评分卡模型建模、WOE分箱以及模型评估

向AI转型的程序员都关注了这个号👇👇👇
评分卡的种类——ABC卡
A卡(Application score card)申请评分卡,贷前,一般可做贷款0-1年的信用分析
B卡(Behavior score card)行为评分卡, 贷中,在申请人有了一定行为后,有了较大数据进行的分析,一般为3-5年
C卡(Collection score card)催收评分卡,贷后,需加入催收后客户反应等属性数据
FICO信用分
1、FICO信用分简介
FICO信用分是最常用的一种普通信用分。由于美国三大信用局都使用FICO信用分,每一份信用报告上都附有FICO信用分,以致FICO信用分成为信用分的代名词。该分数是一个[300,850]区间的分数段。
信用评分达到680分以上,贷款方就可以认为借款人的信用卓著,可以毫不迟疑地同意发放款;信用评分低于620分,贷款方或者要求借款人增加担保,或者干脆寻找各种理由拒绝贷款;如果借款人的信用评分介于620-680分之间,贷款方就要作进一步的调查核实,采用其它的信用分析工具,作个案处理。
2、FICO信用分的评判因素
部分评判标准和影响因素(变量):
(1)信用偿还历史(占总影响因素的35%):
各种信用账户的还款记录(信用卡、零售账户 、分期偿还贷款、金融公司账户、抵押贷款)、公开记录及支票存款记录(破产记录、丧失抵押品赎回权记录、法律诉讼事件、留置权记录及判决)、逾期偿还的具体情况(逾期的天数、未偿还的金额、逾期还款的次数和逾期发生时距现在的时间长度等)
(2)信用账户数(占总影响因素的30%):
分析对于一个客户, 究竟多少个信用账户是足够多的, 从而能够准确反应出客户的还款能力
(3)信用账龄(占总因素的15%):
该用户信用历史越长,FICO信用分越高。该项因素主要指信用账户的账龄,也包括新开立的信用账户的账龄, 以及平均信用账户账龄。
(4)新开立的账户(占总因素的10%):
在很短时间内开立多个信用账户的客户具有更高的信用风险, 尤其是那些信用历史不长的人。该类因素包括:新开立的信用账户数、新开立的信用账户账龄、目前的信用申请数量。
