Elasticsearch-IK分词器源码学习01
Elasticsearch-IK分词器源码学习01
- 一、说明
- 1、源码参考
- 2、IDE
- 3、Demo
- 二、整体流程
- 1、构建字典
- 1.1、DictSegment类基本介绍
- 1.2、DictSegment类lookforSegment()构建字典
- 2、分词
- 2.1、分词入口
- 2.2、IKSegmenter类
- 2.3、AnalyzeContext类
- 2.3.1、fillBuffer()方法读取输入
- 2.3.2、Lexeme getNextLexeme()方法
- 2.4、CJKSegmenter类
- 2.4.1、Hit类
- 2.4.2、字符类型识别
- 2.4.3、实际分词整体流程
- 2.5、IKArbitrator类
- 1. 路径文本长度和([上海、人民],加起来长度为4)长的优先;
- 2. 词元个数越少越优先;
- 3. 路径跨度越大越优先([上海、人民],跨度为下标0-4,长度为4);
- 4. 路径跨度越靠后的越优先([上海、人民】,跨度最后为下标4),依据:根据统计学结论,逆向切分概率高于正向切分,因此位置越靠后的优先;
- 5. 词长越平均越好:
- 6. 词元位置权重比较,越大的越优先;
- 三、总结
一、说明
本文是简单介绍IK分词器的源码,整体的结构,不涉及详细具体的源码分析,请知晓。
1、源码参考
地址:git@github.com:medcl/elasticsearch-analysis-ik.git
tag为:5.3.2
2、IDE
Intellij idea+Maven 3.0
3、Demo
package iktest;import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.elasticsearch.common.settings.Settings;
import org.junit.Test;
import org.wltea.analyzer.cfg.Configuration;
import org.wltea.analyzer.lucene.IKTokenizer;import java.io.IOException;
import java.io.StringReader;
import java.util.concurrent.ConcurrentHashMap;public class IKTestOne {public final String TEXT_Chinese = "上海迪士尼乐园";@Testpublic void test1() throws IOException {Settings settings = Settings.EMPTY;Configuration conf = new Configuration(null, settings);//use ik_smartconf.setUseSmart(true);IKTokenizer