Spring Cloud Data Flow使用 Spring Batch 进行批处理-8
使用 Spring Batch 进行批处理
在本指南中,我们开发了一个 Spring Batch 应用程序并将其部署到 Cloud Foundry、Kubernetes 和您的本地计算机。在另一个指南中,我们使用 Data Flow部署Spring Batch 应用程序。
本指南介绍了如何从头开始构建此应用程序。如果您愿意,您可以下载一个包含billsetup应用程序源的 zip 文件,将其解压缩,然后继续进行部署步骤。
您可以从浏览器下载项目或运行以下命令从命令行下载它:
wget https://github.com/spring-cloud/spring-cloud-dataflow-samples/blob/master/dataflow-website/batch-developer-guides/batch/batchsamples/dist/batchsamples.zip?raw=true -O batchsamples.zip
开发
我们从Spring Initializr开始并创建一个 Spring Batch 应用程序。
假设手机数据提供商需要为客户创建账单。使用数据存储在存储在文件系统上的 JSON 文件中。计费解决方案必须从这些文件中提取数据,从该使用数据生成计费数据,并将其存储在BILL_STATEMENTS表中。
我们可以在使用 Spring Batch 的单个 Spring Boot 应用程序中实现整个解决方案。但是,对于此示例,我们将解决方案分为两个阶段:
billsetuptask: 该billsetuptask应用程序是一个使用 Spring Cloud Task 创建BILL_STATEMENTS表的 Spring Boot 应用程序。billrun:该billrun应用程序是一个 Spring Boot 应用程序,它使用 Spring Cloud Task 和 Spring Batch 从 JSON 文件中读取每一行的使用数据和价格,并将结果数据放入BILL_STATEMENTS表中。
对于本节,我们创建一个 Spring Cloud Task 和 Spring Batchbillrun应用程序,它从一个 JSON 文件中读取使用信息,该文件包含每个条目的客户使用数据和价格,并将结果放入BILL_STATEMENTS表中。
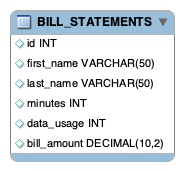
下图显示了该BILL_STATEMENTS表:
介绍 Spring Batch
Spring Batch 是一个轻量级、全面的批处理框架,旨在支持开发健壮的批处理应用程序。Spring Batch 通过提供以下功能,提供了处理大量记录所必需的可重用功能:
- 记录/跟踪
- 基于块的处理
- 声明式 I/O
- 启动/停止/重启
- 重试/跳过
- 资源管理
它还提供更高级的技术服务和功能,通过优化和分区技术实现超大容量和高性能的批处理作业。
对于本指南,我们将重点介绍五个 Spring Batch 组件,如下图所示:
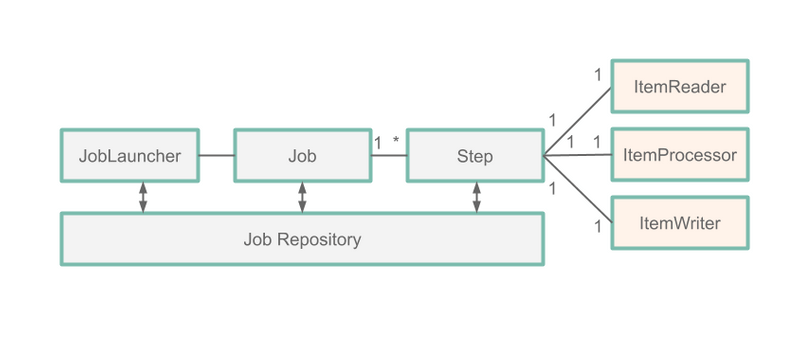
Job:AJob是封装了整个批处理过程的实体。一项工作由一个或多个steps.Step: AStep是一个域对象,它封装了批处理作业的独立、顺序阶段。每个都由step一个ItemReader、一个ItemProcessor和一个组成ItemWriter。ItemReader:ItemReader是一种抽象,表示一次检索Step一个项目的输入。ItemProcessor:ItemProcessor是一个抽象,代表一个项目的业务处理。ItemWriter:ItemWriter是一个抽象,表示 a 的输出Step。
在上图中,我们看到每个阶段JobExecution都存储在一个JobRepository(在本例中是我们的 MySQL 数据库)中。这意味着 Spring Batch 执行的每个操作都记录在数据库中,用于日志记录和重新启动作业。
注意:您可以在此处阅读有关此过程的更多信息。
我们的批量作业
因此,对于我们的应用程序,我们有一个BillRun Jobthat has one Step,其中包括:
JsonItemReader:ItemReader读取包含使用数据的 JSON 文件。BillProcessor:ItemProcessor根据从 发送的每行数据生成价格的JsonItemReader。JdbcBatchItemWriter:ItemWriter将定价Bill记录写入BILLING_STATEMENT表中。
初始化
我们使用Spring Initializr来创建我们的应用程序。为此:
- 访问Spring Initializr 站点。
- 选择最新版本的 Spring Boot。
io.spring使用 Group 名称和 Artifact 名称创建一个新的 Maven 项目billrun。- 在依赖项文本框中,键入
task以选择 Cloud Task 依赖项。 - 在依赖项文本框中,键入
jdbc并选择 JDBC 依赖项。 - 在依赖项文本框中,键入
h2并选择 H2 依赖项。我们使用 H2 进行单元测试。 - 在Dependencies文本框中,键入
