查进程 linux的命令etr,高通平台Linux kernel死机解题心得
一、前言
1.1 目的
可以结合知识背景,借助相关调试工具,使用通常分析手段分析、定位解决项目过程当中遇到的死机类系统稳定性问题,提高工做效率
持续积累,拓宽知识深度和广度
1.2 死机?
指系统发生致命性异常致使主动或者被动进入系统彻底不可用的状态,致使系统死机的问题缘由有不少,排除硬件问题,还有这些大模块:Android、Linux kenrel、modem、TZ 等等,各个子系统都有可能致使系统死机重启,咱们这里主要介绍最多见的Linux kernel panic的通常调试分析手法。
1.3 调试策略
。
稳定复现的问题,能够借助飞线抓
uart log的方式来获取异常现场,kernel在发生panic以前会把不少重要寄存器信息、以及重要的call stack(调用栈)信息打印出来(可参考
http://blog.csdn.net/forever_2015/article/details/53235716),一般能够借助相关GNU工具(addr2Line) 解析出异常地址所在的文件、函数、行号来定位问题。这是最经常使用的分析手法,对于不少简单的死机问题一般能够比较清晰的定位解决。
。
几率性复现的问题,上面飞线抓uart log的方式就显得有些无力了,因为出现异常的时机存在不肯定性,因此必需要一直连着串口线操做才能够,还有些问题几天或者更长时间才出现一次,此种状况下,普通的抓uart log的方式就显得很苍白无力了。这个时候就须要借助另外的分析手段抓
ramdump分析了。ramdump是什么?其实就是指内存转储,简单来讲就是整个DRAM的运行时内容数据,当系统发生崩溃性异常时候,经过一种机制实现将DRAM中的数据保存起来的一种方式,保留了异常现场,待离线分析用。ramdump中保留了因此异常时候的DRAM中的信息,包括各类全局变量、局部变量、进程状态等待供调试的信息,经过Crash、gdb、Trace32等工具就能够完成这些信息的提早,很是有助于复杂问题的分析。
二、案例描述
2.1 问题现象:
高通8940平台系统灭屏下,快速重复用错误指纹触摸指纹模组(或亮屏在指纹列表目录下),系统死机,持续测试30min出现2-4次,几率很高。
2.2 初步判断
咱们知道Android层(用户空间进程)若是主线程(tid == 0)被堵塞了会触发Watchdog time out致使system_server进程被杀 =》zygote被杀 =》开机动画响起,出现Android crash的状况:
services/core/java/com/android/server/Watchdog.java :533
Slog.w(TAG, "***GOODBYE!");Process.killProcess(Process.myPid());System.exit(10);
一般这种状况出现异常后不会立刻死机重启,会有一个触发WDT的等待时间(各类组件前台后台进程触发时间设置策略不一样),此种类型异常给用户的感受就是:指纹失效了,而后等个10s左右手机自动重启。
而目前的状况不一样,与测试mm沟通确认发现,出问题后手机没有任何等待,直接黑屏死机,没有重启,直接进入了ramdump模式,因此能够初步判断为
底层发现异常,而跟指纹相关的最大可能就是发生了kernel panic(TA crash异常最终会以Android wdt方式表现出来)。
三、ramdump的抓取
高通平台首先保证机器是已使能ramdump抓取机制的,默认设置开关:
kernel/drivers/power/reset/msm-poweroff.c
static intdownload_mode = 1;
若是开启了secboot 支持的项目还须要更改BOOT:
BOOT.BF.3.3/boot_images/core/securemsm/secdbgplcy/oem/oem_debug_policy.c-//#define SKIP_SERIAL_NUMBER_CHECK 1+#define SKIP_SERIAL_NUMBER_CHECK 1
高通平台可使用PC端的QPST工具抓取所有的dump信息,步骤以下:
安装QPST工具(须要安装QBUK驱动),打开程序主界面,选址Ports分页:
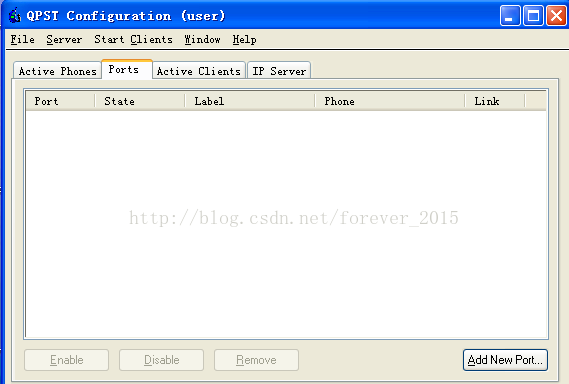
插入usb,自动识别抓取ramdump,彻底傻瓜式操做:
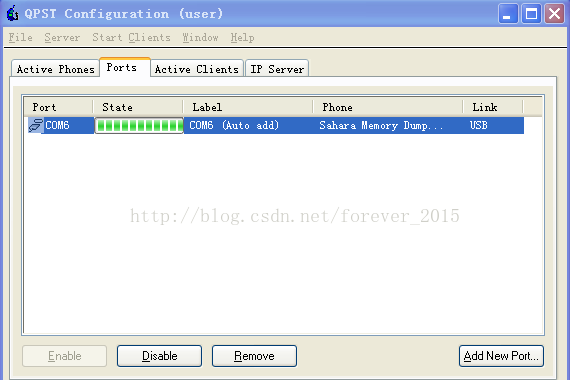
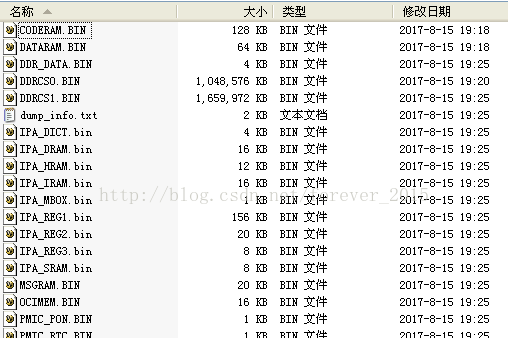
大概5min左右完成,选择 Help =》Open Log File Directory ,拿到抓取的ramdump数据:
PS: 若仅仅是为了测试调试,能够这样主动触发ramdump
adb root
adb shell
echo c > /proc/sysrq-trigger
其本质就是让内核访问空指针内存,被MMU拦截而触发data abort异常.
