机器学习实践(二)——决策树
一、决策树
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
决策树是基于树状结构来进行决策的,一般地,一棵决策树包含一个根节点、若干个内部节点和若干个叶节点。
- 每个内部节点表示一个属性上的判断
- 每个分支代表一个判断结果的输出
- 每个叶节点代表一种分类结果。
- 根节点包含样本全集
二、决策树算法
决策树的典型算法有ID3,C4.5,CART等。国际权威的学术组织,数据挖掘国际会议ICDM (the IEEE International Conference on Data Mining)在2006年12月评选出了数据挖掘领域的十大经典算法中,C4.5算法排名第一。C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。C4.5算法产生的分类规则易于理解,准确率较高。不过在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,在实际应用中因而会导致算法的低效。 [2]
决策树算法的优点如下:
(1)分类精度高;
(2)生成的模式简单;
(3)对噪声数据有很好的健壮性。
因而是目前应用最为广泛的归纳推理算法之一,在数据挖掘中受到研究者的广泛关注。
三、决策树算法学习
由对决策树算法的了解可知,决策树学习的关键点就在于如何选择最优划分属性。此次实践主要使用到ID3算法,ID3算法的核心是根据信息增益来选择进行划分的特征,然后递归地构建决策树。
1.信息熵
信息熵可以用来衡量信息量的大小。若不确定性越大,则信息量越大,熵越小;若不确定性越小,则信息量越小,熵越小。
假如有变量X,其可能的取值有n种,每一种取到的概率为Pi,那么X的熵就定义为:
构建决策树的过程,就是减小信息熵,减小不确定性,从而完整构造决策树模型。
2.信息增益
在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。所谓信息量,就是熵。
根据信息熵的定义可以知道:X可能的变化越多,X所携带的信息量越大,熵也就越大。对于文本分类或聚类而言,就是说文档属于哪个类别的变化越多,类别的信息量就越大。所以特征T给聚类C或分类C带来的信息增益为IG(T)=H(C)-H(C|T)。
而用信息增益来决定决策树的划分属性,也就是著名的ID3决策树学习算法。
3.ID3算法步骤
从根节点开始,计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的划分特征;
由该特征的不同取值建立子节点;
再对子节点递归1-2步,构建决策树;
直到没有特征可以选择或类别完全相同为止,得到最终的决策树。
四、python实现决策树
1.建立数据集
数据集的目的是决策今日是否适宜进行社团活动,属性有温度、天气情况、人员齐全情况。
| 温度 | 天气情况 | 人员齐全情况 | 场地情况 | 是否适宜进行社团活动 |
| 高 | 晴朗 | 齐全 | 人较多 | 是 |
| 适中 | 晴朗 | 齐全 | 宽敞 | 是 |
| 适中 | 降雨 | 齐全 | 宽敞 | 是 |
| 高 | 降雨 | 不齐全 | 人较多 | 否 |
| 高 | 降雨 | 齐全 | 拥挤 | 否 |
| 适中 | 降雨 | 不齐全 | 宽敞 | 否 |
| 适中 | 阴天 | 不齐全 | 宽敞 | 是 |
| 适中 | 阴天 | 齐全 | 人较多 | 是 |
根据属性对其进行标注:
温度高为1,适中为0;天气情况降雨为0,阴天为1,晴朗为2;人员不齐全为1,齐全为0;场地情况拥挤为0,人较多为1,宽敞为2;适宜进行活动为yes,不适宜为no。
代码:
dataSet = [[1, 2, 0, 1, 'yes'],[0, 2, 0, 2, 'yes'],[0, 0, 0, 2, 'yes'],[1, 0, 1, 1, 'no'],[1, 0, 0, 0, 'no'],[0, 0, 0, 2, 'no'],[0, 1, 1, 2, 'yes'],[0, 1, 0, 1, 'yes']]labels = ['温度', '天气情况', '人员齐全情况', '场地情况']2.计算熵值
def calcShannonEnt(dataSet):totalNum = len(dataSet)labelSet = {}for dataVec in dataSet:label = dataVec[-1]if label not in labelSet.keys():labelSet[label] = 0labelSet[label] += 1shannonEnt = 0for key in labelSet:pi = float(labelSet[key])/totalNumshannonEnt -= pi*math.log(pi,2)return shannonEnt3.计算信息增益
#按给定特征划分数据集