mysql并选择 MySQL 依赖项(或您喜欢的数据库)。我们使用 MySQL 作为运行时数据库。 - 在Dependencies文本框中,键入
batch然后选择 Batch。 - 单击生成项目按钮。
- 解压缩
billrun.zip文件并将项目导入您喜欢的 IDE。
或者,您可以通过下载预构建文件来初始化您的项目。为此:
- 单击此 Spring Initializr 链接以下载预配置
billrun.zip文件。 - 解压缩 billrun.zip 文件并将项目导入您喜欢的 IDE。
设置 MySQL
如果您没有可用的 MySQL 实例,您可以按照以下说明运行此示例的 MySQL Docker 映像:
-
通过运行以下命令来拉取 MySQL Docker 映像:
复制
docker pull mysql:5.7.25 -
通过运行以下命令启动 MySQL:
复制
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=password \ -e MYSQL_DATABASE=task -d mysql:5.7.25
构建应用程序
-
下载
https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow-samples/master/dataflow-website/batch-developer-guides/batch/batchsamples/billrun/src/main/resources/usageinfo.json title=usageinfo.json生成的文件并将其复制到/src/main/resources目录中。 -
下载
https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow-samples/master/dataflow-website/batch-developer-guides/batch/batchsamples/billrun/src/main/resources/schema.sql title=schema.sql生成的文件并将其复制到/src/main/resources目录中。 -
在您最喜欢的 IDE 中,创建
io.spring.billrun.model包。 -
Usage在 中创建一个io.spring.billrun.model类似于Usage.java内容的类。 -
Bill在其中创建一个io.spring.billrun.model类似于Bill.java内容的类。 -
在您最喜欢的 IDE 中,创建
io.spring.billrun.configuration包。 -
为每条记录
ItemProcessor定价。Usage为此,请在如下所示的清单中创建一个BillProcessor类:io.spring.billrun.configuration复制
public class BillProcessor implements ItemProcessor<Usage, Bill> {@Overridepublic Bill process(Usage usage) {Double billAmount = usage.getDataUsage() * .001 + usage.getMinutes() * .01;return new Bill(usage.getId(), usage.getFirstName(), usage.getLastName(),usage.getDataUsage(), usage.getMinutes(), billAmount);} }请注意,我们实现了具有我们需要重写
ItemProcessor的方法的接口。process我们的参数是一个Usage对象,返回值是类型Bill。 -
现在我们可以创建一个 Java 配置来指定
BillRunJob. 在这种情况下,我们需要BillingConfiguration在包中创建一个类,io.spring.billrun.configuration如下所示:复制
@Configuration @EnableTask @EnableBatchProcessing public class BillingConfiguration {@Autowiredpublic JobBuilderFactory jobBuilderFactory;@Autowiredpublic StepBuilderFactory stepBuilderFactory;@Value("${usage.file.name:classpath:usageinfo.json}")private Resource usageResource;@Beanpublic Job job1(ItemReader<Usage> reader,ItemProcessor<Usage,Bill> itemProcessor, ItemWriter<Bill> writer) {Step step = stepBuilderFactory.get("BillProcessing").