C++分布式项目学习笔记
文章目录
- Introduction
- 理论基础
- 开发
- 环境
- 传输协议
- 发布服务
- zookeeper
- 快速掌握前后端分布式
- 1. 掌握计算机网络知识
- 网络模型
- 系统内核调用(read and soon on ), 内存映射(mmap), 零拷贝(sendfile)等问题
- redis , nginx , kafka , 秒杀系统, 同步异步
- 集群, 分布式, cap , zookeeper , paxos.
- 总结
- ClusterChatSever
- How to use it ?
- 1 背景
- 2 任务
- 3 行动
- 1. 环境配置
- 2. 整体实现思路
- 3 框架
- 3. 技术栈
- 4. 具体步骤
- 4 结果
- 5 问题记录
- 编程问题
- 设计问题
- 微服务聊天服务器
- 基础知识
- 1. probuff
- 2. zookeeper
- 3. redis
- 4. nginx
- 5. rpc
- 整体架构
- 个人的不足之处
- 常见问题
- 1. 介绍一下这个项目
- 2. 项目中觉得可说的小细节
- 你自己在项目中负责的任务
- 这个项目目前的缺点是啥?
- 客户端断网会怎么样?
- 说一下数据表的操作和设计?
- probuf为什么比较高效?
- rpc框架的底层原理
- redis,zookeeper,nginx分别的工作
- 日志模块怎么设计的
- 项目中遇到了哪些困难?
- 参考文献
- 版本记录
- 招聘
- C、C++语言
- 操作系统
- 计算机网络
- 数据库mysql , redis
- 数据结构
- 场景题和项目
Introduction
由于学习的需要, 需要学一下RPC和ZK怎么使用, 这里笔记一下石磊老师课程。
理论基础
- 什么时候要用分布式?
-
- 首先我们将一整套应用拆分成多种网络分布式服务, 方便部署和运维(公司的代码一般是很大的, 单机服务任意的修改都会重新部署和编译), 分布式可以解耦代码。
-
- 功能分为CPU密集和io密集,分布式可以让CPU密集型的模块部署到CPU较好的硬件上, 有效的利用资源。
-
- 一些访问量不高的服务根本不需要高并发, 使用普通集群会重复部署多次, 非常浪费。
-
- 分布式代码起码也得过万行才会考虑吧,不然设计的工作时间都超过了你写代码的时间。 因为分布式的解耦工作是很麻烦的(生活中很多东西都是难以分类和解耦的)。 一个小的项目没有那么多访问量而且代码也很好理解, 直接普通集群就行了。盲目上rpc服务就是夜空皓龙。
-
- 分布式的一些问题: 模块难以划分,各个模块可能有很多共同需要的代码, 难以拆分代码到一个服务中。 因此会产生冗余。 还是难以解耦的问题。
- 什么是分布式?
-
- 分布式就是一个应用服务器的功能全部拆分成服务, 多个服务部署在不同服务器上, 共同构成一个聊天系统。 但是这样的话一个服务可以部署多次, 需求量大的服务可以多部署一些。
-
- 分布式主要去解决的就是跨域通信和一致性。
- RPC是什么,通信原理?
-
- 各个分布式节点之间的通信或者说一个服务调用另外几个服务。 他们共同作用才能完成业务。 如果发现服务通过zookeeper。
-
- 原理参照:
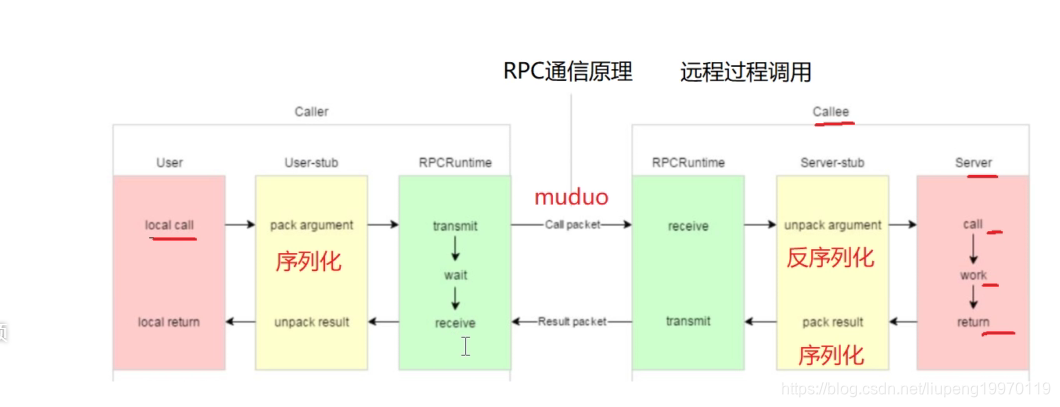
- 原理参照:
开发
环境
- 需要什么开发环境?
-
- vscode + cmake + muduo + probuf + 远程linux服务器 + 项目管理
传输协议
-
传输协议使用probuff ,它是一种二进制存储的协议, 因此存储小, 速度更快。 它是一个开源的跨语言的项目。我们可以使用一个probuf工具将我们定义的数据转换成对应语言的代码。 在项目中导入使用。 这里面生成的代码还是非常复杂的, 有精力还是需要学习一下。
-
如何使用probuf呢?
-
- 一般我们使用protbuf自定义的数据类型写出协议,然后我们使用命令生成对应语言的代码, 主要是将定义的变量和方法封装成类。 我们在自己语言程序里面操作这个对象, 进行序列化或者反序列等操作。 此外里面封装了很多种方法和函数。
-
-
RPC中如何使用probuf?
-
- 需要注意probuf为rpc方法提供了自己封装, 只是为了方便, 而不是代表二者有直接关系。 怎么定义呢? 一般是定义一个server ,然后里面定义一个函数,接收和返回使用message。 message使用请求类封装成员设置方法, 发送类封装读写数据的方法。 servise 封装函数和请求过来的数据。
- RPC服务 在probuf中分为消费和提供者。 消费者类中函数都是封装到channel里面, 最终实现请求和访问。 还需要注意probuf需要定义好, 服务和消费者都需要知道具体格式。
发布服务
- 首先要注意我们要开发框架的应用需要注意, 框架本身将我们实际的业务快速封装成rpc 服务, 这里一定要注意。 框架的写代码思路和服务的代码思路是不一样的。 这一点要理解。
- 我们需要框架将本地一个方法注册成远程服务。 而不是本地调用。 如何修改呢? 一般先定义好自己的probuf 转成对应语言的代码。 包含数据类和服务类。 我们需要将我们的方法重写到服务提供类中对应的函数中。
- 在写好的的框架高度函数中,服务方从请求中拿到数据, 执行本地的业务(本地函数), 执行回调返回过去。这是框架封装业务的流程。 理解业务如何使用RPC, 我们才能知道如何去写好框架,帮助业务快速的完成任务。
- 框架需要提供什么呢 : 初始化自己, 将服务类发布到自己的muduo库中, 进行数据监听。 至此我们知道框架需要做什么了, 下面我们开始写框架。做出上述的功能。
- 首先我们需要一个初始化类, 还有一个服务操作类。
- 初始化类需要从配置文件中读取一些信息 , 服务的ip, 服务的端口, zookeeper的地址和端口。 因此我们设置一个额外的静态类去读取(提供读取和查询函数)。
- 开发provider类 : 设置成基于muduo库的网络类。 具体怎么做呢? 我们封装一个类, 然后在类中使用muduo库, 库中通过muduo绑定多种事件(类成员函数绑定)。启动后可以接收事件。
- 添加完了网络功能之后, 我们去将我们的服务发布出去。 在发布的前期首先我们需要让我们发布的函数封装到muduo的连接事件回调中。 这个怎么做呢? 首先服务prc的request类中有很多函数和变量可以拿到, 我们将这个类中的方法绑定到muduo的连接事件表中, key设置成服务的name。这里只是先注册,还没用哦。
- 我们在muduo的读写事件中将数据进行解析,拿到probuf类型的数据(这里会有一个发送和响应之间的数据协议, 就是指发送是以什么形式去发送, 接收以什么形式去接收, 这些需要probuf再定义一下, 这样避免干扰字符), 至此我们拿到了service对象和函数名和参数等。我们从之前注册的服务列表中找, 找到了的话获取service对象和method方法。 然后我们根据参数信息拿到probuf请求和响应对象. 对于根据传入方法拿到新的请求对象, 我们进行调用执行login本地业务并拿到了返回值。 然后我们在probuf的类中绑定一个回调函数, 用于执行响应对象发送的任务。发送任务中堆数据序列化, 然后将数据通过socket send发送给调用方。至此发布服务结束了。
