Spark应用场景以及与hadoop的比较
Spark应用场景以及与hadoop的比较
一、大数据的四大特征:
a.海量的数据规模(volume)
b.快速的数据流转和动态的数据体系(velocity)
c.多样的数据类型(variety)
d.巨大的数据价值(value)
二.Spark 和 Hadoop的不同
Spark是给予map reduce 算法实现的分布式计算,拥有Hadoop MapReduce所具有的有点,但不同与MaoReduce的是Job中间输出和结果可以保存在内存中,从而不用在读写HDFS,因此Spark能更好的适用于数据挖掘与机器学习等需要迭代的map reduce的算法
架构如图:
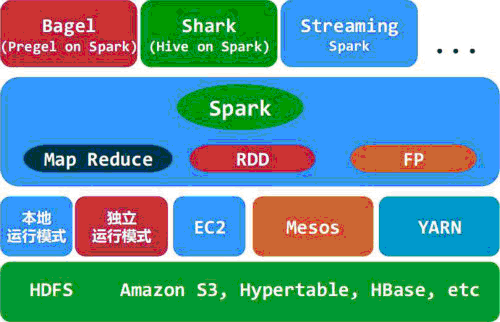
1. Spark的中间数据放到内存中,对于迭代运算效率比较高。
2. Spark比Hadoop更通用。
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap,sample,groupByKey, reduceByKey, union, join, cogroup, mapValues, sort,partionBy等多种操作类型,他们把这些操作称为Transformations。同时还提供Count, collect,
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!