<Usage, Bill>chunk(1).reader(reader).processor(itemProcessor).writer(writer).build();return jobBuilderFactory.get("BillJob").incrementer(new RunIdIncrementer()).start(step).build();}@Beanpublic JsonItemReader<Usage> jsonItemReader() {ObjectMapper objectMapper = new ObjectMapper();JacksonJsonObjectReader<Usage> jsonObjectReader =new JacksonJsonObjectReader<>(Usage.class);jsonObjectReader.setMapper(objectMapper);return new JsonItemReaderBuilder<Usage>().jsonObjectReader(jsonObjectReader).resource(usageResource).name("UsageJsonItemReader").build();}@Beanpublic ItemWriter<Bill> jdbcBillWriter(DataSource dataSource) {JdbcBatchItemWriter<Bill> writer = new JdbcBatchItemWriterBuilder<Bill>().beanMapped().dataSource(dataSource).sql("INSERT INTO BILL_STATEMENTS (id, first_name, " +"last_name, minutes, data_usage,bill_amount) VALUES " +"(:id, :firstName, :lastName, :minutes, :dataUsage, " +":billAmount)").build();return writer;}@BeanItemProcessor<Usage, Bill> billProcessor() {return new BillProcessor();} }@EnableBatchProcessing注释启用 Spring Batch 功能并提供用于设置批处理作业的基本配置。@EnableTask注释设置了一个,它存储了有关任务执行的TaskRepository信息(例如任务的开始和结束时间以及退出代码)。在前面的配置中,我们看到我们的ItemReaderbean 是JsonItemReader. 该JsonItemReader实例读取资源的内容并将 JSON 数据解组为Usage对象。JsonItemReader是ItemReaderSpring Batch 提供的实现之一。我们还看到我们的ItemWriterbean 是JdbcBatchItemWriter. 该JdbcBatchItemWriter实例将结果写入我们的数据库。JdbcBatchItemWriter是ItemWriterSpring Batch 提供的实现之一。这ItemProcessor是我们自己的BillProcessor. 请注意,所有使用 Spring Batch 提供的类 (Job,Step,ItemReader,ItemWriter) 的 bean 都是使用 Spring Batch 提供的构建器构建的,这意味着更少的编码。
测试
现在我们已经编写了代码,是时候编写测试了。在这种情况下,我们要确保账单信息已正确插入到BILLING_STATEMENTS表中。要创建您的测试,请更新BillrunApplicationTests.java,使其类似于以下清单:
复制
package io.spring.billrun;import io.spring.billrun.model.Bill;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.jdbc.core.JdbcTemplate;import javax.sql.DataSource;
import java.util.List;import static org.assertj.core.api.Assertions.assertThat;@SpringBootTest
public class BillRunApplicationTests {@Autowiredprivate DataSource dataSource;private JdbcTemplate jdbcTemplate;@BeforeEachpublic void setup() {this.jdbcTemplate = new JdbcTemplate(this.dataSource);}@Testpublic void testJobResults() {List<Bill> billStatements = this.jdbcTemplate.query("select id, " +"first_name, last_name, minutes, data_usage, bill_amount " +"FROM bill_statements ORDER BY id",(rs, rowNum) -> new