- 我们服务提供类定义之后, 调用方使用probuf服务类的另外一个生成类, 去将我们想要请求的方法传入stub类中进行调用。拿到响应类的数据。 那么我们的stub如何初始化呢: 需要在里面放一个RpcChannel去处理网络接收等东西。RpcChannel(框架中的类)中CallMethod方法用来封装请求并发送。 CallMethod中如何发送呢? 先将数据封装成简单的probuf,然后封装起来用简单的tcp服务去发送过去,然后一直等待接收数据后进行反序列化。至此我们通信算完成。
- 我们添加一个注册例子再用一下rpc服务用来回顾一下整个工作。 首先在probuf定义方法的注册和响应数据类型,并定义一个注册服务, 然后生成c++代码。 我们定义的service类(继承probuf中的prc类)中添加本地服务, 然后将本地服务放到prc类中虚继承来的同款服务进行调用。 这个同款类服务函数里面传入过来的都是用probuf里面的各个类,实现将probuf的request接收的数据解析出来调用本地函数的结果。 发布者怎么使用这个service类?自己先初始化rpc框架,然后使用框架的provider类(底层用muduo库), 并将我们新定义的service类传入到这个provider类中,剩下muduo底层部分参照7、8、9。 然后将probuf中的stub类(里面也有各种定义好的本地函数抽象化)作为数据的发布者,将在这里设置好的request 和respons传入stub类中定义好的同等抽象方法方法中。 一次请求响应之后我们打印出来结果。
- rpc/controller 用来实现错误标志位设置, 遇到不行的地方及时退出。 让每一次rpc服务都做判断, 有问题及时退出。
- 如何添加日志: 使用一个单例日志模块, 里面维护一个线程安全的队列,多个muduo工作线程将日志放到队列中, 使用异步线程去执行任务队列里面的内容, 写入到文件中。中间用锁和条件变量进行控制, 保持通信。
zookeeper
- 我们需要配置服务中心去管理所有服务, 这样我们调用方就不需要rpc服务地址, 只需要知道一个zookeeper, zookeeper还支持分布式锁(互斥锁等在分布式机器中没有用, 因为不在同一个机器中)。 zk 本身使用java开发的, 我们启动服务之后, 使用客户端去链接进去然后进行节点数据的查询。我们可以将rpc服务ip地址和端口注册在zk的节点中, 这样访问zk提供的动态数据查询接口可以拿到正常工作的服务节点信息。绑定到zk中的节点需要定时发送心跳包, 保持连接。
- 如何使用呢? 我们编译客户端生成c++的zk客户端开发包。 但是c++的官方客户端接口有些缺点, 一个是不自动设置心跳包、需要自动配置wathch。 需要注意watch机制就是发布订阅者模式, 每一次zk服务端添加了自己订阅的主题, 都将数据添加到订阅者(也就是客户端这里)。
- 我们在c++代码中封装一个zk类. 里面有启动函数(里面有zookeeper init 函数异步调用, 通过信号量进行控制)。 creat函数(判断我们想要创建的节点是否存在, 如果不存在我们调用zookeeper的创建接口) ,get函数。 然后这个封装类在rpc发布者中进行注册, 在调用者中进行查询zookeeper里面的服务接口, 拿到信息之后进行真实的连接。
快速掌握前后端分布式
1. 掌握计算机网络知识
- 首先安装tcpdump , 然后监听网卡的端口, 然后我们使用curl模拟发送数据。 查看http应用层和tcp的数据。(这个很重要)
- tcp 是三次握手, 面向链接(三次握手(dos攻击,黑名单 ),四次挥手())的且可靠(ack确认 )。
- 一个端口可以绑定多个socket.
- 网关和掩码是ip层的。 网关是啥呢? 是所有主机和不同网段通信的ip。 参照https://zhuanlan.zhihu.com/p/165142303。 也就是你家里所有网络都要上网的路由下一跳(数据包里面放的不是下一跳的IP地址,而是mac地址, 数据放到数据链路层的话通过arp查找对应的下一跳IP, 不停的换。 因此说网络请求过程中mac地址通过arp不停的更换。 )。 统一局域网之间ping由于可以在路由表中找到那种不经过网关的。
网络模型
- 操作系统启动过程, kernel和用户应用空间。 用户应用空间想要调用kernel需要进入系统调用。
- socket就是系统调用, 进入内核去绑定网卡硬件, 设置缓存区。 需要掌握socket函数怎么调用的, 操作系统怎么相应。
- 为了解决阻塞问题,我们使用多线程模型去拿到链接的fd去管理阻塞fd的read . 随后linux内核发明了非阻塞功能(noblock), 进入了非阻塞时代, 但是如果有5000个调用, 我们需要遍历5000次, 这5000次都要从用户态进入内核态 , 十分低效。 因此内核再次升级,提供select接口,可以在内核绑定多个fd , 内核虽然也会遍历, 但是不用read, 只是对fd状态进行判断。 select返回到达数据的fd, 程序只对到达数据的fd进行调用。 这还是同步的, 异步就是read 不是自己做, 自己调用之后就进行其他的, 它完成之后进行通知。select 每次循环一次都要将5000多个fd (举例的)传入进去, 这多个用户态到内核台的调用性能还是不行的, 而且内核遍历也还是性能不够的。 epoll则可以解决这些问题,首先epoll_ctl 会将fd一次性放到内核态, 然后这些有相应的fd会触发中断, 被回调函数被动的放入一个内核共享空间(注意这就不需要遍历了,是fd自己进去)。 epoll_wait 直接访问这个内核共享空间。 红黑树管理所有的链接, 有相应的fd会构成一个双向链表。 内核的共享空间和用户态有的linux版本内核是通过mmap实现了消耗更低的拷贝, 但是好像后面取消了, 直接拷贝到用户态, 这样可以避免多线程问题。
系统内核调用(read and soon on ), 内存映射(mmap), 零拷贝(sendfile)等问题
- 实际上的每个进程都放在一个物理内存上,但是因为虚拟地址的原因, 让每个用户以为自己占用了除了内核态的所有。
- 调用read函数读取文件, 需要进入内核态。可以使用mmap去避免一次拷贝。 kafka使用了这个机制做消息持久化, 它开辟了一个磁盘的mmap , 数据直接从用户态映射到磁盘。
- 0拷贝 是通过sendfile实现的, 就是说内核直接打开这个mmap 或者说底层磁盘, 将数据直接通过内核态发送给客户端,做到0 拷贝。
redis , nginx , kafka , 秒杀系统, 同步异步
- 用户秒杀系统设计中会考虑很多问题。 首先在前段设置动静分离, 让静态数据直接放在cdn里面(也就是运营商服务器), 拿到静态的数据, 需要异步的动态访问数据。 这时候可以通过nginx+redis+lua脚本(存储请求的ip) 结合过滤无效的、 恶意的请求。 这样得到了用户的抢购请求,抢购请求被多个服务去执行, 同时并行对数据库操作可能会造成超卖。 这时候需要对数据库加锁加事务, 但是这样就成了串行化请求, 十分低效。 这时候我们使用redis(是单线程,所以不会存在多线程互斥问题, 会很快)。 redis可以将服务发送的商品减1的请求快速执行, 更新数据库。 当商品没了, 直接通知nginx屏蔽改url. 当我们付款的时候因为要调用很多第三方接口,而且难以并行, 因此可以使用mq去异步操作。 直接返回用户下单结果。当下单成功了。 用户还可以查询是否下单成功, 或者抢到了待付款。 这时候流程就少了很多, 通过消息队列请求这些。
- 引流就是通过nginx记录访问来源和实际交易额来做引流, 对有很高收益的地方进行引流加强。
集群, 分布式, cap , zookeeper , paxos.
