眨眼算什么,让蒙娜丽莎像你一样唠上嗑才算硬核
第一次写文章还把蒙娜丽莎名字写错了,原谅四川人我N、L不分,蒙娜丽莎表示有很多话要说。这不,三星莫斯科AI中心和Skolkovo 科学技术研究所(DeepWarp也是他们的作品)在19年5月份就发表了一篇论文,文章中提出的talking head模型,让蒙娜丽莎说上了话,让玛丽莲梦露笑开了眼。

(话痨式蒙娜丽莎)
像这类换脸的技术有很多,比如被玩坏了的deepfake,最新的FaceShifter(和Face X-Ray简直上演了换脸算法的矛与盾),以及只迁移表情的face2face和其升级版可以完成上身运动和头部运动迁移的HeadOn。但是这些方法都需要大量的数据(应该是A转B,A和B都需要一定量的数据),且对计算资源要求高。而该论文的模型只需要少量样本(few-shot),甚至只需要一张图像(one-shot),比如:蒙娜丽莎,就可以把她的脸、表情、头部动作按照你给的说话视频动起来了。


相关资源

论文:Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
复现代码:https://github.com/vincent-thevenin/Realistic-Neural-Talking-Head-Models

论文笔记


作者首先采用了一个元学习(meta-learning)的架构,在大量不同外表、不同谈话表情的说话人视频数据上进行预训练(embedding)。在预训练过程中,同时利用少量的对应视频帧人头图像(同一个人)和视频的embedding信息完成关键点到真实图像的生成,元学习的主要目的是通过GAN实现人脸关键点(Landmarks)到人脸的生成过程;然后利用元学习得到的高质量生成器和判别器重新在新的人头数据集上(可以同一人像也可以不同人像)进行对抗学习,其实就是一个微调(fine-tuning)或者在线学习的过程。
(论文公开的视频)
01
元学习
元学习阶段包含三个网络:嵌入网络(embedder)、生成网络(generator)和判别网络(discriminator),首先,定义一些如下数学符号:
:视频视频序列数量;
:第i个视频序列;
:第i个视频的第t帧;
:第i个视频的第t帧对应的关键点结果(通过《How far are we from solving the 2d & 3d face alignment problem》得到);
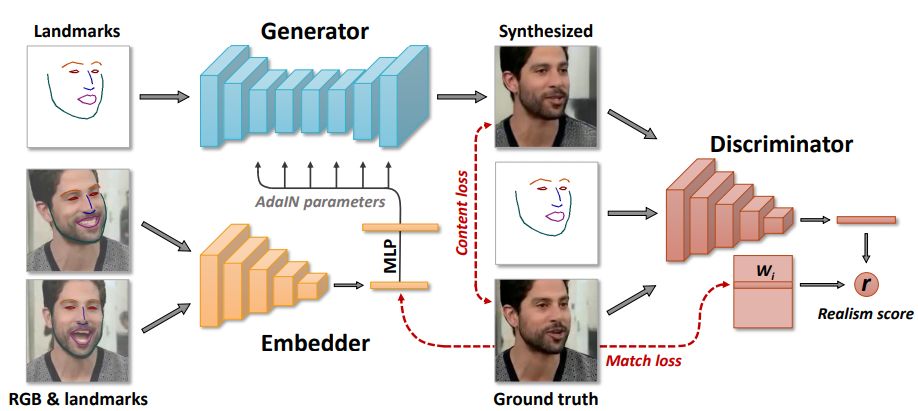
(模型结构)
嵌入网络
:输入视频帧及对应的关键点结果,嵌入式网络的作用是将该输入映射为一个维向量。其中是网络可训练参数,通过元学习过程进行优化,因此嵌入向量就包含了特定的视频帧信息,通过求平均得到视频的嵌入向量。
具体地,从视频数据集随机选取视频i,并从该视频随机选取第t帧,并在除第t帧外随机选取k(k=8)帧s1, s2, . . . , sK,通过对这K帧经过embedder得到的向量求平均,得到的平均向量,作为该视频的嵌入向量。
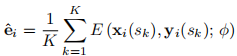
问:那么第t帧是拿来干什么用的呢?
答:通过该帧的关键点让生成网络生成该帧人脸图像。
生成网络
:输入视频帧关键点定位图像,以及要转换的视频嵌入向量,生成对应帧的重建结果。生成器的作用是要使得生成的图像和视频帧视频帧图像相似度越大越好。生成网络的参数有两部分:共性参数 和特性参数,在元学习过程中,ψ可以直接训练得到,而则需要通过嵌入向量 经过MLP预测得到,即:。
那么,利用关键点和视频嵌入向量对第t帧进行重建:

嵌入网络和生成网络的参数通过以下损失函数进行优化:包含三个部分:内容损失、对抗损失和匹配损失。
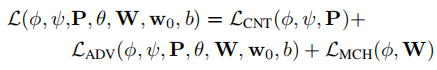
其中,内容损失和风格迁移的损失类似,通过对真实图像和预测图像在VGG19的Conv1,6,11,20,29的激活层特征,以及VGGFace的Conv1,6,11,18,25的激活层特征分别计算L1距离,并进一步加权求和而来。
对抗损失:生成器生成的图像应该尽可能“骗”过判别器,使得判别器输出的真实性得分最大化。
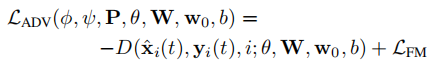
对抗损失中,作者还借鉴了pix2pixHD的特征匹配损失,即从判别器的中间层提取特征,学习匹配真实图像和生成图像的这些中间表示,具有稳定训练的作用。
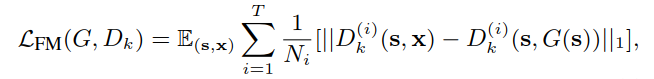
嵌入向量匹配损失:对应视频嵌入向量的距离,其中一个嵌入向量来自于嵌入网络,另一个嵌入向量,是判别网络权重的一部分,借鉴自《cGANs with Projection Discriminat》的思想。
判别网络
:判别网络的输入包括:第t帧的图像或者生成图像、对应的关键点结果,以及视频序列的索引i,为卷积神经网络参数,视频嵌入矩阵,第i列表示第i个视频嵌入向量,以及和都是判别网络的可训练参数。通过卷积网络,判别器将图像和关键点结果映射为一个N维向量,基于这个结果和、和线性运算,得到一个得分,表示输入是否为第t帧的真实图像以及是否和输入的关键点结果相匹配 。
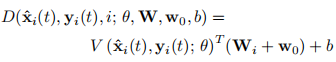
在更新嵌入网络和生成网络时,判别网络通过如下的hinge loss更新其权重,损失函数形式:
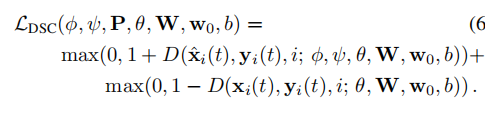
02
少样本微调
在元学习已收敛的模型基础上,通过少量样本进行微调,即只有一个视频序列(要模仿的视频)和少量帧(需要转换的图像)的简单版元学习,选取T张同一视频的图像帧x(1), x(2), . . . , x(T),以及对应的关键点结果图像 y(1), y(2), . . . , y(T),T大小不同于元学习的K,T=1时为one-shot 学习。
通过嵌入网络得到输入T帧图像的嵌入向量:
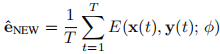
继而完全可以通过生成器对关键点图像生成类似于这T帧的图像,但是存在个体差异:看起来像但是真实度不够,这个差异可以通过接下来的微调有效地解决。
微调生成网络
:同预训练一致,生成器对输入的关键点图像重建人脸图像,训练参数也包含两部分:ψ和ψ',ψ'通过和预训练的投影矩阵P进行初始化,后续直接更新ψ',然后更新ψ′,使得G更快适应于另一个域(测试集),初始化:
损失函数:
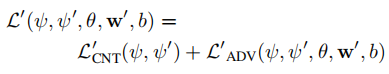
微调判别网络
:卷积层参数以及偏置均由预训练参数初始化,所以微调后的判别器形式如下:
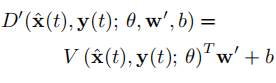
那么该如何初始化呢,并不能像预训练那样采用,因为表示训练集第i个视频的嵌入向量。这时候就体现出它的作用了,因为可以使y与更相似,所以可以初始化为:
损失函数:

03
实验结果
作者在两个数据集:VoxCeleb1和VoxCeleb2进行训练和验证,并通过FID(Frechet Inception Distance)、SSIM(结构相似度)、CSIM(余弦相似度)以及用户调研进行定量和定性地评估。
左边的T表表示测试所用图像数量,可以看出T=1也可以生成比较逼真的图像;T越大时,生成效果越好。


(T为不同值时在两个数据集的生成结果以及不同方法的对比)
作者还在静态画数据上通过one-shot学习,生成动态的视频结果,其中输入的的关键点数据来自于VoxCeleb2。不过作者使用了余弦相似度对视频进行了排序,找出了相似的脸型的视频作为被模仿的输入。(但是这怎么微调呢,没有ground truth啊?)
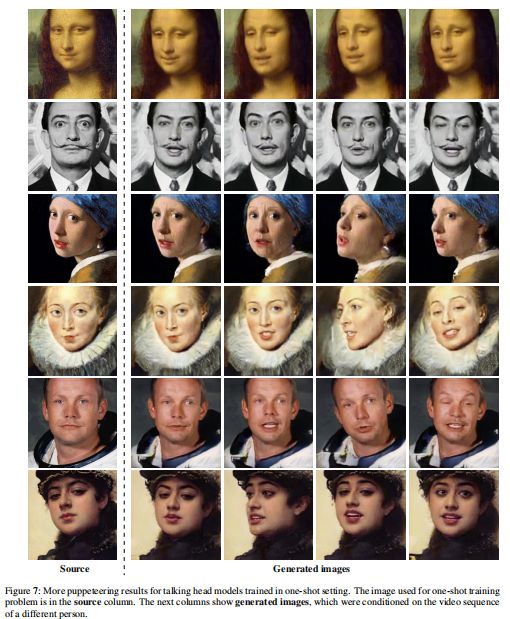
(单张静态画的预测结果)

拿code搞事情

搞不了事情了,以后添置台设备再玩儿吧




长按二维码关注我们
有趣的灵魂在等你



留言请摁
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!