推荐系统 学习笔记(4)推荐系统算法详解
【小结】
统计推荐:基于用户本身的特征,找到相似用户的集合
user-CF:基于用户历史偏好行为,找到相似用户的集合
内容推荐:基于物品本身的特征,找到相似物品的集合 UGC
item-CF:基于用户历史偏好行为,找到相似物品的集合
基于模型的CF:从用户行为中提取特征,给用户和物品都打上标签,LFM发现隐形特征
基于近距邻的CF:
user-CF
(基于用户历史偏好行为,找到相似用户的集合,将其中的某些人的偏好推荐给其中的另一些人)
用户数量少于物品数量时,so从用户角度出发
不同的人喜欢了同样的物品,所以认为人是相似的,因此把其他人的喜欢也推荐给他。
item-CF
(基于用户历史偏好行为,找到相似物品的集合,向偏好了部分物品的人推荐集合中的其他物品)
用户数量远大于物品数量时,so从物品角度出发,
不同的物品被同样的人喜欢,所以认为物品是相似的,因此可以向喜欢了部分这些相似物品的人,推荐相似品

一、基于统计的推荐

二、基于内容的推荐算法(CB)

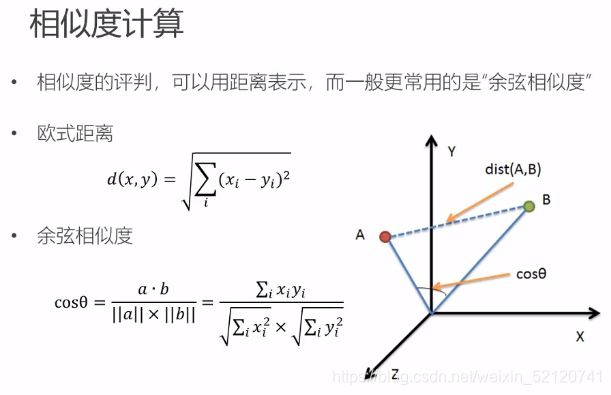

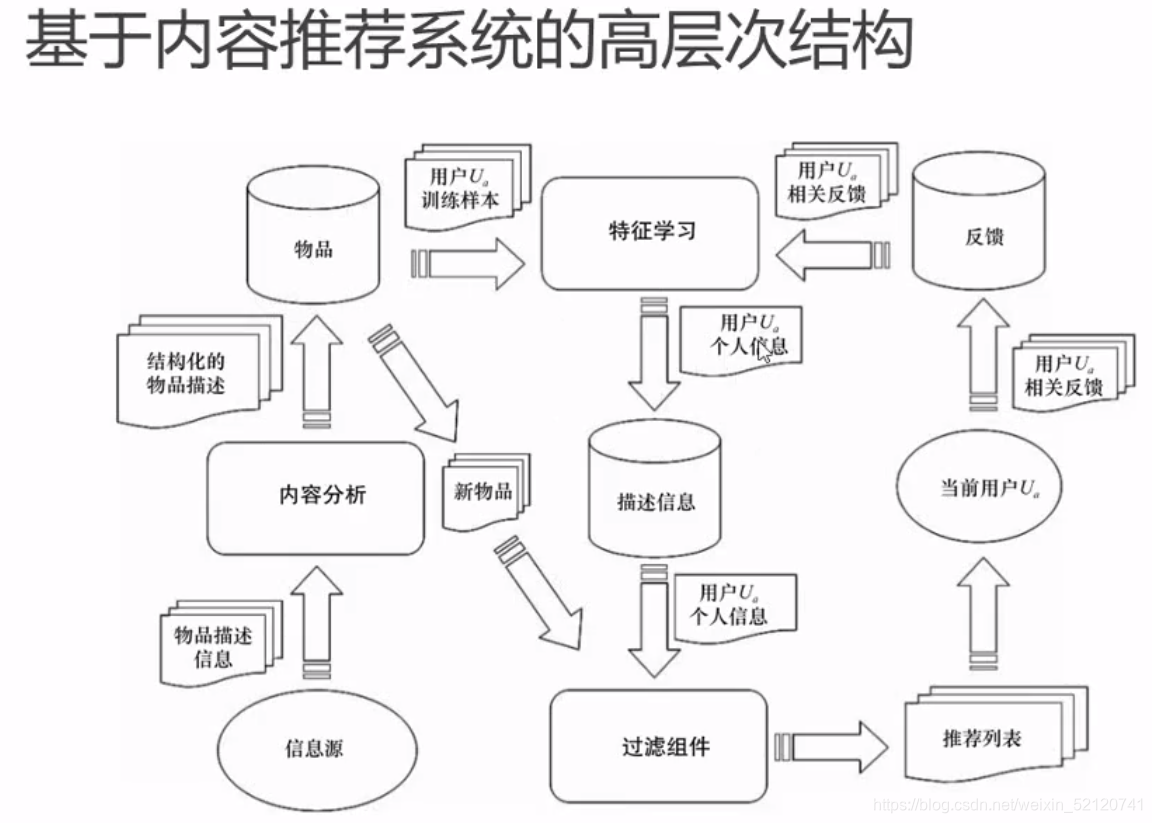
1、特征工程



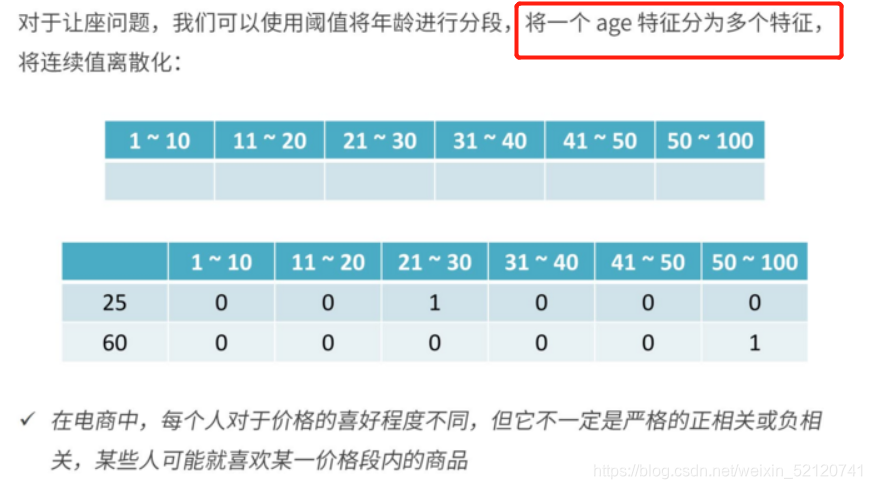





2、UGC


如果所有文章中都出现的词,不应该成为特征,因为特征是用来区分的。



TF-IDF用例,参考《TF-IDF算法示例.ipynb》
import numpy as np
import pandas as pd#1.定义数据和预处理
docA = "The cat sat on my bed"
docB = "The dog sat on my knees"
bowA = docA.split(" ")
bowB = docB.split(" ")# 构建词库
wordSet = set(bowA).union(set(bowB))#2.进行词数统计
# 用统计字典来保存词出现的次数
wordDictA = dict.fromkeys( wordSet, 0 )
wordDictB = dict.fromkeys( wordSet, 0 )# 遍历文档,统计词数
for word in bowA:wordDictA[word] += 1