- redis可以做分布式锁 , redis 多个客户端谁设置 setnx成功了, 谁就拿到了分布式锁 。 还是不懂。 redis做分布式锁不推荐,推荐zk . cap是指一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。Paxos用于解决分布式系统中一致性问题。分布式一致性算法(Consensus Algorithm)是一个分布式计算领域的基础性问题,其最基本的功能是为了在多个进程之间对某个(某些)值达成一致(强一致);简单来说就是确定一个值,一旦被写入就不可改变。
- 这部分还是没掌握好。
总结
- WAITING ADD
ClusterChatSever
How to use it ?
- 安装mysql, 更改root密码为root, 设置监听地址为所有,而不是本地, 并且mysql -u root -p 的命令前面不要加sudo就能进去。 不然代码接口访问不了mysql。 此外还要安装 sudo apt-get install libmysqlclient-dev , 这是开发的依赖库。
- git clone 代码, 将代码拷贝到本地。
- 安装配置nignx
-
- ./configure --with-stream , 缺什么安装什么 sudo apt-get install libpcre3 libpcre3-dev sudo apt-get install openssl libssl-dev
-
- make && make install 编译完成后,默认安装在了/usr/local/nginx目录。
-
- 修改nginx配置文件内容为ClusterChatSever/test/conf/nginx.conf中的内容。
-
- 这里除了自己把字母拼错, 出现了两个问题,一个是没有shared 库, 这里面我就参照【3】做了,然后又出现了 [error] open() “/usr/local/nginx/logs/nginx.pid” failed (2: No such file or directory)问题, 参照【4】解决。最后进入安装的nginx/bin 中 nginx -s reload成功。
- 配置redis 这里就不介绍了, 和nginx差不多, 记得在cmake中添加依赖库(我已经添加了)。
- 运行调试, 发现之前ginx设置的断开链接事件太短了。 需要注意一下(已经修改),而且监听的端口要设置成路由器分配给网卡的路由。 最后得出来运行的效果正常。
1 背景
秋招在急,简历中没有一个合适的项目供面试官去展开提问和自己去练习。 而且在学习c++的过程中最大的问题就是没有合适的项目去融汇贯通, 不知道做什么才好,像java可以做很多有意思的后台项目, 但是c++貌似如果只是懂语法去做这些后台项目很难, 不知道从什么点出发去做。我想通过这个项目去掌握C++如何开发后台项目。 通过这个项目明白后台的开发流程, 让自己的c++能够做到实际开发的水平, 敢写c++。
2 任务
实现一个集群聊天服务器, 能够高并发的接收客服端的请求。 通过这个项目掌握
- 掌握服务器的网络I/O模块,业务模块,数据模块分层的设计思想, ORM
- 掌握C++ muduo网络库的编程以及实现原理
- 掌握Json的编程应用
- 掌握nginx配置部署tcp负载均衡器的应用以及原理
- 掌握服务器中间件的应用场景和基于发布-订阅的redis编程实践以及应用原理
- 掌握CMake构建自动化编译环境
- 掌握Github管理项目
- 熟悉现代c++, 尤其是绑定器和function等使用, 掌握面向对象设计的思想。
3 行动
1. 环境配置
- vscode + 远程linux
2. 整体实现思路
客户端:
用户过来进入登录或者注册页面。 如果选择登录的话, 我们发送一个json给服务器, 服务器返回该用户的信息, 例如好友列表, 群组, 离线消息。 登录成功之后, 我们将个人信息展示出来, 离线的群组消息和个人消息展示出来。 然后开启一个线程阻塞等待接受到的消息。之后主线程进入到聊天页表内。 另外一个主线程的业务是注册, 这个就不说了,很简单的一个。 我们继续说一下聊天业务中, 子线程阻塞去接受网卡的数据,这是因为别人发送消息自己要去接收,有消息就展示出来。
-
- 聊天业务有很多,我们通过一个
的map表存储回调函数对象。 string存函数的stringname , function里面传入函数名作为绑定。 这个函数名对应的函数要符合function定义的接受函数的类型。 这样的话娿我们就做到了解耦。 这样我们在聊天业务中去循环接受参数, 如果参数的函数名在回调函数的map表中找到的话, 我们就将fd 和字符串内容传递进去。 下面我们分析一下各个任务
(1) 添加好友任务就string的数据转换后才能json,并配置对应的信息标识后发送给服务器。 如果添加失败的话,服务器会返回错误代码的。
(2)聊天任务是将当前用户信息和消息以及发送的内容给服务器, 设置好对应的消息标识。
(3)创建群组的业务也是一样,需要发送自己的id和群名字和信息等。
(4) 添加群组的任务发送自己的信息和想添加的群组id给服务器。
(5) 群组聊天的话发送自己的信息和内容给群组id .
- 聊天业务有很多,我们通过一个
服务器 :
- ChatServer这个类封装网络层, 这个层的绑定自身类中的两个函数作为链接回调和接收回调。连接回调就不说了,直接拿到回调的fd进行关闭操作。 一般正常链接的话muduo自动放入epoll之后再触发这个事件。 数据接收回调的话 首先解析字符串成json, 之后会调用ChatService这个单例类的处理方法的函数,传入的就是这个json的消息id, 这个任务处理函数返回的是函数对象, 我们接收到函数对象之后传入fd, json数据和超时时间。
- ChatService 这个是业务类, 业务类的话只用一个单例就可以, 创建多个并没有意义,而且在多线程状态下,如果创建多个业务类的话, 一个请求来一个业务类,一个业务类被频繁的创建和销毁, 很浪费资源,而且避免了我们将一个统计变量弄成全局变量去统计, 全部在自己这个变量中去操作 。这个类绑定了很多自己的成员函数, 这些成员函数大部分的接受字符是fd + ** , 这些参数不一致情况的通过bind去填补。这个类有一些很重要的成员变量,四张表的对象类, redis的操作类, 互斥锁, 还有一个函数对象的hash_map表。 这个业务中会经常调用这些数据类。
3 框架
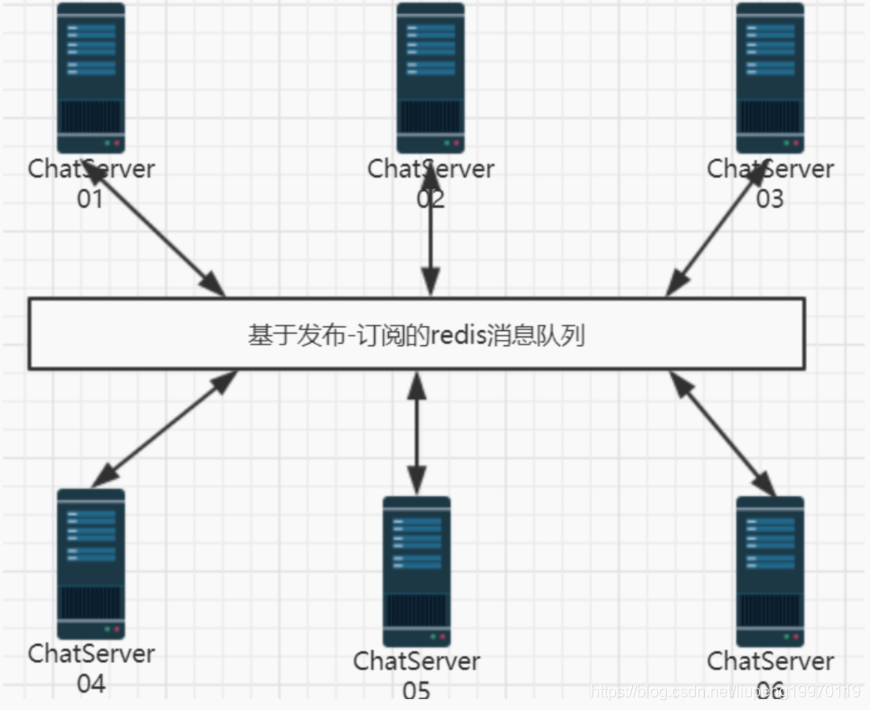
整体的框架如下, 多个服务器通过redis构建互通信息, 然后将多个服务器绑定到niginx上,与客户端交互。 服务器采用muduo库作为网络库底层, 以muduo库提供的回调作为业务层, 以自己封装的数据库类作为数据层的MVC结构进行开发。最终实现了一个高并发的集群服务器。
3. 技术栈
C++, linux , cmake , mysql , redis , nginx , muduo , gdb , git, json
4. 具体步骤
- 学习json和json开源库
-
- 数据交换语言是独立于编程语言的, 不同编程语言通信时通过json等交换语言进行。 json是一个比较简单的字节流交换语言。 通过key-value存储数据。 我们使用一个开源库 , 他可以支持很多语言的json序列化和反序列化(也就是转换成数据类型或数据类型变成json)。用的时候也比较方便, 直接倒入一个头文件就行, 具体序列化实现都在这个文件文件中做了。
- muduo 网络库使用和学习
-
- 编译安装参照【1】, 这里面我已经装好了。
-
- muduo和众多网络库都是epoll+ 线程池的高性能服务器设计。 可以让我们直接关注到连接断开读写这几个事件的callback业务层, 请求来了底层自动调用callback。
-
- 学会使用muduo开发一个基本的高并发服务器。
- cmake的使用与学习
-
- 在vscode上配置cmake 辅助工具(界面操作+代码提示与检查), 便于操作linux系统中的cmake.