tokenizer = new IKTokenizer(conf);tokenizer.setReader(new StringReader(TEXT_Chinese));tokenizer.reset();CharTermAttribute term = tokenizer.addAttribute(CharTermAttribute.class);PositionIncrementAttribute postIncr = tokenizer.addAttribute(PositionIncrementAttribute.class);int position = 0;while (tokenizer.incrementToken()) {int increment = postIncr.getPositionIncrement();if (increment > 0) {position = position + increment;System.out.println();System.out.print(position + ": ");}System.out.print("[" + new String(term.buffer(), 0, term.length()) + "]");}System.out.println();}@Testpublic void testConcurrentMapSize() {ConcurrentHashMap map = new ConcurrentHashMap(4);System.out.println(map);}
}
输出:
1: [上海]
2: [迪士尼]
3: [乐园]
二、整体流程
整体流程可以分为2部分:构建字典、分词,以下逐个介绍。
1、构建字典
涉及如下类:
| 编号 | 类 |
|---|---|
| 1 | org.wltea.analyzer.cfg.Configuration |
| 2 | org.wltea.analyzer.dic.Dictionary |
| 3 | org.wltea.analyzer.dic.DictSegment |
Configuration类决定一些配置项,这里只是涉及smart分词:
conf.setUseSmart(true);
Dictionary类是字典主类,其默认包含如下子字典:
| 编号 | 字段 | 说明 | 字典位置 | 示例 |
|---|---|---|---|---|
| 1 | _MainDict | 主字典 | config/main.dic | 上海,迪士尼 |
| 2 | _SurnameDict | config/surname.dic | 人姓字典 | 丁,万 |
| 3 | _QuantifierDict | config/quantifier.dic | 量词字典 | 指,支 |
| 4 | _SuffixDict | config/suffix.dic | 后缀字典 | 乡,区 |