for word in bowB:wordDictB[word] += 1print(pd.DataFrame([wordDictA, wordDictB]))#3.计算词频TF
def computeTF( wordDict, bow ):# 用一个字典对象记录tf,把所有的词对应在bow文档里的tf都算出来tfDict = {}nbowCount = len(bow)for word, count in wordDict.items():tfDict[word] = count / nbowCountreturn tfDicttfA = computeTF( wordDictA, bowA )
tfB = computeTF( wordDictB, bowB )#4.计算逆文档频率idf
def computeIDF( wordDictList ):# 用一个字典对象保存idf结果,每个词作为key,初始值为0idfDict = dict.fromkeys(wordDictList[0], 0)N = len(wordDictList)import mathfor wordDict in wordDictList:# 遍历字典中的每个词汇,统计Nifor word, count in wordDict.items():if count > 0:# 先把Ni增加1,存入到idfDictidfDict[word] += 1# 已经得到所有词汇i对应的Ni,现在根据公式把它替换成为idf值for word, ni in idfDict.items():idfDict[word] = math.log10( (N+1)/(ni+1) )return idfDictidfs = computeIDF( [wordDictA, wordDictB] )#5.计算FT-IDF
def computeTFIDF( tf, idfs ):tfidf = {}for word, tfval in tf.items():tfidf[word] = tfval * idfs[word]return tfidftfidfA = computeTFIDF( tfA, idfs )
tfidfB = computeTFIDF( tfB, idfs )print(pd.DataFrame( [tfidfA, tfidfB] ))三、基于协同过滤(CF)