-
- 基本的编译程序所做的命令例如:g++ -o server -g muduo_server.cpp xx.cpp -l/usr/include -L/usr/ib -Imuduo_net -lmuduo_base -lpthread 都可以在cmake中找到对应的配置选项, 去自动生成makefile。
-
- cmakelists.txt 真的很强, 通过add_subdirectory(src) 去找子cmakelists.txt去编译。
- mysql 学习
-
- mysql 安装与账号、权限配置
-
- 创建业务需要用到的数据库和表。
CREATE TABLE IF NOT EXISTS user (id INT AUTO_INCREMENT PRIMARY KEY , name VARCHAR(50) NOT NULL UNIQUE , password VARCHAR(50) NOT NULL , state ENUM('online', 'offline') DEFAULT 'offline' )ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE IF NOT EXISTS friend (userid INT NOT NULL , friendid INT NOT NULL ,PRIMARY KEY (userid,friendid) )ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE IF NOT EXISTS allgroup (id INT AUTO_INCREMENT PRIMARY KEY , groupname VARCHAR(50) NOT NULL UNIQUE , groupdesc VARCHAR(200) DEFAULT '' )ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE IF NOT EXISTS groupuser (groupid INT NOT NULL , userid int NOT NULL , grouprole ENUM('creator', 'normal') DEFAULT 'normal' ,PRIMARY KEY (groupid,userid) )ENGINE=InnoDB DEFAULT CHARSET=utf8;CREATE TABLE IF NOT EXISTS offlinemessage (userid INT NOT NULL , message VARCHAR(500) NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
创建源代码目录
整个项目在src,include中分为后台和客户端。 各种目录的编译通过各级的cmakelist.txt去控制。 -
开发网络模块,搭建业务模块, 定义消息类型
-
- 我们使用muduo库开发网络层,在网络层的回调中, 设置了单例的业务类, 根据自身消息的id在业务类的map回调函数表中找对应的处理函数, 至此网络模块不再变动添加,完全解耦。
-
- 消息类型如下: {“msgid” : 4 , “name” : “zhang san”, “password” : “123456”}
-
- 封装mysql数据库类
-
- 像orm框架一样, 用类封装数据库操作, 这样当数据库的代码有所变动,例如表的变动, 不会变动业务代码。
-
- 使用时候我们先将一个表定义成一个表类, 定义一个数据库连接类, 定义一个数据库封装类, 这个类包传入表类和包含数据库连接类, 在封装类中将表类中数据传递到数据库连接类(数据库连接类依赖mysql的客户端包)。
-
- 简单的传入一两个数据的话,不用再添加一个数据类。 直接定义一个数据库操作类。
-
- 说一下各个数据表的作用:
-
- redis类封装了redis接口类, 当订阅的id传入给redis服务器之后,初始化业务类的成员函数为一个函数对象。 并给一个子线程接口, 这个子线程一直while, 当有订阅内容过来的时候, 将内容传给这个函数对象, 也就是业务类成员函数。 (这个子线程好像是在connect里面弄得, 但是sub时候把上下文添加进去)。
-
- mysql底层的驱动库, 这里面封装了查询语句, 给个类。
-
- friend 数据类: 添加好友关系到表, 查询用户的好友表()
- 编写业务模块类
-
- 编写了数据库类之后,我们开始关注业务层。 注意数据库层一般是辅助业务层的, 所以不能在一开始就写完数据层,而是业务层缺什么补什么。
-
- 首先来看登录业务, 我们根据输入的信息 要去users数据操作类中设置一个函数查找对应id的数据,判断是否账号密码匹配。 当匹配的话进入业务逻辑: 判断如果没有登录过,也就是users数据库的内容为offine后, 我们使用lock_guard 这种对象绑定创建的锁,控制这个类的当前在线用户列表添加这个数据, 通过生命周期释放。还要向redis注册这个id, 并且将自身的成员函数绑定到redis的回调中,如果这个id有事件了, 会过来通知。 此外拿着这个表去好友表查, 群组表查,离线表查,
-
- 注册业务比较简单了, 将json数据放入user对象之后, 传入到数据库操作类定义的insert函数中对接数据库sql。不用加锁。
-
- 退出业务的话删除在线用户从在线map中。 redis取消这个id的订阅,user表设置该id状态为离线。
-
- 添加客户端异常退出, 这个不是回调业务, 而是当服务器退出时候需要处理业务类的数据,清空在线状态。此外当我们调试阶段会主动关闭服务器, 导致里面的业务数据来不及更新。 因此添加ctrl +c 接收函数, 处理退出时候的业务重置。这个放到main函数里面。 但是好像不怎么解耦, 不过业务重置所在的类实单例业务类, 也没事。
-
- 点对点聊天业务: 定义好发送信息的json格式之后,一个用户往另外一个用户发送的数据服务器判断当前这个表是否存在这个用户id, 存在的话往在线的用户fd直接socket send 数据。 不存在的话如果检测在线, 就去redis里面去发送。 不在线的话就保存数据到离线数据库中。
-
- 离线业务比较简单,而且不是单独的业务,而是一个放在其他业务的子服务(例如当登录的时候先去调用这个数据库封装类看有无消息)。 而且其数据表比较简单, 所以我们不用设计数据对象, 直接封装数据库操作类, 传入的参数为整数和string即可。
-
- 加好友的业务 : 当对应添加id的数据来的话, 对friend表进行insert, 此外还要将好友数据类的多表联合查询功能提供给登录业务, 一开始的时候就要显示当前登录账号的好友。
-
- 创建群的业务 : group 是需要定义一个对象来存储数据的, group数据类内部封装了两个表, 有一个数据库对象负责创建群的和管理这个群用户之间的关系。
-
- 加入群业务: 将自己的信息和用户id加入到group这个表中, 成员为normal.