Bill(rs.getLong("id"),rs.getString("FIRST_NAME"), rs.getString("LAST_NAME"),rs.getLong("DATA_USAGE"), rs.getLong("MINUTES"),rs.getDouble("bill_amount")));assertThat(billStatements.size()).isEqualTo(5);Bill billStatement = billStatements.get(0);assertThat(billStatement.getBillAmount()).isEqualTo(6.0);assertThat(billStatement.getFirstName()).isEqualTo("jane");assertThat(billStatement.getLastName()).isEqualTo("doe");assertThat(billStatement.getId()).isEqualTo(1);assertThat(billStatement.getMinutes()).isEqualTo(500);assertThat(billStatement.getDataUsage()).isEqualTo(1000);}
}
对于此测试,我们使用JdbcTemplate执行查询并检索billrun. 查询运行后,我们将验证表第一行中的数据是否符合我们的预期。
本地部署
在本节中,我们将部署到本地机器、Cloud Foundry 和 Kubernetes。
现在我们可以构建项目了。
-
从命令行,将目录更改为项目的位置,并通过运行以下 Maven 命令构建项目
./mvnw clean package: -
使用处理数据库中的使用信息所需的配置运行应用程序。
要配置
billrun应用程序,请使用以下参数:spring.datasource.url:将 URL 设置为您的数据库实例。在以下示例中,我们通过task端口 3306 连接到本地计算机上的 MySQL 数据库。spring.datasource.username:用于 MySQL 数据库的用户名。在下面的示例中,它是root.spring.datasource.password:用于 MySQL 数据库的密码。在下面的示例中,它是password.spring.datasource.driverClassName: 用于连接 MySQL 数据库的驱动程序。在下面的示例中,它是com.mysql.jdbc.Driver.spring.datasource.initialization-mode:使用此应用程序所需的BILL_STATEMENTS和表初始化数据库。BILL_USAGE在下面的示例中,我们声明我们always想要这样做。这样做不会覆盖已经存在的表。spring.batch.initialize-schema:使用 Spring Batch 所需的表初始化数据库。在下面的示例中,我们声明我们always想要这样做。这样做不会覆盖已经存在的表。
复制
java -jar target/billrun-0.0.1-SNAPSHOT.jar \ --spring.datasource.url=jdbc:mysql://localhost:3306/task?useSSL=false \ --spring.datasource.username=root \ --spring.datasource.password=password \ --spring.datasource.driverClassName=com.mysql.jdbc.Driver \ --spring.datasource.initialization-mode=always \ --spring.batch.initialize-schema=always -
登录
mysql容器查询BILL_STATEMENTS表。为此,请运行以下命令:
复制
$ docker exec -it mysql bash -l
# mysql -u root -ppassword
mysql> select * from task.BILL_STATEMENTS;
输出应如下所示:
| ID | 名 | 姓 | 分钟 | 数据使用 | 账单金额 |
|---|---|---|---|---|---|
| 1 | 简 | 母鹿 | 500 | 1000 | 6.00 |
| 2 | 约翰 | 母鹿 | 550 | 1500 | 7.00 |
| 3 | 梅丽莎 | 史密斯 | 600 | 1550 | 7.55 |
| 4 | 迈克尔 | 史密斯 | 650 | 1500 | 8.00 |
| 5 | 玛丽 | 琼斯 | 700 | 1500 | 8.50 |
清理
要停止和删除在 Docker 实例中运行的 MySQL 容器,请运行以下命令:
复制
docker stop mysql
docker rm mysql
Kubernetes
本部分将引导您billrun在 Kubernetes 上运行应用程序。
设置 Kubernetes 集群
对于这个例子,我们需要一个正在运行的Kubernetes 集群,并且我们部署到minikube.