(5)在使用的信用类型(占总因素的10%):
主要分析客户的信用卡账户、零售账户、分期付款账户、金融公司账户和抵押贷款账户的混合使用情况, 具体包括: 持有的信用账户类型和每种类型的信用账户数。
数据准备
1、需要排除异常行为
销户、按条例拒绝、特殊账户(卡丢失、死亡、未成年、出国、员工账户、VIP账户);
2、解释指标的选择
(1)申请评分所需指标:参考上述FICO信用分的 评判标准
(2)行为评分所需指标:
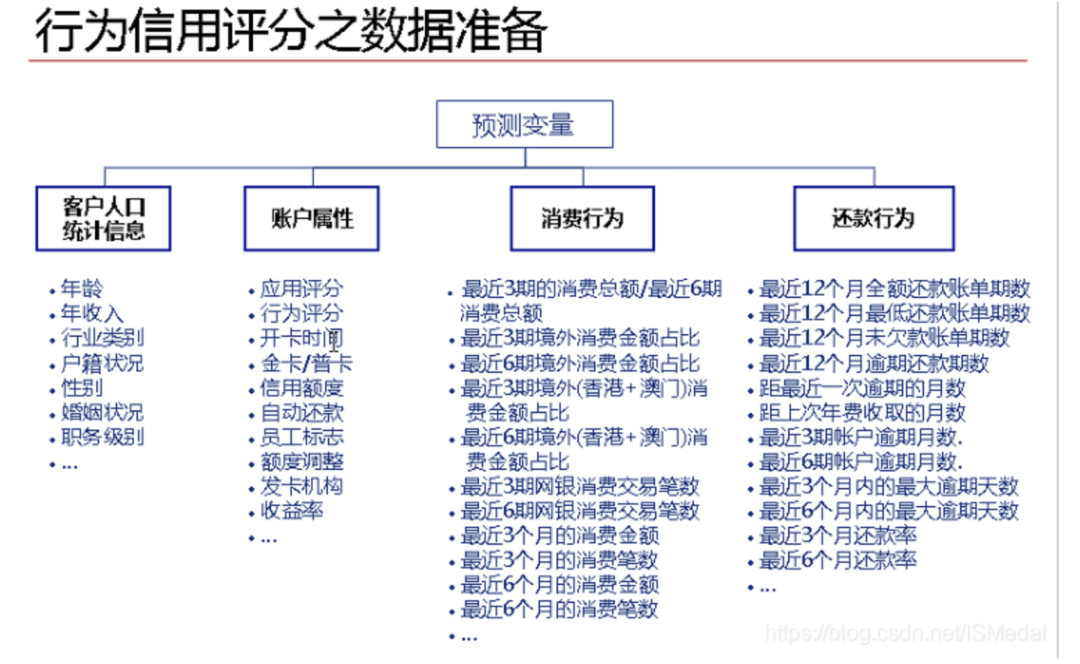
3、目标变量的确立
目标变量为坏客户/好客户
坏客户:观察窗口内,逾期60/90/120天的用户
因此在此之前还需要确定观察窗口和违约时间的长短。
变量分箱——WOE转换
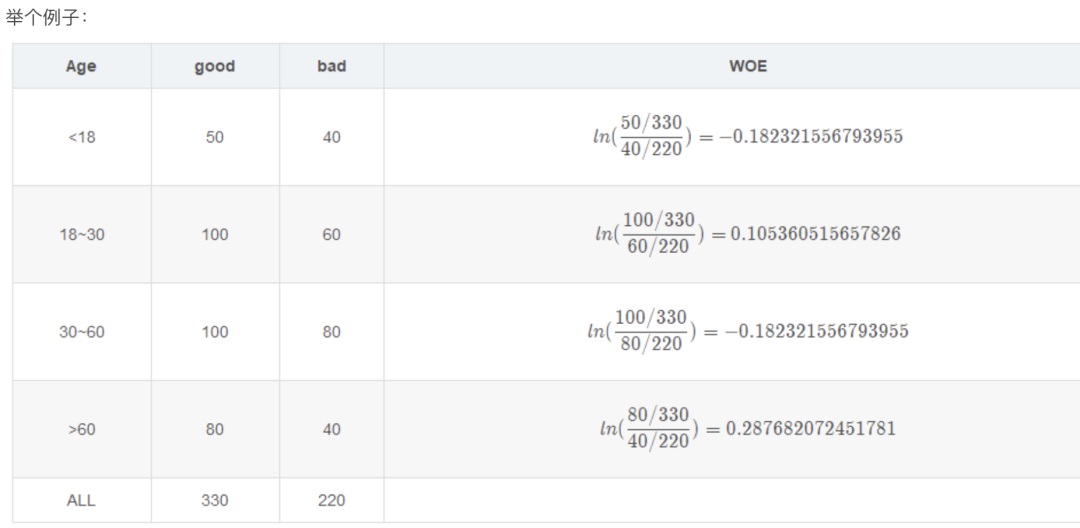
WOE为优势比,将各个连续变量细分为若干组后,每组的WOE为:

*注意:”该组好客户占比“指的是该组好用户数/所有的好用户数
1、如果计算得到的WOE与违约概率具有某种线性关系,或者WOE与目标变量之间的有U型或者倒U型的非线性关系,说明该种分组方式合理,否则需要调整分组方式,如果无论怎么分组均无法达到上述两种情况,说明该变量对目标变量的解释性较弱。
2、模型拟合出来的自变量系数应该都是正数,如果结果中出现了负数,应当考虑是否是来自自变量多重共线性的影响——可以计算各个变量的VIF值,删去那些具有明显多重共线性的变量。
3、WOE编码之后,自变量其实具备了某种标准化的性质,也就是说,自变量内部的各个取值之间都可以直接进行比较(WOE之间的比较),而不同自变量之间的各种取值也可以通过WOE进行直接的比较。
4、如果遇到分箱后某组的坏客户数量为0,则需要合并分箱,保证每个分箱中必须同时包含好用户和坏用户
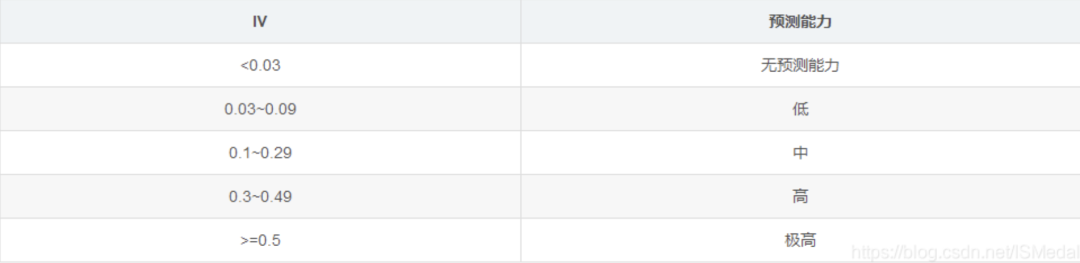
