深入解析serialVersionUID原理及其使用场景
深入解析serialVersionUID及其使用
相信经常写项目以及研究源码的读者朋友一定没少见这行代码:
static final long serialVersionUID = -5024744406713321676L;
那么这行代码到底是干什么的呢?什么时候用它?怎么使用?为什么看到有的类中有声明有的类中没声明?它后面那串唯一标识号是根据什么生成的?
带着这些疑问,我们来逐一解开serialVersionUID的面纱。
1、serialVersionUID是什么?
serialVersionUID是Java序列化机制中的一个特殊字段,用于标识序列化类的版本号。它的作用是确保在进行序列化和反序列化时,类的版本一致,以避免兼容性问题。
2、什么是序列化和反序列化?
序列化(Serialization)是将对象转换为字节流的过程,以便将其存储到文件、内存中进行传输或在网络中进行传输。反序列化(Deserialization)则是将字节流转换回对象的过程,以便恢复对象的状态和数据。
序列化和反序列化的主要目的是在不同的计算机环境或进程之间传递对象,并且保持对象的完整性和一致性。
它们在以下情况下非常有用:
-
持久化对象:将对象保存到磁盘或数据库中,以便后续使用。
-
远程通信:通过网络传输对象,例如在客户端和服务器之间传递数据。
-
对象复制:通过序列化和反序列化创建对象的副本。
以下是序列化与反序列化的常见使用:
-
在Java中,序列化和反序列化可以通过实现
java.io.Serializable接口来实现。这个接口是一个标记接口,没有任何方法,但它确保了被标记的类的对象可以被序列化和反序列化。 -
在序列化过程中,可以使用
ObjectOutputStream类将对象转换为字节流并写入输出流。在反序列化过程中,可以使用ObjectInputStream类从输入流中读取字节流并将其转换回对象。 -
Java的序列化机制可以处理对象的成员变量,并在序列化和反序列化过程中保持对象图的完整性。但需要注意的是,不是所有的对象都可以序列化,有些对象可能会因为不可序列化的成员变量或特定的逻辑而导致序列化失败。
-
序列化和反序列化的过程也可以用于实现深拷贝,即通过序列化对象并将其反序列化回来,创建一个原始对象的独立副本。
注意: 在进行序列化和反序列化时,需要注意版本兼容性和安全性的问题,例如在不同的Java版本之间进行序列化和反序列化时,需要确保对象的兼容性,以及在反序列化时要防止安全漏洞和恶意代码的注入。
2.1关于字节流序列化与Json序列化的3个问题
- 为什么将对象转换为JSON字符串也叫序列化?
在编程中,序列化是指将对象转换为一种可存储或传输的格式,以便在需要时可以还原为对象。虽然传统意义上,序列化通常指的是将对象转换为字节流,但是在更广泛的概念中,序列化也可以指代将对象转换为其他格式,比如JSON字符串。JSON序列化将对象的数据以JSON格式进行表示,以便在不同系统之间进行数据交换和传输。
- JSON序列化和字节流序列化的关系是什么?
JSON序列化和字节流序列化都是将对象转换为不同的表示形式。字节流序列化将对象转换为字节流的形式,适用于底层的数据传输和存储。而JSON序列化将对象转换为JSON字符串的形式,适用于数据交换和跨平台传输。它们的目的都是将对象转换为一种可传输或存储的格式,只是所采用的表示形式不同而已。
- TCP/IP网络传输只支持字节流,那JSON序列化后的字符串传输的时候JVM是会自动将其转换为二进制吗?
TCP/IP网络传输确实只支持字节流的传输。当使用JSON序列化后的字符串进行网络传输时,JVM并不会自动将其转换为二进制。在传输过程中,JSON字符串仍然是以文本形式进行传输的,只是在传输的两端需要将JSON字符串转换为字节流进行传输。发送方可以将JSON字符串编码为字节流,然后通过网络传输。接收方在接收到字节流后,可以解码为JSON字符串再进行解析和处理。
总结: JSON序列化和字节流序列化是两种不同的表示形式,用于将对象转换为不同的格式进行存储或传输。JSON序列化将对象转换为JSON字符串,适用于数据交换和跨平台传输;而字节流序列化将对象转换为字节流,适用于底层的数据传输和存储。在网络传输中,JSON字符串可以通过编码和解码的方式转换为字节流进行传输。
2.2在网络传输中,JSON字符串如何通过编码和解码的方式转换为字节流进行传输?
编码(序列化): 在发送方(客户端)将JSON字符串进行编码时,通常会将其转换为字节数组,以便进行网络传输。这个过程称为编码或序列化。编码的具体步骤如下:
- 将JSON字符串按照指定的字符编码(如UTF-8)转换为字节数组。
- 可选地,可以在字节数组前添加一些额外的标识信息,例如长度信息,以便在接收方解码时能够正确还原。
解码(反序列化): 在接收方(服务器端)接收到字节流后,需要将其解码为原始的JSON字符串。这个过程称为解码或反序列化。解码的具体步骤如下:
- 根据接收到的字节数组,按照相同的字符编码(如UTF-8)将其转换为JSON字符串。
- 可选地,根据编码过程中添加的额外标识信息(如长度信息),从字节数组中提取出实际的JSON字符串部分。
3、什么时候使用它?