CF中,用户的行为(评分),不仅表示用户的兴趣(评过分),还可以反映物品的质量(分值高低)。但CF无法解决冷启动的问题,因此实践中都是混合起来用的。
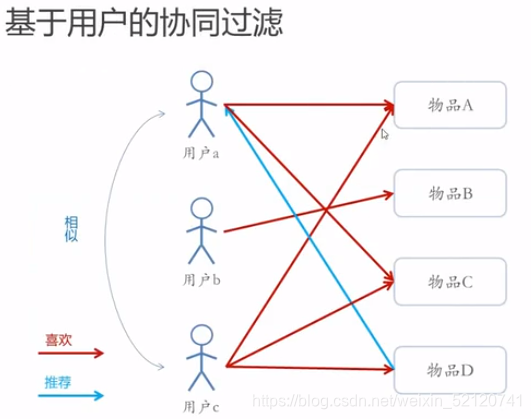
1、基于近邻的CF
用户数量少于物品数量时,so从用户角度出发
不同的人喜欢了同样的物品,所以认为人是相似的,因此把其他人的喜欢也推荐给他。
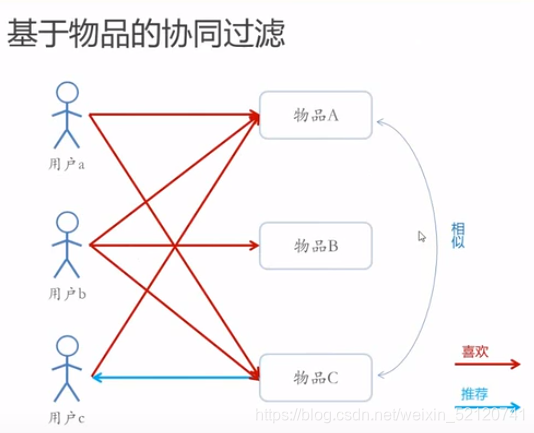
因为,用户a和用户c都喜欢了物品A和C,
所以,我们认为用户a和用户c是相似的,
因此,我们就把c喜欢的物品D推荐给了用户a。

用户数量远大于物品数量时,so从物品角度出发,
不同的物品被同样的人喜欢,所以认为物品是相似的,因此可以向喜欢了部分这些相似物品的人,推荐相似品
因为,物品A被用户a和用户b喜欢,物品C也被用户a和用户b喜欢
因此,我们认为物品A和物品C是相似的
所以,我们认为喜欢物品A的用户c也会喜欢物品C,因此把物品C推荐给用户c

