java 爬虫大型教程(四)
java 爬虫大型教程(四)
基本爬虫进阶(二)
1. 爬虫的监控
你可以利用爬虫的监控功能查看爬虫的执行情况——已经下载了多少页面、还有多少页面、启动了多少线程等信息。该功能通过JMX实现,你可以使用Jconsole等JMX工具查看本地或者远程的爬虫信息。
如果你完全不会JMX也没关系,因为它的使用相对简单,这次教程比较详细的讲解使用方法。如果要弄明白其中原理,你可能需要一些JMX的知识,推荐阅读:JMX整理。
注意: 如果你自己定义了Scheduler,那么需要用这个类实现MonitorableScheduler接口,才能查看“LeftPageCount”和“TotalPageCount”这两条信息。
1.1 为项目添加监控
添加监控非常简单,获取一个SpiderMonitor的单例SpiderMonitor.instance(),并将你想要监控的Spider注册进去即可。你可以注册多个Spider到SpiderMonitor中,这里对前面的例子在进行改造一下,增加监控功能。
public static void main(String[] args) throws Exception {long startTime, endTime;System.out.println("开始爬取...");startTime = System.currentTimeMillis();Spider cnblogSpider = Spider.create(new CdnRepoPageProcessor())//从https://www.cnblogs.com开始抓.addUrl("https://www.cnblogs.com/")//指定数据存储路径.addPipeline(new