Scala比较理解map、flatMap
写在前面:首先问几个问题,如果以下问题大家都能轻松的说明白,那么说明你对这几种方法已经熟练掌握了。如果对这些问题,你还有疑问,那么我希望通过这篇文章能让你不再有疑问。
1、Scala中map、flatMap的区别是什么?
2、map/flatMap 和filter/where在处理数据上的区别又是什么?
3、map和UDF在处理数据上的区别是什么?map(函数)的方法是否等同于UDF?如果等同,那么UDF的优势是什么,适用场景是什么?
4、flatMap() 和UDTF有什么区别? 和SQL中的explore函数有什么区别?同样的,如果它们等同,那么UDTF的优势是什么,适用场景是什么?
* 1、map 接受一个函数可以改变数据的列数,如3列的输入数据经过map后变成5列或者2列。但map改变不了行数。 flatMap可以改变行数,但改变不了列数。
* 2、filter\where对输入数据做过滤,可以筛选哪些可以通过、哪些不可以通过。它也是改变输入数据的行数,但改变不了列数。
0、创建一个DataFrame,我们接下来都使用这个简单的DataFrame来做说明
//创建一个DataFrame
val df =spark.createDataFrame(Seq((1,"Hello world"),(2,"Toby Gao"))).toDF("id","words")
df.show()
这是一个2行2列的DataFrame。
大家在下面的代码中注意看将这个2*2的DataFrame使用了map、flatMap后生成的是几行几列的DataFrame。比较之后,大家会更加的清楚map、flatMap的作用和区别。
1、写一个map函数,对words列按照空格“ ”拆分生成多列
示例一:对第二列进行拆分,输出1列 (一行入,一行出;一列进,一列出。结果DF是2*1的)
(注:当我们不用.toDF()来声明Schema列名时,Spark对列自动命名为value。当然建议是进行命名,我这里就是为了展示map的实现结果而故意没有命名的。)
df.map{row =>{row.getAs[String]("words").split(" ")}}.show()
示例二:对第二列进行拆分,输出两列 (一行入,一行出;两列进,两列出。结果DF是2*2的)
df.map{row =>{val id=row.getAs[Int]("id")val words = row.getAs[String]("words")(id,words.split(" "))}}.toDF("id","word_list").show()
示例三:对第二列进行拆分,输出三列 (一行入,一行出;两列进,三列出。结果DF是2*3的)
df.map{row =>{val id=row.getAs[Int]("id")val words = row.getAs[String]("words")(id,words.split(" ")(0),words.split(" ")(1))}}.toDF("id","word1","word2").show()
示例四:对第二列进行拆分,输出4列 (一行入,一行出;两列进,四列出。结果DF是2*4的)
//定义拆分函数
def SepTab(Astring: String):Array[String] = {Astring.split(" ")}//使用map方法调用拆分函数对指定的列进行拆分
df.map{row =>{val id=row.getAs[Int]("id")val words = row.getAs[String]("words")val wordArray = SepTab(words)(id,wordArray,wordArray(0),wordArray(1))}}.toDF("id","word_list","word1","word2").show()
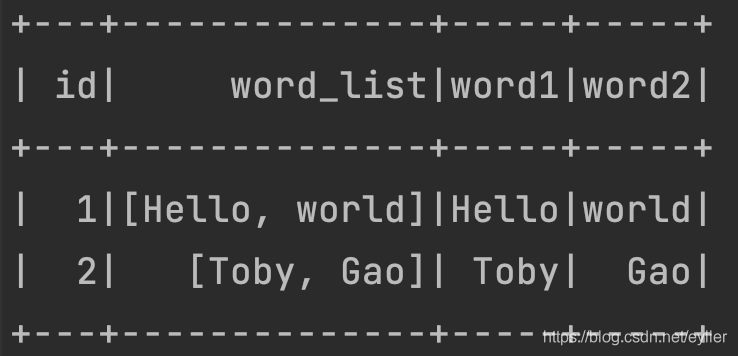
注:通过比较输入、输出DataFrame的行数、列数,大家可以发现,map()函数保持输入DataFrame的行数不变,而列数却是可以任意变化的。这是很重要的特点!!!