-
- 群聊天业务: 创建一个锁之后, 对从group中查询的用户信息进行判断,如果在本机就直接发送, 在线但是不在本机使用redis push, 其他的离线存储
- 编写客户端
-
- 完成服务器之后,我们使用简单的多线程开发一个termail客户端。 客户端通过主线程管理聊天过程, 子线程阻塞接收服务器的发送信息。 此外通过functional 绑定自身的函数, 将switch选择调用函数的耦合度较低代码做成闭合的代码。
-
- 一些交互的代码这里就不再补充了。 如果出错的话或者不出错但是逻辑输出不对,记得调试一下。 还是说一下吧,
- 加入nginx负载均衡器
-
- 我们主要使用nginx的负载均衡器, 注意这里使用的是tcp负载均衡模块。 本来一台是1-2w并发, 但是nginx能够轻松5-6w, 因此多加几个应用服务器后可以达到5-6w, 此外还可以nginx可以集群, 在前面加硬件的LVS负载均衡。
-
- 负载算法有轮询, 一致性哈希(在短链接中经常用,http服务器中经常问),负载权重等。
-
- 此外聊天服务是长连接服务, 服务器发送给客户端还需要进行负载均衡器。 也有直接发送client,不经过nginx的服务器。
-
- nginx还有心跳检测功能,保证服务器一直正常工作。 还有支持动态加载配置文件, 不用重启就可以更换添加应用服务器。
-
- 应用服务器启动后, nginx会自动管理他们。 我们访问nginx时候会转发给响应的服务器。
- redis 解决跨服务器之间的数据交互
-
- 当client1和client2登录在不同的服务器上, client1的userconnmap里面找不到client2的信息, 因为虽然是在线的, 但是他登录在其他的服务器上。 这个问题怎么解决呢? 我们先在userconnmap找, 如果找不到再去数据库找这个用户是不是online, online的话代表在其他服务器上, 那么这就还有一个问题, 如果把数据发过去呢?我虽然知道他在其他服务器上,但是不知道具体在哪个。那么得两两相互连接,每一台服务器要和其他服务器互相连接。 这会代码的耦合性非常高。因此我们使用服务器中间件中的消息队列中间件。 像比较出名的kafka(还支持分布式部署的), rabbitmq都是, 但是我们这个项目比较简单,就只用个基于发布订阅的redis就行。(注意这里我们没有使用redis的key-value这些内容,而是用了redis的一个发布订阅的小功能。 )
-
- 基于发布订阅的redis : 每一个用户在chat服务器上登录时 ,都会去redis上订阅自己的id相关的消息,当别人发送消息时候,本地找不到,数据库显示在线状态, 就肯定在redis中, 就执行publish消息给redis。 redis将消息notify给订阅这个主题的人。
-
- redis首先是一个强大的缓存服务器,比memcache强大很多,不仅仅支持多种数据结构(不像memcache
只能存储字符串)如字符串、list列表、set集合、map映射表等结构,还可以支持数据的持久化存储
(memcache只支持内存存储),经常被应用到高并发的服务器环境设计之中。
- redis首先是一个强大的缓存服务器,比memcache强大很多,不仅仅支持多种数据结构(不像memcache
-
- 安装redis服务器,客户端登录后测试,并且安装客户端源码,里面包含了开发库和头文件。
-
- 如何将redis的代码加入到之前的项目中呢? 在登录的时候连接redis,设置上报时候的回调函数(bind+fc) des订阅主题。 单点或者群聊天的时候如果online本地找不到的话记得加publish。 上报设置的回调是别人发送消息时候redis服务器notice过来时候会自动调用的。 回调里面是在这个服务器的con连接中找到对方要发的con, 进行推送。
4 结果
完成服务器的搭建。 高并发高可用。
5 问题记录
编程问题
-
define 内容别的地方引用时候要在头文件里面define才能用到。
-
g++ muduo_server.cpp -o server -lmuduo_net -lmuduo_base -lpthread 这个连接库是有依赖关系的, 最基础的在最前面。
-
hpp代表head file combine with cpp file
-
sudo netstat -tanp 查看端口对应的进程。
-
回调之前一直不理解, c++回调基本全部用bind+ functional 去代替了, 因为普通函数回调限制较多不能携带使用类变量。 回调贯穿了整个程序oop的解耦操作中, 当一个函数什么时候发生和发生时候怎么做不再一起,就要事先设置回调。 供其他程序调用发生时候启动。(其实可以写到其他程序那部分, 但是不能解耦。)这个项目中我们将业务封装到了业务类中, 当网络这块回调被epoller-wait启动后根据数据的id拿到业务类的对应方法进行调用(通过bind+ fc+ map)。 业务再怎么改, 这边代码都不动了。 真正解耦。
-
头文件负责定义类还有添加头文件(定义时候需要用到的) , 注意只需要编译一次。 对应的.cpp 负责具体实现, 当我们将其编译成库的时候, 就只需要头文件了, 具体源码实现都在.so中, 不用库的话, 也会自动去找.cpp的实现。当然我们有时候不需要这个cpp文件,类直接在hpp里面定义并声明完成。
-
当形参变量和类成员变量的名字一样时候,一定要加this区分。
-
如何设计开源文件的目录, bin放可执行文件 , lib是生成的库文件 , include是头文件, src 是源码, build 项目编译时候产生的临时文件, test放的代码, cmakelist.txt 设计编译文件的规则, autobuild.sh 自动编译, readme.md 。
-
公网链接的时候, 服务器绑定自己内网网卡的地址, 客户端访问服务器所连接的公网地址, 请求过来之后自然会通过路由找到内网所在的网卡。建立链接。
-
当程序从看的角度找不到问题, 就只能调试了, gdb打断点break到出问题的之前点, 然后run, next,排除问题。 而且很多知名的开源代码会经常使用基类指针的运行时多态, 如果不走运行调试分析, 很难理清整体的框架。
设计问题
- 如果我们还需要扩展的话, 需要将这些服务拆分,通过RPC框架注册成RPC服务, 然后供客户端请求, 有时候一个请求需要多个服务交互完成,这时候就需要zookeeper 注册中心,做服务的管理和统计, 让各个服务能够及时的响应和并保持一致性。但是很简单的一个问题, 贪多就不能精。 在这个找实习的节骨眼上, 做分布式明显不是自己现阶段的主要矛盾。
- 线程数量和cpu核数量请保持一致, 这样避免不同核时候, 线程调用上下文调用过慢。
- 这个项目并没有使用数据库连接池, 因此每次查询都要创建数据库连接类效率比较低效。
- 用户和群的关系是多对多, 因此必须有一个中间表反应多对多之间的关系, 这里我们使用了一个id和组id联合主键的表作为中间表, 反应了用户和表的关系。 这是表的设计问题。
- 创建群等操作没有ack, 我们可以自己添加。
- 不用担心json输入错误,我们调试时候是自己手动输入json, 而实际发送信息的是客户端, 到时候发送的格式是固定的。
- 可以自学一些界面库或者前端的内容,将客户端从termail改成界面类型。 这是加分项。
- 注意这里我们没有使用redis的key-value这些内容,而是用了redis的一个发布订阅的小功能。因此如果面试时候被问到, 很可能关注点都不一样。 人家关注的数据如何保持一致性, 存储的原理。 我用的只有发布订阅设计模式。
- 数据库可以使用基于java语言开发的mycat中间件 , 做分表分库, 主从复制,读写分离。