例1:
public class TextVo implements Serializable {@Serial@SuppressWarnings("all")private static final long serialVersionUID = -6479963612765539614L;private int id;private String name;
}
例2:
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, java.io.Serializable
{@java.io.Serialstatic final long serialVersionUID = -5024744406713321676L;private transient HashMap<E,Object> map;
例3:
public class AuthConstant {public static final String SMS_CODE_CACHE_PREFIX = "sms:code:";public static final String LOGIN_USER = "loginUser";
}
根据以上代码我们发现一个特征,只有类继承了Serializable接口才会声明serialVersionUID字段。而且声明字段的一般都是实体类。那么我们什么时候需要用到它呢?
以下情况下需要使用serialVersionUID:
- 当类的结构发生变化时:如果对类的结构进行了修改,例如添加、删除或修改了字段、方法、父类等,那么需要更新
serialVersionUID的值。这样可以确保在反序列化时,旧版本的类能够与新版本的类保持兼容性。 - 跨不同的Java虚拟机(JVM)之间进行序列化和反序列化时:如果将序列化的对象存储在文件中或通过网络传输到另一个JVM上,那么在反序列化时需要确保两个JVM上的类版本一致。通过显式地指定相同的
serialVersionUID,可以确保不同JVM上的类能够进行正确的序列化和反序列化操作。 - 控制类的序列化兼容性:在某些情况下,可能需要控制类的序列化兼容性,即只允许特定版本的类进行序列化和反序列化。通过指定固定的
serialVersionUID值,可以实现对类的版本控制,禁止对不兼容的版本进行序列化和反序列化操作。
主要应用场景:不同的Java版本之间进行序列化和反序列化时,可以确保对象的兼容性。
继承了Serializable接口不声明serialVersionUID行不行?
继承了Serializable接口且没有显式声明serialVersionUID是可以的。在这种情况下,Java会根据类的结构自动生成一个默认的序列化版本号。
如果没有显式地定义serialVersionUID,Java会根据类的名称、实现的接口、字段、方法等信息自动生成一个序列化版本号。生成的序列化版本号是基于类的结构计算得出的,它会随着类的结构的变化而变化。
但是,建议在需要控制类的版本兼容性时显式地声明serialVersionUID。通过显式声明serialVersionUID,可以确保在类的结构发生变化时,序列化版本号不会随着自动生成而改变,从而保持序列化兼容性。
4、在IDEA中怎么自动生成serialVersionUID?
在Java的序列化机制中是通过判断类的serialVersionUID来验证版本的一致性的,JVM会将接到的Java对象字节流中的serialVersionUID和本地相应实体类的serialVersionUID进行对比,看下是否是一致的,如果是一致,则进行反序列化操作,如果不是一致的,则会出现InvalidCastException错误。因此,我们常常显示声明serialVersionUID以避免对象不一致问题,为了快速显示声明serialVersionUID,我们需要用到IDEA的Serializable的快捷键功能。
