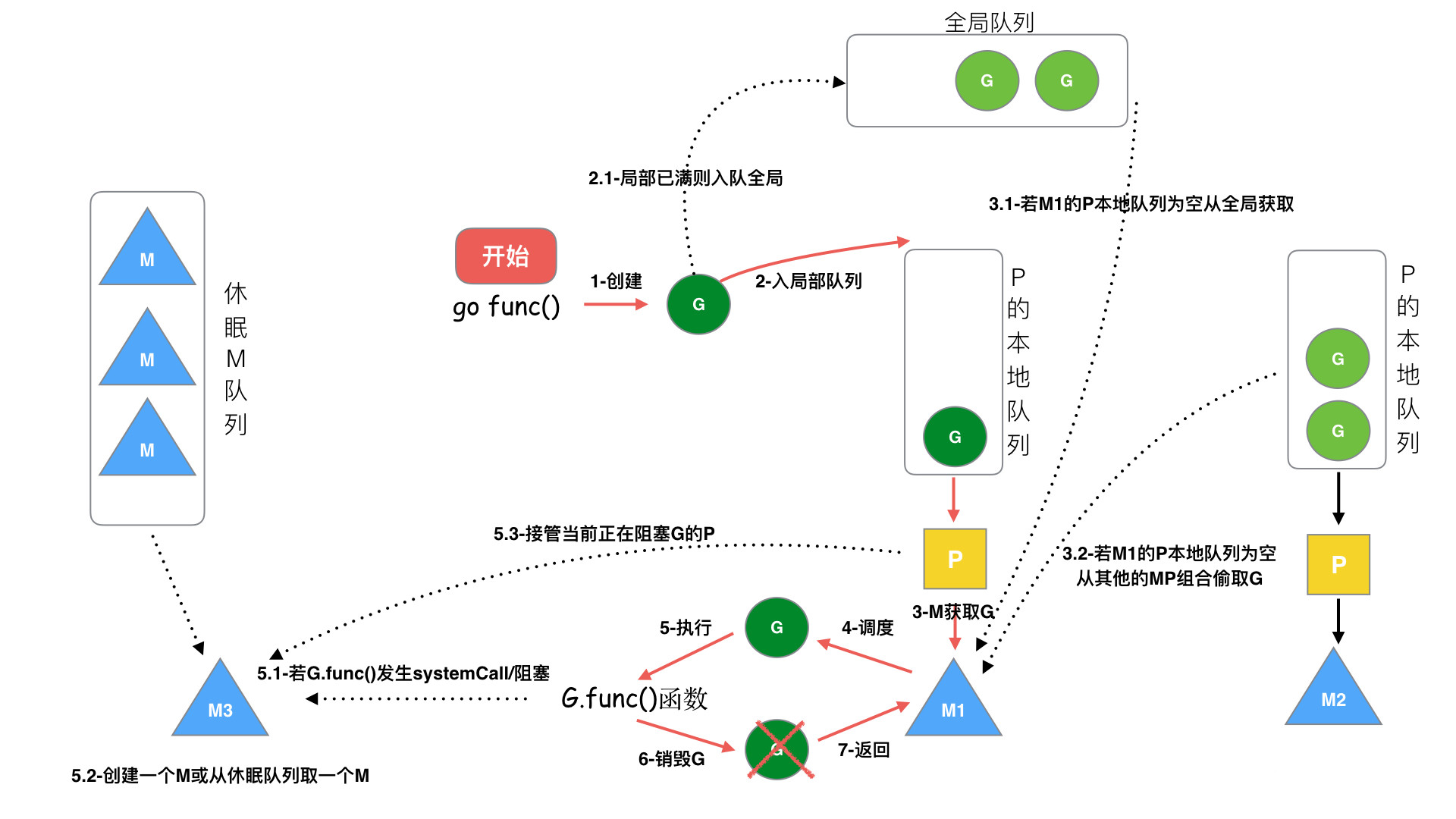
-
步骤 1:创建 G,关键字 go func() 创建 G
-
步骤 2:保存 G,创建的 G 优先保存到本地队列 P,如果 P 满了,则会平衡部分P到全局队列中
- 执行 go func 的时候,主线程 M0 会调用 newproc()生成一个 G 结构体,这里会先选定当前 M0 上的 P 结构
- 每个协程 G 都会被尝试先放到 P 中的 runnext,若 runnext 为空则放到 runnext 中,生产结束
- 若 runnext 满,则将原来 runnext 中的 G 踢到本地队列中,将当前 G 放到 runnext 中,生产结束
- 若本地队列也满了,则将本地队列中的 G 拿出一半,放到全局队列中,生产结束。
-
步骤3:唤醒或者新建M执行任务,进入调度循环(步骤4,5,6)
-
步骤 4:M 获取 G,M首先从P的本地队列获取 G,如果 P为空,则从全局队列获取 G,如果全局队列也为空,则从另一个本地队列偷取一半数量的 G(负载均衡),这种从其它P偷的方式称之为 work stealing
-
步骤 5:M 调度和执行 G,M调用 G.func() 函数执行 G
- 如果 M在执行 G 的过程发生系统调用阻塞(同步),会阻塞G和M(操作系统限制),此时P会和当前M解绑,并寻找新的M,如果没有空闲的M就会新建一个M ,接管正在阻塞G所属的P,接着继续执行 P中其余的G,这种阻塞后释放P的方式称之为hand off。当系统调用结束后,这个G会尝试获取一个空闲的P执行,优先获取之前绑定的P,并放入到这个P的本地队列,如果获取不到P,那么这个线程M变成休眠状态,加入到空闲线程中,然后这个G会被放入到全局队列中。
- 如果M在执行G的过程发生网络IO等操作阻塞时(异步),阻塞G,不会阻塞M。M会寻找P中其它可执行的G继续执行,G会被网络轮询器network poller 接手,当阻塞的G恢复后,G1从network poller 被移回到P的 LRQ 中,重新进入可执行状态。异步情况下,通过调度,Go scheduler 成功地将 I/O 的任务转变成了 CPU 任务,或者说将内核级别的线程切换转变成了用户级别的 goroutine 切换,大大提高了效率。
-
步骤6:M执行完G后清理现场,重新进入调度循环(将M上运⾏的goroutine切换为G0,G0负责调度时协程的切换)
调度时机
在以下情形下,会切换正在执行的goroutine
- 抢占式调度
- sysmon 检测到协程运行过久(比如sleep,死循环)
- 切换到g0,进入调度循环
- 主动调度
- 新起一个协程和协程执行完毕
- 触发调度循环
- 主动调用runtime.Gosched()
- 切换到g0,进入调度循环
- 垃圾回收之后
- stw之后,会重新选择g开始执行
- 被动调度
- 系统调用(比如文件IO)阻塞(同步)
- 阻塞G和M,P与M分离,将P交给其它M绑定,其它M执行P的剩余G
- 网络IO调用阻塞(异步)
- 阻塞G,G移动到NetPoller,M执行P的剩余G
- atomic/mutex/channel等阻塞(异步)
- 阻塞G,G移动到channel的等待队列中,M执行P的剩余G
调度策略
使用什么策略来挑选下一个goroutine执行?