- 有的表不需要创建额外的数据结构去定义数据, 有的复杂的需要。 各种表的查找问题: 查找好友的话, 需要求用户表和好友表的交集。 查找离线信息的话是单表查询。 查找用户的话也是单表查询。 创建组的话就在allgroup里面添加, 加入组的话就是添加到组成员表, 查询用户所在组是多对多的关系, 查找成员表中特定id的组, 这些组联合allgroup 查出来结果, 查询群组的用户信息。
- 主要操作stl的容器, 对其增删改查都是线程不安全的 。要加锁。
微服务聊天服务器
基础知识
1. probuff
- probuf可以看成是一个新的协议, 可以压缩的一个协议。 定义好协议proto之后会生成pb. cc.pb.h 这两个文件。 需要交互的时候, 我们给对方proto , 对方生成自己语言版本的 代码和头文件之后就可以解析出来。 但是这样有一个麻烦就是每次数据协议更改, 都要重新生成。但是快呀。每个语言的编译代码和头文件都有序列化和反序列化这些代码。只不过定义的方式不一样。 proto采用vlant压缩的。
2. zookeeper
- zookeeper的功能很多,常用的就是一个服务注册和发现, 但是像一些watch等api可以实现发布订阅功能,此外zk还支持分布式锁等,负载均衡。 我们这个项目中就是只使用了一个服务注册和发现的功能。
3. redis
- redis作为一个消息中间件有很多功能, 这里我们只用了一个, Redis 服务器主要存储了用户的Host信息如下: id号 ip:host 例:10086 “127.0.0.1:3001” 先去 Redis 服务器上查询这个用户是否在线;如果在线,取得它的 Host 信息.。 之前项目的发布订阅功能取消了,直接用这个代替, 拿到对应的服务所在地址,发送一个消息, 接收方拿到这个消息之后找本地的链接conn, 进行通信。
4. nginx
- 负载均衡和反向代理功能就不说了
5. rpc
rpc框架的实现逻辑:
服务方:
- rpc服务器类就是首先传入rpc服务类进去, 然后调用run成员函数。
整个 run 其实就是干了这么几件事情:
因为底层调用的是muduo网络库,所以这里会获取ip地址和端口号,然后初始化网络层
然后去设置一个连接回调以及发生读写事件时候的回调函数(后面说)
然后创建zookeeper配置中心,将这些方法的信息以及本机的IP地址注册到zookeeper
然后开启本机服务器的事件循环,等待其他服务器的连接 - rpc服务类是基于UserServiceRpc.pb.cc.h 重写的, 重写里面的登录函数绑定成本地的函数了, 并建立了函数对象的map表。 那么还有一个问题就是发送过来如何找到的是这个类下的函数呢?这个好像就是直接去zookeeper里面去查的。但是还要找到具体的函数呀, 哦 原来是这个服务类继承的就是rpcprobuf类,进行成员函数的重写的。发过来通过基类指针可以指向具体的服务。
- 这里说一下muduo读写回调中干了啥, 首先是给一个probuf ::done指针, 这个指针绑定了发送序列化数据的函数,但是不执行。 这样当每次执行类似login服务的时候, 都会运行这个done指向的函数,让这个函数去发送序列化数据。
客户端:
客户端调用stub, stub里面传入一个指针, 这个指针在login方法中去调用callmethod函数, 这个callmethod函数至关重要, 主要实现了
组织要发送的 request_str 字符串
从zookeeper中拿到服务端的 ip 和 port,连接服务端
发送 request_str
接受服务端返回过来的 response 字符串并反序列化出结果
整体架构
-
set 模型: 整个ByteTalk整体设计抽象为由多台服务器组合而成的一台超级性能的服务器,这些服务器形成一个小集合,部署一整套对外的服务。set模型弥补了单机能力的不足,对业务组合搭配成一个单元。本质上是对服务的一个高内聚的封装。
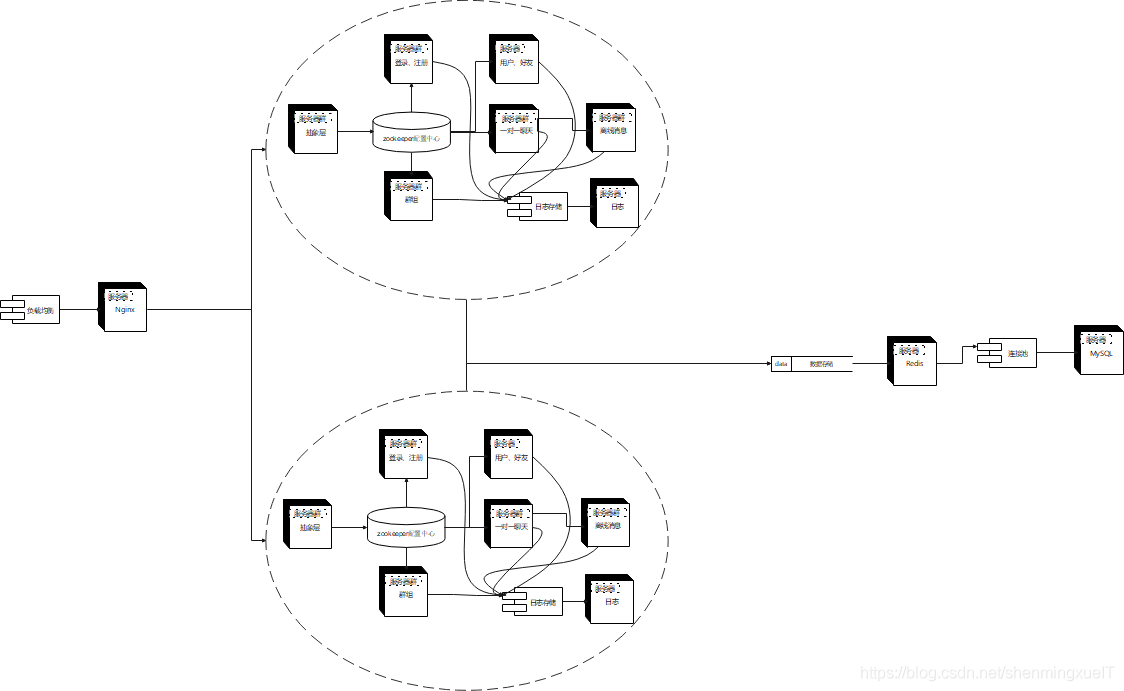 2. 分布式项目整体的框架如下。 首先的也是采用nginx去转发用户请求, 转发到多个超级集群中,每个超级集群是一整套业务。这个集群中有一个网关服务器转发到各个服务,实际上就是集群服务中的具体业务功能不在本地实现,使用rpc去调用这个逻辑。 因此我们现在来看这个框架就明显了。
2. 分布式项目整体的框架如下。 首先的也是采用nginx去转发用户请求, 转发到多个超级集群中,每个超级集群是一整套业务。这个集群中有一个网关服务器转发到各个服务,实际上就是集群服务中的具体业务功能不在本地实现,使用rpc去调用这个逻辑。 因此我们现在来看这个框架就明显了。 -
ProxyService 作为整个服务单元的入口(底层就是一个网络类加一个service类。 网络类转发数据到单例的service类的handle函数中得到函数对象, 拿到这个函数对象后将数据转发过去),整个服务单元对外暴露的也是它的 Host 信息,他从文件配置中拿到ip后将本地服务配置成网关服务器, 也就是nginx的下一层。 在封装了muduo库的server类中,对于客户端的请求信息,它会首先通过单例业务类中函数对象map表找到函数对象, 然后调用。 也就是实现了判断这个信息是哪个业务(难免要把所有probuf全部引用过来),如果是服务器的业务,它就会去Zookeeper注册中心,找到提供这个服务的服务节点,并把这个请求序列后发送过去。 (需要注意这个其实可以类比之前我们的集群服务器,但是我们的函数和数据类型全部用probuf桩代替了, 之前的基于数据和函数调用的操作全部用这个stub了。 此外找到的用户id和socket链接仍然存在这里, 所有访问直接通过这个抽象服务器去链接到具体的服务器, 在线用户所在的服务器ip也是在这里注册的)
-
- 登录业务的话去发送到业务服务器上, 如果响应登录成功的话,在redis上注册这个用户所在的服务器单元, 并在本地的链接map上添加id和本地和nginx链接的conn。但是注意这里的注册和连接是网关在做, 实际的函数调用是业务层在做, 本身不记录状态。
-
- 对于群消息而言, 我们拿到后判断能否在本地的已经链接的数据中找到这个对应的conn,找到之后使用conn发送。
-
- 注册注销,添加好友 , 获取用户信息,好友列表, 离线信息, 加群, 创建群, 群成员信息这些服务就没有任何额外的处理, 都是转发的。
- 每个具体的业务服务也都会启动一个抽象节点,以登录、注册节点:UserService为例 。还会启动很多个实际的业务节点。 抽象节点收到一个消息,就会去zookeeper注册中心中获取一个可用的服务节点UserServer x地址,然后将这个消息派发给它,让它去执行。UserServer x会和持久层的 mysql 进行交互,具体的读取这个用户信息。(这里面没有实现对象的orm封装), 此外我们会疑惑userservice和userserver之间的关系如何, 其实都是一个rpc服务, 但是代码中少了一个抽象单元服务启动模块, 类的申明没有调用。哦, 看错了, 其实在辅助代码那一栏里面写了。
-
- 我们来继续看一下里面的逻辑, 从userservice开始, 这个就相当于一个调用者, 它里面对stub这个桩进行重写, 里面的实现步骤就是重写登录退出注册函数, 这些函数的步骤就是先调用zk客户端去获取当前服务的站点信息, 然后选择一个发送给真正的服务处理端。注册和退出是同理的。 继续走到userserver服务中, 这个是服务的真实落脚点。 这个就是服务的提供者, UserServer 大体上还是分为两层:网络层和业务层。网络层还是基于muduo网络库构建, 在run函数里启动网络层绑定回调(注意之前看很多代码都是叉开了,这里没有拆开让我刚开始看的时候比较迷。 )run业务层则是首要的就是向zookeeper中去注册这个节点。一般是在/UserService目录下,以便抽象节点能够去发现服务。注意这个是临时节点,断开就没了。 然后还有回调的业务层,在这里面我们解析数据, 将解析出来的数据放到对应的本地方法中, 本地方法通过数据库线程连接池拿到一个ptr, 去查询,结果进行返回。 这里面的业务比较简单都是单表查询。
