Python文本分析可视化词云图WordCloud练习及错误总结
Python文本分析可视化整体思路:
一.导入待可视化文本文件,分词并统计词频。
二.筛选出高频词。
三.根据词频绘制形状词云图。
import os
print(os.getcwd())
os.chdir("e:\\")
print(os.getcwd())首先通过“os.getcwd()”确认当前工作的目录与待分析的文本文件位置是否在同一目录下,
并利用“os.chdir()”改变位置,保证操作系统能成功找到文本文件。
import jieba#导入jieba库处理中文文本
with open("BNYJ.txt",'r',encoding='utf-8')as f:renmin=f.read()#打开文本
seg_list=jieba.cut(renmin,cut_all=False)#以精准模式处理文本的分词
#print('【精准模式】:'+'/'.join(seg_list))
jieba.load_userdict('BLC.txt')#添加保留词,进行二次分词
tf={}#建立空字典,以键值对的形式存放词频统计结果
for seg in seg_list:#遍历分词结果列表if seg in tf:tf[seg]+=1else:tf[seg]=1
ci=list(tf.keys())
with open('stopwords.txt','r',encoding='utf-8')as ft:stopword=ft.read()#导入停用词,作筛选用
for seg in ci:#遍历键值if tf[seg]<5 or len(seg)<2 or seg in stopword or'一'in seg:tf.pop(seg)#将词频小于5,单字、停用词,“一”的分词筛掉
print(tf)jieba有三种分词模式,分别是精确模式、全模式、搜索引擎模式。下图是他们分别的应用方法和应用场景。
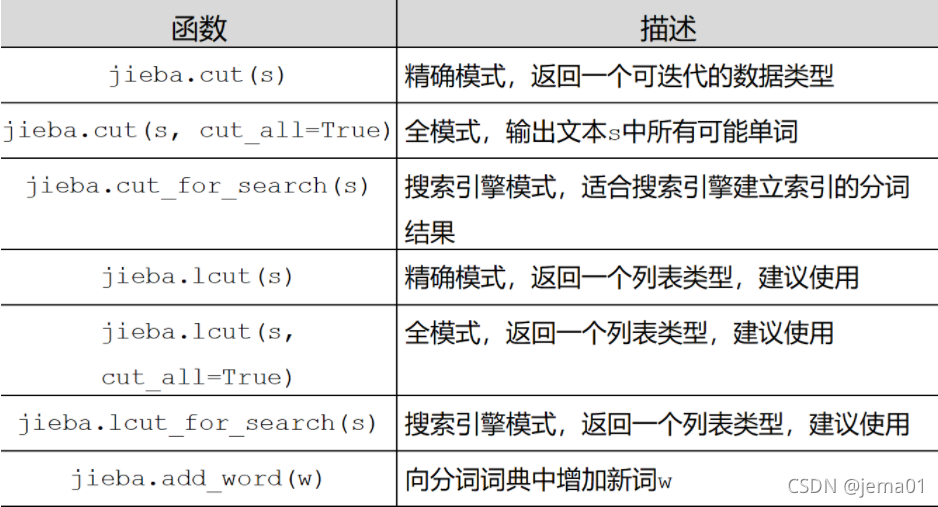
在初次利用jieba分词后,我们还需要在此结果的基础上,自己建立保留词文本,完善分词结果。我在作业过程中尝试了三种分词模式:
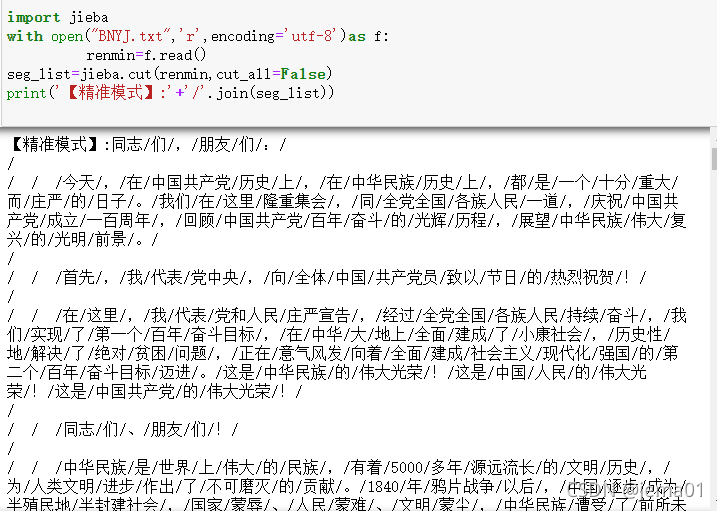
全模式: 精准模式
精准模式
搜索引擎模式
 经过比较可以发现,精准模式将句子最精准地分开,且在此分词基础上,自建保留词文本库工作量最小,所以,精准模式最适合文本分析。
经过比较可以发现,精准模式将句子最精准地分开,且在此分词基础上,自建保留词文本库工作量最小,所以,精准模式最适合文本分析。
注意:1.读取文本时,“encoding=XXX”的填写主要是看文本文件的编码格式,txt文件有下图几种编码格式,填写相对应的即可正常读取。
2.print分词结果检查、查看后,一定要把“print('【精准模式】:'+'/'.join(seg_list))”注释掉!!!因为print分词结果表示该层工作已结束,参数“seg_list”不再继续参与。此时“print(tf)”的结果为空字典。
做完以上后,我们已得出按照文章顺序排列的高频词统计结果,接下来可直接进入绘图。
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
font=r'c:\Windows\Fonts\simfang.ttf' #中文文本需规定中文字体
mask=np.array(Image.open('gongji.jpg'))#打开套用的图形
wc=WordCloud(background_color='white',mask=mask,font_path=font,width=500,height=2000).generate_from_frequencies(tf)
image_colors=ImageColorGenerator(mask)
plt.imshow(wc.recolor(color_func=image_colors))#使字体的颜色取自背景图颜色
plt.axis('off')#关闭坐标轴
plt.show()#输出词云文件
wc.to_file('l3.jpg')#保存词云文件PIL是python的第三方图像处理库。具体功能、方法介绍戳链接:Python图像库PIL的类Image及其方法介绍_leemboy的博客-CSDN博客_pil
wordcloud配置对象参数:“wc=wordcloud()”,括号内的参数可填下图:
 wordcloud加载词云文本:“wc.generate()”,括号内填待分析文本。
wordcloud加载词云文本:“wc.generate()”,括号内填待分析文本。
注意:填充背景图尽量不要选择透明背景图、尽量不要选择没有灰度参数的图。比如在使用没有灰度参数的下图作为背景图时,提示错误:"NotImplementedError: Gray-scale images TODO''。

原因在以下连接中找到了,但还是有些不太明白。实际操作时,最简单的操作就是换个能用的图。(15条消息) Windows环境下Python中wordcloud的使用——自己踩过的坑 2017.08.08_heyuexianzi的博客-CSDN博客
ci,num,data=list(tf.keys()),list(tf.values()),[]
for i in range(len(tf)):data.append((num[i],ci[i]))
data.sort(reverse=True)
tf_sorted={}
for i in range(len(data)):tf_sorted[data[i][1]]=data[i][0]
print(tf_sorted)上面这段代码是在按文章检索顺序统计完高频词后,按词出现频率重新排列的代码。遍历字典中的key值、value值,将值提前,对值排序,后输出降序排列的新词典。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!