由于 P 中的 G 分布在 runnext、本地队列、全局队列、网络轮询器中,则需要挨个判断是否有可执行的 G,大体逻辑如下:
- 每执行61次调度循环,从全局队列获取G,若有则直接返回
- 从P 上的 runnext 看一下是否有 G,若有则直接返回
- 从P 上的 本地队列 看一下是否有 G,若有则直接返回
- 上面都没查找到时,则去全局队列、网络轮询器查找或者从其他 P 中窃取,一直阻塞直到获取到一个可用的 G 为止
从全局队列查找时,如果要所有 P 平分全局队列中的 G,每个 P 要分得多少个,这里假设会分得 n 个。然后把这 n 个 G,转移到当前 G 所在 P 的本地队列中去。但是最多不能超过 P 本地队列长度的一半(即 128)。这样做的目的是,如果下次调度循环到来的时候,就不必去加锁到全局队列中再获取一次 G 了,性能得到了很好的保障。
从其它P查找时,会偷一半的G过来放到当前P的本地队列
Go work stealing 机制
概念
当线程M⽆可运⾏的G时,尝试从其他M绑定的P偷取G,减少空转,提高了线程利用率(避免闲着不干活)。
当从本线程绑定 P 本地 队列、全局G队列、netpoller都找不到可执行的 g,会从别的 P 里窃取G并放到当前P上面。
从netpoller 中拿到的G是_Gwaiting状态( 存放的是因为网络IO被阻塞的G),从其它地方拿到的G是_Grunnable状态
从全局队列取的G数量:N = min(len(GRQ)/GOMAXPROCS + 1, len(GRQ/2)) (根据GOMAXPROCS负载均衡)
从其它P本地队列窃取的G数量:N = len(LRQ)/2(平分)
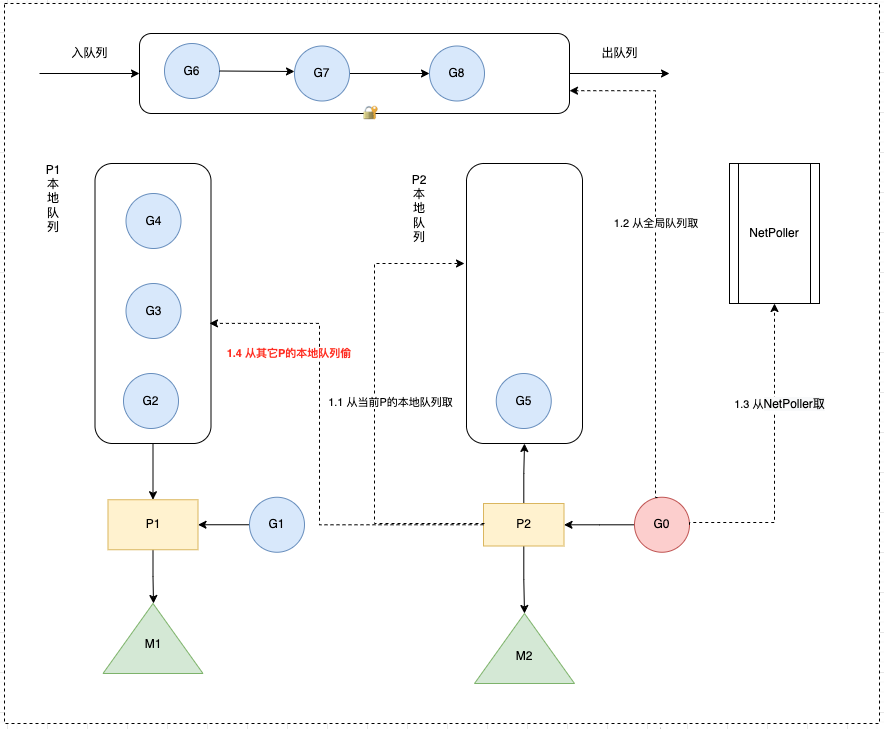
窃取流程
- 随机从P中窃取
- 从P中偷走一半G
Go hand off 机制
概念
也称为P分离机制,当本线程 M 因为 G 进行的系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的 M 执行,也提高了线程利用率。
当前线程M阻塞时,释放P,给其它空闲的M处理
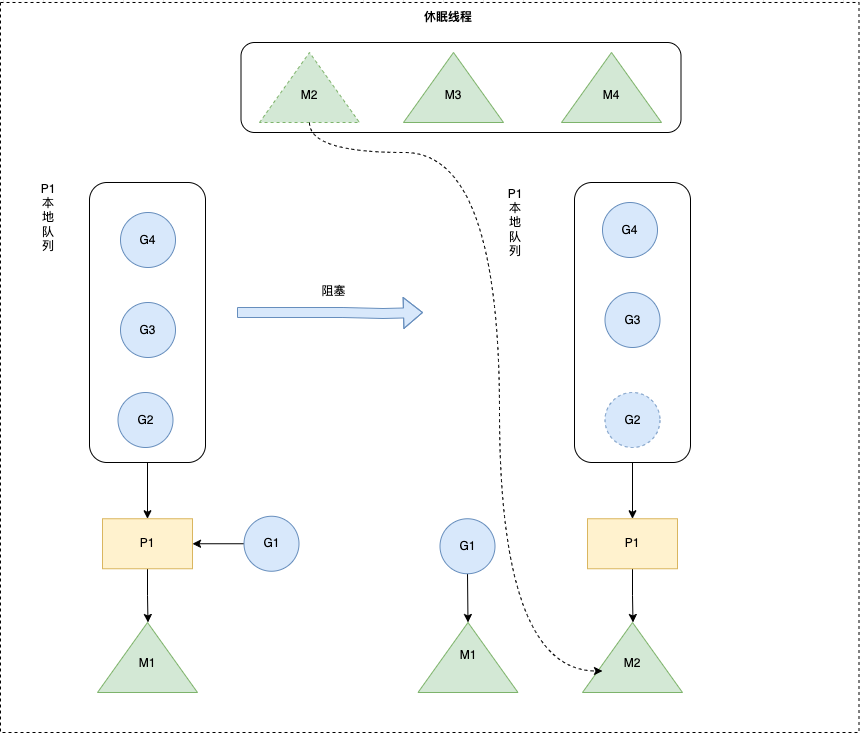
Go 抢占式调度
在1.2版本之前,Go的调度器仍然不支持抢占式调度,程序只能依靠Goroutine主动让出CPU资源才能触发调度,这会引发一些问题,比如:
- 某些 Goroutine 可以长时间占用线程,造成其它 Goroutine 的饥饿
- 垃圾回收器是需要stop the world的,如果垃圾回收器想要运行了,那么它必须先通知其它的goroutine停下来,这会造成较长时间的等待时间
为解决这个问题:
- Go 1.2 中实现了基于协作的“抢占式”调度
- Go 1.14 中实现了基于信号的“抢占式”调度
基于协作的抢占式调度
-
编译器会在调用函数前插入 runtime.morestack,让运行时有机会在这段代码中检查是否需要执行抢占调度
-
Go语言运行时会在垃圾回收暂停程序、系统监控发现 Goroutine 运行超过 10ms,那么会在这个协程设置一个抢占标记
-
当发生函数调用时,可能会执行编译器插入的 runtime.morestack,它调用的 runtime.newstack会检查抢占标记,如果有抢占标记就会触发抢占让出cpu,切到调度主协程里
-
这种解决方案只能说局部解决了“饿死”问题,只在有函数调用的地方才能插入“抢占”代码(埋点),对于没有函数调用而是纯算法循环计算的 G,Go 调度器依然无法抢占。
基于信号的抢占式调度
- M 注册一个 SIGURG 信号的处理函数:sighandler
- sysmon启动后会间隔性的进行监控,最长间隔10ms,最短间隔20us。如果发现某协程独占P超过10ms,会给M发送抢占信号
- M 收到信号后,内核执行 sighandler 函数把当前协程的状态从_Grunning正在执行改成 _Grunnable可执行,把抢占的协程放到全局队列里,M继续寻找其他 goroutine 来运行
- 被抢占的 G 再次调度过来执行时,会继续原来的执行流
抢占分为_Prunning和_Psyscall,_Psyscall抢占通常是由于阻塞性系统调用引起的,比如磁盘io、cgo。_Prunning抢占通常是由于一些类似死循环的计算逻辑引起的。
查看运行时调度信息
在代码中启动 trace goroutine
package mainimport (
"fmt"
"os"
"runtime/trace"
"time"
)func main() {//创建trace文件f, err := os.Create("trace.out")if err != nil {panic(err)}defer f.Close()//启动trace goroutineerr = trace.Start(f)if err != nil {panic(err)}defer trace.Stop()//mainfor i := 0; i < 5; i++ {time.Sleep(time.Second)fmt.Println("Hello World")}
}
go tool trace
go run trace.go
#启动可视化界面
go tool trace trace.out
打开 可视化界面

点击 view trace 能够看见可视化的调度流程:


一共有2个G在程序中,一个是特殊的G0,是每个M必须有的一个初始化的G,另外一个是G1 main goroutine (执行 main 函数的协程),在一段时间内处于可运行和运行的状态。
点击 Threads 那一行可视化的数据条,可以看到M详细的信息

一共有2个 M 在程序中,一个是特殊的 M0,用于初始化使用,另外一个是用于执行G1的M1
点击 Proc 那一行可视化的数据条,我们会看到P上正在运行goroutine详细的信息
一共有3个 P 在程序中,分别是P0、P1、P2
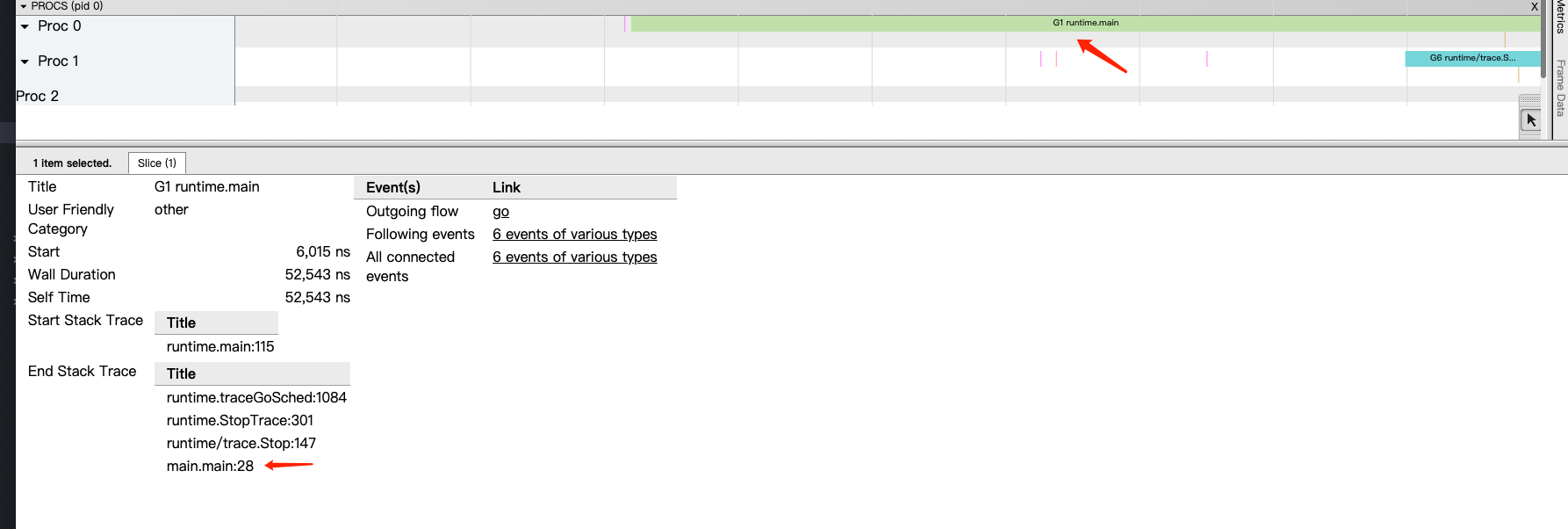
点击具体的 Goroutine 行为后可以看到其相关联的详细信息:
- Start:开始时间
- Wall Duration:持续时间
- Self Time:执行时间
- Start Stack Trace:开始时的堆栈信息
- End Stack Trace:结束时的堆栈信息
- Incoming flow:输入流
- Outgoing flow:输出流
- Preceding events:之前的事件
- Following events:之后的事件
- All connected:所有连接的事件
GODEBUG
GODEBUG 变量可以控制运行时内的调试变量。查看调度器信息,将会使用如下两个参数:
- schedtrace:设置 schedtrace=X 参数可以使运行时在每 X 毫秒发出一行调度器的摘要信息到标准 err 输出中。
- scheddetail:设置 schedtrace=X 和 scheddetail=1 可以使运行时在每 X 毫秒发出一次详细的多行信息,信息内容主要包括调度程序、处理器、OS 线程 和 Goroutine 的状态。
go build trace.go
GODEBUG=schedtrace=1000 ./traceSCHED 0ms: gomaxprocs=8 idleprocs=6 threads=4 spinningthreads=1 idlethreads=0 runqueue=0 [1 0 0 0 0 0 0 0]
Hello World