def splitDataSet(dataSet, featNum, featvalue):retDataSet = []for dataVec in dataSet:if dataVec[featNum] == featvalue:splitData = dataVec[:featNum]splitData.extend(dataVec[featNum+1:])retDataSet.append(splitData)return retDataSetdef chooseBestFeatToSplit(dataSet):featNum = len(dataSet[0]) - 1maxInfoGain = 0bestFeat = -1baseShanno = calcShannonEnt(dataSet)for i in range(featNum):featList = [dataVec[i] for dataVec in dataSet]featList = set(featList)newShanno = 0for featValue in featList:subDataSet = splitDataSet(dataSet, i, featValue)prob = len(subDataSet)/float(len(dataSet))newShanno += prob*calcShannonEnt(subDataSet)infoGain = baseShanno - newShannoif infoGain > maxInfoGain:maxInfoGain = infoGainbestFeat = ireturn bestFeat
4.创建决策树
def createDecideTree(dataSet, featName):classList = [dataVec[-1] for dataVec in dataSet]if len(classList) == classList.count(classList[0]):return classList[0]if len(dataSet[0]) == 1:return majorityCnt(classList)bestFeat = chooseBestFeatToSplit(dataSet)beatFestName = featName[bestFeat]del featName[bestFeat]DTree = {beatFestName:{}}featValue = [dataVec[bestFeat] for dataVec in dataSet]featValue = set(featValue)for value in featValue:subFeatName = featName[:]DTree[beatFestName][value] = createDecideTree(splitDataSet(dataSet,bestFeat,value), subFeatName)return DTreedef getNumLeafs(tree):numLeafs = 0firstFeat = list(tree.keys())[0]secondDict = tree[firstFeat]for key in secondDict.keys():if type(secondDict[key]).__name__== 'dict':numLeafs += getNumLeafs(secondDict[key])else:numLeafs += 1return numLeafs
5.获取决策树深度
def getTreeDepth(tree):maxDepth = 0firstFeat = list(tree.keys())[0]secondDict = tree[firstFeat]for key in secondDict.keys():if type(secondDict[key]).__name__ == 'dict':thisDepth = 1 + getTreeDepth(secondDict[key])else:thisDepth = 1if thisDepth > maxDepth:maxDepth = thisDepthreturn maxDepth6.画出决策树
def createPlot(tree):fig = plt.figure(1, facecolor='white')fig.clf()xyticks = dict(xticks=[], yticks=[])createPlot.pTree = plt.subplot(111, frameon=False, **xyticks)plotTree.totalW = float(getNumLeafs(tree))plotTree.totalD = float(getTreeDepth(tree))plotTree.xOff = -0.5 / plotTree.totalWplotTree.yOff = 1.0plotTree(tree, (0.5, 1.0), '')plt.show()
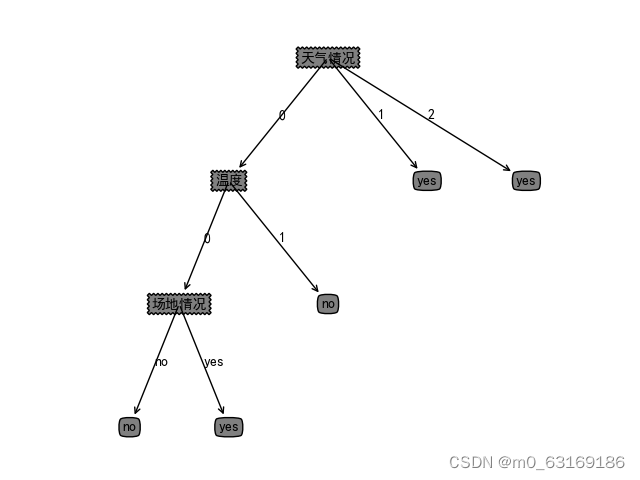
7.预测数据集
testVec = [0, 1, 1, 1]result = classify(myTree, featLabels, testVec)if result == 'yes':print('今日适宜进行社团活动')if result == 'no':print('今日不适宜进行社团活动')
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!