验证 Minikube 是否正在运行
要验证 Minikube 是否正在运行,请运行以下命令(显示其输出):
复制
minikube status
host: Running
kubelet: Running
apiserver: Running
kubectl: Correctly Configured: pointing to minikube-vm at 192.168.99.100
安装数据库
我们使用 Spring Cloud Data Flow 的默认配置安装 MySQL 服务器。为此,请运行以下命令:
复制
kubectl apply -f https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.9.1/src/kubernetes/mysql/mysql-deployment.yaml \
-f https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.9.1/src/kubernetes/mysql/mysql-pvc.yaml \
-f https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.9.1/src/kubernetes/mysql/mysql-secrets.yaml \
-f https://raw.githubusercontent.com/spring-cloud/spring-cloud-dataflow/v2.9.1/src/kubernetes/mysql/mysql-svc.yaml
为示例任务应用程序构建 Docker 映像
我们需要为billrun应用程序构建一个 Docker 映像。
为此,我们使用jib maven 插件。如果您下载了源代码分发版,则 jib 插件已配置。如果您从头开始构建应用程序,请在pluginsin下添加以下内容pom.xml:
复制
<plugin><groupId>com.google.cloud.toolsgroupId><artifactId>jib-maven-pluginartifactId><version>0.10.1version><configuration><from><image>springcloud/openjdkimage>from><to><image>${docker.org}/${project.artifactId}:${docker.version}image>to><container><useCurrentTimestamp>trueuseCurrentTimestamp>container>configuration>
plugin>
然后在下面添加引用的属性properties对于本例,我们使用以下属性:
复制
<docker.org>springcloudtaskdocker.org>
<docker.version>${project.version}docker.version>
现在您可以运行以下命令将映像添加到minikubeDocker 注册表:
复制
eval $(minikube docker-env)
./mvnw clean package jib:dockerBuild
运行以下命令以验证其存在(通过springcloudtask/billrun在图像列表中查找):
复制
docker images
Spring Cloud Data Flow 已经测试了由Spring Boot 的 gradle/maven 插件、jib maven 插件和docker build命令创建的容器。
部署应用程序
部署批处理应用程序的最简单方法是作为独立Pod。将批处理应用程序部署为作业或CronJob被认为是生产环境的最佳实践,但超出了本指南的范围。
将以下内容保存到batch-app.yaml:
复制
apiVersion: v1
kind: Pod
metadata:name: billrun
spec:restartPolicy: Nevercontainers:- name: taskimage: springcloudtask/billrun:0.0.1-SNAPSHOTenv:- name: SPRING_DATASOURCE_PASSWORDvalueFrom:secretKeyRef:name: mysqlkey: mysql-root-password- name: SPRING_DATASOURCE_URLvalue: jdbc:mysql://mysql:3306/task- name: SPRING_DATASOURCE_USERNAMEvalue: root- name: SPRING_DATASOURCE_DRIVER_CLASS_NAMEvalue: com.mysql.jdbc.DriverinitContainers:- name: init-mysql-databaseimage: mysql:5.6env:- name: MYSQL_PWDvalueFrom:secretKeyRef:name: mysqlkey: mysql-root-passwordcommand:['sh','-c','mysql -h mysql -u root -e "CREATE DATABASE IF NOT EXISTS task;"',]
要启动应用程序,请运行以下命令:
复制
kubectl apply -f batch-app.yaml
任务完成后,您应该会看到类似于以下内容的输出:
复制
kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-5cbb6c49f7-ntg2l 1/1 Running 0 4h
billrun 0/1 Completed 0 10s
现在您可以删除 pod。为此,请运行以下命令:
复制
kubectl delete -f batch-app.yaml
现在登录mysql容器查询BILL_STATEMENTS表。使用获取mysqlpod的名称kubectl get pods,如前所示。然后登录查询BILL_STATEMENTS表,如下:
复制
kubectl exec -it mysql-5cbb6c49f7-ntg2l -- /bin/bash
# mysql -u root -p$MYSQL_ROOT_PASSWORD
mysql> select * from task.BILL_STATEMENTS;
输出应如下所示:
| ID | 名 | 姓 | 分钟 | 数据使用 | 账单金额 |
|---|---|---|---|---|---|
| 1 | 简 | 母鹿 | 500 | 1000 | 6.00 |
| 2 | 约翰 | 母鹿 | 550 | 1500 | 7.00 |
| 3 | 梅丽莎 | 史密斯 | 600 | 1550 | 7.55 |
| 4 | 迈克尔 | 史密斯 | 650 | 1500 | 8.00 |
| 5 | 玛丽 | 琼斯 | 700 | 1500 | 8.50 |
要卸载mysql,请运行以下命令:
复制
kubectl delete all -l app=mysql
数据库特定说明
微软 SQL 服务器
在同时启动多个 Spring Batch 应用程序时,使用 Spring Batch 4.x 和更早版本以及 Microsoft SQL Server 数据库,您可能会收到来自数据库的死锁。此问题已在此问题中报告。一种解决方案是创建序列而不是表并创建一个BatchConfigurer来使用它们。