SCHED 1010ms: gomaxprocs=8 idleprocs=8 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0 0 0 0 0]
Hello World
SCHED 2014ms: gomaxprocs=8 idleprocs=8 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0 0 0 0 0]
Hello World
SCHED 3024ms: gomaxprocs=8 idleprocs=8 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0 0 0 0 0]
Hello World
SCHED 4027ms: gomaxprocs=8 idleprocs=8 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0 0 0 0 0]
Hello World
SCHED 5029ms: gomaxprocs=8 idleprocs=7 threads=4 spinningthreads=0 idlethreads=2 runqueue=0 [0 0 0 0 0 0 0 0]
-
sched:每一行都代表调度器的调试信息,后面提示的毫秒数表示启动到现在的运行时间,输出的时间间隔受 schedtrace 的值影响。
-
gomaxprocs:当前的 CPU 核心数(GOMAXPROCS 的当前值)。
-
idleprocs:空闲的处理器数量,后面的数字表示当前的空闲数量。
-
threads:OS 线程数量,后面的数字表示当前正在运行的线程数量。
-
spinningthreads:自旋状态的 OS 线程数量。
-
idlethreads:空闲的线程数量。
-
runqueue:全局队列中中的 Goroutine 数量,而后面的[0 0 0 0 0 0 0 0] 则分别代表这 8 个 P 的本地队列正在运行的 Goroutine 数量。
详细信息
#查看详细信息
go build trace.go
GODEBUG=scheddetail=1,schedtrace=1000 ./traceSCHED 0ms: gomaxprocs=8 idleprocs=6 threads=4 spinningthreads=1 idlethreads=0 runqueue=0 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0
P0: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=1 gfreecnt=0 timerslen=0
P1: status=1 schedtick=0 syscalltick=0 m=2 runqsize=0 gfreecnt=0 timerslen=0
P2: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 timerslen=0
P3: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 timerslen=0
P4: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 timerslen=0
P5: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 timerslen=0
P6: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 timerslen=0
P7: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 timerslen=0
M3: p=0 curg=-1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 spinning=false blocked=false lockedg=-1
M2: p=1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=2 dying=0 spinning=false blocked=false lockedg=-1
M1: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=2 dying=0 spinning=false blocked=false lockedg=-1
M0: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 spinning=false blocked=false lockedg=1
G1: status=1(chan receive) m=-1 lockedm=0
G2: status=1() m=-1 lockedm=-1
G3: status=1() m=-1 lockedm=-1
G4: status=4(GC scavenge wait) m=-1 lockedm=-1
G
status:G 的运行状态。
m:隶属哪一个 M。
lockedm:是否有锁定 M。
G 的运行状态共涉及如下 9 种状态:
| 状态 | 值 | 含义 |
|---|---|---|
| _Gidle | 0 | 刚刚被分配,还没有进行初始化。 |
| _Grunnable | 1 | 已经在运行队列中,还没有执行用户代码。 |
| _Grunning | 2 | 不在运行队列里中,已经可以执行用户代码,此时已经分配了 M 和 P。 |
| _Gsyscall | 3 | 正在执行系统调用,此时分配了 M。 |
| _Gwaiting | 4 | 在运行时被阻止,没有执行用户代码,也不在运行队列中,此时它正在某处阻塞等待中。 |
| _Gmoribund_unused | 5 | 尚未使用,但是在 gdb 中进行了硬编码。 |
| _Gdead | 6 | 尚未使用,这个状态可能是刚退出或是刚被初始化,此时它并没有执行用户代码,有可能有也有可能没有分配堆栈。 |
| _Genqueue_unused | 7 | 尚未使用。 |
| _Gcopystack | 8 | 正在复制堆栈,并没有执行用户代码,也不在运行队列中。 |
M
p:隶属哪一个 P。
curg:当前正在使用哪个 G。
runqsize:运行队列中的 G 数量。
gfreecnt:可用的G(状态为 Gdead)。
mallocing:是否正在分配内存。
throwing:是否抛出异常。
preemptoff:不等于空字符串的话,保持 curg 在这个 m 上运行。
P
status:P 的运行状态。
schedtick:P 的调度次数。
syscalltick:P 的系统调用次数。
m:隶属哪一个 M。
runqsize:运行队列中的 G 数量。
gfreecnt:可用的G(状态为 Gdead)
| 状态 | 值 | 含义 |
|---|---|---|
| _Pidle | 0 | 刚刚被分配,还没有进行进行初始化。 |
| _Prunning | 1 | 当 M 与 P 绑定调用 acquirep 时,P 的状态会改变为 _Prunning。 |
| _Psyscall | 2 | 正在执行系统调用。 |
| _Pgcstop | 3 | 暂停运行,此时系统正在进行 GC,直至 GC 结束后才会转变到下一个状态阶段。 |
| _Pdead | 4 | 废弃,不再使用。 |
GM 模型
Go早期是GM模型,没有P组件
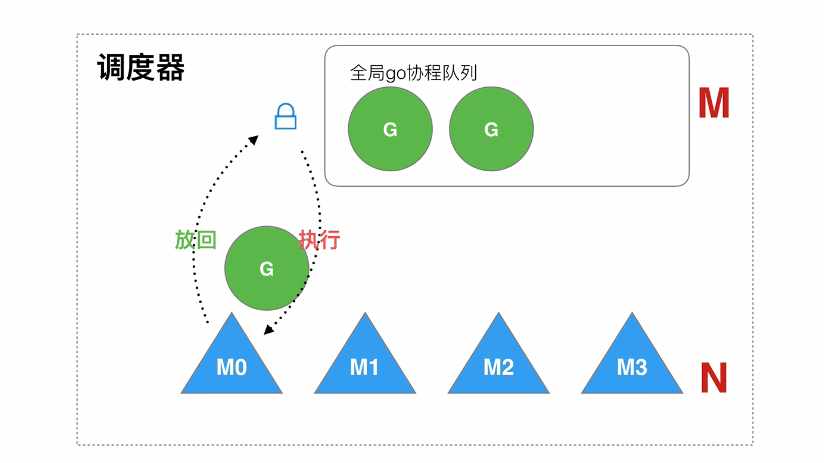