| 5 | _PrepDict | config/preposition.dic | 介词字典 | 不,也 |
| 6 | _StopWords | config/stopword.dic | 停用词字典 | a,an |
Dictionary类的主要作用就是为了加载这些词典到内存中,供后续分词使用,下面以_MainDict为例来讲解。
1.1、DictSegment类基本介绍
_MainDict字段类型为DictSegment,其包含如下主要属性:
| 编号 | 字段 | 是否静态 | 含义 |
|---|---|---|---|
| 1 | Map | 是 | 存储字符字典,避免重复构建对象 |
| 2 | int ARRAY_LENGTH_LIMIT = 3 | 是 | 当下续内容个数大于3时使用map结构,否则使用数组结构 |
| 3 | Map | 否 | map结构字典存储 |
| 4 | DictSegment[] childrenArray | 否 | 数组结构字典存储 |
| 5 | Character nodeChar | 否 | 当前节点字符 |
| 6 | int storeSize | 否 | 下续内容个数 |
| 7 | int nodeState | 否 | 状态,0-没有终止,1-终止。比如针对词项[迪士尼],迪:0,士:0,尼:1 |
该类主要构建字典的方法为:fillSegment(),参数为将要构建的词项,比如[迪士尼]。其主要思路为:
- 将单个字符经过charMap,如不存在则放入,存在则获取出来;
- 查找当前节点下续节点是否有该字符数据存在,不存在则创建,其主要调用lookforSegment()方法,其接受一个字符作为参数。
1.2、DictSegment类lookforSegment()构建字典
- 判断是否当前大小storeSize大于ARRAY_LENGTH_LIMIT,如是的话则使用map字段childrenMap,否则使用childrenArray;
- 如果是map则直接获取当前字符对应的值,否则使用二分法查找childrenArray,找到下级的DictSegment;
- 如果找到则返回,没有找到则创建并添加进对应的字段中。
整体[上海迪士尼]的内存结构如下:
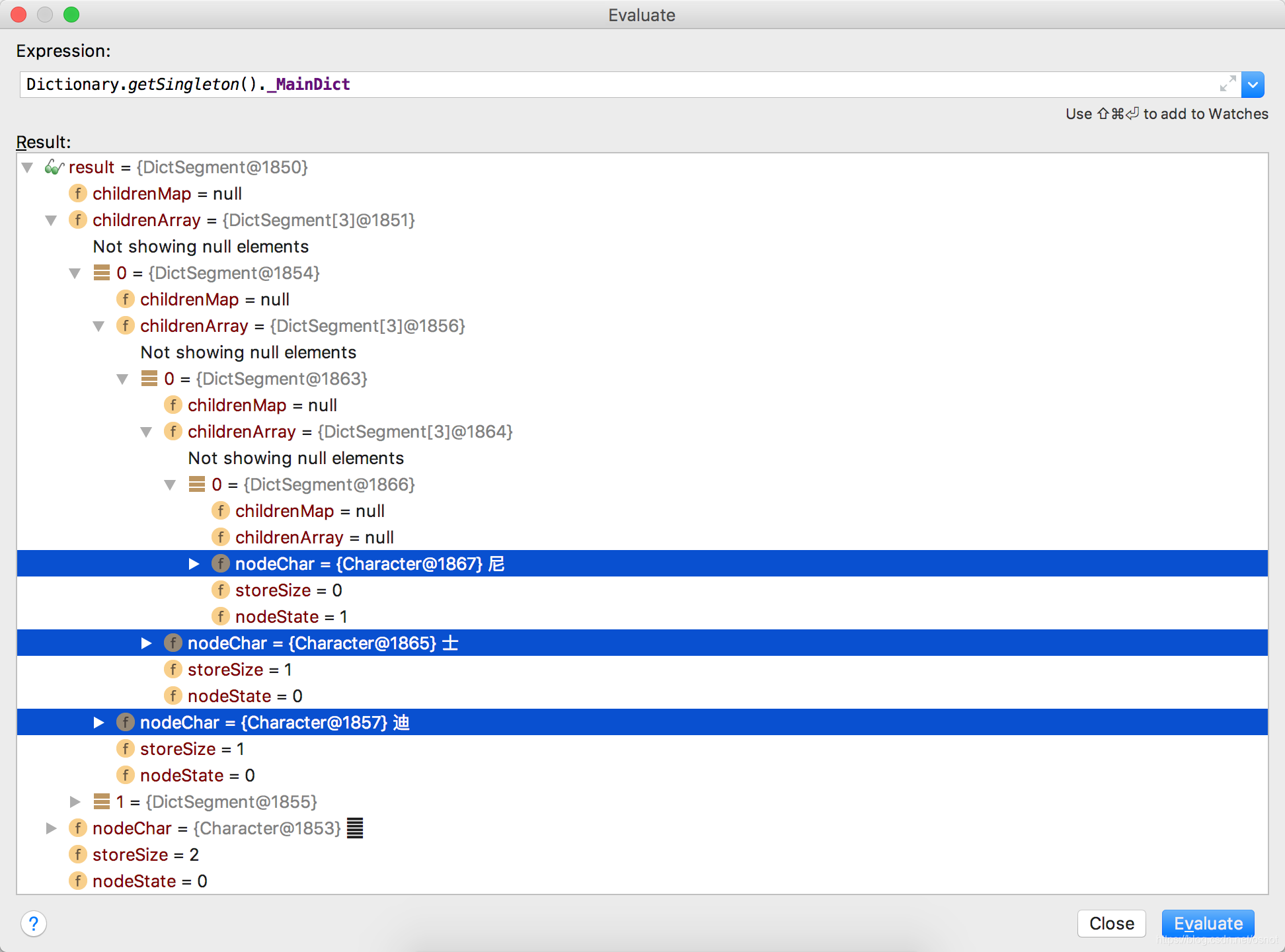
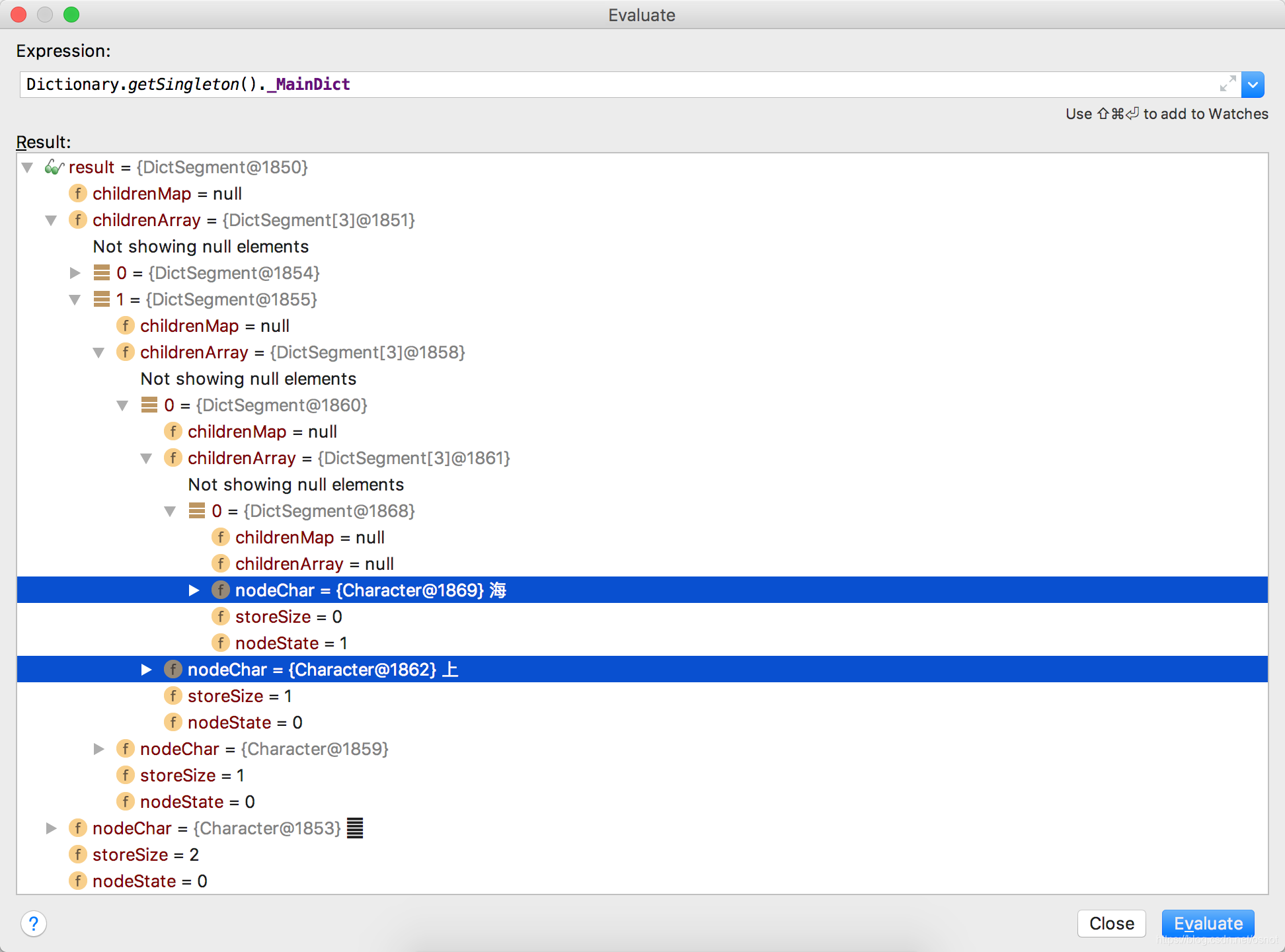
可以看到其内部是嵌套结构,比较简单。
至此构建完成。
2、分词
ElasticSearch底层使用的Lucene,IK分词器是基于ElasticSearch的分词插件规范来开发的,主要用到的几个类如下:
| 编号 | 类 | 说明 |
|---|---|---|
| 1 | org.apache.lucene.analysis.Tokenizer | lucene底层分词器抽象父类 |
| 2 | org.wltea.analyzer.lucene.IKTokenizer | IK分词器适配类,继承Tokenizer类 |