此外,IV值(information value)衡量的是某一个变量的信息量,可用来表示一个变量的预测能力。公式如下(假设该变量经过变量分箱后被分为m组):

不同IV值表示的变量的预测能力大小如下表:


模型的评价——模型区分度
1、KS值
KS的计算步骤如下:
计算每个评分区间的好坏用户数。
计算每个评分区间的累计好用户数占总好用户数比率(good%)和累计坏账户数占总坏账户数比率(bad%)。
计算每个评分区间累计坏账户占比与累计好账户占比差的绝对值(累计good%-累计bad%),然后对这些绝对值取最大值即得此评分卡的K-S值。
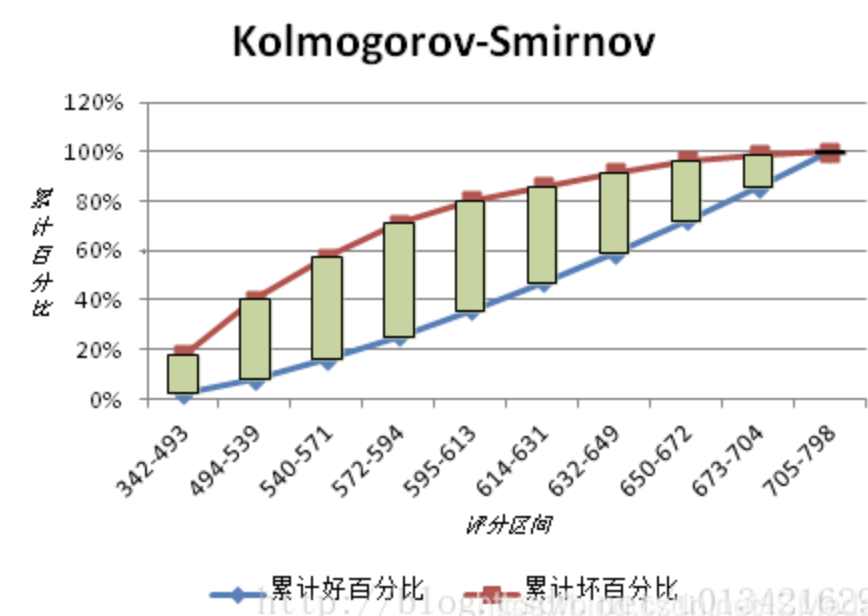
KS用于模型风险区分能力进行评估,好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。
2、GINI指数
GINI系数的计算步骤如下:
计算每个评分区间的好坏账户数。
计算每个评分区间的累计好账户数占总好账户数比率(累计good%)和累计坏账户数占总坏账户数比率(累计bad%)。
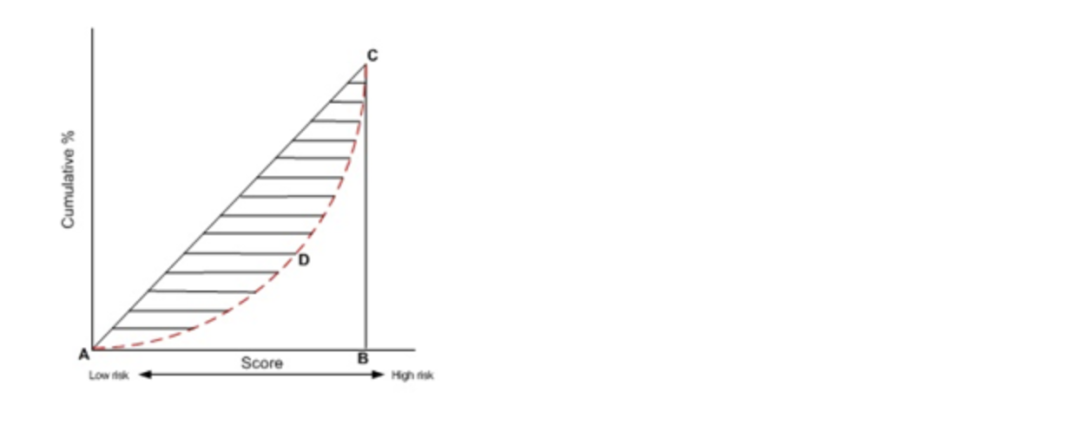
按照累计好账户占比和累计坏账户占比得出下图所示曲线ADC。
计算出图中阴影部分面积,阴影面积占直角三角形ABC面积的百分比,即为GINI系数。
【注】本文引用了以下文章:
https://blog.csdn.net/sinat_26917383/article/details/51721107
https://blog.csdn.net/sscc_learning/article/details/78591210
https://blog.csdn.net/u013421629/article/details/78217498
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
《深度学习:基于Keras的Python实践》PDF和代码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!