GM调度存在的问题
- 全局队列的锁竞争,当 M 从全局队列中添加或者获取 G 的时候,都需要获取队列锁,导致激烈的锁竞争
- M 转移 G 增加额外开销,当 M1 在执行 G1 的时候, M1 创建了 G2,为了继续执行 G1,需要把 G2 保存到全局队列中,无法保证G2是被M1处理。因为 M1 原本就保存了 G2 的信息,所以 G2 最好是在 M1 上执行,这样的话也不需要转移G到全局队列和线程上下文切换
- 线程使用效率不能最大化,没有work-stealing 和hand-off 机制
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,为了解决这一的问题 go 从 1.1 版本引入P,在运行时系统的时候加入 P 对象,让 P 去管理这个 G 对象,M 想要运行 G,必须绑定 P,才能运行 P 所管理 的 G
在运行时系统的时候加入 P 对象,让 P 去管理这个 G 对象,M 想要运行 G,必须绑定 P,才能运行 P 所管理 的 G
内存分配机制
参考链接
Go语言内置运行时(就是runtime),抛弃了传统的内存分配方式,改为自主管理。这样可以自主地实现更好的内存使用模式,比如内存池、预分配等等。这样,不会每次内存分配都需要进行系统调用。
设计思想
- 内存分配算法采用Google的TCMalloc算法,每个线程都会自行维护一个独立的内存池,进行内存分配时优先从该内存池中分配,当内存池不足时才会向加锁向全局内存池申请,减少系统调用并且避免不同线程对全局内存池的锁竞争
- 把内存切分的非常的细小,分为多级管理,以降低锁的粒度
- 回收对象内存时,并没有将其真正释放掉,只是放回预先分配的大块内存中,以便复用。只有内存闲置过多的时候,才会尝试归还部分内存给操作系统,降低整体开销
分配组件
Go的内存管理组件主要有:
- mspan
- mcache
- mcentral
- mheap
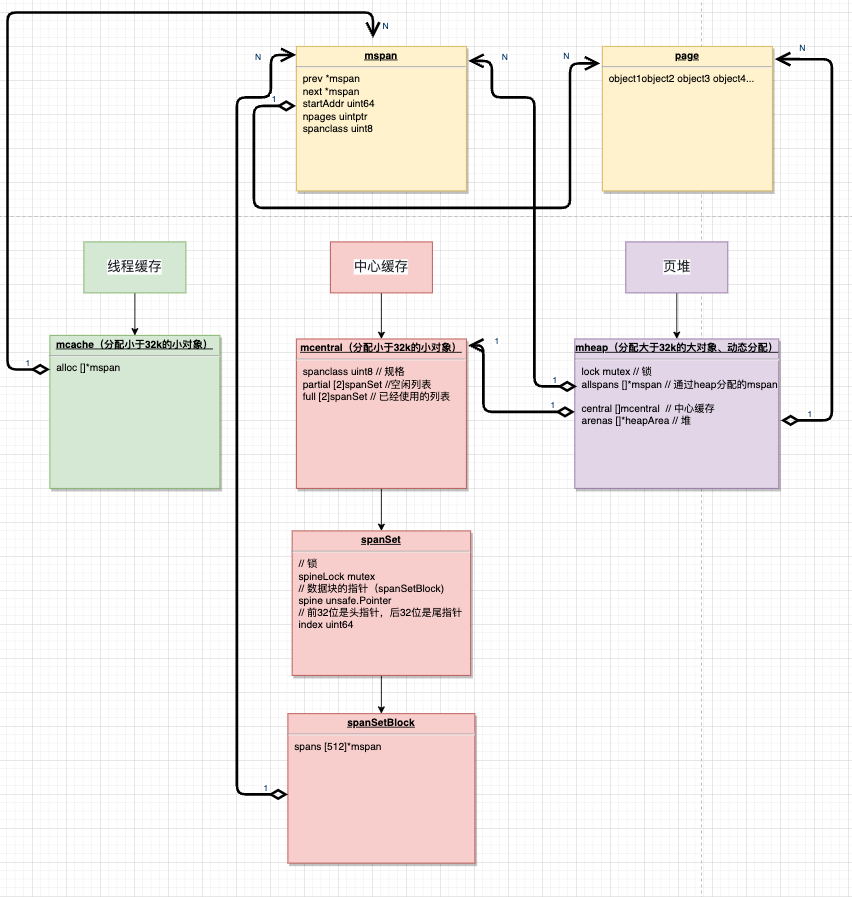
内存管理单元 mspan
mspan是 内存管理的基本单元,该结构体中包含 next 和 prev 两个字段,它们分别指向了前一个和后一个mspan,每个mspan 都管理 npages 个大小为 8KB 的页,一个span 是由多个page组成的,这里的页不是操作系统中的内存页,它们是操作系统内存页的整数倍。
page是内存存储的基本单元,“对象”放到page中
type mspan struct {next *mspan // 后指针prev *mspan // 前指针startAddr uintptr // 管理页的起始地址,指向pagenpages uintptr // 页数spanclass spanClass // 规格...
}type spanClass uint8
Go有68种不同大小的spanClass,用于小对象的分配
const _NumSizeClasses = 68
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
如果按照序号为1的spanClass(对象规格为8B)分配,每个span占用堆的字节数:8k,mspan可以保存1024个对象
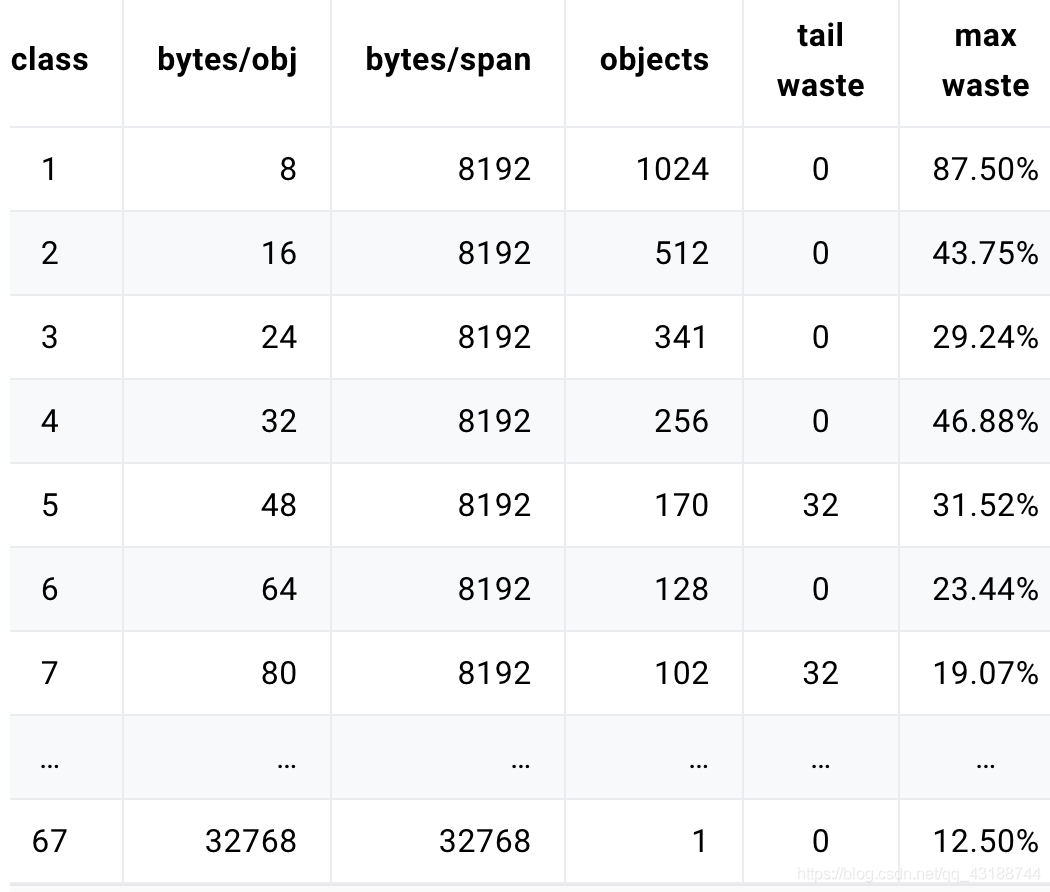
字段含义:
- class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型
- bytes/obj:该class代表对象的字节数
- bytes/span:每个span占用堆的字节数,也即页数*页大小
- objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)
- waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)
大于32k的对象出现时,会直接从heap分配一个特殊的span,这个特殊的span的类型(class)是0, 只包含了一个大对象
线程缓存:mcache
mcache管理线程在本地缓存的mspan,每个goroutine绑定的P都有一个mcache字段
type mcache struct {alloc [numSpanClasses]*mspan
}_NumSizeClasses = 68
numSpanClasses = _NumSizeClasses << 1
mcache用Span Classes作为索引管理多个用于分配的mspan,它包含所有规格的mspan。它是_NumSizeClasses的2倍,也就是682=136,其中2是将spanClass分成了有指针和没有指针两种,方便与垃圾回收。对于每种规格,有2个mspan,一个mspan不包含指针,另一个mspan则包含指针。对于无指针对象的mspan在进行垃圾回收的时候无需进一步扫描它是否引用了其他活跃的对象。
mcache在初始化的时候是没有任何mspan资源的,在使用过程中会动态地从mcentral申请,之后会缓存下来。当对象小于等于32KB大小时,使用mcache的相应规格的mspan进行分配。
中心缓存:mcentral
mcentral管理全局的mspan供所有线程使用,全局mheap变量包含central字段,每个 mcentral 结构都维护在mheap结构内
type mcentral struct {spanclass spanClass // 指当前规格大小partial [2]spanSet // 有空闲object的mspan列表full [2]spanSet // 没有空闲object的mspan列表
}
每个mcentral管理一种spanClass的mspan,并将有空闲空间和没有空闲空间的mspan分开管理。partial和 full的数据类型为spanSet,表示 mspans 集,可以通过pop、push来获得mspans
type spanSet struct {spineLock mutexspine unsafe.Pointer // 指向[]span的指针spineLen uintptr // Spine array length, accessed atomicallyspineCap uintptr // Spine array cap, accessed under lockindex headTailIndex // 前32位是头指针,后32位是尾指针
}
mcache从mcentral获取和归还mspan的流程:
- 获取; 加锁,从partial链表找到一个可用的mspan;并将其从partial链表删除;将取出的mspan加入到full链表;将mspan返回给工作线程,解锁。
- 归还; 加锁,将mspan从full链表删除;将mspan加入到partial链表,解锁。
页堆:mheap
mheap管理Go的所有动态分配内存,可以认为是Go程序持有的整个堆空间,全局唯一
var mheap_ mheaptype mheap struct {lock mutex // 全局锁pages pageAlloc // 页面分配的数据结构allspans []*mspan // 所有通过 mheap_ 申请的mspans// 堆arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena// 所有中心缓存mcentralcentral [numSpanClasses]struct {mcentral mcentralpad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte}...