| 3 | org.wltea.analyzer.core.IKSegmenter | IK分词器主类 |
| 4 | org.wltea.analyzer.core.ISegmenter | IK子分词器接口 |
| 5 | org.wltea.analyzer.core.AnalyzeContext | IK分词器上下文类,每次分词有一个独立上下文实例 |
| 6 | org.wltea.analyzer.core.IKArbitrator | IK歧义决断器,按照指定规则进行歧义决断,比如假设[上海人民银行]分词结果:1-[上海、人民银行]2-[上海人、人民、银行],会进行决断输出其中一种结果 |
| 7 | org.wltea.analyzer.core.Lexeme | 分词后的单个词元,比如[上海] |
| 8 | org.wltea.analyzer.core.QuickSortSet.Cell | Lexeme类的链表节点包装类 |
| 9 | org.wltea.analyzer.core.QuickSortSet | Lexeme的双链表,使用Cell类进行前后指针包装 |
| 10 | org.wltea.analyzer.core.LexemePath | 继承自QuickSortSet,用于存放词元组合链表 |
| 11 | org.wltea.analyzer.core.CJKSegmenter | 中日韩子分词器类,实现ISegmenter接口 |
2.1、分词入口
入口是通过循环IKTokenizer.incrementToken()得到分词结果,其内部调用IKSegmenter _IKImplement字段的next()方法来进行分词,如果其返回值不为空则incrementToken()可以继续分词,否则终止。
2.2、IKSegmenter类
其具有如下字段:
| 编号 | 字段 | 说明 |
|---|---|---|
| 1 | AnalyzeContext context | 分词器上下文 |
| 2 | List segmenters | 子分词器列表,这里主要讨论CJKSegmenter |
| 3 | IKArbitrator arbitrator | IK歧义决断器 |
| 4 | Configuration configuration | IK配置类,构造函数赋值 |
接上节,其next()方法内部做了如下事情:
- 循环获取context.getNextLexeme()获取Lexeme分词词元,直到输入读取完成,注意:为空时循环;
- 遍历子分词器void analyze(AnalyzeContext context)方法进行分词,分词完成后移动上下文输入串到下一个字符,直到读取完所有的输入;
- 重置子分词器,为下轮循环进行初始化;
- 对该次分词结果进行歧义决断
this.arbitrator.process(context, configuration.isUseSmart()); - 将分词结果输出到结果集results,并处理未切分的单个CJK字符;