2、写一个flatMap对words列按照空格“ ”拆分后拉直
示例一:生成一列 (一行入,两行出;两列进,一列出。结果DF是4*1的)
df.flatMap{row =>{row.getAs[String]("words").split(" ")}}.toDF("word").show() 
或者
df.flatMap{row =>{(row.getAs[Int]("id").to(3))}}.toDF("id_num").show() 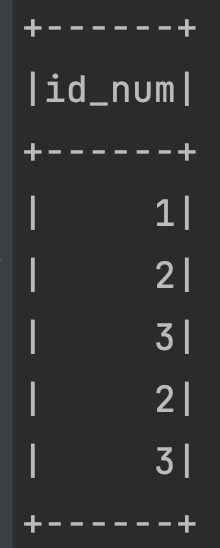
示例二: 不能直接将id列和word列一起生成两列。(注:这点和explode函数很像)
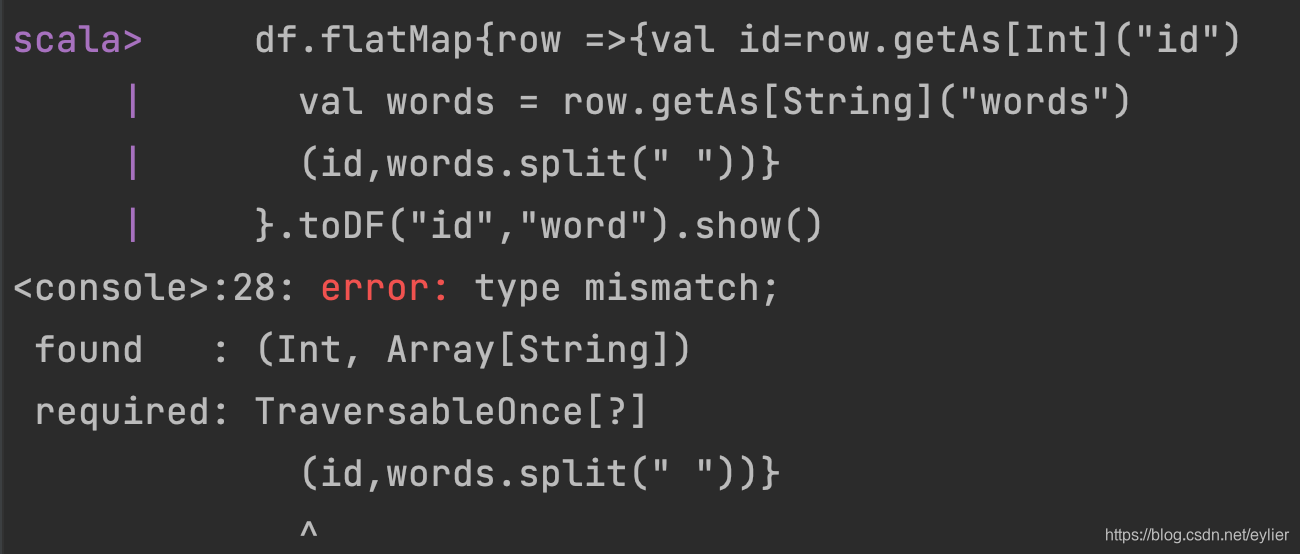
但可以使用zip方法,将两个可迭代的数据映射到一起后,再输出。
示例三:使用zip方法实现flatMap多列的输出 (一行入,两行出;两列进,两列出。结果DF是4*2的)
df.flatMap{row =>{val id=row.getAs[Int]("id")val words = row.getAs[String]("words")Array(id,id).zip(words.split(" "))}}.toDF("id","word").show()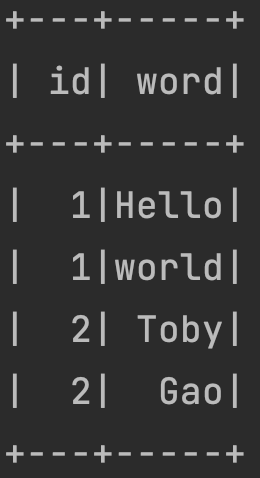
注:通过比较输入、输出DataFrame的行数、列数,大家可以发现,flatMap()函数即不保持输入DataFrame的行数不变,列数也可以任意变化的。但如果不考虑我这里使用了zip的方法,那么可以说flatMap函数将m*n的输入DF变成k*1的输出DF。即不保持行数,但保持1列。
写在最后:
通过以上的代码和结果示例,我们基本清楚了map 、flatMap各自的功能 和使用方法。
我们大可以将示例中的函数替换成其他任意的函数,将这两个方法的作用放大来满足千奇百怪的业务需求。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!