}
所有mcentral的集合则是存放于mheap中的。mheap里的arena 区域是堆内存的抽象,运行时会将 8KB 看做一页,这些内存页中存储了所有在堆上初始化的对象。运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个 runtime.heapArena 都会管理 64MB 的内存。
当申请内存时,依次经过 mcache 和 mcentral 都没有可用合适规格的大小内存,这时候会向 mheap 申请一块内存。然后按指定规格划分为一些列表,并将其添加到相同规格大小的 mcentral 的 非空闲列表 后面
分配对象
- 微对象 (0, 16B):先使用线程缓存上的微型分配器,再依次尝试线程缓存、中心缓存、堆 分配内存;
- 小对象 [16B, 32KB]:依次尝试线程缓存、中心缓存、堆 分配内存;
- 大对象 (32KB, +∞):直接尝试堆分配内存;
分配流程
- 首先通过计算使用的大小规格
- 然后使用mcache中对应大小规格的块分配。
- 如果mcentral中没有可用的块,则向mheap申请,并根据算法找到最合适的mspan。
- 如果申请到的mspan 超出申请大小,将会根据需求进行切分,以返回用户所需的页数。剩余的页构成一个新的 mspan 放回 mheap 的空闲列表。
- 如果 mheap 中没有可用 span,则向操作系统申请一系列新的页(最小 1MB)

Go 内存逃逸机制
概念
在一段程序中,每一个函数都会有自己的内存区域存放自己的局部变量、返回地址等,这些内存会由编译器在栈中进行分配,每一个函数都会分配一个栈桢,在函数运行结束后进行销毁,但是有些变量我们想在函数运行结束后仍然使用它,那么就需要把这个变量在堆上分配,这种从"栈"上逃逸到"堆"上的现象就成为内存逃逸。
在栈上分配的地址,一般由系统申请和释放,不会有额外性能的开销,比如函数的入参、局部变量、返回值等。在堆上分配的内存,如果要回收掉,需要进行 GC,那么GC 一定会带来额外的性能开销。编程语言不断优化GC算法,主要目的都是为了减少 GC带来的额外性能开销,变量一旦逃逸会导致性能开销变大。
逃逸机制
编译器会根据变量是否被外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中;
- 如果函数外部存在引用,则必定放到堆中;
- 如果栈上放不下,则必定放到堆上;
逃逸分析也就是由编译器决定哪些变量放在栈,哪些放在堆中,通过编译参数-gcflag=-m可以查看编译过程中的逃逸分析,发生逃逸的几种场景如下:
指针逃逸
package mainfunc escape1() *int {var a int = 1return &a
}func main() {escape1()
}
通过 go build -gcflags=-m main.go查看逃逸情况:
./main.go:4:6: moved to heap: a
函数返回值为局部变量的指针,函数虽然退出了,但是因为指针的存在,指向的内存不能随着函数结束而回收,因此只能分配在堆上。
栈空间不足
package mainfunc escape2() {s := make([]int, 0, 10000)for index, _ := range s {s[index] = index
}
}func main() {escape2()
}
通过 go build -gcflags=-m main.go查看逃逸情况:
./main.go:4:11: make([]int, 10000, 10000) escapes to heap
当栈空间足够时,不会发生逃逸,但是当变量过大时,已经完全超过栈空间的大小时,将会发生逃逸到堆上分配内存。局部变量s占用内存过大,编译器会将其分配到堆上
变量大小不确定
package mainfunc escape3() {number := 10s := make([]int, number) // 编译期间无法确定slice的长度for i := 0; i < len(s); i++ {s[i] = i}
}func main() {escape3()
}
编译期间无法确定slice的长度,这种情况为了保证内存的安全,编译器也会触发逃逸,在堆上进行分配内存。直接s := make([]int, 10)不会发生逃逸
动态类型
动态类型就是编译期间不确定参数的类型、参数的长度也不确定的情况下就会发生逃逸
空接口 interface{} 可以表示任意的类型,如果函数参数为 interface{},编译期间很难确定其参数的具体类型,也会发生逃逸。
package mainimport "fmt"func escape4() {fmt.Println(1111)
}func main() {escape4()
}
通过 go build -gcflags=-m main.go查看逃逸情况:
./main.go:6:14: 1111 escapes to heap
fmt.Println(a …interface{})函数参数为interface,编译器不确定参数的类型,会将变量分配到堆上
闭包引用对象
package mainfunc escape5() func() int {var i int = 1return func() int {i++return i}
}func main() {escape5()
}
通过 go build -gcflags=-m main.go查看逃逸情况:
./main.go:4:6: moved to heap: i
总结
-
栈上分配内存比在堆中分配内存效率更高
-
栈上分配的内存不需要 GC 处理,而堆需要
-
逃逸分析目的是决定内分配地址是栈还是堆
-
逃逸分析在编译阶段完成
因为无论变量的大小,只要是指针变量都会在堆上分配,所以对于小变量我们还是使用传值效率(而不是传指针)更高一点。
Go 内存对齐机制
为了能让CPU可以更快的存取到各个字段,Go编译器会帮你把struct结构体做数据的对齐。所谓的数据对齐,是指内存地址是所存储数据大小(按字节为单位)的整数倍,以便CPU可以一次将该数据从内存中读取出来。 编译器通过在结构体的各个字段之间填充一些空白已达到对齐的目的。
内存对齐是指首地址对齐,CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问,数据结构应该尽可能地在自然边界上对齐**,如果访问未对齐的内存,处理器需要做两次内存访问,然后拼接字节流。
对齐系数
不同硬件平台占用的大小和对齐值都可能是不一样的,每个特定平台上的编译器都有自己的默认"对齐系数",32位系统对齐系数是4,64位系统对齐系数是8
不同类型的对齐系数也可能不一样,使用Go语言中的unsafe.Alignof函数可以返回相应类型的对齐系数,对齐系数都符合2^n这个规律,最大也不会超过8
数据类型对齐边界是取类型大小与平台最大对其边界中较小的那一个。

优点
-
提高可移植性,有些CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了
-
提高内存的访问效率,32位CPU下一次可以从内存中读取32位(4个字节)的数据,64位CPU下一次可以从内存中读取64位(8个字节)的数据,这个长度也称为CPU的字长。CPU一次可以读取1个字长的数据到内存中,如果所需要读取的数据正好跨了1个字长,那就得花两个CPU周期的时间去读取了。因此在内存中存放数据时进行对齐,可以提高内存访问效率。