四、 ramdump解析
4.1 高通QCAP网站
登陆高通帐户后进入以下界面:(此处建议使用google浏览器,个别浏览器有不支持的状况)
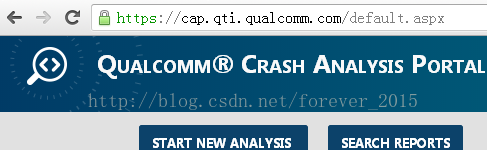
点击
START NEW ANALYSIS
将对应模块(KERNEL/TZ/RPM/MODEM/ADSP等)的符号文件(elf、vmlinux)路径加到对应的选项里面选择开始便可,解析完成后会产生一个报告文件:QCAPReport.html ,里面会有各个模块的相关异常信息描述,包括dmesg等等。QCAP的优势是使用简单,工具安装简单,缺点是解析出来的信息颇有限,跟抓log差很少的意思,没法分析定位复杂问题。(QCAP的使用能够参考高通文档:80-nr964-54_j_qcap start-up guide.pdf)
4.2 ramdump-parse
(此脚本只能解析kernel的异常,不一样子系统须要配合不一样的解析脚步)
解析前须要确保vimlinux跟ramdump的一致性,能够按下面的方法确认:
$ strings vmlinux |grep "Linux version"
Linux version 3.18.31 (android@ubuntu) (gcc version4.9 20150123 (prerelease) (GCC) ) #1 SMP PREEMPT Wed Aug9 23:23:27CST 2017
$ strings DDRCS0.BIN |grep "Linux version"
Linux version 3.18.31 (android@ubuntu) (gcc version4.9 20150123 (prerelease) (GCC) ) #1 SMP PREEMPT Wed Aug9 23:23:27CST 2017
若是不匹配,没法继续分析,若确认匹配后就能够执行解析:
$ ramdump-parser.sh
Start ramdump parser..
cd /home/android/tools/ramdump/tools/linux-ramdump-parser-v2
python ramparse.py -v /home/android/share/fp-quick-wakeup/crash/Port_COM112-6901-die/vmlinux -g /home/android/tools/gnu-tools/aarch64-linux-android-4.9/bin/aarch64-linux-android-gdb -n /home/android/tools/gnu-tools/aarch64-linux-android-4.9/bin/aarch64-linux-android-nm -j /home/android/tools/gnu-tools/aarch64-linux-android-4.9/bin/aarch64-linux-android-objdump -a /home/android/share/fp-quick-wakeup/crash/Port_COM112-6901-die/ -o /home/android/share/fp-quick-wakeup/crash/Port_COM112-6901-die/out -x
[1/32] --clock-dump ... 0.848617s
[2/32] --cpr3-info ... 0.157973s
[3/32] --cpr-info ... 1.026817s
[4/32] --cpu-state ... 0.104325s
[5/32] --ddr-compare ... 5.864537s
[6/32] --check-for-watchdog ... 0.011254s
[7/32] --parse-debug-image ... 10.632866s
[8/32] --dmesg ... 0.519516s
...
out: /home/android/share/fp-quick-wakeup/crash/Port_COM112-6901-die/out
ls out/
ClockDumps.txt DDRCacheCompare.txt MSM_DUMP_DATA_L1_DATA_CACHE_0x2 roareadiff.txt t32_startup_script.cmm thermal_info.txt
core0_regs.cmm dmesg_TZ.txt MSM_DUMP_DATA_L1_DATA_CACHE_0x3 secure_world_core0_regs.cmm tasks_sched_stats0.txt timerlist.txt
core1_regs.cmm kconfig.txt MSM_DUMP_DATA_L1_DATA_CACHE_0x6 secure_world_core1_regs.cmm tasks_sched_stats1.txt tmc-etf.bin
core2_regs.cmm launch_t32.sh MSM_DUMP_DATA_L1_DATA_CACHE_0x7 secure_world_core2_regs.cmm tasks_sched_stats2.txt tmc-etr.bin
core3_regs.cmm lpm.txt msm_iommu_domain_00.txt secure_world_core3_regs.cmm tasks_sched_stats3.txt tmc_etr.txt
core4_regs.cmm mdpinfo_out.txt msm_iommu_domain_01.txt secure_world_core4_regs.cmm tasks_sched_stats4.txt vmalloc.txt
core6_regs.cmm memory.txt msm_iommu_domain_02.txt secure_world_core6_regs.cmm tasks_sched_stats5.txt
core7_regs.cmm mem_stat.txt msm_iommu_domain_03.txt secure_world_core7_regs.cmm tasks_sched_stats6.txt
cpr3_info.txt MSM_DUMP_DATA_L1_DATA_CACHE_0x0 New Folder spm.txt tasks_sched_stats7.txt
cprinfo.txt MSM_DUMP_DATA_L1_DATA_CACHE_0x1 page_tables.txt t32_config.t32 tasks.txt
五、解题手段
5.1 分析dmesg
上面是解析完成后的文件,有咱们须要的kernel log,也就是文件 dmesg_TZ.txt,打开 dmesg_TZ.txt 看下大体发生了什么事情?
搜索关键字发现
发生了kernel panic!
...
[ 423.400073] Unable to handle kernel NULL pointer dereference at virtual address 00000008
[ 423.400075] [silead finger_interrupt_handler 505]:S IRQ 19 , GPIO 12 state is 0
[ 423.400083] [silead finger_interrupt_handler 506]:state is 0
[ 423.400096] pgd = ffffffc0017eb000
[ 423.400103] [00000008] *pgd=000000008ea0a003, *pud=000000008ea0a003, *pmd=000000008ea0b003, *pte=006000000b000707
[ 423.400124] Internal error: Oops: 96000046 [#1] PREEMPT SMP
[ 423.400132] Modules linked in: wlan(O)
[ 423.400148] CPU: 4 PID: 0 Comm: swapper/4 Tainted: G W O 3.18.31-perf #1
[ 423.400155] Hardware name: Qualcomm Technologies, Inc. MSM8940-PMI8950 MTP (DT)
[ 423.400164] task: ffffffc04eae4980 ti: ffffffc0b28bc000 task.ti: ffffffc0b28bc000
[ 423.400182] PC is at run_timer_softirq+0x4ac/0x5ec
[ 423.400192] LR is at run_timer_softirq+0x324/0x5ec
[ 423.400199] pc : [] lr : [] pstate: 600001c5
[ 423.400204] sp : ffffffc0b28bfb60
...
[ 423.401490] Process swapper/4 (pid: 0, stack limit = 0xffffffc0b28bc058)
[ 423.401496] Call trace:
[ 423.401510] [] run_timer_softirq+0x4ac/0x5ec
[ 423.401523] [] __do_softirq+0x178/0x350
[ 423.401532] [] irq_exit+0x74/0xb0
[ 423.401543] [] __handle_domain_irq+0xb4/0xec
[ 423.401553] [] gic_handle_irq+0x54/0x84
[ 423.401560] Exception stack(0xffffffc0b28bfd40 to 0xffffffc0b28bfe60)
...
[ 423.401671] [] el1_irq+0x68/0xd4
[ 423.401685] [] cpuidle_enter_state+0xd0/0x224
[ 423.401695] [] cpuidle_enter+0x18/0x20
[ 423.401706] [] cpu_startup_entry+0x288/0x384
[ 423.401717] [] secondary_start_kernel+0x108/0x114
[ 423.401728] Code: b90052a0 34000840 f9400321 f9400720 (f9000420)
[ 423.401736] ---[ end trace d0daa1892c14378b ]---
[ 423.401753] Kernel panic - not syncing: Fatal exception in interrupt
[ 423.401774] CPU7: stopping
...
看到异常调用栈,一眼看不出问题所在,那么咱们须要搞清楚CPU发生了什么事情?CPU停下的缘由是什么?