JsonFilePipeline("/Users/duke/IdeaProjects/javaspider/data"))//开启3个线程抓取.thread(3);//注册爬虫到spiderMonitor中,你可以在创建多个爬虫并且注册SpiderMonitor.instance().register(cnblogSpider);//开始爬虫,以创建的爬虫对象名开启,可以开启多个cnblogSpider.start();endTime = System.currentTimeMillis();System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");}
1.2 查看监控信息
WebMagic的监控使用JMX提供控制,你可以使用任何支持JMX的客户端来进行连接。我们这里以JDK自带的JConsole为例。我们首先启动WebMagic的一个Spider,并添加监控代码,然后我们通过JConsole来进行查看。在命令行输入jconsole(windows下是在DOS下输入jconsole.exe)即可启动JConsole。
为了防止你使用前面的例子无法观测到监控信息,你需要在加个线程sleep,这样,你就可以顺利的观察到监控信息。
if(page.getResultItems().get("articleTitle")== null){//skip this pagepage.setSkip(true);}else {System.out.println("抓取的内容:"+ page.getResultItems().get("articleTitle"));//在这里加上线程暂停,可以顺利的查看监控信息,当然正式的项目中,没有必要加的try{Thread.sleep(5000);}catch(Exception e){System.exit(0);//退出程序}count ++;}
首先,在控制台输入命令:
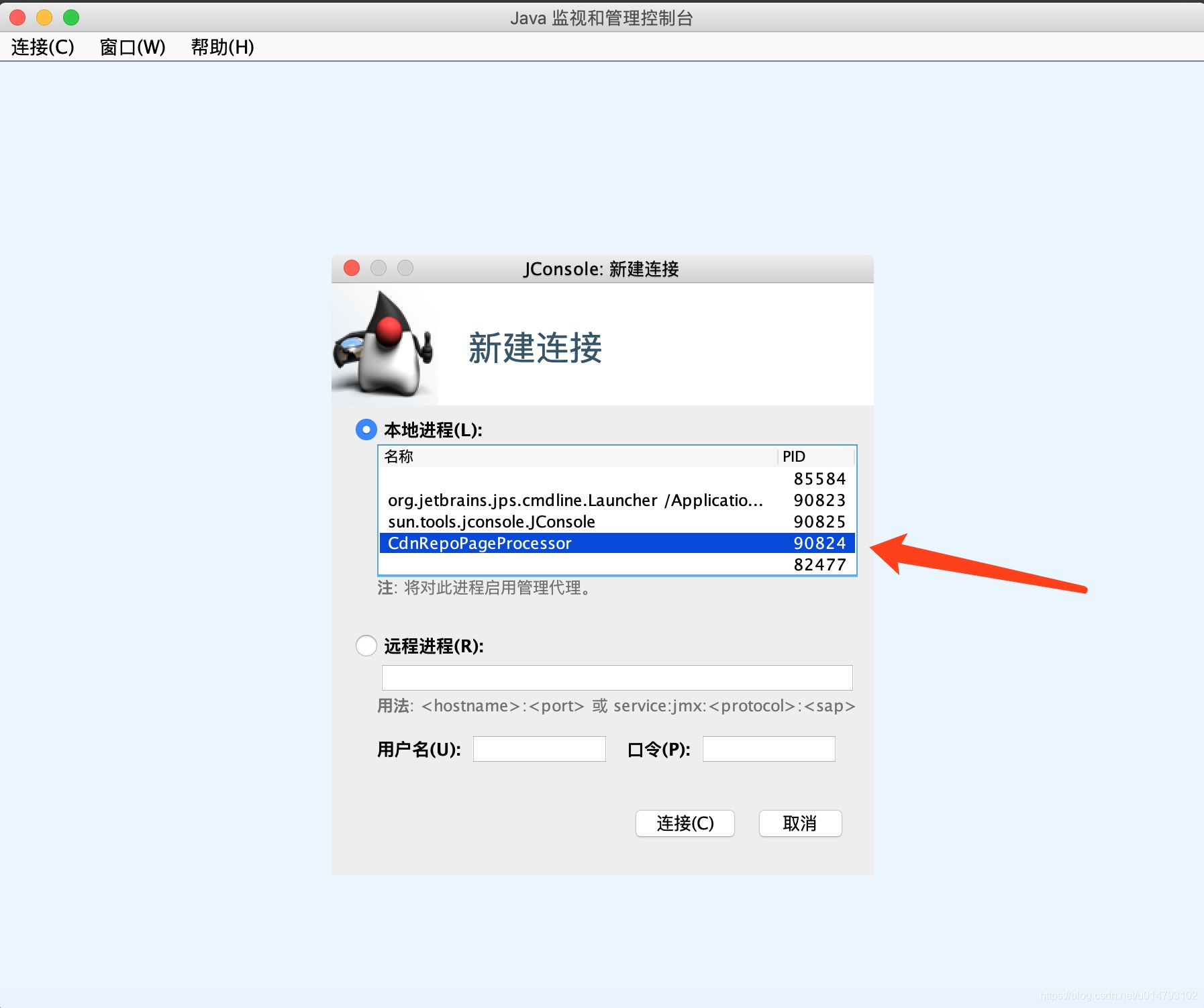
