可学习的图像调整器(一些理解)
前言
图像size对于训练任务的准确性有很大影响,size越大小目标越清晰,而目前大部分模型的input都是resize或者reshape成W,H相同(双线性插值),但是这些resize会不会限制了训练网络的任务性能呢?
作者通过实验证明硬resize可被调整为可学习的resize,从而大大提高性能。
背景
目前resize方法都是提前设计好了,因此我这里自己取名为硬resize,典型的有NEAREST,BILINEAR,BICUBIC,下面可以看看这些resize的效果:
原图:

NEAREST:
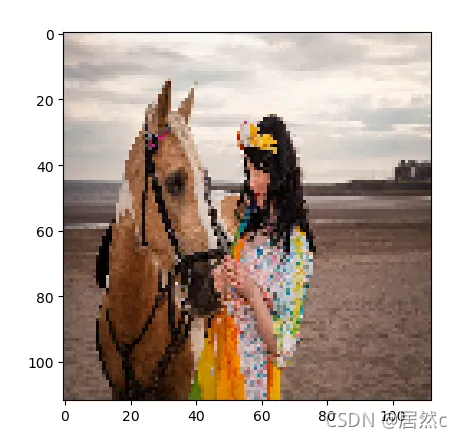
BILINEAR
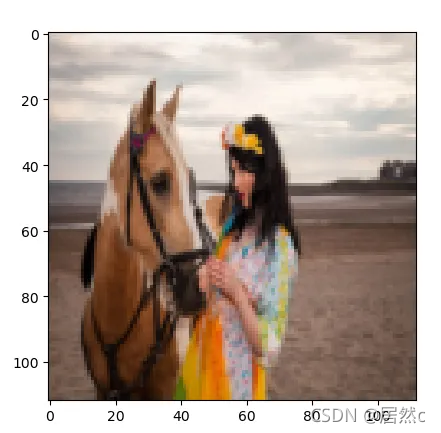
BICUBIC
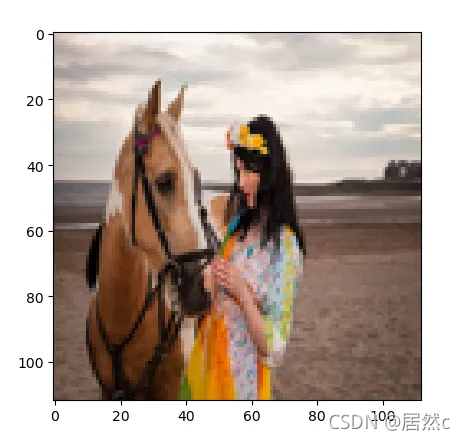
可以看出来,不同的resize方法差别还是很大,那么对于模型来说应该采用什么样的resize呢?为此作者提出了采用可学习的resizer model,以此来提高cv任务的性能。
1. 论文和代码地址

论文地址:论文
代码地址:未开源
2.Motivation
深度神经网络和大规模图像数据集的出现使机器视觉识别取得了重大突破。这类数据集中的图像通常是从网络上获得的,因此已经经过了各种后处理步骤。除了收集数据时采用的一些处理方法,在CNN训练的时候,通常还需要额外的图像处理方法,比如resize。
图像下采样是分类模型中最常用的预处理模块。图像大小的调整主要有以下几个原因:
(1)增大感受野
(2)显存限制
(3)较大图像size会导致训练和推理速度变慢
因此如何trade-off 下采样倍数和空间分辨率会在极大程度上影响模型的最终性能
目前最基本的调整器的方法有最近邻、bilinear和bicubic(如Section 0中的可视化结果)。这些调整器速度快,可以灵活地集成到训练和测试框架中。但是,这些方法是在深度学习成为视觉识别任务的主流解决方案之前就发展起来的,因此没有对深度学习进行专门的优化。
近年来,通过图像处理方法在提高分类模型的准确性和保持感知质量方面取得了良好的效果。这类方法保持了分类模型的参数固定,并且只训练了增强模块。此外,也有一些方法采用了联合训练预处理模块和识别模型,这些算法建立了具有混合损失的训练框架,允许模型同时学习更好的增强和识别。**然而,在实践中,调整图像大小等识别预处理操作不应该优化为更好的感知质量,因为最终目标是让识别网络产生准确的结果,而不是产生对人觉得“看起来好”的图像。**例如mosaic,mixup,cutout等图像增强处理方法,人觉得“看起来很难受”,而实践上则会让网络产生更加准确的结果!
因此,本文提出了一种与分类模型联合训练的新型图像调整器。