先来看当前64位CPU的状态寄存器组PSTATE:
《ARMv8-A Architecture reference manual-DDI0487A_g_armv8_arm.pdf》

pstate:
600001c5
0x600001c5 ==》1610613189 ==》1100000000000000000000111000101
解析后表明的意思就是禁止debug异常,禁止IRQ,切换异常等级到EL1(Exception Level 1),使用SP_EL1为堆栈指针,EL1说明异常确实是发生在kernel层,禁止IRQ是为了避免让被中断干扰现场.
继续看Oops:
[
423.400124
] Internal error: Oops:
96000046
[#1] PREEMPT SMP
这里Oops后面接的
96000046
是ARM发生异常后上报的错误码,分析kernel panic流程代码(可参考:
http://blog.csdn.net/forever_2015/article/details/53235716
)可知,这个错误码就是
ESR(异常综合寄存器)
寄存器的值,
根据上面PSTATE的解析,ESR寄存器也将是使用ESR_EL1,ESR_EL1寄存器的描述以下:
An
ESR_ELxholds the syndrome information for an exception that is taken to AArch64 state
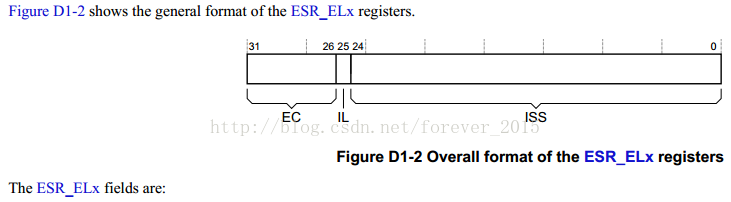
因此,ESR寄存器中的EC值保持
了异常的类型等信息
,咱们能够解析这个值:
0x96000046 ==》2516582470 ==》10010110000000000000000001000110
EC ==》100101
对应以下:
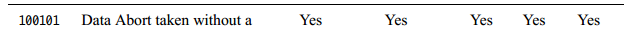
表面kernel层发生数据终止异常,而且没有改变Exception level,也就是没有路由到EL3或者sec-EL1.
==》死机的
缘由就是由于CPU发生了 Data abort异常!那么何时会发生Data abort异常呢?简单来讲就是访问了不可访问的虚拟内存地址,被内存管理单元(MMU)拦截到的异常,好比最多见的空指针异常,内核线程访问非内核虚拟地址空间等(内核虚拟地址空间:
0xFFFF_0000_0000_0000 =>0xFFFF_FFFF_FFFF_FFFF )
如今死机的缘由是知道了,那么接下来咱们最想知道的就是致使死机的代码是在哪里,咱们能够借助add2Line工具解析出调用栈所在函数,文件行号:
$ aarch64-linux-android-addr2line -e vmlinux -f -C ffffffc0000feb98
__list_del
/home/android/project/6901-7.1/LA.UM.5.6/LINUX/android/kernel/msm-3.18/include/linux/list.h:89
$ aarch64-linux-android-addr2line -e vmlinux -f -C ffffffc0000a6864
static_key_count
/home/android/project/6901-7.1/LA.UM.5.6/LINUX/android/kernel/msm-3.18/include/linux/jump_label.h:88
$ aarch64-linux-android-addr2line -e vmlinux -f -C ffffffc0000a6c8c
tick_irq_exit
/home/android/project/6901-7.1/LA.UM.5.6/LINUX/android/kernel/msm-3.18/kernel/softirq.c:363
如此即可以还原调用栈的代码,最终是下面的代码致使的异常:
87 static inline void __list_del(struct list_head * prev, struct list_head * next)
88 {
89 next->prev = prev; ==》猜测那会不会是next->prev指针为NULL所致么?90 prev->next = next;91 }
要确认是否是NULL指针所致,咱们须要来看下对应的汇编指令,打开
Trace32
,切到汇编源码混合显示(也能够经过objdump -S vmlinux > vmlinux.S 查看):
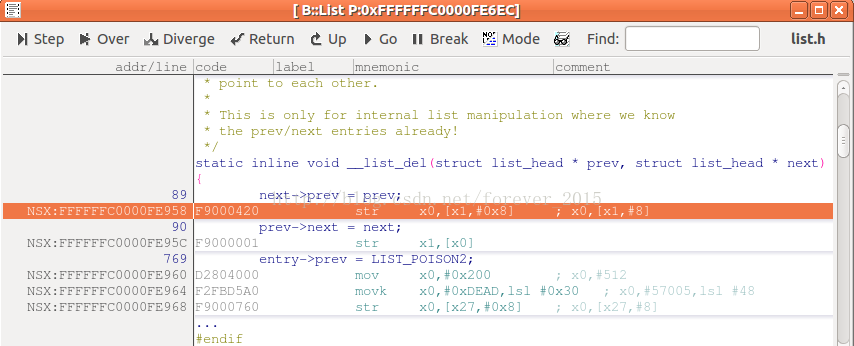
为方便查看,复制贴出来:
static inline void __list_del(struct list_head * prev, struct list_head * next)
|{
89| next->prev = prev;NSX:FFFFFFC0000FE958|F9000420str x0,[x1,#0x8]; x0,[x1,#8]90| prev->next = next;NSX:FFFFFFC0000FE95C|F9000001str x1,[x0]
769| entry->prev = LIST_POISON2;NSX:FFFFFFC0000FE960|D2804000mov x0,#0x200; x0,#512NSX:FFFFFFC0000FE964|F2FBD5A0 movk x0,#0xDEAD,lsl #0x30; x0,#57005,lsl #48NSX:FFFFFFC0000FE968|F9000760str x0,[x27,#0x8]; x0,[x27,#8]|...
简单解释下,
FFFFFFC0000FE968 ==》当前汇编指令的虚拟地址
F9000760 ===》汇编机器码,ARM/ARM64的指令机器码都是32位固定长度
str x0,[x27,
#
0x8
]==》 汇编指令,;后的是注释
根据
AAPCS
(ARM二进制过程调用标准)参数传递规则,ARM64的 v0 - v7 参数直接由 x0 - x7 传递,其余参数由压栈传递,子程序返回结果保存到x0,
那么这里可推导以下:
x0 == prev
x1 == next
指令:str
x0
,[
x1
,
#
0x8
]
x1+0x8 其实就是next+8个字节的偏移,看下
struct
list_head 的结构:
struct list_head {
struct list_head *next, *prev;
};
ARM体系结构中,ARM64一个指针占
8
个字节内存,也就是: [
x1+0x8] == prev
因此这个
str
指令就是对应上面的
next->prev = prev
,那么咱们来看下具体的寄存器
x0,x1
值是多少?
