PAC学习理论
当使用机器学习方法来解决某个特定问题时, 通常靠经验或者多次试验来选择合适的模型、 训练样本数量以及学习算法收敛的速度等 . 但是经验判断或多次试验往往成本比较高, 也不太可靠 , 因此希望有一套理论能够分析问题难度、 计算模型能力 , 为学习算法提供理论保证 , 并指导机器学习模型和学习算法的设计. 这就是计算学习理论 . 计算学习理论 ( Computational Learning Theory) 是机器学习的理论基础 , 其中最基础的理论就是 可能近似正确 ( Probably Approximately Correct, PAC ) 学习理论 .
机器学习中一个很关键的问题是期望错误和经验错误之间的差异,称为 泛化错误 ( Generalization Error ). 泛化错误 在有些文献 中也指 期望错误 ,指在未知样本上的错误. 泛化错误可以衡量一个机器学习模型𝑓 是否可以很好地泛化到未知数据.
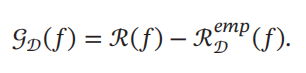



本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!