- 结束1循环后,返回1分词词元。
下面逐个讲解。
2.3、AnalyzeContext类
AnalyzeContext类具有一些和输入有关的字段,剩余字段如下:
| 编号 | 字段名 | 说明 |
|---|---|---|
| 1 | Set buffLocker | 子分词器锁,该集合非空,说明有子分词器在占用segmentBuff |
| 2 | QuickSortSet orgLexemes | 原始分词结果集合,未经歧义处理 |
| 3 | Map | LexemePath位置索引表,在输入字符串中的位置 |
| 4 | LinkedList results | 最终的分词结果 |
| 5 | Configuration cfg | IK配置类,构造函数中赋值 |
2.3.1、fillBuffer()方法读取输入
每次读取4096个字符,填充到char[] segmentBuff字段中,并使用int cursor记录当前分词进度在segmentBuff的位置,使用int buffOffset记录在总的输入中的分词进度。
2.3.2、Lexeme getNextLexeme()方法
该方法不做分词处理,只是读取results结果第一个,进行:
- 数量词合并
- 判断当前result是否完全停用词,是的话读取results下一个,继续;
- 不是停用词则输出
result.setLexemeText(String.valueOf(segmentBuff , result.getBegin() , result.getLength()));
故此方法是用于最终输出结果使用,其results值是在IKSegmenter.next()方法后续处理中赋值的。
2.4、CJKSegmenter类
接IKSegmenter.next()方法第2步进行分词。
该类其含有一个字段:List tmpHits,用于存储临时得到的分词结果,Hit类介绍如下。
2.4.1、Hit类
其用于存放临时处理结果,主要有如下字段:
| 编号 | 字段 | 说明 |
|---|---|---|
| 1 | int hitState | 当前匹配状态,分为:不匹配,完全匹配,前缀匹配;可同时设置2个值 |
| 2 | DictSegment matchedDictSegment | 当前匹配到的字典项 |
| 3 | int begin | 词段的开始位置 |
| 4 | int end | 词段的结束位置 |
2.4.2、字符类型识别
AnalyzeContext在读取当前字符后会进行字符类型判断,得到该字符属于如下类别之一:
| 编号 | 类型 | 说明 |
|---|---|---|
| 1 | CharacterUtil.CHAR_USELESS | 无法识别不做处理的字符类型 |
| 2 | CharacterUtil.CHAR_ARABIC | 阿拉伯数字 |