从dmesg log中找到当前发生异常的调用栈(注意,必定要找对应的异常栈的寄存器值),以下:
[ 423.400182] PC is at run_timer_softirq+0x4ac/0x5ec
[ 423.400192] LR is at run_timer_softirq+0x324/0x5ec
[ 423.400199] pc : [] lr : [] pstate: 600001c5
[ 423.400204] sp : ffffffc0b28bfb60
[ 423.400210] x29: ffffffc0b28bfb60 x28: ffffffc0b2619038
[ 423.400219] x27: ffffffc000c9a000 x26: 0000000000000000
[ 423.400228] x25: ffffffc001741120 x24: ffffffc0006e277c
[ 423.400237] x23: ffffffc0b2619000 x22: ffffffc0b28bfbf8
[ 423.400246] x21: ffffffc0b28bc000 x20: ffffffc0013d2000
[ 423.400254] x19: ffffffc0b2618000 x18: 0000007f9588e080
[ 423.400263] x17: 0000007f9a36d4b4 x16: ffffffc0001e4f6c
[ 423.400272] x15: 003b9aca00000000 x14: 0000000000000001
[ 423.400280] x13: 0000000000000000 x12: 0000000000000001
[ 423.400289] x11: 000000000000000f x10: ffffffc000c9c3f4
[ 423.400297] x9 : 0000000000000000 x8 : 0000000000000005
[ 423.400305] x7 : 0000000000000000 x6 : 000000000001451c
[ 423.400314] x5 : ffffffc0b2ae8000 x4 : 00135f1aa15bb200
[ 423.400323] x3 : 0000000000000018 x2 : 0000000000000000
[ 423.400331] x1 : 0000000000000000 x0 : ffffffc0b28bfbf8
上面能够看到,x1+0x8 ==0x0000000000000000+0x8==0x0000000000000008
上面咱们有讲过,ARM64内核的虚拟地址空间范围是0xFFFF_0000_0000_0000 =>0xFFFF_FFFF_FFFF_FFFF
很明显这个值0x0000000000000008不在范围内,它属于用户空间的虚拟地址空间,确定会被MMU拦截掉上报data abort异常,因此此题的真正缘由是程序跑飞访问非法地址所致.
CPU发生异常的缘由已经明确了,但仔细一看,好像也看不出来具体是哪里源码致使的死机,并且这些都是内核自己的代码,没人改动过的,为何会报异常呢?
目前看来从kernel log上的信息没法直接分析出致使问题的具体源代码,从dmesg的这些信息咱们已经知道出问题的是这个prev指针,可是比较难直接抓到致使异常的真凶源码位置。
5.2 Trace32分析
5.2.1 启动模拟器
前面使用ramdump-parse脚本解析完成后,out下有生成这几只文件:
launch_t32.sh t32_config.t32 t32_startup_script.cmm
./launch_t32.sh
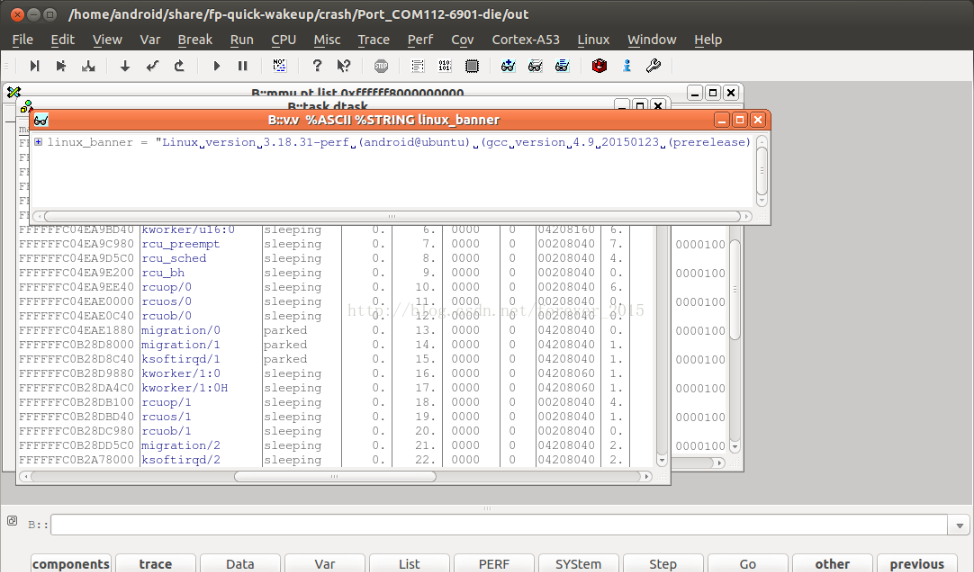
输入v.f 调出 当前的调用栈关系
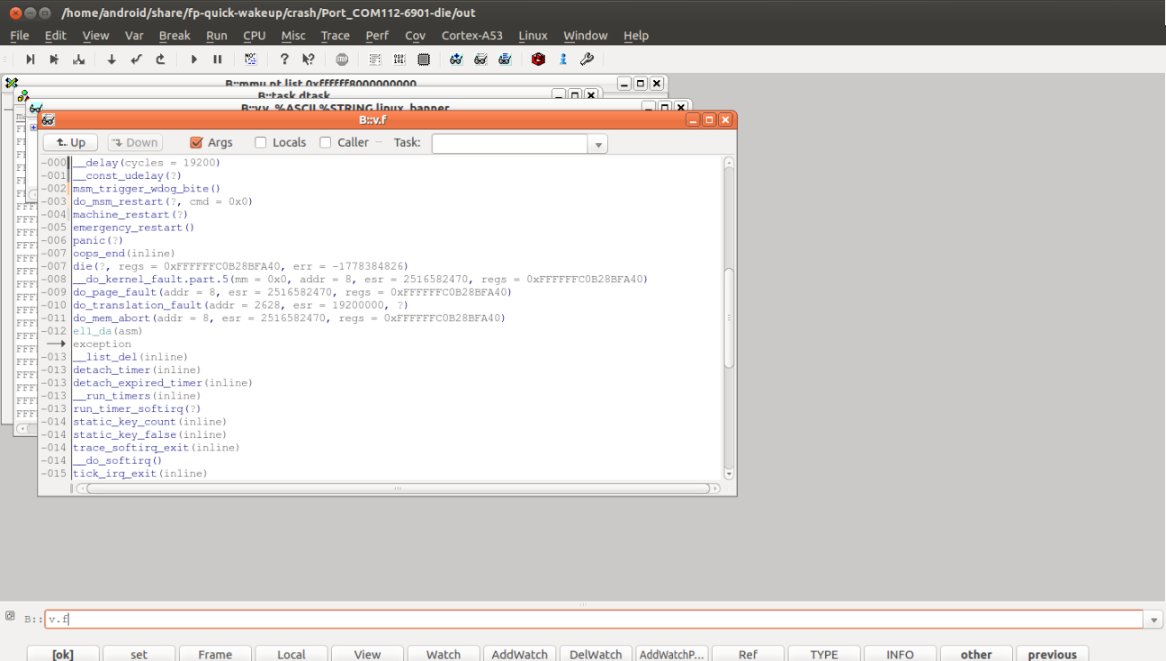
为便于分析传参分析,须要将Locals的框框打钩:
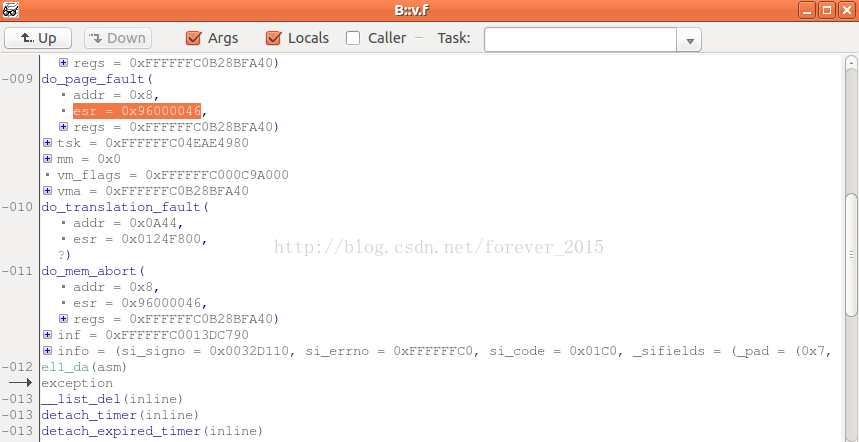
能够看到,异常时候的各类参数都显示出来了,这样就很是有利于咱们debug了,这也是单纯从dmesg没法获得的重要信息!注意inline类型的函数会被编译器默认优化掉,因此inline类型的函数的参数不可见,须要经过读汇编代码,分析寄存器传参推导。
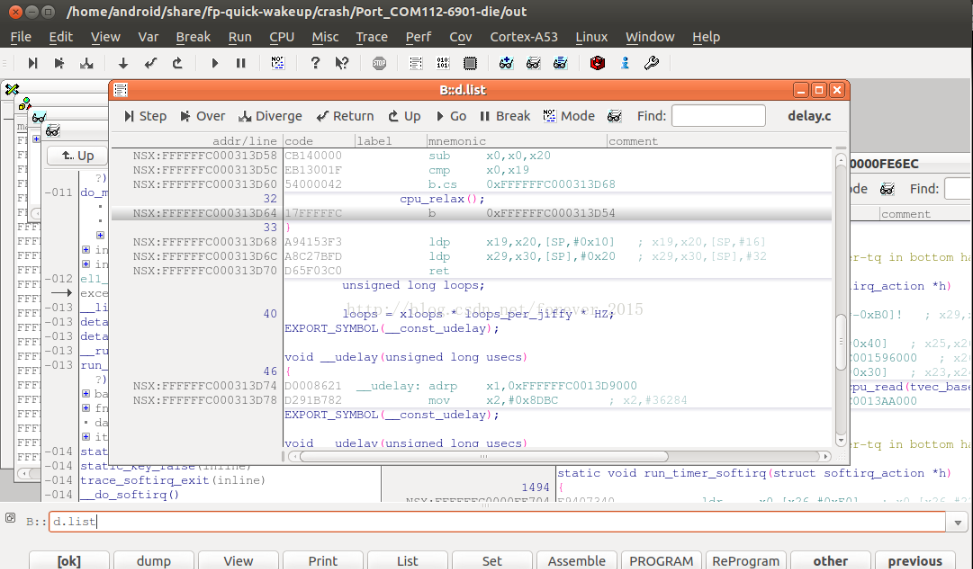
输入d.list 查看PC中止的位置,以下高亮:
5.2.2 分析Call Stack:
为方便查看,把调用栈信息复制出来,以下:
1. ...
-007|die(
| ?,
| regs = 0xFFFFFFC0B28BFA40 -> (
| user_regs = (regs = (0xFFFFFFC0B28BFBF8, 0x0, 0x0, 0x18,0x00135F1AA15BB200, 0xFFFFFFC0B2AE800
| regs = (0xFFFFFFC0B28BFBF8, 0x0, 0x0, 0x18,0x00135F1AA15BB200, 0xFFFFFFC0B2AE8000,0x0001451C