-
- 其他业务类似。
-
- 聊天服务器是没有抽象节点了, 直接本身就是在做处理,本身的抽象代理是网关自己。 因为这个聊天服务器可能会创建多个, 一个个人聊天消息, ChatServer 会先去 Redis 服务器上查询这个用户是否在线;如果在线,取得它的 Host 信息(也就是用户所在的服务单元),然后去已建立的连接map 中看是否建立过,如果没有建立,那么就建立,然后将这个连接放入map。接下来将这条信息转发过去;如果不在线,就将这个消息存储到 mysql 的OfflineMsg表中,供客户端下次上线时读取。此外聊天服务器的消息接收接口是抽象网关交互的。 网关检测到本地的链接没有的话, 那么就从zk这个服务路径下随机链接一个服务, 对这个zk给的地址发送链接, 并且将数据转发过去。然后如果聊天服务器本地服务还会执行之前说的去redi查找对应的用户所在的ip
-
- 群聊天没有实现,这里感觉不解耦,放到聊天里面, 我们多表查询到用户之后,依次去发,这样做一下估计可以的。
个人的不足之处
- 数据表的操作和意义不熟练, 还需要再复习
- redis的发布订阅任务底层不熟练
- 群聊天没有实现,这里感觉不解耦,放到聊天里面, 我们多表查询到用户之后,依次去发,这样做一下估计可以的。
常见问题
1. 介绍一下这个项目
这个项目将之前的集群项目升级到分布式项目,第一个项目是nginx集群服务器项目。 首先我们请求过来之后, 我们会访问到nginx, nginx转发到我们的业务服务器上。 我们的业务服务器采用mvc架构, 通过muduo库作为网络层, 将触发事件绑定到类成员函数中。 services是v层, 通过传入定义的信号id在map中得到函数对象后调用。
- 登录业务, 查询传入的id和数据库是否匹配进行判断, 并且查询离线数据表中是否存在离线的数据。 然后还要查询当前用户的好友, 所有群组信息返回。 在redis上订阅自己的监听事件
- 退出业务: 删除已经链接的用户map, 删除在redis上的消息订阅, 更新数据库用户状态。
- 注册业务: 像用户类写入数据。
- 聊天发送服务: 当发送的id在本地,发消息给本地在线的服务器,数据库在线的话,我们推送数据到redis上,如果是离线的话就数据保存到离线数据上。
- 添加好友: 添加好友到好友列表。
- 群组创建: 将信息放到群组类中,并添加自身为creator成员到群组信息表中。
- 群组加入: 加入群组到群组详情表
- 群聊 : 先从群组信息表中查, 查完之后重复单人聊天服务。
- 聊天接收服务: 这个事件是redis类绑定的,只绑定这个id。 别人在其他服务器上push到自己id时候, 这个会触发, 触发了之后检测本地在线, 发送。 不在线的会退出。
说完业务层, Model 其实是对数据的操作的封装, 我们首先将mysqlcudr原生操作封装成一个类(这里面其实可以用一个线程连接池的),供数据模型调用。 数据模型操作时候还可以添加一层抽象的数据模型,统一管理操作。 (表的具体操作和设计参照后面)
在此基础上我对这个项目进行了升级, 采用微服务的形式去做了升级, 将各个业务抽离了,形成一个个集群服务。通过rpc来调来调去。 虚拟服务节点做了很多服务的绑定,虽然这个服务都是在做rpc的调用者。
2. 项目中觉得可说的小细节
- 第一个就是我们设置成后台程序,而且设置了信号捕捉, 避免ctrl-c的干扰。
- 业务类采用单例模式, 为什么是单例模式呢, 因为很多用户请求都重复调用这个,对立面的成员变量修改设置好锁就好了。 还要注意lock_guard 设置括号可以自动析构这个技巧。
- 我们实现了一个配置文件的参数初始化,进行了项目的解耦。 让配置原理源代码。
- rpc一套服务要放在一个局域网中, 性能会更高一些。
你自己在项目中负责的任务
- 在前期系统调研的时候是我们一起讨论的。 后续的话我负责登录注销退出和群组。 他负责数据库和聊天系统的设计。 不过在做完之后我们都有系统的分享, 仔细说了一下对面是怎么做的, 因为会涉及很多交互。
这个项目目前的缺点是啥?
- 首先就是我的nginx的负载太大了。 这一点可以配置LVS软件,运行在操作系统内核态,可对TCP请求或更高层级的网络协议进行转发,因此支持的协议更丰富,并且性能也远高于Nginx,单机的LVS可支持几十万个并发的请求转发。 但是更好的方法是dns服务器轮循, 转发到多个nginx, 这样可以解决上亿的并发量了。 或者我们可以将分布式中和客户端交互的节点通过zk告诉给客户端, 让他们自己建立链接。 减轻交互的负担。
- 第二个就是对于数据库,包括mysql Redis部分,其并没有考虑高并发和高可用,也没有进行分库分表等设计。模拟的数量数据量过小, 没有一些实践故障上的经验。
- 对于容灾的考虑没有考虑很好, 对于实际的业务节点,我们是有zk临时节点监听这个去保证(但是轮询算法也是不太好, 应该用权重算法)。 但是对于业务抽象层, 集群网关服务器没有一个好的方法去解决容灾。这里建议就是corntab 定时检测去拉起来。
-
- 一些业务没有完善, 其实实际的聊天业务的话加好友还要同意,还有退出群聊等等相关的业务, 但是这个项目本身是为了学习, 所以业务方面完善程度不够。
- 数据库链接并没有采用链接池, 应该采用去做优化的, 通过一个单例的线程池管理, 设置固定量的链接放到队列中, 通过信号量控制连接池资源的分配。 这里面对于存数据库链接的队列,读写要加锁。 要加信号量防止资源分配溢出。 通过raii进行资源创建和删除的管理
- 很多异常处理可能没有想到, 感觉服务代码异常处理要考虑很多, 要保证服务不能宕机,最简单的corntab自动拉起来要用到。
客户端断网会怎么样?
- 首先就是断网了估计没有四次挥手,然后服务端那边会做一个定时器检测心跳, 当这个断网的链接端口超时之后会自动关闭, 关闭了就触发了muduo库的链接回调, 我们将这个回调绑定到自己的service层, 去关闭这个在线但是断开的连接。
说一下数据表的操作和设计?
- 用户表是一个以id为主键的表, 封装成了一个抽象模型对其进行cudr,没有什么难的操作。
- 好友表是一个联合主键表, 查某一个用户的好友时候, 设计多表查询。 select a.id , a. name,a.state from user a inner join friend b on b.friendid = a.id where b.userid = 3
10.离线消息: 离线消息是一个简单表, 只需要普通查找就行了。 - 组查询: 这个是一个复杂数据结构, 里面涉及了多对多的表的操作。 例如我们根据用户的id去找用户所在的群账号信息(select a * from allgroup a inner join groupuser b on a.id = b.gourpid where b.userid = 3 ) 查询组成员的信息(select a * from user a inner join groupuser b on b.userid = a .id where b.goup = 3. ) 根据组的id找本群的所有成员信息(select userid from groupuser where groupid = 100 and userid != myself )
probuf为什么比较高效?