3.方法
本文的调整器模型是易于训练的,因此它可以插入到各种深度学习框架和任务中。此外,它还可以处理任何的缩放因子,包括不同比例的放大和缩小。在本文中,作者探索了分辨率与batch大小的trade-off,从而为特定CV任务寻找最佳的分辨率。在理想情况下,通过这种自适应调整大小获得的性能增益需要超过调整大小增加到的额外计算复杂度。另一方面,bilinear和bicubic等缩放方法本身是不可训练的,因此不适合完成这样的目标。为此,作者设计了一个满足这些标准的模型。
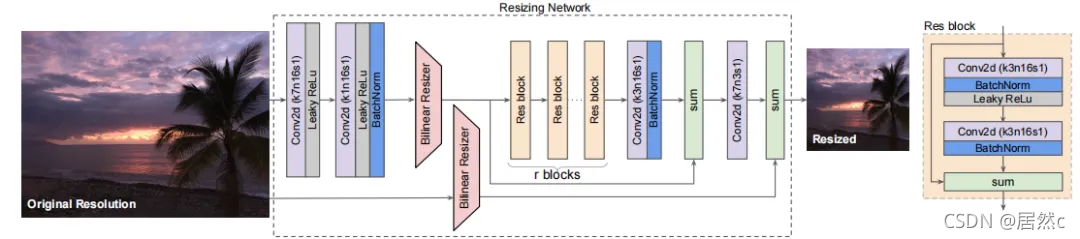
本文提出的调整器架构如上图所示。该模型最重要的特性是(1)bilinear resizer,(2)skip connection。bilinear resizer使得能够向模型中合并以原始分辨率计算的特征。skip connection使得模型能够更容易学习。上图中的bilinear resizer模块使得模型能够呈现一个bottleneck或者inverse bottleneck的结构。与典型的编码-解码器架构不同,Resizer Model能够将图像调整为任何目标大小和长宽比。此外,学习到的Resizer Model的性能几乎不依赖于bilinear resizer的选择。
在Resizer Model中有r个相同的残差块,在实验中,作者设置了r=1或r=2,所有的中间卷积层都有n=16个大小为3x3的核,第一层和最后一层的卷积核大小为7x7。
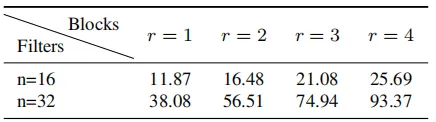
本文提出的Resizer Model相对来说比较轻量级,与原始模型相比,没有添加大量的可训练参数,Resizer Model各种配置的可训练参数数量如上表所示。
3.2 Learning Losses
Resizer Model是用Baseline Model的损失函数进行联合训练的。由于Resizer Model的目标是学习baseline视觉任务的最优调整器,因此作者没有对Resizer Mode用任何其他损失或正则化约束。
3.2.1 Image Classification
分类模型采用交叉熵损失进行训练。ImageNet由1000个类组成,因此,模型的输出代表1000个预测类概率。作者在训练过程中采用了label-smoothing方法,损失函数如下所示:


4.实验
4.1 Classification
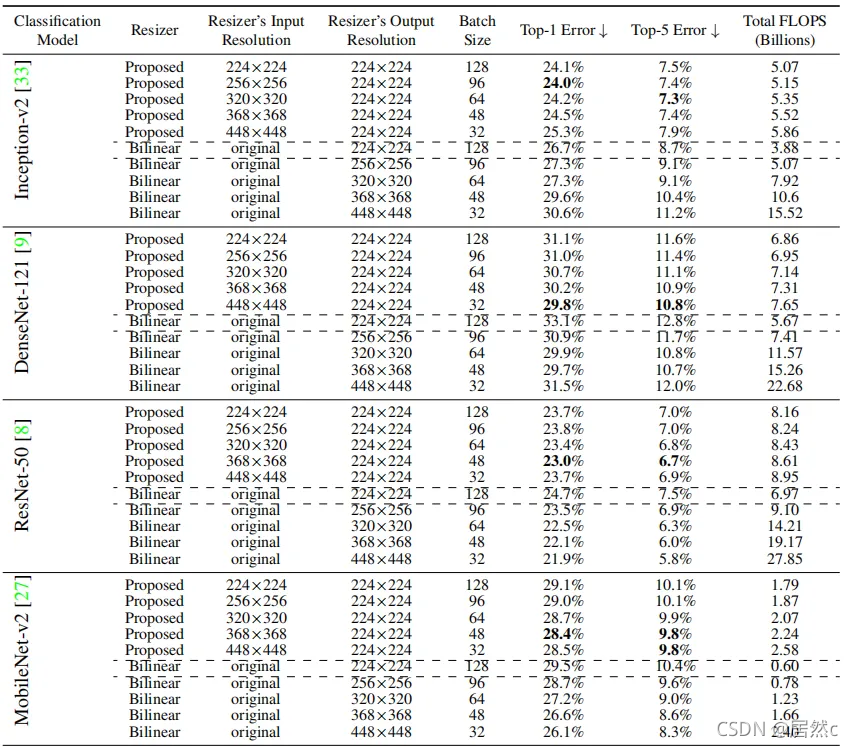
作者采用了四个模型来验证Resizer Model的有效性。可以看到,使用Resizer Model训练的网络显示出比默认baseline更好的性能。与默认baseline相比,DenseNet-121和MobileNet-v2分别显示出最大和最小的性能增益。此外,无论是否使用Resizer Model,增加输入分辨率都有利于DenseNet-121、ResNet-50和MobileNet-v2的性能提升。
4.2 Ablation
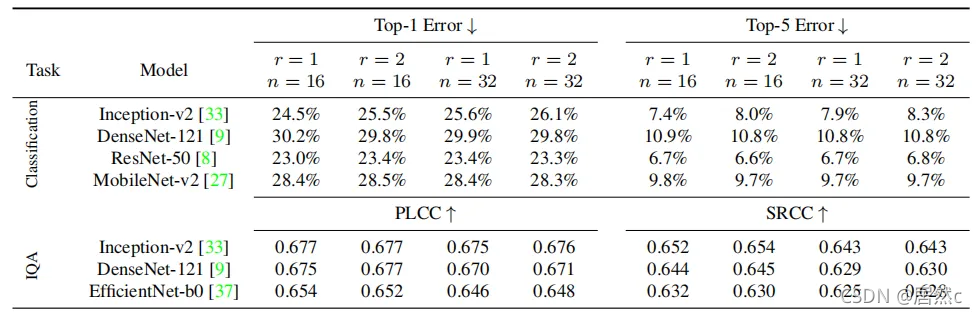

5.总结
在本文中,作者提出了一个可学习的调整器模型(resizer model)来提高模型的性能。作者关注于调整图像大小**,并没有对重新调整的图像施加像素或感知的损失函数**,因此结果只针对机器视觉任务进行了优化。实验表明,用resizer model代替传统的图像调整器可以提高视觉模型的性能。
个人认为,本文的实现方法其实非常简单,就是用了一个模型去学习图片应该怎么resize。但是思路还是比较新奇的,因为以前的方法大多都是关注在怎么更改模型的结构来提升模型的性能,但是这篇论文自己开了一个赛道,学习一个更好的调整器模型,用更适用于深度学习模型的方式来进行resize。
本文亮点总结
1.图像大小的调整主要原因:
(1)通过梯度下降的mini-batch学习需要batch中的所有图像具有相同的空间分辨率 ;
(2)显存限制阻碍了在高分辨率下训练CNN模型;
(3)较大的图像尺寸会导致训练和推理的速度较慢。
2.本文模型最重要的特性是(1)bilinear resizer,(2)skip connection。bilinear resizer使得能够向模型中合并以原始分辨率计算的特征。skip connection使得模型能够更容易学习。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!