缺点
存在内存空间的浪费,实际上是空间换时间
结构体对齐
对齐原则:
- 结构体变量中成员的偏移量必须是成员大小的整数倍
- 整个结构体的地址必须是最大字节的整数倍(结构体的内存占用是1/4/8/16byte…)
package mainimport ("fmt""runtime""unsafe"
)type T1 struct {i16 int16 // 2 bytebool bool // 1 byte
}type T2 struct {i8 int8 // 1 bytei64 int64 // 8 bytei32 int32 // 4 byte
}type T3 struct {i8 int8 // 1 bytei32 int32 // 4 bytei64 int64 // 8 byte
}func main() {fmt.Println(runtime.GOARCH) // amd64t1 := T1{}fmt.Println(unsafe.Sizeof(t1)) // 4 bytest2 := T2{}fmt.Println(unsafe.Sizeof(t2)) // 24 bytest3 := T3{}fmt.Println(unsafe.Sizeof(t3)) // 16 bytes
}
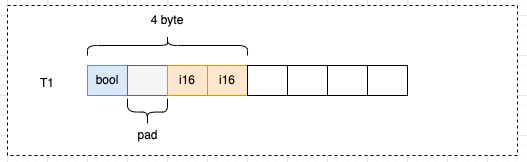
以T1结构体为例,实际存储数据的只有3字节,但实际用了4字节,浪费了1个字节:
i16并没有直接放在bool的后面,而是在bool中填充了一个空白后,放到了偏移量为2的位置上。
如果i16从偏移量为1的位置开始占用2个字节,根据对齐原则2:构体变量中成员的偏移量必须是成员大小的整数倍,套用公式 1 % 2 = 1,就不满足对齐的要求,所以i16从偏移量为2的位置开始
以T2结构体为例,实际存储数据的只有13字节,但实际用了24字节,浪费了11个字节:

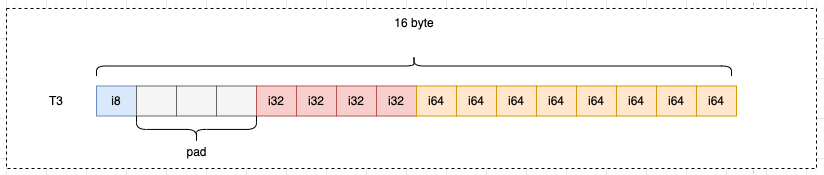
以T3结构体为例,实际存储数据的只有13字节,但实际用了16字节,浪费了3个字节:
Go GC
垃圾回收也称为GC(Garbage Collection),是一种自动内存管理机制
现代高级编程语言管理内存的方式分为两种:自动和手动,像C、C++ 等编程语言使用手动管理内存的方式,工程师编写代码过程中需要主动申请或者释放内存;而 PHP、Java 和 Go 等语言使用自动的内存管理系统,有内存分配器和垃圾收集器来代为分配和回收内存,其中垃圾收集器就是我们常说的GC。
在应用程序中会使用到两种内存,分别为堆(Heap)和栈(Stack),GC负责回收堆内存,而不负责回收栈中的内存:
栈是线程的专用内存,专门为了函数执行而准备的,存储着函数中的局部变量以及调用栈,函数执行完后,编译器可以将栈上分配的内存可以直接释放,不需要通过GC来回收。
堆是程序共享的内存,需要GC进行回收在堆上分配的内存。
垃圾回收器的执行过程被划分为两个半独立的组件:
- 赋值器(Mutator):这一名称本质上是在指代用户态的代码。因为对垃圾回收器而言,用户态的代码仅仅只是在修改对象之间的引用关系,也就是在对象图(对象之间引用关系的一个有向图)上进行操作。
- 回收器(Collector):负责执行垃圾回收的代码。
判断对象可以被回收的方法
- 引用计数法
为每个对象维护一个引用计数,当引用该对象的对象销毁时,引用计数 -1,当对象引用计数为 0 时回收该对象。 - 可达性分析
通过一系列的“GC roots”对象作为起点搜索。如果在“GC roots”和一个对象之间没有可达路径,则称该对象是不可达的。要注意的是,不可达对象不等价于可回收对象, 不可达对象变为可回收对象至少要经过两次标记过程。两次标记后仍然是可回收对象,则将面临回收。
垃圾回收算法
- 复制算法:按照容量划分二个大小相等的内存区域,当一块用完的时候将活着的对象复制到另一块上,然后再把已使用的内存空间一次清理掉。缺点:内存使用率不高,只有原来的一半。
- 分代收集:按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,短的放入新生代,不同代有不同的回收算法和回收频率。
- 代表语言:Java
- 优点:回收性能好
- 缺点:算法复杂
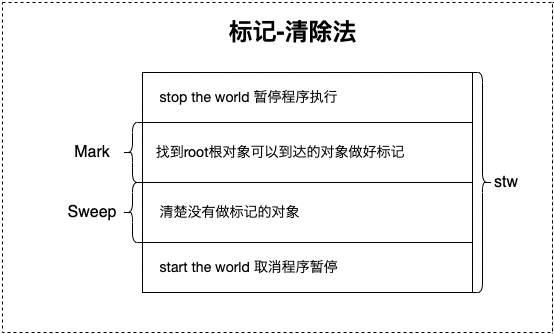
- 标记-清除:从根变量开始遍历所有引用的对象,标记引用的对象,没有被标记的进行回收。
代表语言:Golang(三色标记法)
优点:解决了引用计数的缺点。
缺点:需要 STW,暂时停掉程序运行。
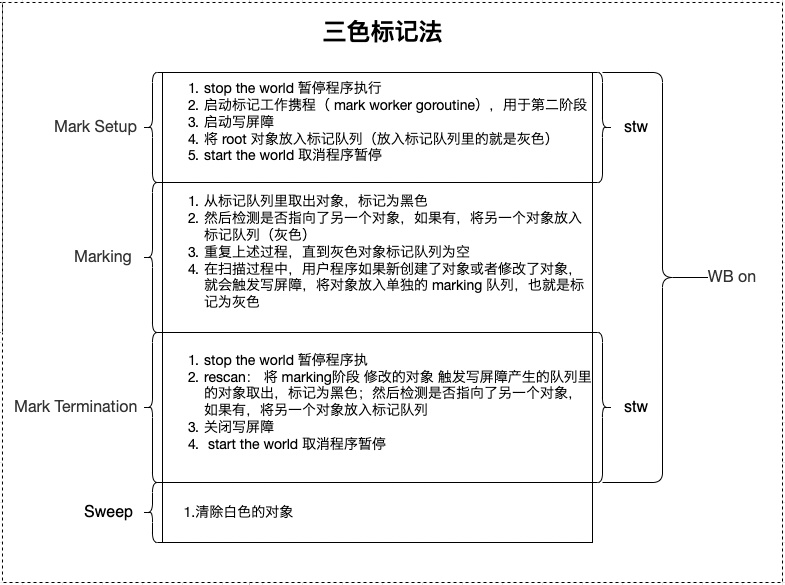
Go GC算法 三色标记法
此算法是在Go 1.5版本开始使用,Go 语言采用的是标记清除算法,并在此基础上使用了三色标记法和混合写屏障技术,GC过程和其他用户goroutine可并发运行,但需要一定时间的STW
三色标记法只是为了叙述方便而抽象出来的一种说法,实际上的对象是没有三色之分的。这里的三色,对应了垃圾回收过程中对象的三种状态:
- 灰色:对象还在标记队列中等待
- 黑色:对象已被标记,gcmarkBits 对应位为 1 (该对象不会在本次 GC 中被回收)
- 白色:对象未被标记,gcmarkBits 对应位为 0 (该对象将会在本次 GC 中被清理)
- step 1: 创建:白、灰、黑 三个集合
- step 2: 将所有对象放入白色集合中
- step 3: 遍历所有root对象,把遍历到的对象从白色集合放入灰色集合 (这里放入灰色集合的都是根节点的对象)
- step 4: 遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,自身标记为黑色
- step 5: 重复步骤4,直到灰色中无任何对象,其中用到2个机制:
- 写屏障(Write Barrier):上面说到的 STW 的目的是防止 GC 扫描时内存变化引起的混乱,而写屏障就是让 goroutine 与 GC 同时运行的手段,虽然不能完全消除 STW,但是可以大大减少 STW 的时间。写屏障在 GC 的特定时间开启,开启后指针传递时会把指针标记,即本轮不回收,下次 GC 时再确定。
- 辅助 GC(Mutator Assist):为了防止内存分配过快,在 GC 执行过程中,GC 过程中 mutator 线程会并发运行,而 mutator assist 机制会协助 GC 做一部分的工作。
- step 6: 收集所有白色对象(垃圾)
root对象
根对象在垃圾回收的术语中又叫做根集合,它是垃圾回收器在标记过程时最先检查的对象,包括:
全局变量:程序在编译期就能确定的那些存在于程序整个生命周期的变量。
执行栈:每个 goroutine 都包含自己的执行栈,这些执行栈上指向堆内存的指针。
寄存器:寄存器的值可能表示一个指针,参与计算的这些指针可能指向某些赋值器分配的堆内存区块。
不STW,并发清除不希望同时发生的两个条件
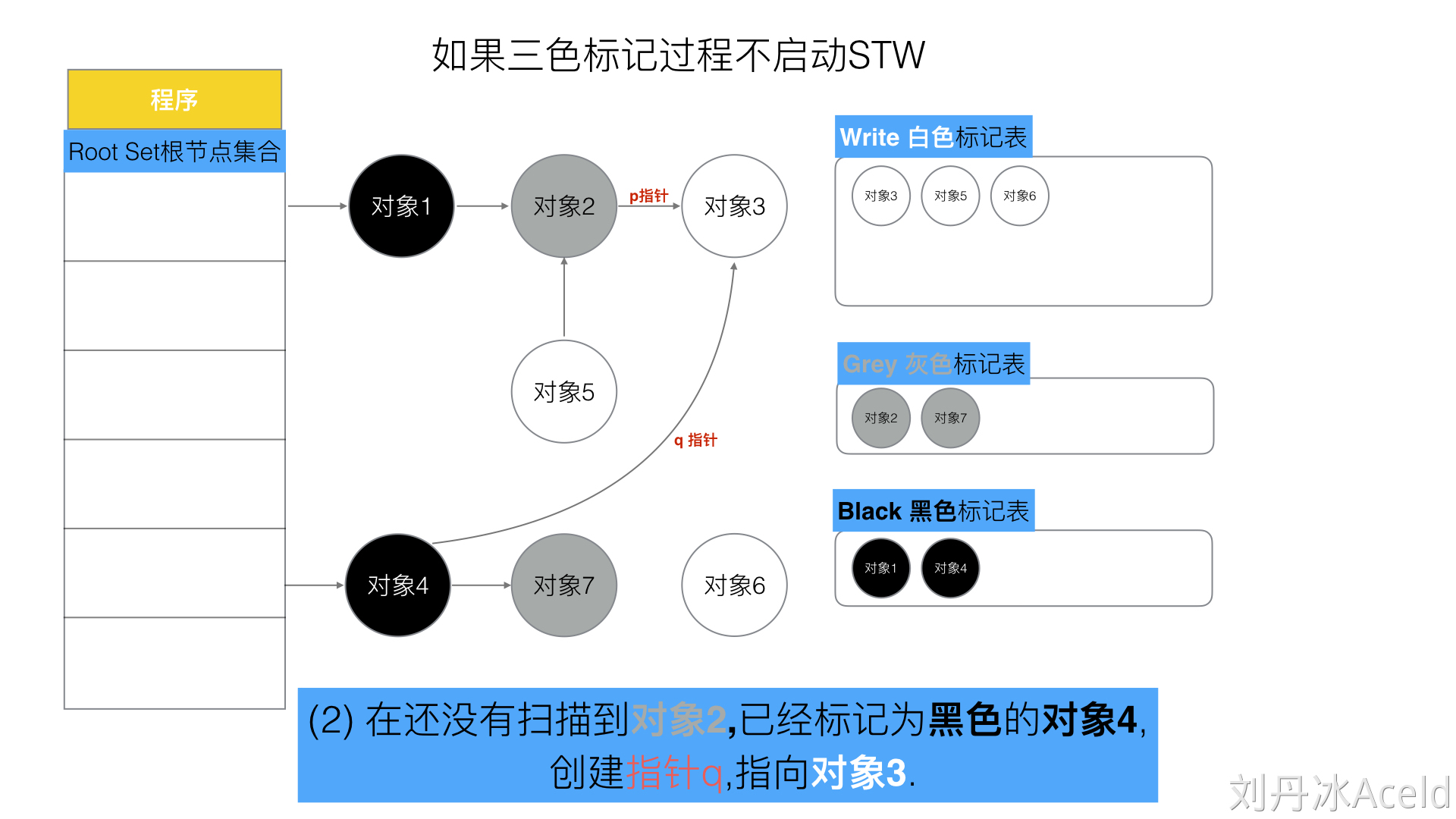
● 条件1: 一个白色对象被黑色对象引用(白色被挂在黑色下)
● 条件2: 灰色对象与它之间的可达关系的白色对象遭到破坏(灰色同时丢了该白色)
如果当以上两个条件同时满足时,就会出现对象丢失现象!