| 3 | CharacterUtil.CHAR_ENGLISH | 英文26个字母,包括大小写 |
| 4 | CharacterUtil.CHAR_CHINESE | 中文字符类型,包括:Character.UnicodeBlock.CJK_UNIFIED_IDEOGRAPHS、CJK_COMPATIBILITY_IDEOGRAPHS、CJK_UNIFIED_IDEOGRAPHS_EXTENSION_A |
| 5 | CharacterUtil.CHAR_OTHER_CJK | 全角数字或日韩:Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS;韩文:Character.UnicodeBlock.HANGUL_SYLLABLES、HANGUL_JAMO、HANGUL_COMPATIBILITY_JAMO;日文:Character.UnicodeBlock.HIRAGANA、KATAKANA、KATAKANA_PHONETIC_EXTENSIONS |
2.4.3、实际分词整体流程
analyze(AnalyzeContext context)分词步骤:
- 如果当前字符是CHAR_USELESS,不进行处理,并将tmpHits字段清空(认为该段分词结束);
- 如果context的缓冲区为空,说明该次分段读取已经结束,也将tmpHits字段清空;
- 如果是其他字符类型则进行分词,详见如下流程。
首先当前是否已经在处理中,比如输入上海,现在读取海时,上已经读取并识别为词典项了(对应tmpHits不为空),分为如下两种情况处理:
如果没有词在处理中,底层调用DictSegment.match()进行该字符进行匹配(是从字典根部进行匹配)得到一个Hit对象,如该词项可以作为结束词则设置hitState为完全匹配;
然后继续判断其是否仍有接续词,如有则同时设置hitState为前缀词;
- 如找到且是完全匹配则将其构建为Lexeme对象,加入到context的orgLexemes字段中;
- 如果是前缀匹配,则同时入到tmpHits字段中;
如果词在处理中,则遍历tmpHits子项,按照当前词项进行继续查找(底层调用DictSegment.match()),比如tmpHits中包含[上]词典项,则继续查找其接续词典是否包含当前查找[海]字;
- 如找到且是完全匹配则将其构建为Lexeme对象,加入到context的orgLexemes字段中;如此时不再是前缀匹配则从tmpHits删除此词段;
- 如不匹配,则从tmpHits删除此词段;
即tmpHits保留此词段的前提是找到并前缀匹配;
至此子分词器分词结束,其最终的效果是将一个一个词段识别出来,构建为构建为Lexeme对象,并放入context.orgLexemes中,比如[上海迪士尼]:
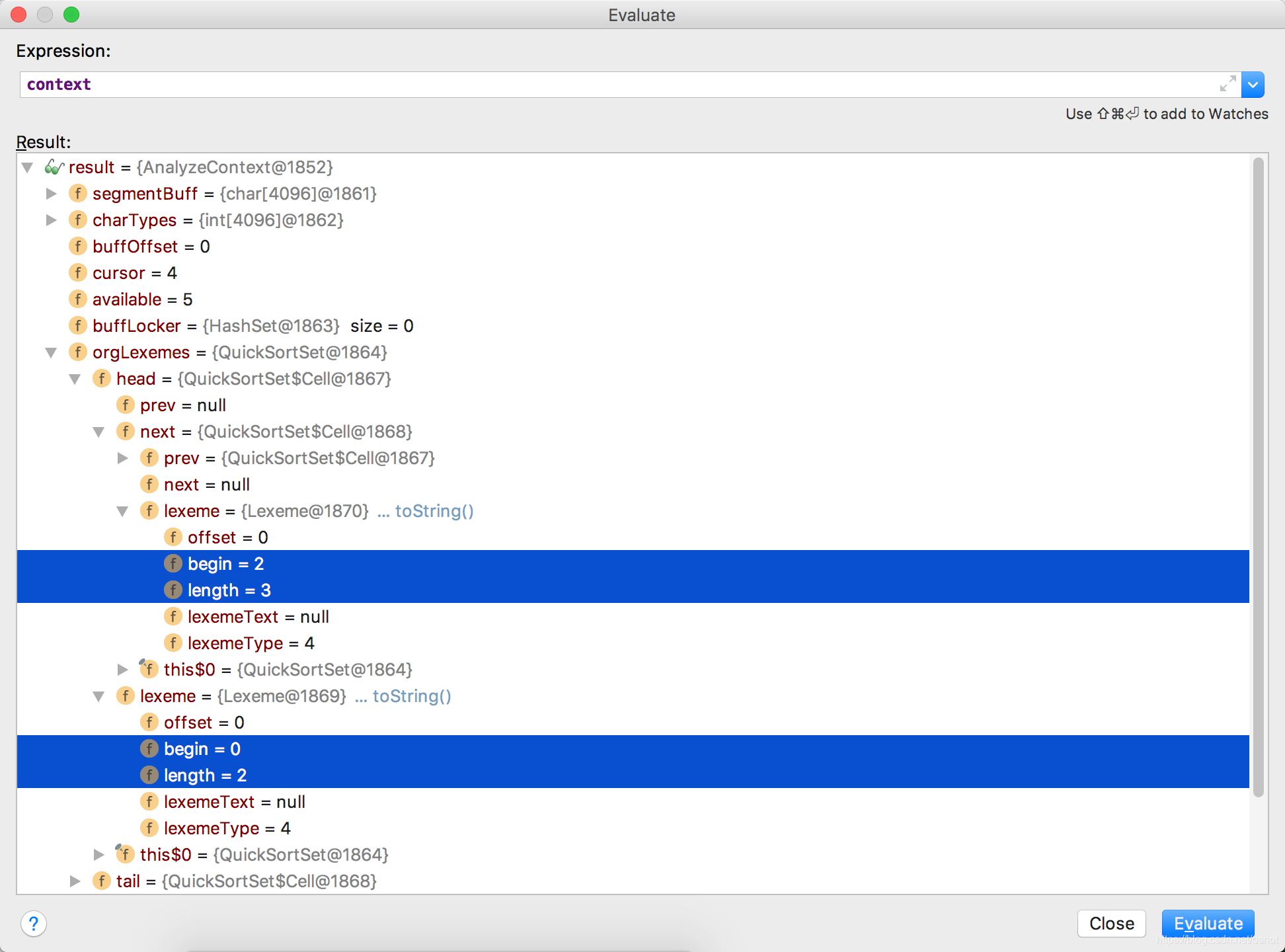
2.5、IKArbitrator类
然后进行IKSegmenter类next()方法第4步,进入歧义决断。