用户多时,物品比较固定,可采用item-CF
物品多时,用户比较固定,可采用user-CF


2、基于模型的CF



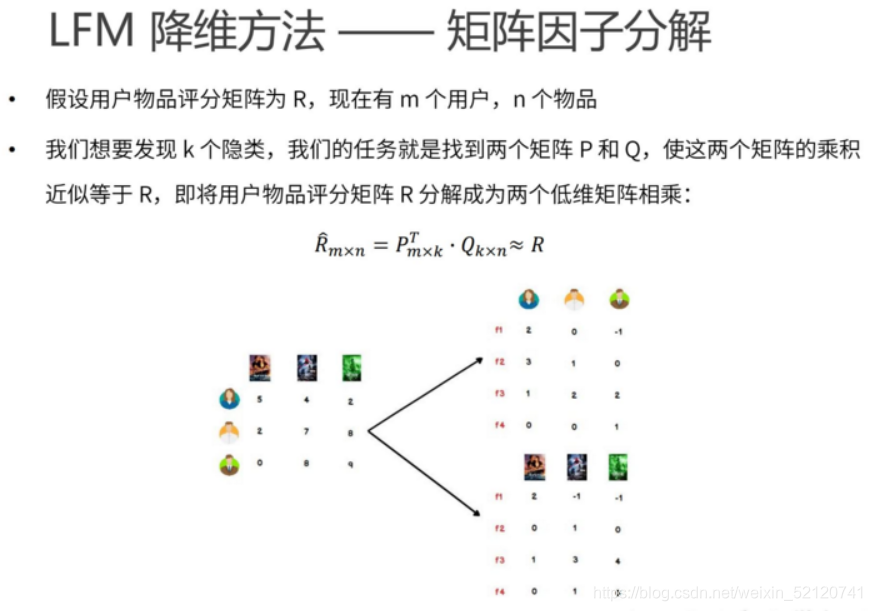

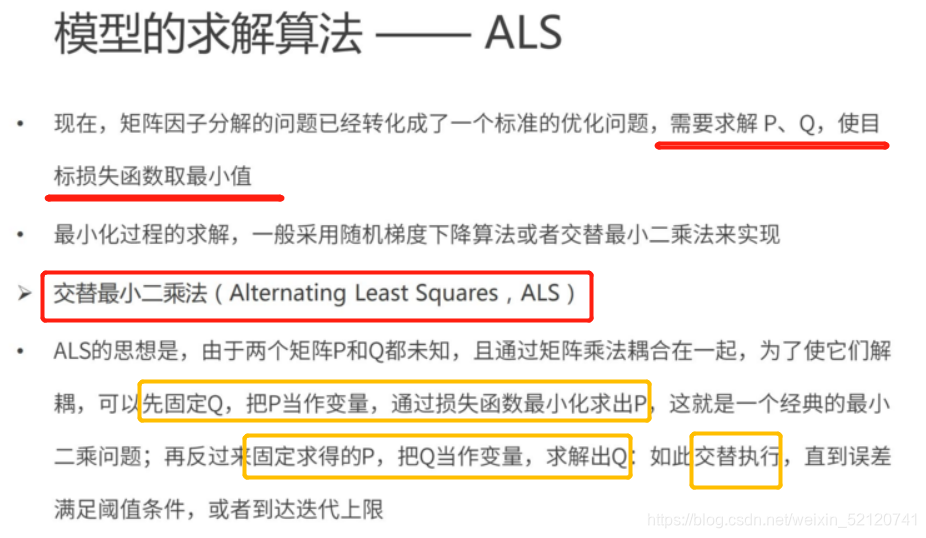




代码参见《LFM梯度下降算法实现.ipynb》
import numpy as np
import pandas as pd#1.数据准备
# 评分矩阵R
R = np.array([[4,0,2,0,1],[0,2,3,0,0],[1,0,2,4,0],[5,0,0,3,1],[0,0,1,5,1],[0,3,2,4,1],])
#print(len(R)) #R.shape[0],得到行数
print(len(R[0])) # R.shape[1],得到列数#2.算法实现
"""
@输入参数:
R:M*N 的评分矩阵
K:隐特征向量维度
max_iter: 最大迭代次数
alpha:步长
lamda:正则化系数@输出:
分解之后的 P,Q
P:初始化用户特征矩阵M*K
Q:初始化物品特征矩阵N*K
"""# 给定超参数K = 5
max_iter = 5000
alpha = 0.0002
lamda = 0.004# 核心算法
def LFM_grad_desc( R, K=2, max_iter=1000, alpha=0.0001, lamda=0.002 ):# 基本维度参数定义M = len(R)N = len(R[0])# P,Q初始值,随机生成P = np.random.rand(M, K)Q = np.random.rand(N, K)Q = Q.T# 开始迭代for step in range(max_iter):# 对所有的用户u、物品i做遍历,对应的特征向量Pu、Qi梯度下降for u in range(M):for i in range(N):# 对于每一个大于0的评分,求出预测评分误差if R[u][i] > 0:eui = np.dot( P[u,:], Q[:,i] ) - R[u][i]# 代入公式,按照梯度下降算法更新当前的Pu、Qifor k in range(K):P[u][k] = P[u][k] - alpha * ( 2 * eui * Q[k][i] + 2 * lamda * P[u][k] )Q[k][i] = Q[k][i] - alpha * ( 2 * eui * P[u][k] + 2 * lamda * Q[k][i] )# u、i遍历完成,所有特征向量更新完成,可以得到P、Q,可以计算预测评分矩阵predR = np.dot( P, Q )# 计算当前损失函数cost = 0for u in range(M):for i in range(N):if R[u][i] > 0:cost += ( np.dot( P[u,:], Q[:,i] ) - R[u][i] ) ** 2# 加上正则化项for k in range(K):cost += lamda * ( P[u][k] ** 2 + Q[k][i] ** 2 )if cost < 0.0001:breakreturn P, Q.T, cost#3.测试
P, Q, cost = LFM_grad_desc(R, K, max_iter, alpha, lamda)print(P)
print(Q)
print(cost)predR = P.dot(Q.T)print(R)
print(predR)本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!