| sp = 0xFFFFFFC0B28BFB60,
| pc = 0xFFFFFFC0000FEB98,
| pstate =0x600001C5,
| orig_x0 = 0xFFFFFFC0B2618000,
| syscallno = 0xFFFFFFC0000FE7D0),
| err =0x96000046)
| flags = 0x01C0
| ret = 0x1
| tsk = 0xFFFFFFC04EAE4980
| die_counter = 0x1
-008|__do_kernel_fault.part.5(
| mm = 0x0,
| addr = 0x8,
| esr =0x96000046,
| regs = 0xFFFFFFC0B28BFA40)
-009|do_page_fault(
| addr = 0x8,
| esr =0x96000046,
| regs = 0xFFFFFFC0B28BFA40)
| tsk = 0xFFFFFFC04EAE4980
| mm = 0x0
| vm_flags = 0xFFFFFFC000C9A000
| vma = 0xFFFFFFC0B28BFA40
-010|do_translation_fault(
| addr = 0x0A44,
| esr =0x0124F800,
| ?)
-011|do_mem_abort(
| addr = 0x8,
| esr =0x96000046,
| regs = 0xFFFFFFC0B28BFA40)
| inf = 0xFFFFFFC0013DC790 -> (
| fn = 0xFFFFFFC000099A74,
| sig = 0x0B,
| code =0x00030001,
| name = 0xFFFFFFC0010DF250 -> 0x6C)
| info = (
| si_signo =0x0032D110,
| si_errno = 0xFFFFFFC0,
| si_code = 0x01C0,
| _sifields = (_pad = (0x7, 0x0, 0xB28BF9E0, 0xFFFFFFC0,0x000A6D78, 0xFFFFFFC0, 0xB28BF9F0, 0xFFF
-012|el1_da(asm)
-->|exception
-013|__list_del(inline)
-013|detach_timer(inline)
-013|detach_expired_timer(inline)
-013|__run_timers(inline)
-013|run_timer_softirq(
| ?)
| base = 0xFFFFFFC0B2618000-> (
| lock = (rlock = (raw_lock = (owner = 0x6FCD, next = 0x6FCE))),
| running_timer =0xFFFFFFC001741120-> (
| entry = (next = 0xFFFFFFC0B27BC9B8, prev = 0xFFFFFFC0B27BC9B8),
| expires =0x0000000100003098,
| base = 0xFFFFFFC0B27BC000,
| function =0xFFFFFFC0006E277C-> ,
| data = 0x0,
| slack = 0xFFFFFFFF,
| start_pid = 0xFFFFFFFF,
| start_site = 0x0,
| start_comm = (0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0))
| timer_jiffies =0x0000000100003035,
| next_timer =0x0000000100003034,
| active_timers = 0x7,
| all_timers = 0x7,
| cpu_=_0x4,
| tv1 = (vec = ((next = 0xFFFFFFC0B2618038, prev = 0xFFFFFFC0B2618038), (next = 0xFFFFFFC0B2618048| tv2 = (vec = ((next = 0xFFFFFFC0B2619038, prev = 0xFFFFFFC0B2619038), (next = 0xFFFFFFC0B2619048| tv3 = (vec = ((next = 0xFFFFFFC0B2619438, prev = 0xFFFFFFC0B2619438), (next = 0xFFFFFFC0B2619448| tv4 = (vec = ((next = 0xFFFFFFC0B2619838, prev = 0xFFFFFFC0B2619838), (next = 0xFFFFFFC0B2619848| tv5 = (vec = ((next = 0xFFFFFFC0B2619C38, prev = 0xFFFFFFC0B2619C38), (next = 0xFFFFFFC0B2619C48| fn = 0xFFFFFFC0006E277C ->
| data = 0x0
| it_func_ptr = 0x0
...