删除下表并将它们替换为使用相同名称的序列:
BATCH_STEP_EXECUTION_SEQBATCH_JOB_EXECUTION_SEQBATCH_JOB_SEQ
**注意:**确保将每个序列值设置为表的当前值id+ 1。
一旦表被序列替换,然后更新批处理应用程序以覆盖BatchConfigurer,这样它将使用自己的增量器。以下部分显示了此实现的一个示例:
增量器
创建自己的增量器:
复制
import javax.sql.DataSource;import org.springframework.jdbc.support.incrementer.AbstractSequenceMaxValueIncrementer;public class SqlServerSequenceMaxValueIncrementer extends AbstractSequenceMaxValueIncrementer {SqlServerSequenceMaxValueIncrementer(DataSource dataSource, String incrementerName) {super(dataSource, incrementerName);}@Overrideprotected String getSequenceQuery() {return "select next value for " + getIncrementerName();}
}
批处理配置器
在您的配置中创建您自己的BatchConfigurer以利用上面显示的增量器:
复制
@Bean
public BatchConfigurer batchConfigurer(DataSource dataSource) {return new DefaultBatchConfigurer(dataSource) {protected JobRepository createJobRepository() {return getJobRepository();}@Overridepublic JobRepository getJobRepository() {JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();DefaultDataFieldMaxValueIncrementerFactory incrementerFactory =new DefaultDataFieldMaxValueIncrementerFactory(dataSource) {@Overridepublic DataFieldMaxValueIncrementer getIncrementer(String incrementerType, String incrementerName) {return getIncrementerForApp(incrementerName);}};factory.setIncrementerFactory(incrementerFactory);factory.setDataSource(dataSource);factory.setTransactionManager(this.getTransactionManager());factory.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");try {factory.afterPropertiesSet();return factory.getObject();}catch (Exception exception) {exception.printStackTrace();}return null;}private DataFieldMaxValueIncrementer getIncrementerForApp(String incrementerName) {DefaultDataFieldMaxValueIncrementerFactory incrementerFactory = new DefaultDataFieldMaxValueIncrementerFactory(dataSource);DataFieldMaxValueIncrementer incrementer = null;if (dataSource != null) {String databaseType;try {databaseType = DatabaseType.fromMetaData(dataSource).name();}catch (MetaDataAccessException e) {throw new IllegalStateException(e);}if (StringUtils.hasText(databaseType) && databaseType.equals("SQLSERVER")) {if (!isSqlServerTableSequenceAvailable(incrementerName)) {incrementer = new SqlServerSequenceMaxValueIncrementer(dataSource, incrementerName);}}}if (incrementer == null) {try {incrementer = incrementerFactory.getIncrementer(DatabaseType.fromMetaData(dataSource).name(), incrementerName);}catch (Exception exception) {exception.printStackTrace();}}return incrementer;}private boolean isSqlServerTableSequenceAvailable(String incrementerName) {boolean result = false;DatabaseMetaData metaData = null;try {metaData = dataSource.getConnection().getMetaData();String[] types = {"TABLE"};ResultSet tables = metaData.getTables(null, null, "%", types);while (tables.next()) {if (tables.getString("TABLE_NAME").equals(incrementerName)) {result = true;break;}}}catch (SQLException sqe) {sqe.printStackTrace();}return result;}};
}
**注意:**创建的隔离级别已设置为ISOLATION_REPEATABLE_READ防止在批处理表中创建条目时出现死锁。
依赖项
要求您使用 Spring Cloud Task 2.3.3 或更高版本。这是因为 Spring Cloud Task 2.3.3 将使用一个TASK_SEQ可用的序列。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!