- 采用了vlant压缩的方式, 然后可以跨平台使用, 我们只要拿到通信的probuf, 可以生成自己语言的序列化和反序列化代码 , probuf最好的就是对原生的rpc支持, 通过桩定义了probuf里面描述的方法, 服务发现者只需要重写里面的内容改成自己的就可以实现自己的rpc服务。 很方便。
rpc框架的底层原理
- 首先我们要有rpc的底层通信原理框架思路, 序列化和反序列化这个意识要有。
服务方: - rpc服务器类就是首先传入rpc服务类进去, 然后调用run成员函数。
整个 run 其实就是干了这么几件事情:
因为底层调用的是muduo网络库,所以这里会获取ip地址和端口号,然后初始化网络层
然后去设置一个连接回调以及发生读写事件时候的回调函数(后面说)
然后创建zookeeper配置中心,将这些方法的信息以及本机的IP地址注册到zookeeper
然后开启本机服务器的事件循环,等待其他服务器的连接 - rpc服务类是基于UserServiceRpc.pb.cc.h 重写的, 重写里面的登录函数绑定成本地的函数了, 并建立了函数对象的map表。 那么还有一个问题就是发送过来如何找到的是这个类下的函数呢?这个好像就是直接去zookeeper里面去查的。但是还要找到具体的函数呀, 哦 原来是这个服务类继承的就是rpcprobuf类,进行成员函数的重写的。发过来通过基类指针可以指向具体的服务。
- 这里说一下muduo读写回调中干了啥, 首先是给一个probuf ::done指针, 这个指针绑定了发送序列化数据的函数,但是不执行。 这样当每次执行类似login服务的时候, 都会运行这个done指向的函数,让这个函数去发送序列化数据。
客户端:
客户端调用stub, stub里面传入一个指针, 这个指针在login方法中去调用callmethod函数, 这个callmethod函数至关重要, 主要实现了
组织要发送的 request_str 字符串
从zookeeper中拿到服务端的 ip 和 port,连接服务端
发送 request_str
接受服务端返回过来的 response 字符串并反序列化出结果
redis,zookeeper,nginx分别的工作
- redis主要就是做了一个全局的通信, 将每个用户所在的ip信息放到redis上,发送消息的时候代替之前的redis发布订阅的功能, 自己主动去发送。 zookeeper是一个服务注册的, 让上一层的服务能够发现自己底层的服务。nginx就不说了, 简单的反向代理。
- redis里面存储的实际每个用户所在的位置, 而zookeeper只是做了一个服务的管理, 这些zookeeper的服务有的是抽象服务, 还会往下面转。 因此注意这一点。
日志模块怎么设计的
之前的项目是采用本地的异步的单例日志, 这个日志是借鉴web服务器项目的, 首先创建一个线程,然后资源给shared_ptr , 这个指针循环从队列里面取string数据, 然后写入。 我们调用方只需要调用这个单例类, 将数据放到这个信息队列中(需要拿到锁,向buf中写入数据,把数据加入到队列中后才释放锁。但是这都只是在内存中,速度很快)。 这个日志类底层的另外一个线程会检测这个队列中的数据, 循环写入到硬盘。
但是升级到分布式的项目之后, 我们的日志采用了rpc交互, 但是交互的底层应该去模拟之前的日志模块去设计的,通过异步队列实现。
项目中遇到了哪些困难?
- 在前期学习的时候,其实分布式的c++项目很少, 那会学的很痛苦, 看着旁边学java同学对分布式这些非常数据, 数据库也很6 , 其实是比较慌的, 那会就在想是不是自己能力不行,或者是自己的方向走错了。 为啥资料这么少,c++后台是不是和java的不一样。 后面在学习的过程,我明白了为啥c++的项目难找, 一个就是因为官方生态比较慢, 第二个就是比较看重基础等。 到了6月份自己才接触到这个项目, 做了很久, 做完之后彻底打通了c++后台, 很多技术栈能和java对得上了, 但是确实存在偏差, 像数据库这些其实c++好像没有很多涉及, 所以大数据量的情况难以接触。
- 在开发阶段, 我们针对架构进行了设计, 这里面我们去看了一下别人分布式怎么设计的。 开发过程中学习了很多调试的技巧, 还有就是如何去写一个高质量的代码。
- 最后的话,也是我一直想要强调的文档文化, 学习没有文档等于白学。 我自己接触了很多朋友, 技术厉害的有很多, 但是愿意写文档的真的不多。但是我觉得文档真的非常重要, 包括在工作中, 很多知识密集的会, 开会前和开会后有文档效率会很高。 对于这部分我对技术的理念就是,我不是最强的, 但是我一直在努力变强中, 我一直以帮助他人, 轻松自己这个方向在努力。就有点科技向善的思想吧。
参考文献
- https://blog.csdn.net/QIANGWEIYUAN/article/details/89023980
- 服务器编程教程
- https://blog.csdn.net/lihao19910921/article/details/81907795
- https://blog.csdn.net/tjcyjd/article/details/69683360
版本记录
- 完成初步版本。 2021.4
- 重新复习和完善文档,整理出来问题。 2021.8
- 整理分布式扩展的思路
招聘
C、C++语言
-
正反码
-
内存碎片
分为内部和外部, 内部是指没有充分利用,这没办法, 但是外部可以通过段页方式管理或者内存池。 每次配置一大块内存,并维护对应的16个空闲链表,大小从8字节到128字节。如果有小额内存被释放,则回收到空闲链表中。
(1)如果有相同大小的内存需求,则直接从空闲链表中查找对应大小的子链表。
(2)如果在自由链表中查找不到或者空间不够,则向内存池进行申请。 -
请你说说malloc内存管理原理(内存管理池)
brk、sbrk、mmap都属于系统调用,若每次申请内存,都调用这三个,那么每次都会产生系统调用,影响性能;其次,这样申请的内存容易产生碎片,因为堆是从低地址到高地址,如果高地址的内存没有被释放,低地址的内存就不能被回收。
所以malloc采用的是内存池的管理方式(ptmalloc), 避免内存碎片 -
拷贝构造函数的参数类型为什么必须是引用⭐⭐⭐⭐⭐
-
说说静态变量什么时候初始化?
-
说说初始化列表的使用场景⭐⭐⭐⭐⭐
-
请说说多重继承的二义性
-
vector如何正确删除重复元素⭐⭐⭐⭐⭐
-
unique_ptr指针实现原理⭐⭐⭐⭐⭐
-
说一说cast类型转换
-
lambda值捕获可以修改吗
-
函数对象这几个不熟悉
操作系统
- 请你说说CPU工作原理⭐⭐⭐⭐⭐
- 说说中断流程⭐⭐⭐
- 说说常见信号有哪些,表示什么含义?⭐⭐⭐
- 内存模型(堆栈的增长不熟悉)
- 说说写时复制⭐⭐⭐⭐⭐
- 说说什么是守护进程,如何创建?⭐⭐⭐⭐
- 说说进程通信的方式有哪些?⭐⭐⭐⭐⭐(不够细节)
- 进程通信中的管道实现原理是什么?⭐⭐⭐⭐⭐
- 共享内存的使用实现原理(必考必问,然后共享内存段被映射进进程空间之后,存在于进程空间的什么位置?共享内存段最大限制是多少?)
- 说说进程调度算法有哪些?⭐⭐⭐⭐⭐
- 多线程和多进程的区别(重点 面试官最最关心的一个问题,必须从cpu调度,上下文切换,数据共享,多核cup利用率,资源占用,等等各方面回答,然后有一个问题必须会被问到:哪些东西是一个线程私有的?答案中必须包含寄存器,否则悲催)
- 简述内存置换算法。⭐⭐⭐⭐⭐
- 为什么要用虚拟内存,好处是什么?⭐⭐⭐⭐⭐(回答的不够全面)
- 虚拟地址到物理地址怎么映射的?⭐⭐⭐⭐⭐(不熟悉)
- 简述操作系统中的缺页中断。⭐⭐⭐⭐⭐(注意操作的是内存物理地址)
- 简述自旋锁和互斥锁的使用场景⭐⭐⭐⭐⭐
- 异步IO:
- 说说多路IO复用技术有哪些,区别是什么?⭐⭐⭐⭐⭐
计算机网络
数据库mysql , redis
数据结构
- 前缀树和倒排索引
- 排序算法的复杂度和是否稳定, 什么是稳定排序?为什么需要稳定排序?
场景题和项目 - 二叉搜索树, 红黑树
- 过滤器模式
场景题和项目
- Linux中,如何通过端口查进程,如何通过进程查端口
- 简述GDB常见的调试命令,多线程下如何调试。core dump有没有遇到过,gdb怎么调试
linux如何设置core文件生成⭐⭐⭐⭐ - 用过哪些工具检测程序性能,如何定位性能瓶颈的地方
- netstat tcpdump等
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!