看到这里,咱们能够猜测是否是run_timer_softirq的参数出现了问题致使后面发生的一系列异常?能够从这个方向开始思考,咱们先来看下这个函数的实现:
static void run_timer_softirq(struct softirq_action *h)
{
struct tvec_base *base= __this_cpu_read(tvec_bases);hrtimer_run_pending();__run_deferrable_timers();if (time_after_eq(jiffies, base->timer_jiffies))
__run_timers(base);}
咱们看到这个函数最重要的参数变量就是这个base,传入的*h没有使用,继续来看下*base的结构tvec_base :
struct tvec_base {
spinlock_t lock;struct timer_list *running_timer;unsigned long timer_jiffies;unsigned long next_timer;unsigned long active_timers;unsigned long all_timers;intcpu; // 跟踪所在的CPU是哪一个核,这里是CPU 4struct tvec_root tv1;struct tvec tv2;struct tvec tv3;struct tvec tv4;struct tvec tv5;} ____cacheline_aligned;
这里就看到,*base的结构里面有个 struct timer_list * 的结构,咱们继续看它的结构是怎么样的:
struct timer_list {
/*
* All fields that change during normal runtime grouped to the
* same cacheline
*/
struct list_headentry;unsigned long expires;struct tvec_base *base;void (*function)(unsigned long);unsigned long data;int slack;...
这个就是内核里面实现定时器标准的数据结构了,其中function这个指针就是time out后执行的callback,并且异常发生在CPU 4,
了解这些数据结构背景后就能够借助T32工具来分析了,既然这个定时器发生了异常,那么咱们最想知道的是这是哪个定时器?
它在源码中的定义是在哪一个文件哪一个行号?这些均可以借助Trace32工具来获取.
首先咱们查看
*
running_timer
的数据内容:
工具栏 调出:view -> Watch,输入:
(
struct
timer_list *)
0xffffffc001741120
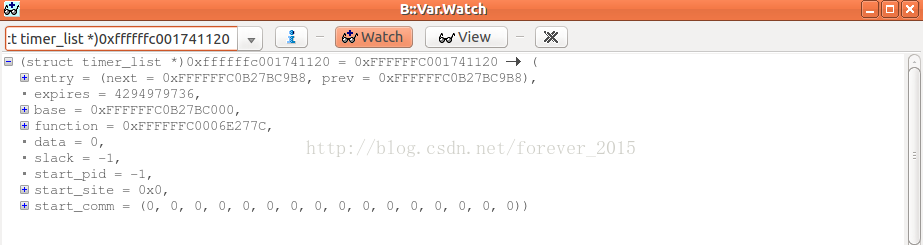
复制出来就是这样:
(struct timer_list *)0xffffffc001741120 = 0xFFFFFFC001741120 -> (
entry = (next = 0xFFFFFFC0B27BC9B8, prev = 0xFFFFFFC0B27BC9B8),
expires = 4294979736,
base = 0xFFFFFFC0B27BC000,
function = 0xFFFFFFC0006E277C,
data = 0,
slack = -1,
start_pid = -1,
start_site = 0x0,
start_comm = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0))
这个就是发生异常的那个timer的数据结构实例,咱们最但愿的就是但愿能够经过这里的数据信息找到它在源码的位置,而后进一步分析它,使用Trace32的
dump
分析功能就能够作到这点。
菜单栏调出:
view -》dump
输入地址 0xffffffc001741120 而后点OK
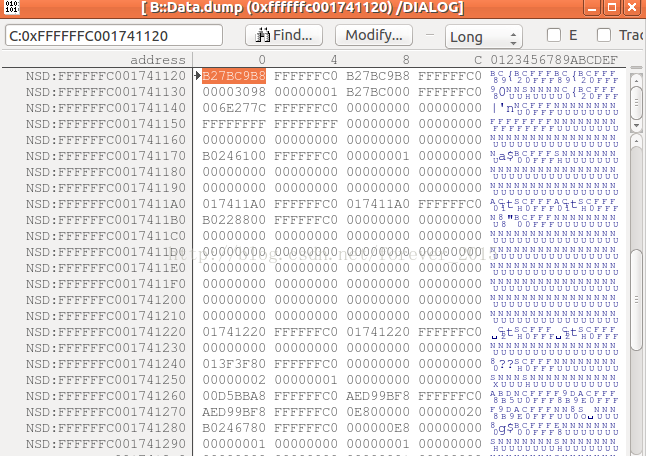
右击高亮,选择view info:
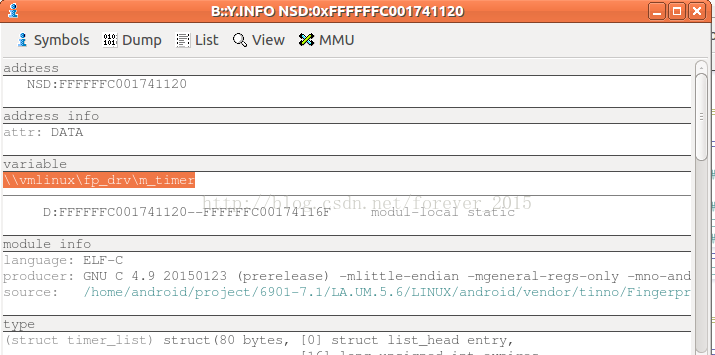
同理,还能够看function的位置(
0xFFFFFFC0006E277C
):
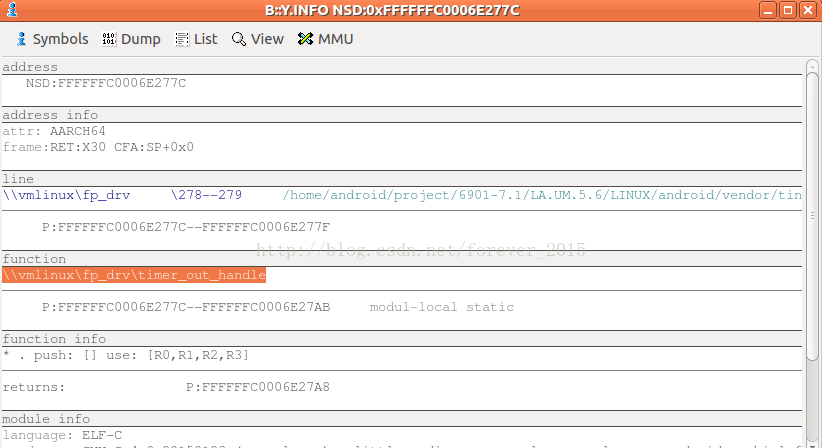
上面所示,出异常的timer实例就是:fp_drv/m_timer, callback = timer_out_handle,
源码位置也给出来了,那么就能够着手修复问题了。
六、 同源不一样表现
6.1 dmesg分析
致使
Kernel panic的源码改动是同一处,可是死机后的表现却可能大不同,像这个问题当时出现的时候有抓到两份ramdump,解开后却发现表现不同(极可能每次出现死机都在不同的地方),逆向推导过程老是须要耐心细心分析,加上必定的运气成分,那么就能够比较顺利定位问题点,简单介绍下:
解析ramdump后查看的dmesg是这样的:
[256.595276] list_add corruption. prev->next should be next (ffffffc0ab1d4178), but was ffffffc0aba4c628. (prev=ffffffc001b77da8).