IDEA的Serializable的快捷键设置及使用
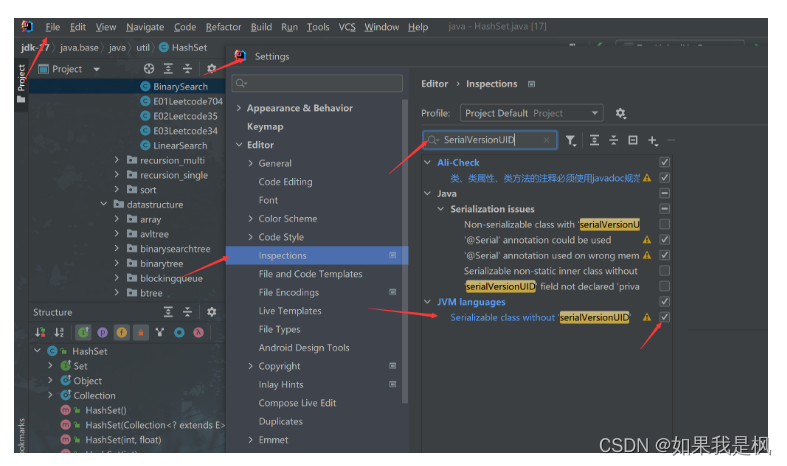
- 选择File->settings->Editor->Inspections,然后在右边搜索框输入“serialVersionUID”再点击确定后,在搜索出的选项里面选择“Serializable class without ‘serialVersionUID’”勾选,然后点击“OK”,完成设置。
- 使用:光标放到实体类的名字上或右键鼠标选择“Show Context Actions”点击
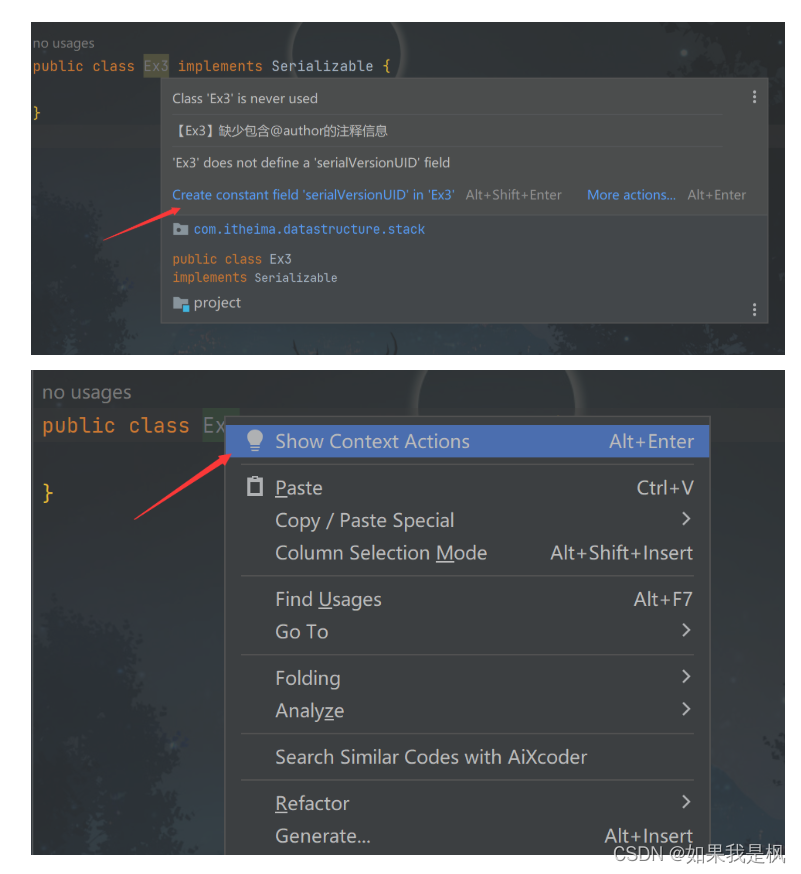
public class Ex3 implements Serializable {@Serialprivate static final long serialVersionUID = 9152089316051495279L;
}
这里@Serial注解是Java 14及以后版本新增的用于显式声明序列化版本号的注解。
5、它后面那串唯一标识号是根据什么生成的?
serialVersionUID有两种显示的生成方式:
①是默认的1L,比如:
private static final long serialVersionUID = 1L;
②是根据包名,类名,继承关系,非私有的方法和属性,以及参数,返回值等诸多因子计算得出的,极度复杂生成的一个64位的哈希字段。基本上计算出来的这个值是唯一的。比如:
private static final long serialVersionUID = 9152089316051495279L;
这样在类发生变化时,如果没有显式指定serialVersionUID,系统会根据类的结构自动生成版本号。
注:这里用的是默认算法,也可以用SHA-1(Secure Hash Algorithm 1)算法和(Message Digest Algorithm 5)算法。
6、总结
以下是serialVersionUID机制的一些关键特点:
- 版本号的定义:serialVersionUID是一个long类型的静态常量字段,通常定义为private static final。它必须是可序列化类的显式声明的字段,并且类型必须为long。
- 版本号的生成规则:serialVersionUID的值是根据类的结构和内容计算生成的。具体生成规则是通过对类的结构、字段、方法、继承关系等信息进行哈希运算来生成一个唯一的版本号。这样,在类发生变化时,如果没有显式指定serialVersionUID,系统会根据类的结构自动生成版本号。
- 版本号的作用:当进行序列化或反序列化操作时,系统会将序列化的对象与目标类的版本号进行比较。如果版本号不匹配,就会抛出InvalidClassException异常,防止不兼容的类进行序列化和反序列化。通过版本号的比较,可以保证在不同版本的类之间进行序列化和反序列化时的兼容性。
在类发生变化时,如果没有显式指定serialVersionUID,系统会根据类的结构自动生成版本号。 - 版本号的作用:当进行序列化或反序列化操作时,系统会将序列化的对象与目标类的版本号进行比较。如果版本号不匹配,就会抛出InvalidClassException异常,防止不兼容的类进行序列化和反序列化。通过版本号的比较,可以保证在不同版本的类之间进行序列化和反序列化时的兼容性。
- 手动指定版本号:为了更好地控制类的版本号,可以显式地在类中声明serialVersionUID字段,并赋予一个特定的值。这样可以确保在类发生更改时,通过更新serialVersionUID来表明类的版本已更改,从而控制序列化和反序列化的兼容性。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!