Xpath 表达式学习及例子
学习scrapy的使用(二)
- 1.Xpath 表达式
- 2 BeautifulSoup
- 3.例子
1.Xpath 表达式
效率高,但是功能没有正则表示式强大。一般选择正则表达式。不能解决就用正则表达式。
xpath表达式:
/ 逐层提取
/html/head/title
实例:
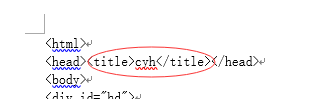
text() 提取标签下的文本
/html/head/title/text()
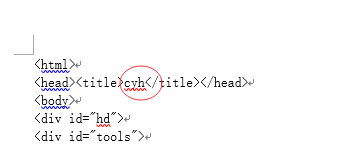
//标签名** 提取所有**的标签
//div
//标签名[@数学=‘属性值‘] 提取属性为XX的标签
@属性名 代表取某个属性
提取div中
针对用浏览器的获取某个属性值用get_attribute(‘src’)
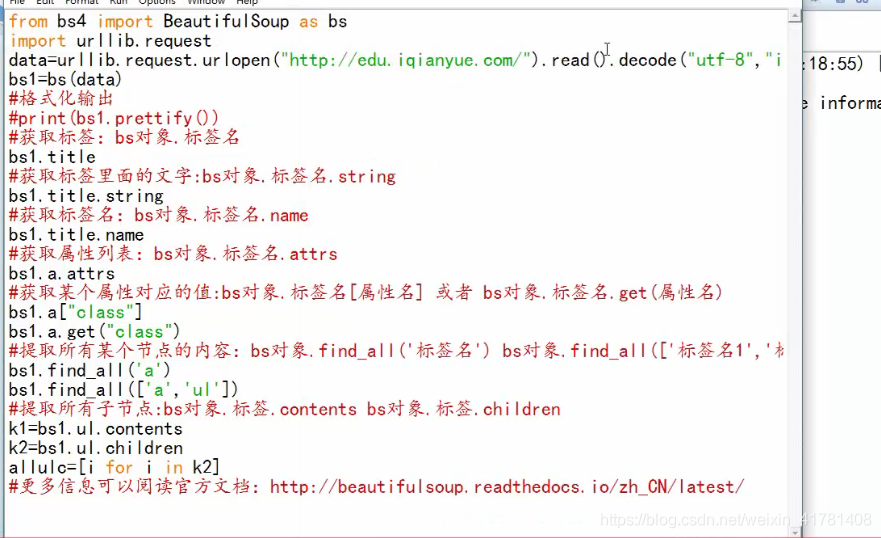
2 BeautifulSoup
from bs4 imort BeautifulSoup as bs
import urllib.request
data=urllib.request.urlopen(网址).read().decode("utf8“,“ignore”)
bs1=bs(data)
格式化输出,
bs1.prettify()
获取标签:bs对象.标签名
bs1.title
#获取

3.例子
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!