歧义决断主要是针对Lexeme词段进行决断,比如一个输入:上海人民银行,可以分词为:
| 编号 | 分词结果 |
|---|---|
| 1 | 上海人、民、银行 |
| 2 | 上海、人民、银行 |
此时应该如何决断?
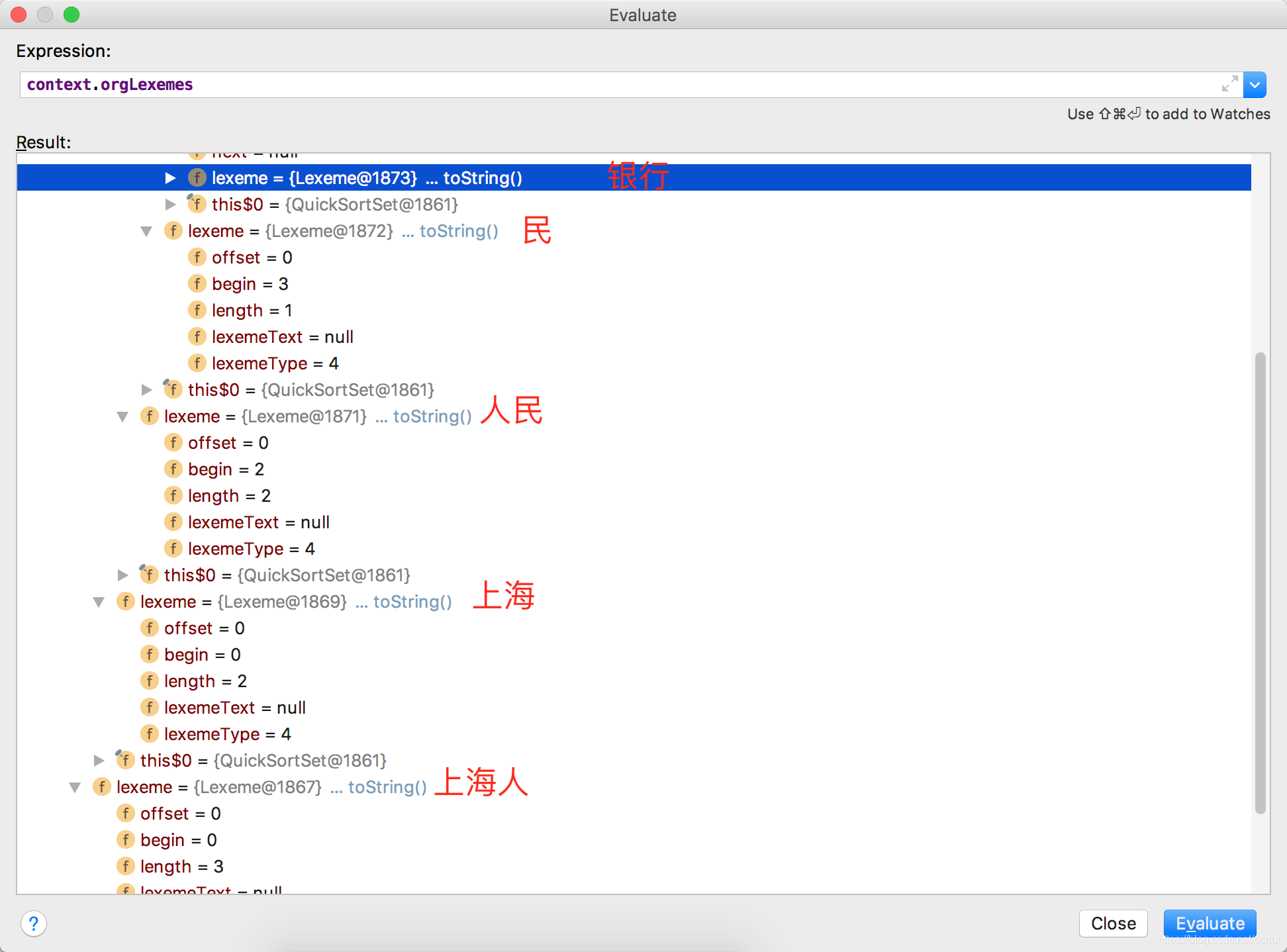
如上面所示一共5个Lexeme分为为:
| 编号 | 文本 | 开始位置 | 长度 |
|---|---|---|---|
| 1 | 上海人 | 0 | 3 |
| 2 | 上海 | 0 | 2 |
| 3 | 人民 | 2 | 2 |
| 4 | 民 | 3 | 1 |
| 5 | 银行 | 4 | 2 |
其处理步骤如下:
- 构建一个新的LexemePath crossPath,然后遍历context.orgLexemes,以下称为item;
- 判断当前crossPath和item是否有交集:(item开始位置在crossPath范围内)OR (crossPath开始位置在item范围内);
- 如有交集,则将item添加到crossPath(继承自QuickSortSet本身就是一个链表)中;否则进行不相交逻辑处理,取出crossPath的第一个Lexeme节点进行歧义处理,即当前已分词段已经形成一个相对独立的段,需要判别下其内部是否可以存在歧义,比如[上海人民银行],走到歧义处理时的crossPath为:

具体歧义处理步骤如下(IKArbitrator.judge(QuickSortSet.Cell lexemeCell , int fullTextLength)):
4. 创建一个候选路径集合:TreeSet
5. 然后遍历lexemeCell及后续节点,判断是否有交集(同3),如有交集则认为存在歧义,则放到Stack
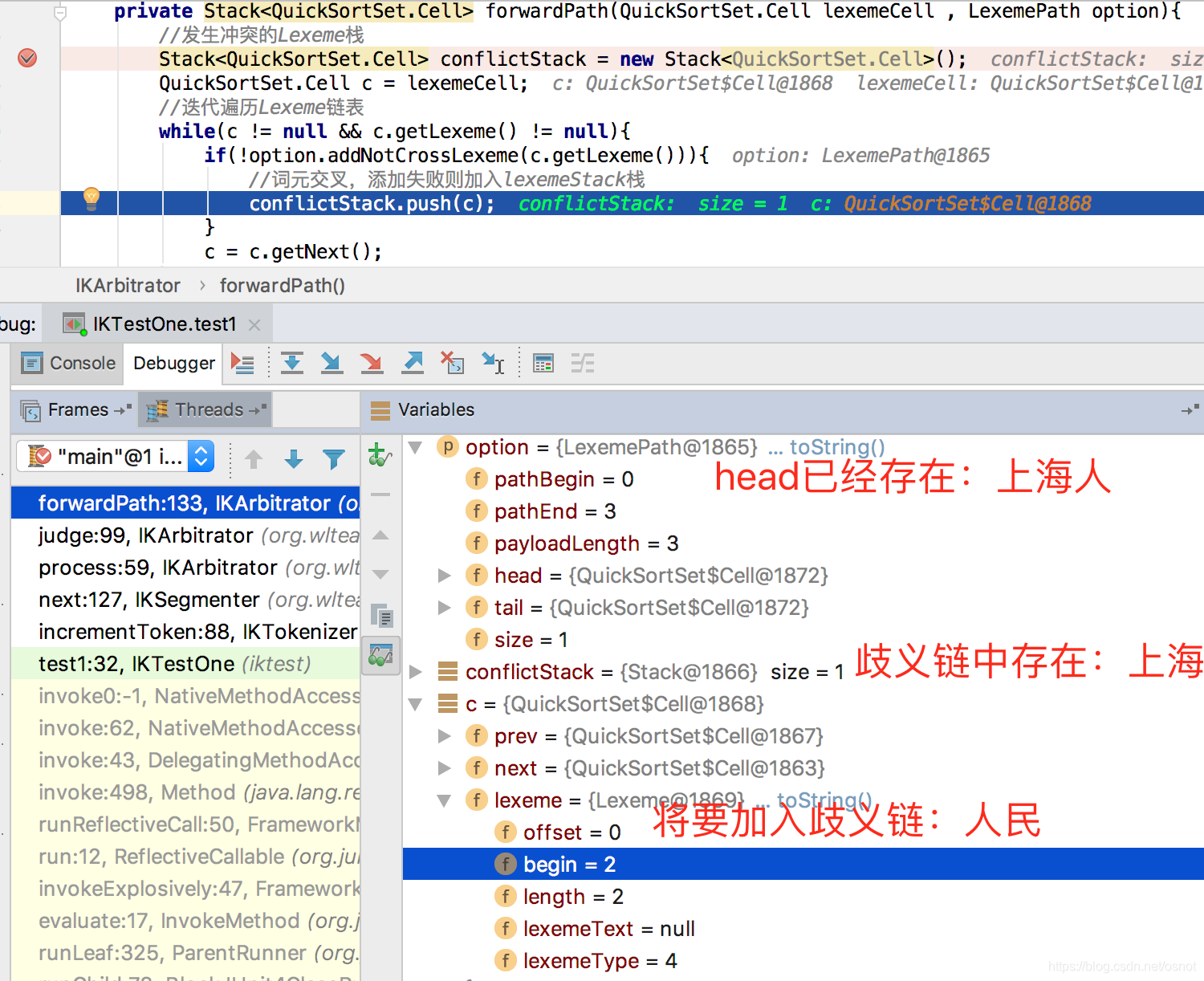
然后最终:
将option(后成为正常链)加入到pathOptions中,作为备选;
6. 遍历歧义链:取出第一个歧义词[人民](栈结构,后入先出),回滚正常链[上海人、民],直到正常链和[人民]没有交集,此case相当于正常链全部回滚完[];
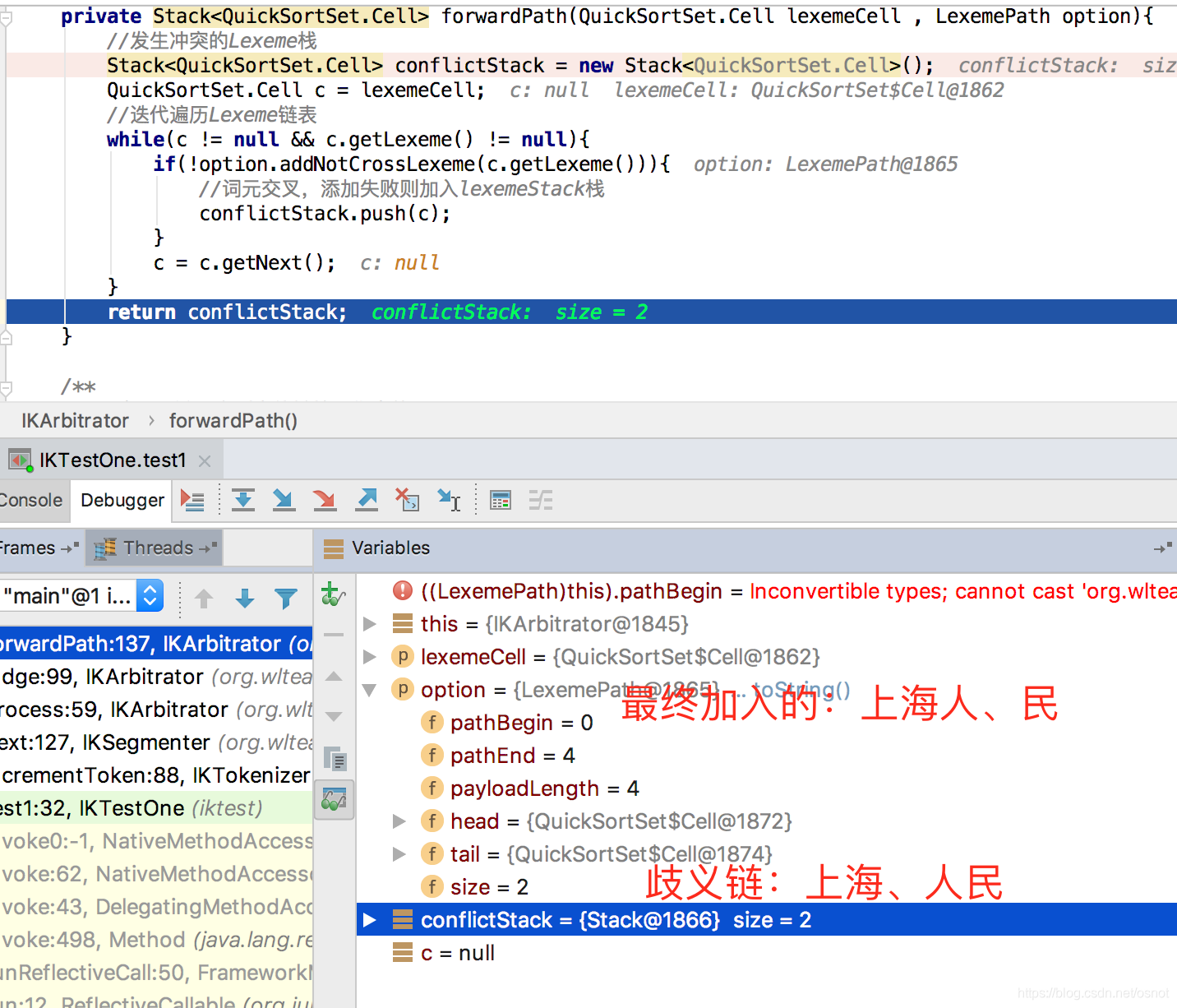
7. 然后以当前歧义词[人民]为head,遍历后续的节点,重复4、5操作,则遍历下一个节点[民]时,会出现新的歧义(但这个目前IK是忽略的,即只进行一次歧义决断):
将上面产生的正常链[人民]作为一个新的备选;然后接着6遍历下一个歧义词[上海];
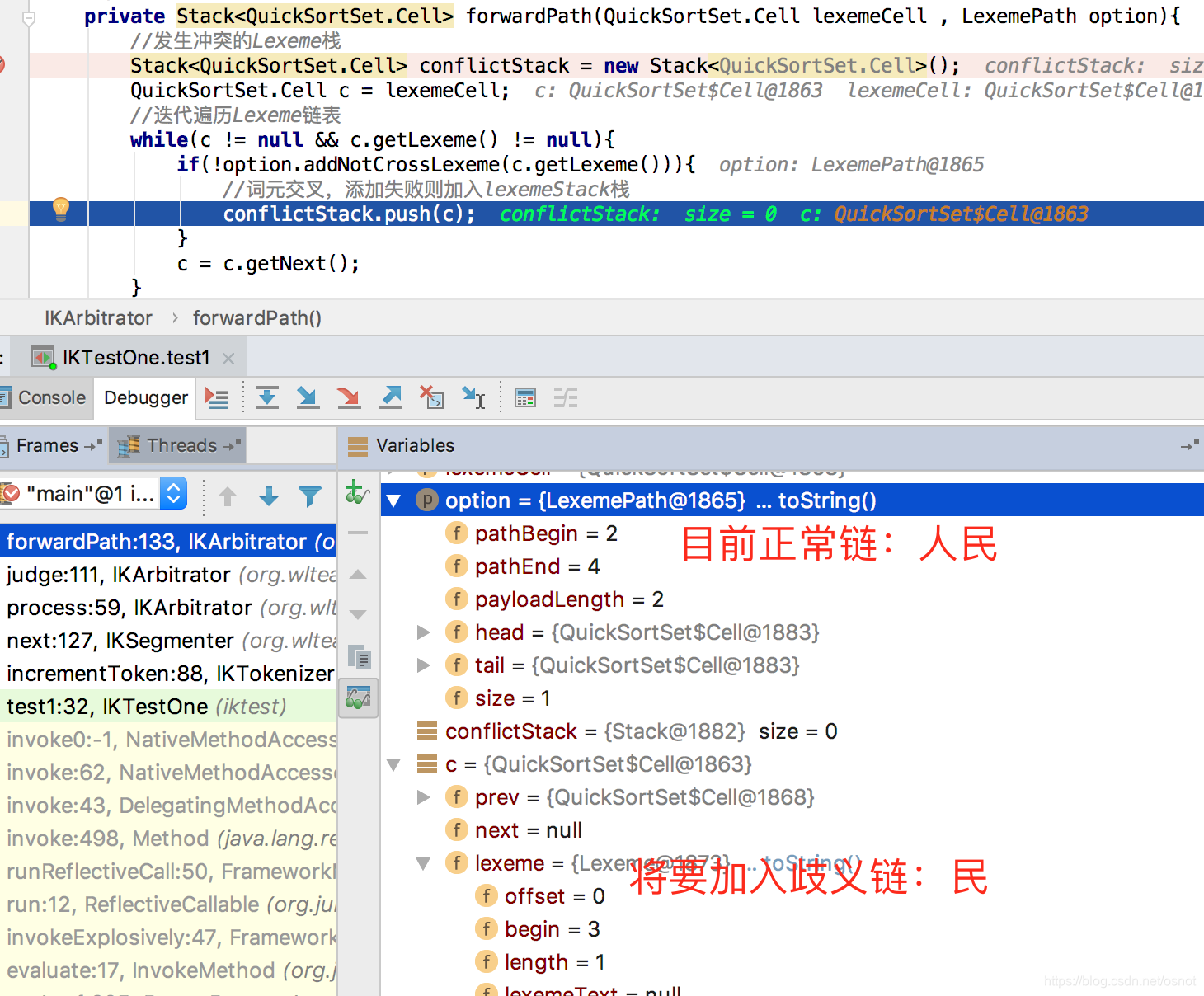
8. 接续第6步,当前歧义词[上海],当前的正常链[人民],接着回滚正常链直到两者没有交集,此场景是无需回滚;
9. 再次构造新路径,重复7以[上海]为head开始遍历,最后有歧义的[人民、民]被加入歧义链(会被忽略),其中人民是因为已经存在正常链中,得到新的链路:[上海、人民]:
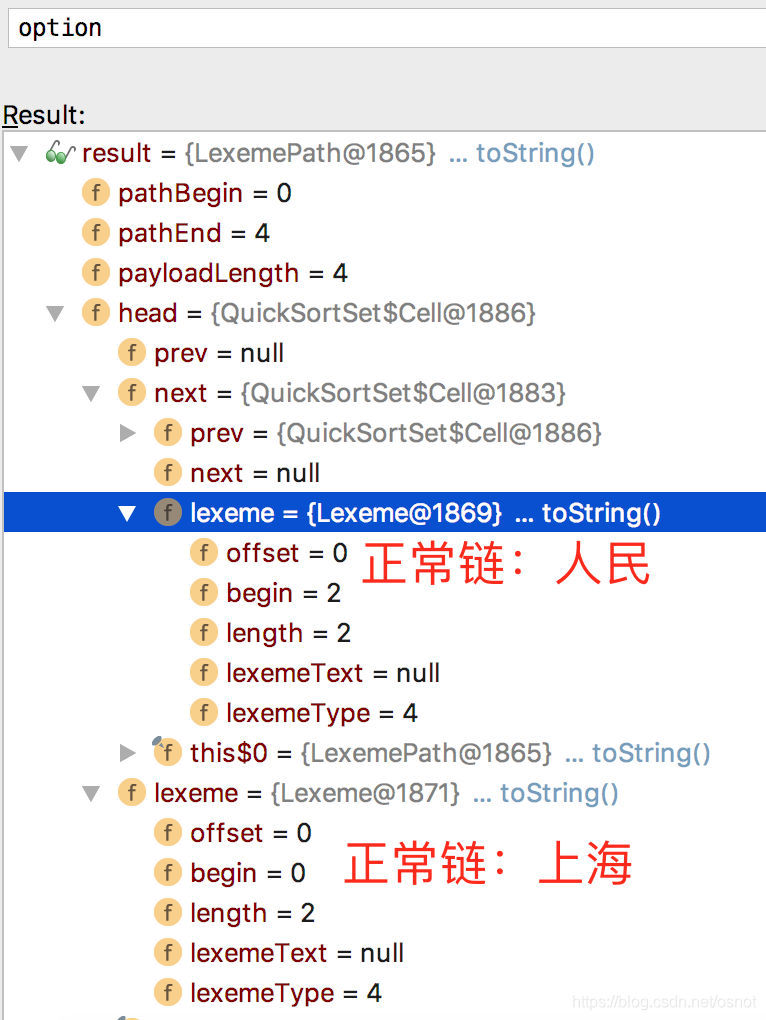
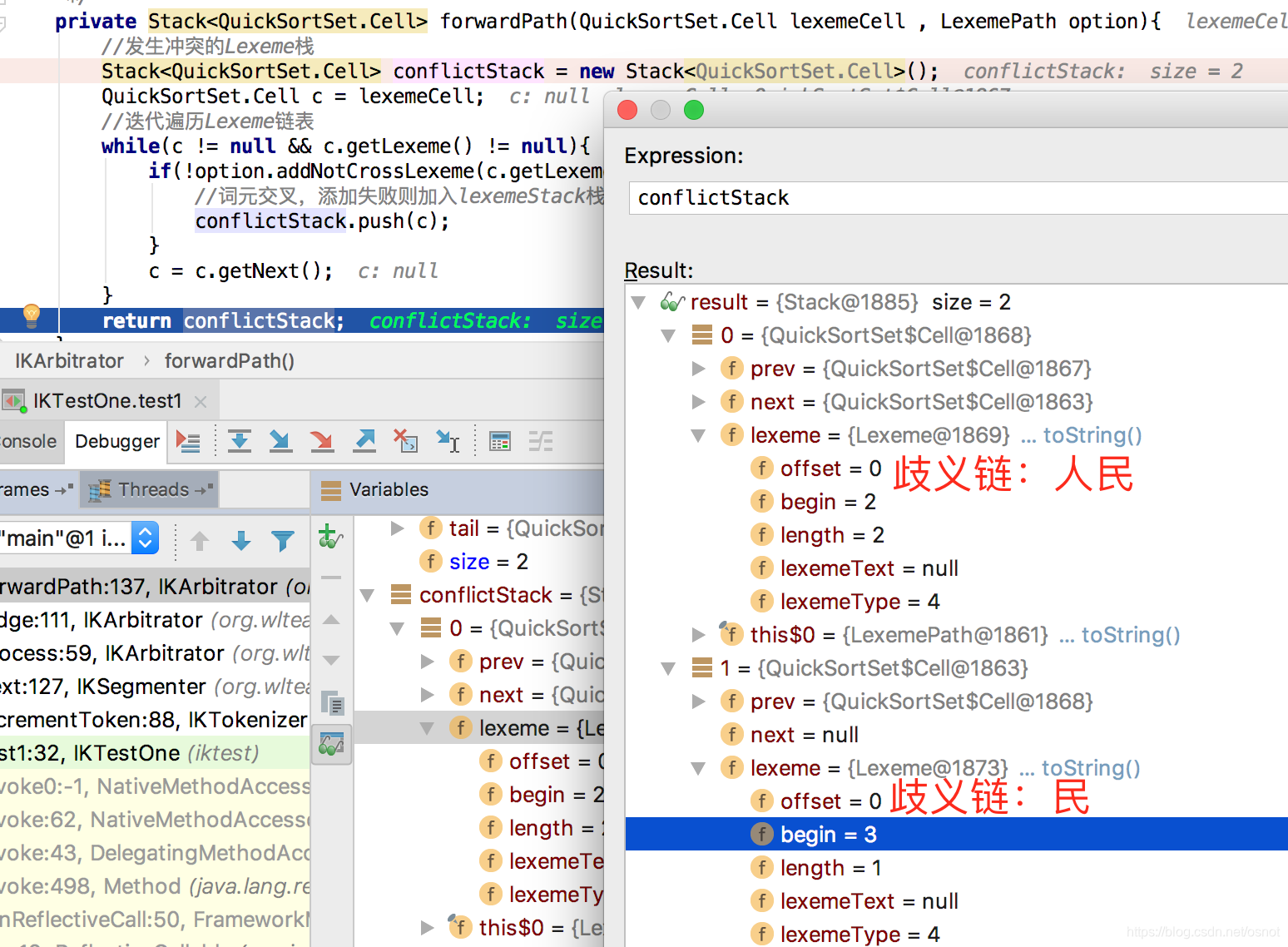
10.最后得到3个候选路径:
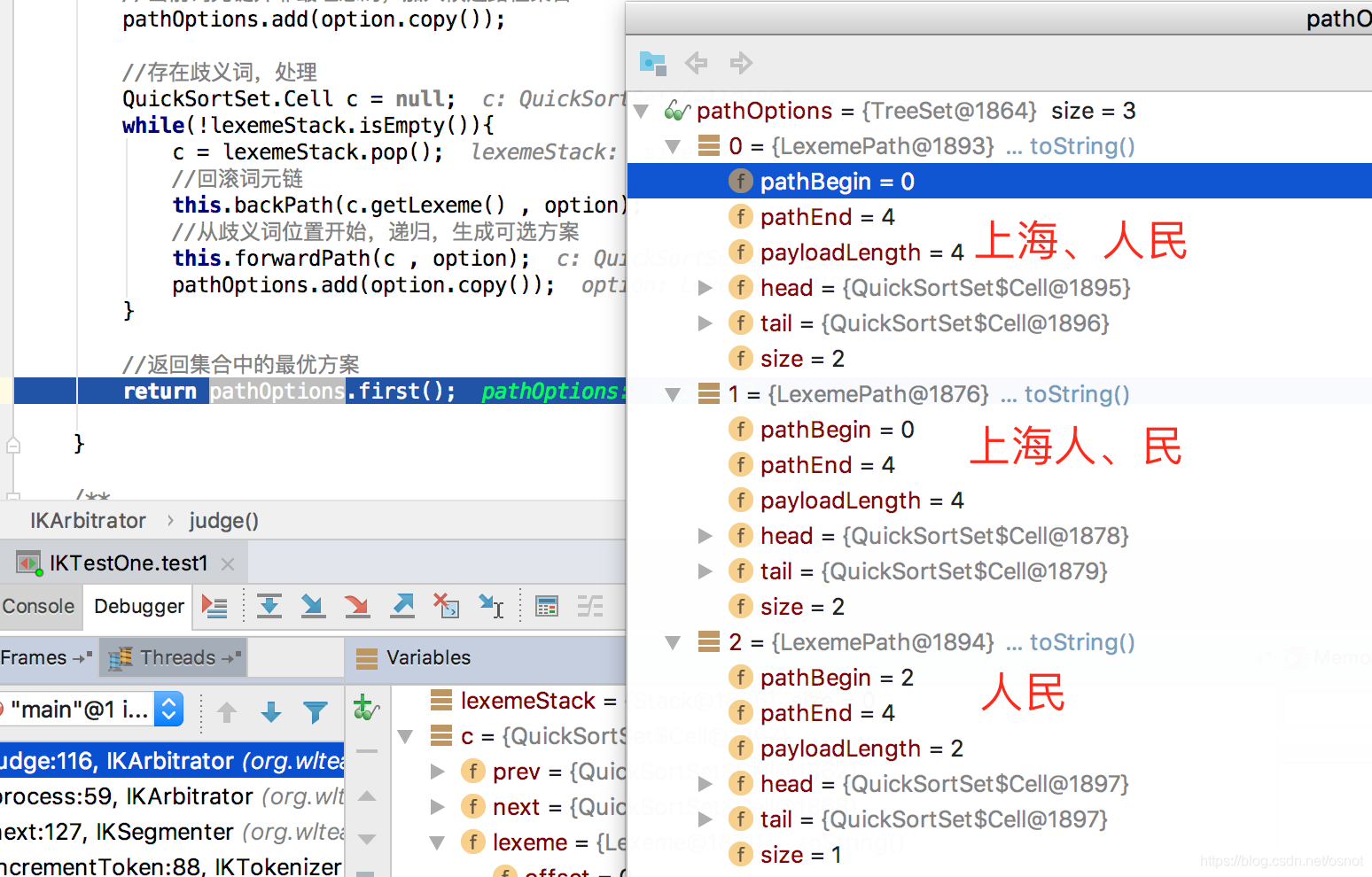
这里其实就直接取了第一个,因为TreeSet
1. 路径文本长度和([上海、人民],加起来长度为4)长的优先;
2. 词元个数越少越优先;
3. 路径跨度越大越优先([上海、人民],跨度为下标0-4,长度为4);
4. 路径跨度越靠后的越优先([上海、人民】,跨度最后为下标4),依据:根据统计学结论,逆向切分概率高于正向切分,因此位置越靠后的优先;
5. 词长越平均越好:
/*** X权重(词元长度积)* @return*/int getXWeight(){int product = 1;Cell c = this.getHead();while( c != null && c.getLexeme() != null){product *= c.getLexeme().getLength();c = c.getNext();}return product;}
6. 词元位置权重比较,越大的越优先;
/*** 词元位置权重* @return*/int getPWeight(){int pWeight = 0;int p = 0;Cell c = this.getHead();while( c != null && c.getLexeme() != null){p++;pWeight += p * c.getLexeme().getLength() ;c = c.getNext();}return pWeight; }
以上规则是按照次序依次比较,有结果则终端;
故整体3个路径比较为:
| 编号 | 路径 | 和N比较 | 失败原因 |
|---|---|---|---|
| 1 | 人民 | 2 | 失败在第1步,长度和小于2(2<4) |
| 2 | 上海人、民 | 3 | 失败在第5步,词长积小于3(3<4) |
| 3 | 上海、人民 | 成功 |
- 接续3,将歧义决断后的路径[上海、人民]加入context.pathMap中;然后重新初始化crossPath,加入当前没后交集的词元[银行],继续1遍历context.orgLexemes;
- 最后再看crossPath的总个数是否为1,不为1的话则进行最后一次歧义决断(第4步);
最后输出结果:
1: [上海]
2: [人民]
3: [银行]
三、总结
IK分词器利用词典进行分词,后利用一些规则进行歧义决断,本文讲述ik_smart分词的过程,如果是ik_max_word则不会进行歧义决断,会将分词结果全部输出,比如[上海人民银行]ik_max_word输出为:
1: [上海人]
2: [上海]
3: [人民]
4: [民]
5: [银行]
(完)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!