[256.595282] Modules linked in: wlan(O)
[256.595299] CPU: 5 PID: 6210 Comm: mdss_fb0 Tainted: G W O 3.18.31 #1
[256.595305] Hardware name: Qualcomm Technologies, Inc. MSM8940-PMI8950 MTP (DT)
[256.595311] Call trace:
[256.595324] [] dump_backtrace+0x0/0x270
[256.595334] [] show_stack+0x14/0x1c
[256.595345] [] dump_stack+0x80/0xa4
[256.595356] [] warn_slowpath_common+0x8c/0xb0
[256.595366] [] warn_slowpath_fmt+0x60/0x80[256.595374] [] __list_add+0x74/0xf0
[256.595384] [] __internal_add_timer+0xb4/0xbc
[256.595392] [] internal_add_timer+0x34/0x90[256.595404] [] schedule_timeout+0x1f0/0x278
[256.595414] [] mdss_mdp_cmd_wait4pingpong+0x12c/0x534
[256.595424] [] mdss_mdp_display_wait4pingpong+0xd8/0x404[256.595432] [] mdss_mdp_display_commit+0x890/0x1128
[256.595443] [] mdss_mdp_overlay_kickoff+0x9ec/0x15f4
[256.595453] [] __mdss_fb_display_thread+0x278/0x4c4
[256.595462] [] kthread+0xf0/0xf8
[256.595468] ---[ end trace 02fd337171f1bd82 ]---
[256.595498] ------------[ cut here ]------------
[256.595506]kernel BUGat /home/android/work/prj/6901-7.1/LA.UM.5.6/LINUX/android/kernel/msm-3.18/lib/list_debug.c:40!
[256.595513] Internal error: Oops - BUG: 0 [#1] PREEMPT SMP
[256.595519] Modules linked in: wlan(O)
[256.595533] CPU: 5 PID: 6210 Comm: mdss_fb0 Tainted: G W O 3.18.31 #1
[256.595538] Hardware name: Qualcomm Technologies, Inc. MSM8940-PMI8950 MTP (DT)
[256.595545] task: ffffffc02f5e6e00ti: ffffffc002bdc000 task.ti: ffffffc002bdc000
[256.595553] PC is at __list_add+0xcc/0xf0
[256.595560] LR is at __list_add+0x74/0xf0
[256.595567] pc : [] lr : [] pstate:200001c5
看到红色部分的kernel BUG 咱们就知道,这个属于内核主动上报异常的行为,咱们看看list_debug.c:40 这里有什么?
以下双链表add实现的红色部分代码,明显就是触发了BUG_ON(x)的条件致使!
void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next)
{
WARN(next->prev != prev,
"list_add corruption. next->prev should be "
"prev (%p), but was %p. (next=%p).\n",
prev, next->prev, next);WARN(prev->next != next,
"list_add corruption. prev->next should be "
"next (%p), but was %p. (prev=%p).\n",
next, prev->next, prev);WARN(new == prev || new == next,
"list_add double add: new=%p, prev=%p, next=%p.\n",
new, prev, next);BUG_ON((prev->next != next || next->prev != prev ||
new == prev || new == next) && PANIC_CORRUPTION);next->prev = new;new->next = next;new->prev = prev;prev->next = new;}
这个内核双链表标准的插入实现,这个BUG_ON条件知足被触发了Panic所致,表示参数传的有错误。继续看log发现:
[ 256.595299] CPU: 5 PID: 6210 Comm: mdss_fb0 Tainted: G W O 3.18.31 #1
异常发生在CPU5这个核,进程是
mdss_fb0,这个是属于显示相关的进程,通常咱们是动不到的,初步判断是别的地方改动埋的雷致使mdss_fb0整个进程在执行的时候炸了的过程。
那么咱们要作的就是如何从这个爆炸现场到推出埋雷的地方。
6.2 Trace32分析
打开Trace32,输入 v.f 回车,将call frame内容贴出来:
-000|ipi_cpu_stop(inline)
-000|handle_IPI(ipinr = 3, regs = 0xFFFFFFC0A3BF36E0)
-001|gic_handle_irq(regs = 0xFFFFFFC0A3BF36E0)
-002|el1_irq(asm)
-->|exception
-003|debug_check_no_obj_freed(address = 0xFFFFFFC028805C00, size = 128)
-004|current_thread_info(inline)
-004|preempt_count(inline)
-004|should_resched(inline)
-004|slab_free(inline)
-004|kfree(x = 0xFFFFFFC028805C00)
-005|ext4_ext_map_blocks(handle = 0x0, inode = 0xFFFFFFC0A3FA8D50, map = 0xFFFFFFC0A3BF3A80, ?)
-006|ext4_map_blocks(handle = 0x0, inode = 0x80, map = 0xFFFFFFC0A3BF3A80, flags = 12)
-007|ext4_get_block(inode = 0xFFFFFFC0A3FA8D50, ?, bh = 0xFFFFFFC0A3BF3AD0, flags = 0)
-008|ext4_get_block(?, ?, ?, ?)
-009|generic_block_bmap(?, ?, ?)
-010|ext4_bmap(mapping = 0xFFFFFFC0A3FA8ED0, block = 12712)
-011|bmap(?, block = 128)
-012|jbd2_journal_bmap(journal = 0xFFFFFFC0A41F3900, ?, retp = 0xFFFFFFC0A3BF3CC0)
-013|jbd2_journal_next_log_block(journal = 0xFFFFFFC0A41F3900, retp = 0xFFFFFFC0A3BF3CC0)
-014|jbd2_journal_commit_transaction(journal = 0xFFFFFFC0A41F3900)
-015|kjournald2(arg = 0xFFFFFFC0A41F3900)
-016|kthread(_create = 0xFFFFFFC0A41E4400)
-017|ret_from_fork(asm)
---|end of frame
这个call frame看上去还挺正常的,属于正常的系统异常切换操做?怎么发现跟dmesg里面看到的call statck不对???