接着,会启动JConsole,选择你要监控的爬虫实例进程:
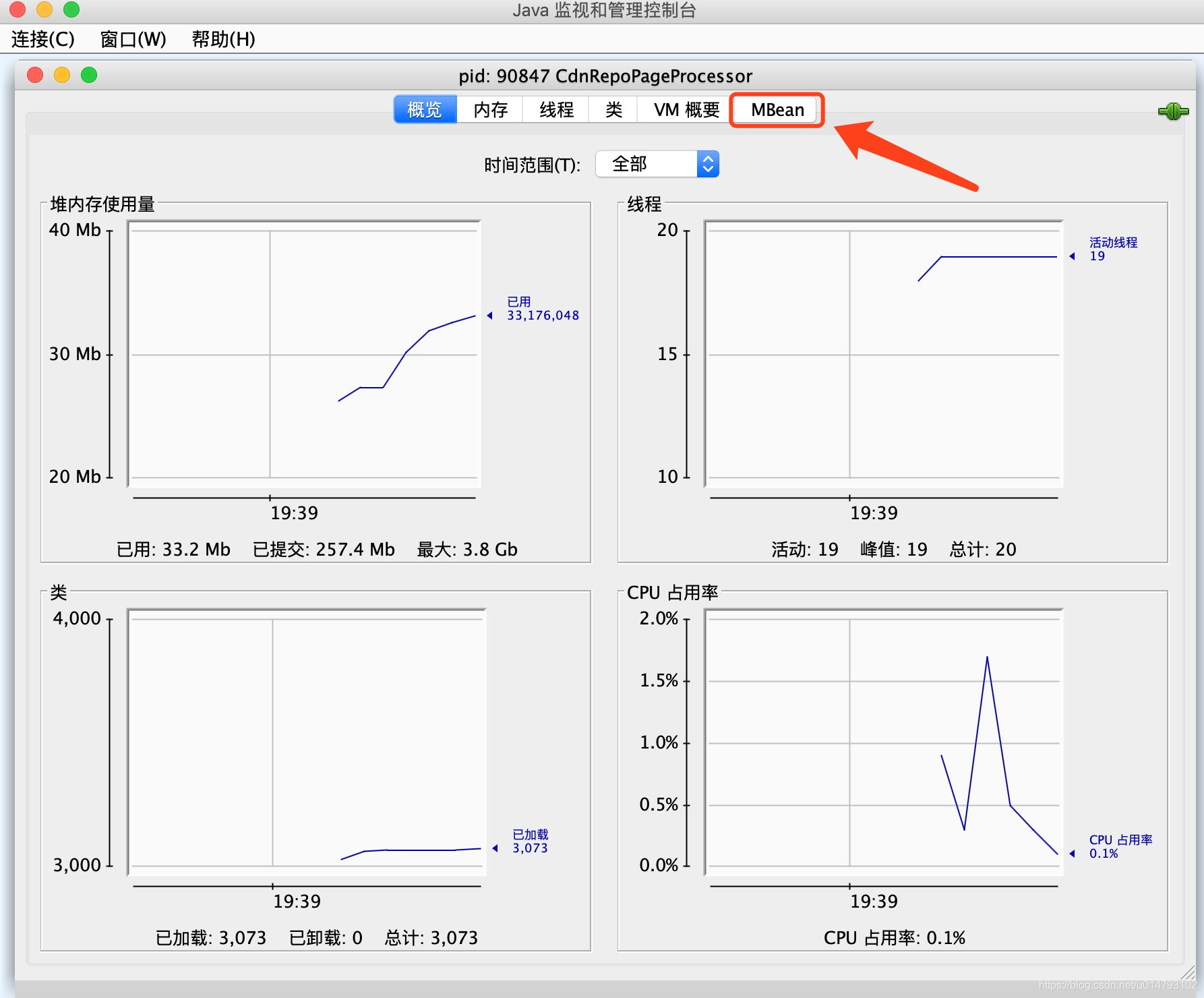
连接之后,选择MBean:
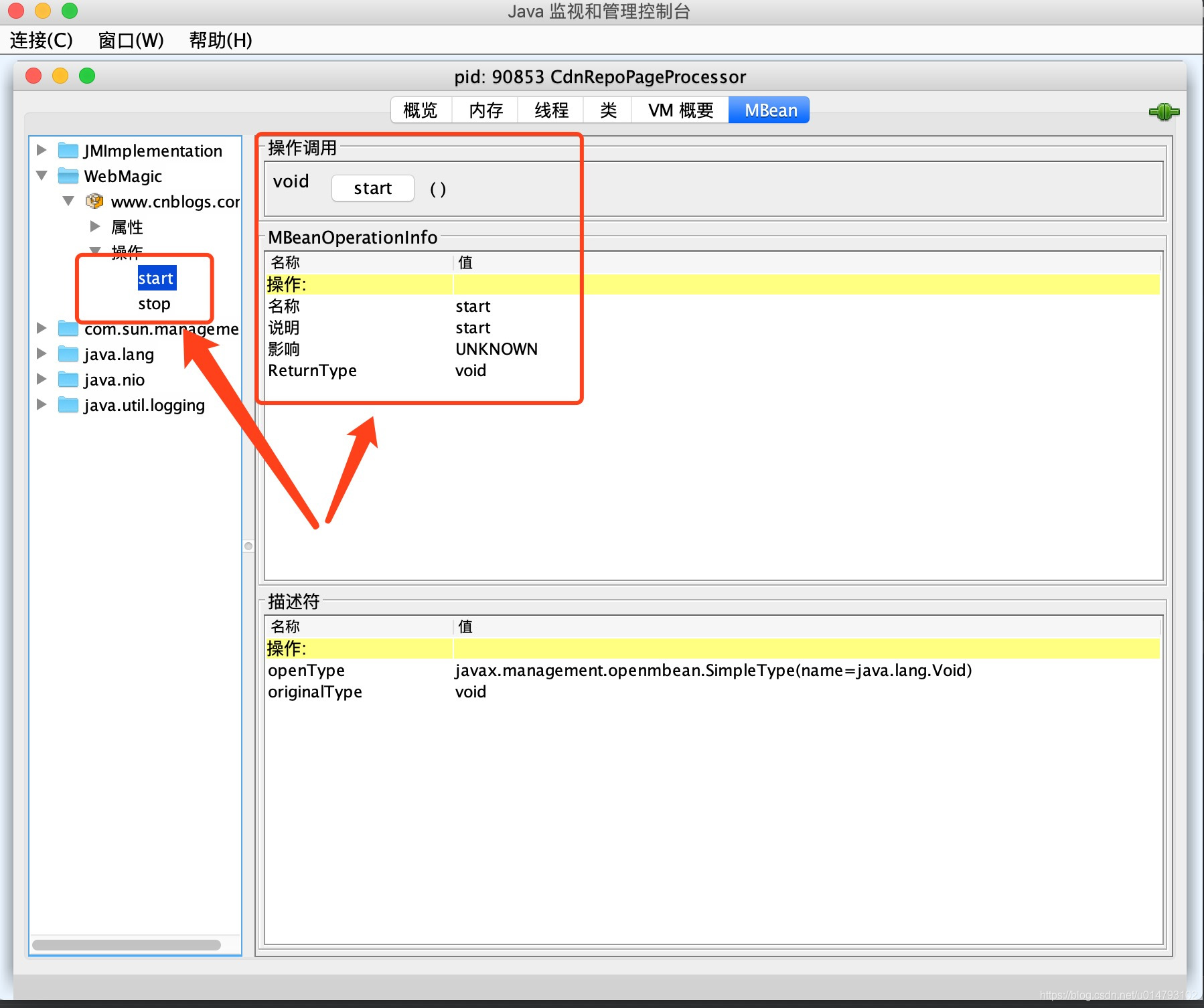
然后点开“WebMagic”,就能看到所有已经监控的Spider信息了!这里我们也可以选择“操作”,在操作里可以选择启动-start()和终止爬虫-stop(),这会直接调用对应Spider的start()和stop()方法,来达到基本控制的目的:
2. 配置代理
WebMagic使用APIProxyProvider。相对于Site的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。
| API | 说明 |
|---|---|
| HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider) | 设置代理 |
ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
代理示例:
1.设置单一的普通HTTP代理为101.101.101.101的8888端口,并设置密码为"username",“password”
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("101.101.101.101",8888,"username","password")));spider.setDownloader(httpClientDownloader);
2.设置代理池,其中包括101.101.101.101和102.102.102.102两个IP,没有密码
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("101.101.101.101",8888),new Proxy("102.102.102.102",8888)));
3. 处理非HTTP GET请求
一般来说,爬虫只会抓取信息展示类的页面,所以基本只会处理HTTP GET方法的数据。但是对于某些场景,模拟POST等方法也是需要的,采用在Request对象上添加Method和requestBody来实现。
Request request = new Request("http://xxx/path");
request.setMethod(HttpConstant.Method.POST);
request.setRequestBody(HttpRequestBody.json("{'id':1}","utf-8"));
HttpRequestBody内置了几种初始化方式,支持最常见的表单提交、json提交等方式。
| API | 说明 |
|---|---|
| HttpRequestBody.form(Map\ params, String encoding) | 使用表单提交的方式 |
| HttpRequestBody.json(String json, String encoding) | 使用JSON的方式,json是序列化后的结果 |
| HttpRequestBody.xml(String xml, String encoding) | 设置xml的方式,xml是序列化后的结果 |
| HttpRequestBody.custom(byte[] body, String contentType, String encoding) | 设置自定义的requestBody |
POST的去重:
POST默认不会去重,如果想要去重可以自己继承DuplicateRemovedScheduler,重写push方法。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!