插入写屏障
对象被引用时触发的机制(只在堆内存中生效):赋值器这一行为通知给并发执行的回收器,被引用的对象标记为灰色
缺点:结束时需要STW来重新扫描栈,标记栈上引用的白色对象的存活
删除写屏障
对象被删除时触发的机制(只在堆内存中生效):赋值器将这一行为通知给并发执行的回收器,被删除的对象,如果自身为灰色或者白色,那么标记为灰色
缺点:一个对象的引用被删除后,即使没有其他存活的对象引用它,它仍然会活到下一轮,会产生很大冗余扫描成本,且降低了回收精度
混合写屏障
GC没有混合写屏障前,一直是插入写屏障;混合写屏障是插入写屏障 + 删除写屏障,写屏障只应用在堆上应用,栈上不启用(栈上启用成本很高)
-
GC开始将栈上的对象全部扫描并标记为黑色。
-
GC期间,任何在栈上创建的新对象,均为黑色。
-
被删除的对象标记为灰色。
-
被添加的对象标记为灰色。
GC流程
一次完整的垃圾回收会分为四个阶段,分别是标记准备、标记开始、标记终止、清理:
- 标记准备(Mark Setup):打开写屏障(Write Barrier),需 STW(stop the world)
- 标记开始(Marking):使用三色标记法并发标记 ,与用户程序并发执行
- 标记终止(Mark Termination):对触发写屏障的对象进行重新扫描标记,关闭写屏障(Write Barrier),需 STW(stop the world)
- 清理(Sweeping):将需要回收的内存归还到堆中,将过多的内存归还给操作系统,与用户程序并发执行
GC触发时机
-
主动触发:
调用 runtime.GC() 方法,触发 GC
-
被动触发:
- 定时触发,该触发条件由 runtime.forcegcperiod 变量控制,默认为 2 分 钟。当超过两分钟没有产生任何 GC 时,触发 GC
- 根据内存分配阈值触发,该触发条件由环境变量GOGC控制,默认值为100(100%),当前堆内存占用是上次GC结束后占用内存的2倍时,触发GC
GC算法演进
- Go 1:mark and sweep操作都需要STW
- Go 1.3:分离了mark和sweep操作,mark过程需要STW,mark完成后让sweep任务和普通协程任务一样并行,停顿时间在约几百ms
- Go1.5:引入三色并发标记法、插入写屏障,不需要每次都扫描整个内存空间,可以减少stop the world的时间,停顿时间在100ms以内
- Go 1.6:使用 bitmap 来记录回收内存的位置,大幅优化垃圾回收器自身消耗的内存,停顿时间在10ms以内
- Go1.7:停顿时间控制在2ms以内
- Go 1.8:混合写屏障(插入写屏障和删除写屏障),停顿时间在0.5ms左右
- Go 1.9:彻底移除了栈的重扫描过程
- Go 1.12:整合了两个阶段的 Mark Termination
- Go 1.13:着手解决向操作系统归还内存的,提出了新的 Scavenger
- Go 1.14:替代了仅存活了一个版本的 scavenger,全新的页分配器,优化分配内存过程的速率与现有的扩展性问题,并引入了异步抢占,解决了由于密集循环导致的 STW时间过长的问题
GC 参考链接

GO GC 调优
调优的方面
- 控制内存分配的速度,限制 Goroutine 的数量,提高赋值器 mutator 的 CPU 利用率(降低GC的CPU利用率)
- 少量使用+连接string
- slice提前分配足够的内存来降低扩容带来的拷贝
- 避免map key对象过多,导致扫描时间增加
- 变量复用,减少对象分配,例如使用 sync.Pool 来复用需要频繁创建临时对象、使用全局变量等
- 增大 GOGC 的值,降低 GC 的运行频率
查看 GC 信息方法
GODEBUG=‘gctrace=1’
GODEBUG='gctrace=1' go run main.gogc 1 @0.003s 4%: 0.013+1.7+0.008 ms clock, 0.10+0.67/1.2/0.018+0.064 ms cpu, 4->6->2 MB, 5 MB goal, 8 P
gc 2 @0.006s 2%: 0.006+4.5+0.058 ms clock, 0.048+0.070/0.027/3.6+0.47 ms cpu, 4->5->1 MB, 5 MB goal, 8 P
字段含义
| 字段 | 含义 |
|---|---|
| gc 2 | 第二个 GC 周期 |
| 0.006 | 程序开始后的 0.006 秒 |
| 2% | 该 GC 周期中 CPU 的使用率 |
| 0.006 | 标记开始时, STW 所花费的时间(wall clock) |
| 4.5 | 标记过程中,并发标记所花费的时间(wall clock) |
| 0.058 | 标记终止时, STW 所花费的时间(wall clock) |
| 0.048 | 标记开始时, STW 所花费的时间(cpu time) |
| 0.070 | 标记过程中,标记辅助所花费的时间(cpu time) |
| 0.027 | 标记过程中,并发标记所花费的时间(cpu time) |
| 3.6 | 标记过程中,GC 空闲的时间(cpu time) |
| 0.47 | 标记终止时, STW 所花费的时间(cpu time) |
| 4 | 标记开始时,堆的大小的实际值 |
| 5 | 标记结束时,堆的大小的实际值 |
| 1 | 标记结束时,标记为存活的对象大小 |
| 5 | 标记结束时,堆的大小的预测值 |
| 8 | P 的数量 |
go tool trace
package mainimport ("os""runtime/trace"
)func main() {f, _ := os.Create("trace.out")defer f.Close()trace.Start(f)defer trace.Stop()for n := 1; n < 100000; n++ {_ = make([]byte, 1<<20)}