咱们来看下加载脚本:t32_startup_script.cmm
title "/home/android/share/fp-quick-wakeup/crash/Port_COM29-0813/out"
sys.cpu CORTEXA53
sys.up
data.load.binary /home/android/share/fp-quick-wakeup/crash/Port_COM29-0813/OCIMEM.BIN0x8600000data.load.binary /home/android/share/fp-quick-wakeup/crash/Port_COM29-0813/DDRCS0.BIN0x40000000data.load.binary /home/android/share/fp-quick-wakeup/crash/Port_COM29-0813/DDRCS1.BIN0x80000000Register.SetNS1
Data.Set SPR:0x30201%Quad0x41c22000Data.Set SPR:0x30202%Quad0x00000032B5193519Data.Set SPR:0x30A20 %Quad0x000000FF440C0400Data.Set SPR:0x30A30 %Quad0x0000000000000000Data.Set SPR:0x30100%Quad0x0000000004C5D93D
Register.Set CPSR 0x3C5
MMU.Delete
MMU.SCAN PT 0xFFFFFF8000000000--0xFFFFFFFFFFFFFFFF
mmu.on
mmu.pt.list 0xffffff8000000000data.load.elf /home/android/share/fp-quick-wakeup/crash/Port_COM29-0813/vmlinux /nocode
task.config /opt/t32/demo/arm64/kernel/linux/linux-3.x/linux3.t32
menu.reprogram /opt/t32/demo/arm64/kernel/linux/linux-3.x/linux.men
task.dtask
v.v %ASCII %STRING linux_banner
do /home/android/share/fp-quick-wakeup/crash/Port_COM29-0813/out/core0_regs.cmm
上面能够看到脚本里面配置trace32默认加载的是
CPU 0的上下文,而咱们从dmesg看到的panic异常是发生在CPU 5,须要手动切换到CPU 5的上下文:
执行:do core1_regs.cmm
(这里有必要须要说明一下,按通常理解应该执行do core5_xx, 可是我发现这样还不对,只能一个个试验了,发现恰好是core1的这个,暂时不知道具体缘由)
-000|arch_counter_get_cntvct_cp15()
-001|arch_counter_get_cntvct()
-002|__delay(cycles = 19200)
-003|__const_udelay(?)
-004|msm_trigger_wdog_bite()
-005|do_msm_restart(?, cmd = 0x0)
-006|machine_restart(?)
-007|emergency_restart()
-008|panic(?)
-009|oops_end(inline)
-009|die(?, regs = 0xFFFFFFC002BDF870, err = 0)
-010|arm64_notify_die(?, ?, ?, ?)
-011|do_undefinstr(regs = 0xFFFFFFC002BDF870) --- 发生未定义指令异常 BUG()
-012|__list_add(new = 0xFFFFFFC002BDF990, prev = 0xFFFFFFC001B77DA8, next = 0xFFFFFFC0AB1D4178)
-013|__internal_add_timer(?, ?)
-014|tbase_get_deferrable(inline)
-014|internal_add_timer(base = 0xFFFFFFC0AB1D4000, timer =0x0124F800)
-015|spin_unlock_irqrestore(inline)
-015|__mod_timer(inline)
-015|schedule_timeout(?)
-016|mdss_mdp_cmd_wait4pingpong(ctl = 0xFFFFFFC0A791A318, ?)
-017|mdss_mdp_display_wait4pingpong(ctl = 0xFFFFFFC0A791A318, use_lock = FALSE)
-018|mdss_mdp_display_commit(ctl = 0xFFFFFFC0A791A318, ?, commit_cb = 0xFFFFFFC002BDFD38)
-019|mdss_mdp_overlay_kickoff(mfd = 0xFFFFFFC0A7B08360, ?)
-020|__mdss_fb_perform_commit(inline)
-020|__mdss_fb_display_thread(data = 0xFFFFFFC0A7B08360)
-021|kthread(_create = 0xFFFFFFC05ABCE200)
-022|ret_from_fork(asm)
---|end of frame
勾选Local、Caller 分析:
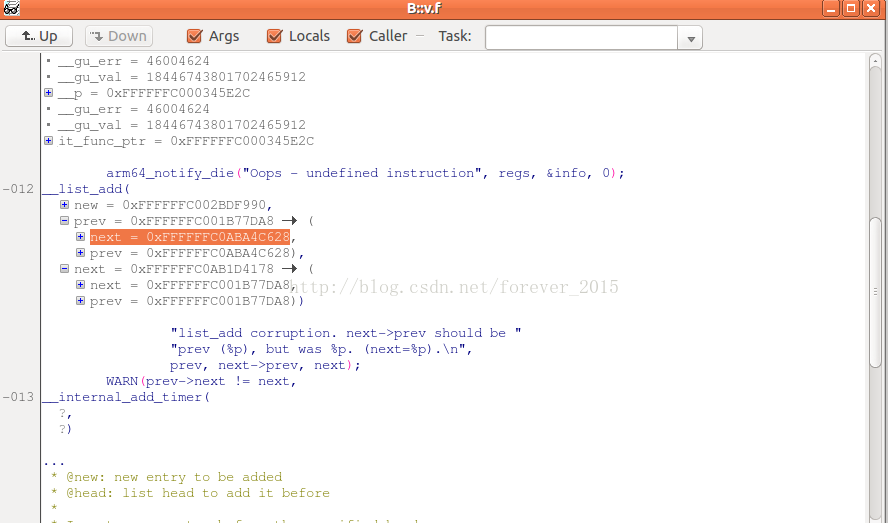
双链表的结构有
前驱next指针
和
后继prev指针
,因此prev->next == next && next->prev == prev,这个条件是必现要成立的,咱们来看这里的状况:
-012|__list_add(
| new = 0xFFFFFFC002BDF990 -> (
| next = 0xFFFFFFC002BDF9C0,
| prev = 0xFFFFFFC00010356C),
| prev =0xFFFFFFC001B77DA8-> (
| next =0xFFFFFFC0ABA4C628,
| prev = 0xFFFFFFC0ABA4C628),
| next =0xFFFFFFC0AB1D4178-> (
| next = 0xFFFFFFC001B77DA8,
| prev = 0xFFFFFFC001B77DA8))
很显然,prev == next->prev, 可是 prev->netxt != next, 因此致使了上面的BUG_ON(1)异常!.
因此出问题的就是这个prev,咱们来看看这个prev具体是什么内容?
前面看过timer的结构知道,这个prev其实就是指向一个struct timer_list *的指针,咱们看下这个结构的内容是什么,
调出 view -> Watch 窗口:
(struct timer_list *)0xFFFFFFC001B77DA8 = 0xFFFFFFC001B77DA8 -> (
entry = (next = 0xFFFFFFC0ABA4C628, prev = 0xFFFFFFC0ABA4C628),
expires = 4294963038,
base = 0xFFFFFFC0ABA4C000,
function_=_0xFFFFFFC00077D4A8,
data = 0,
slack = -1,
start_pid = -1,
start_site = 0x0,
start_comm = (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0))
同上:view -> dump :0xFFFFFFC00077D4A8
address
NSD:FFFFFFC00077D4A8address_info
attr: AARCH64
frame:RET:X30 CFA:SP+0x0
line
\\vmlinux\fp_drv\277--278/home/android/work/prj/6901-7.1/LA.UM.5.6/LINUX/android/vendor/ti
----------------------------------------------------------------------------------------------------
P:FFFFFFC00077D4A8--FFFFFFC00077D4AB
function
\\vmlinux\fp_drv\timer_out_handle...
如此,很清晰的显示了出问题的源码位置,到这里,异常定位分析就已经基本完成了,完成了“追根溯源”,
剩下的就是去分析代码出解决方案了。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!