}
go run main.go
go tool trace trace.out
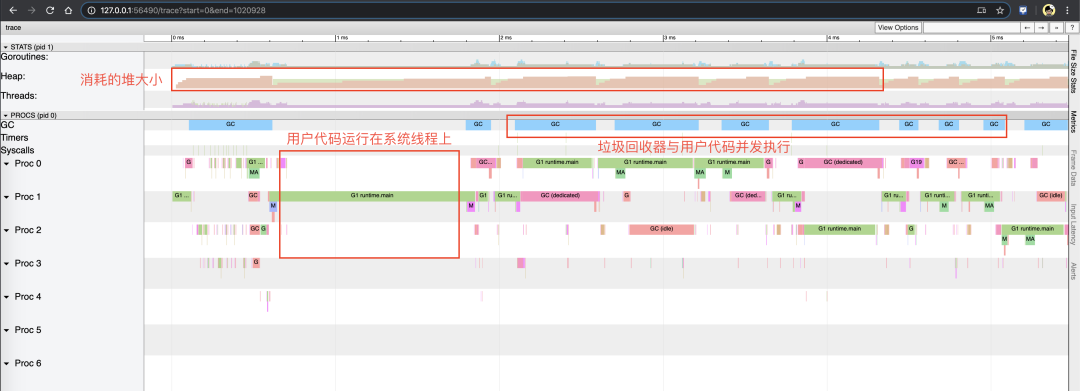
点击View trace,可以查看当时的trace情况
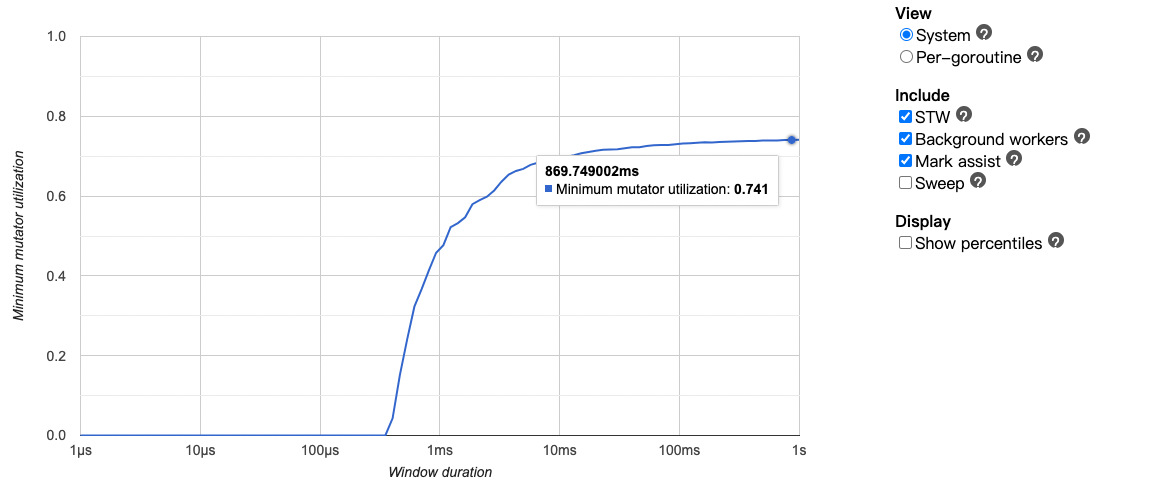
点击 Minimum mutator utilization,可以查看到赋值器 mutator (用户程序)对 CPU 的利用率 74.1%,接近100%则代表没有针对GC的优化空间了
debug.ReadGCStats
runtime.ReadMemStats
并发同步原语
Atomic
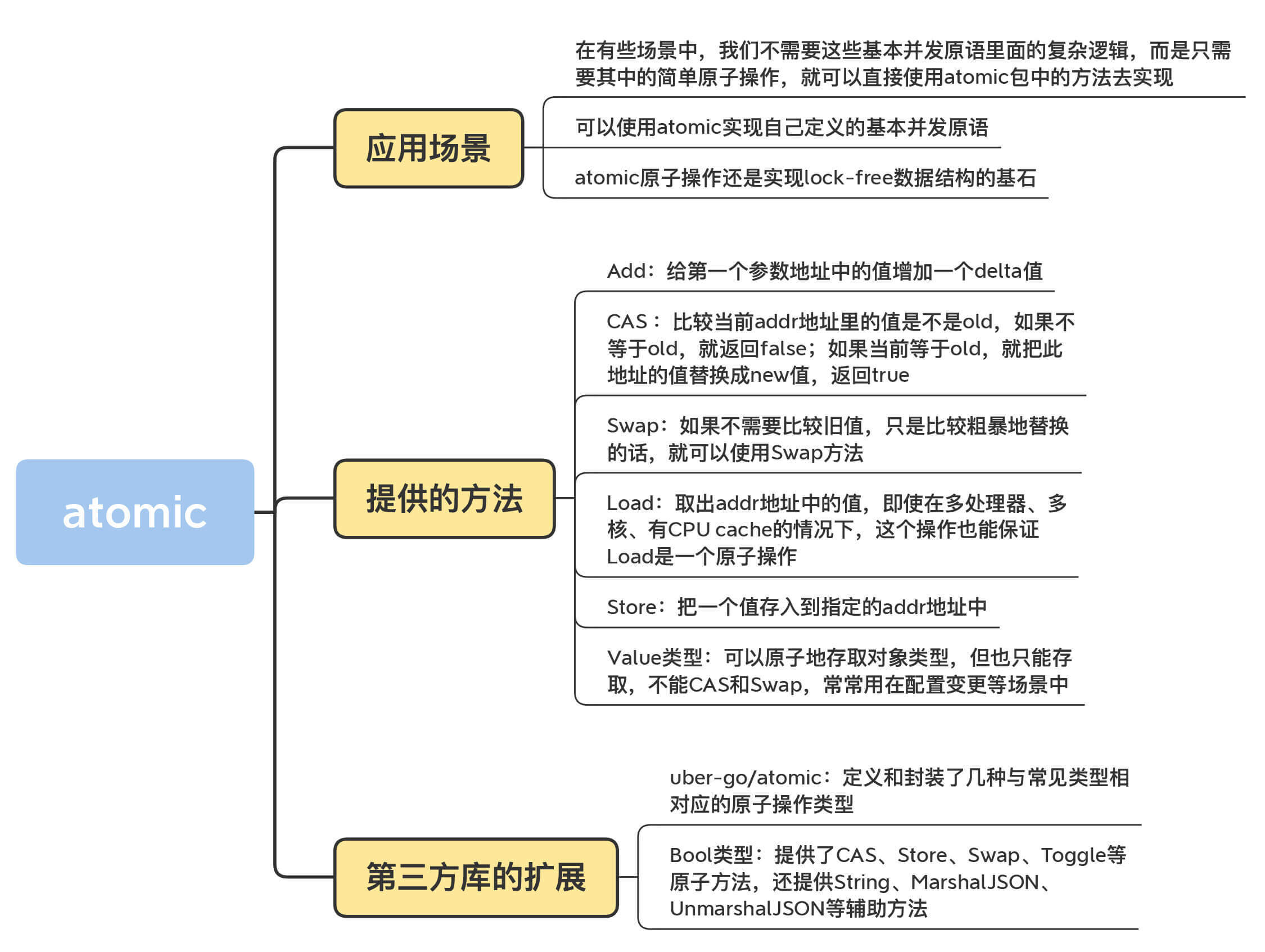
Channel
channel 管道,高级同步原语,goroutine之间通信的桥梁
使用场景:消息队列、数据传递、信号通知、任务编排、锁
基本并发原语
常见的并发原语如下:sync.Mutex、sync.RWMutex、sync.WaitGroup、sync.Cond、sync.Once、sync.Pool、sync.Context
Go WaitGroup实现原理
// A WaitGroup must not be copied after first use.
type WaitGroup struct {noCopy noCopystate1 [3]uint32
}
-
noCopy 是 golang 源码中检测禁止拷贝的技术。如果程序中有 WaitGroup 的赋值行为,使用 go vet 检查程序时,就会发现有报错。但需要注意的是,noCopy 不会影响程序正常的编译和运行。
-
state1主要是存储着状态和信号量,状态维护了 2 个计数器,一个是请求计数器counter ,另外一个是等待计数器waiter(已调用 WaitGroup.Wait 的 goroutine 的个数)
在WaitGroup里主要有3个方法:
- WaitGroup.Add():可以添加或减少请求的goroutine数量,Add(n) 将会导致 counter += n
- WaitGroup.Done():相当于Add(-1),Done() 将导致 counter -=1,请求计数器counter为0 时通过信号量调用runtime_Semrelease唤醒waiter线程
- WaitGroup.Wait():会将 waiter++,同时通过信号量调用 runtime_Semacquire(semap)阻塞当前 goroutine
数据竞争
概念
只要有两个以上的goroutine并发访问同一变量,且至少其中的一个是写操作的时候就会发生数据竞争;全是读的情况下是不存在数据竞争的。
排查方式
package mainimport "fmt"func main() {i := 0go func() {i++ // write i}()fmt.Println(i) // read i
}
go run -race main.goWARNING: DATA RACE
Write at 0x00c0000ba008 by goroutine 7:
exit status 66
Gin
特点:轻量级Web框架,高效、快速、易于扩展。
Gin支持哪些HTTP请求方式
GET、POST、PUT、PATCH、DELETE、HEAD和OPTIONS。
c.Request.Method获取当前请求的HTTP方法
Gin中获取处理GET和POST请求参数
GET:c.Query()方法获取GET请求参数,也可以通过c.DefaultQuery()方法设置默认值
POST:c.PostForm()或c.DefaultPostForm()方法获取POST请求参数,其中c.PostForm()方法只能解析Content-Type为application/x-www-form-urlencoded的表单数据,而c.DefaultPostForm()方法除了可以解析该类型的表单数据外,还可以解析multipart/form-data类型的表单数据。
路由的实现
Gin框架通过路由来确定函数执行的路径,可以使用router :=
gin.Default()创建默认路由组,然后使用router.GET()、router.POST()等方法添加不同请求方式的路由。路由可以包含参数,例如/:name可以匹配任意名称的路径片段,并将该片段存储在name变量中。
中间件
用途:可用于跨域访问、身份认证、数据校验、添加日志
使用方法:可以通过使用gin.Use()方法来添加全局中间件,也可以通过group.Use()方法在指定路由组中添加中间件。
原理:http请求来到时先经过中间件,再到具体的处理函数,gin框架通过移动HandlerFunc切片下标index的位置,实现中间件的调用
Abort()函数的源码,index移动末尾了,所以后面的中间件/路由处理函数,都没法执行
func (c *Context) Abort() {c.index = abortIndex
}
而Next()函数的源码,通过不断的移动下标实现了中间件函数的依次调用,所以在函数调用完毕后,继续执行Next()下方的代码
func (c *Context) Next() {c.index++for c.index < int8(len(c.handlers)) {c.handlers[c.index](c)c.index++}
}
处理并发请求
Gin框架默认使用多协程处理并发请求,每个请求都会被分配到一个独立的协程中执行,可以充分利用CPU资源提高并发处理能力。此外,Gin框架还提供了异步HTTP请求处理的功能,可以通过使用context.Context对象来控制异步请求的超时时间和取消操作。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!