Spark的kryo性能测试以及RDD持久化级别
MEMORY_ONLY
代码如下
package com.yxw.Testimport org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SparkConf, SparkContext}object KryoTest000 {def main(args: Array[String]): Unit = {//定义输入输出路径val inputpath = new Path(args(0)) //file:///E:/BaiduNetdiskDownload/cleaned.logval outputpath = new Path(args(1)) //file:///E:/BaiduNetdiskDownload/outputpath//连接hdfsval fsConf = new Configuration()val fs = FileSystem.get(fsConf)//路径存在就删除if (fs.exists(outputpath)){fs.delete(outputpath,true)val path = args(1).toStringprintln(s"已经删除存在的路径 $path")}//创建sparkcontextval conf = new SparkConf().setAppName("KryoTest000APP").setMaster("local[4]")val sc = new SparkContext(conf)//得到文件 创建RDDval files = sc.textFile(args(0))// files.foreach(println)//调用utils 持久化val res = KryoUtils.logCache(files)//res.collect()// //序列化方式存到内存KryoUtils.saveLog(res,args(1))
//Thread.sleep(50000) //睡50s 以便观察webUI}
}
KryoUtils.scala
package com.yxw.Testimport org.apache.spark.rdd.RDDcase class INFO(cdn: String, region: String, level: String, date: String, ip: String, domain: String, url: String, traffic: String)object KryoUtils {//baidu CN E 2018050103 222.73.34.128 rw.uestc.edu.cn http://rw.uestc.edu.cn/user_upload/15316339776271051.html 72071def logCache(logs: RDD[String]): RDD[INFO] = {logs.filter(_.split("\t").length == 8).map(log => {val info = log.split("\t")INFO(info(0), info(1), info(2), info(3), info(4), info(5), info(6), info(7))}).cache()}def saveLog(logsCache: RDD[INFO], outputpath: String) = {logsCache.map(logCache => {logCache.cdn + "\t" + logCache.region + "\t" + logCache.level + "\t" +logCache.date + "\t" + logCache.ip + "\t" + logCache.domain + "\t" + logCache.url + "\t" + logCache.traffic}).repartition(1).saveAsTextFile(outputpath)}
}
运行的结果如图:
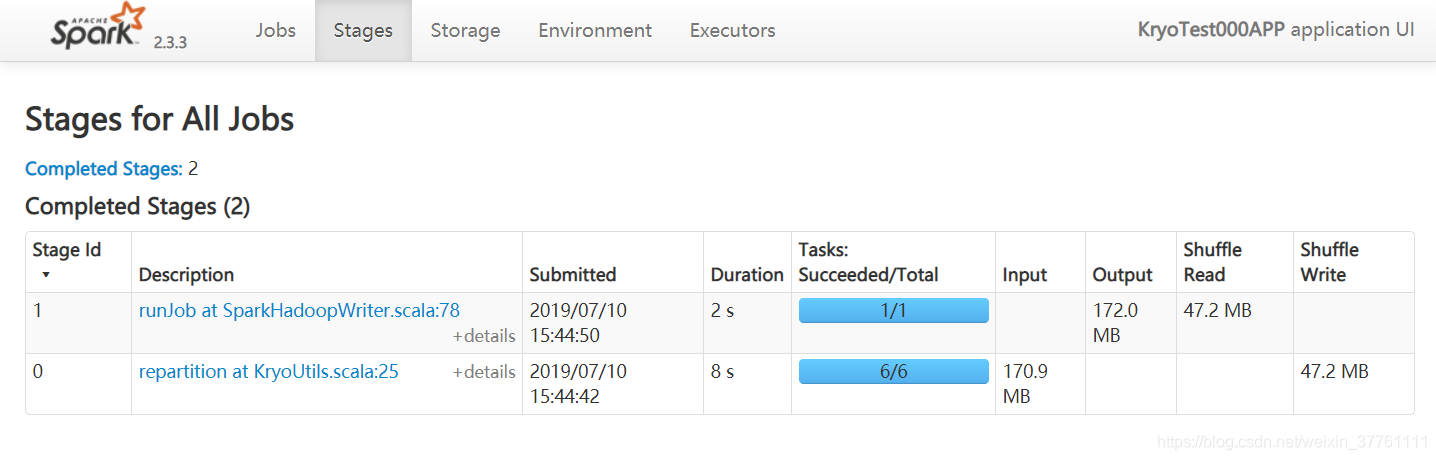
由于有个shuffle操作 共耗时10s
cache的大小为:
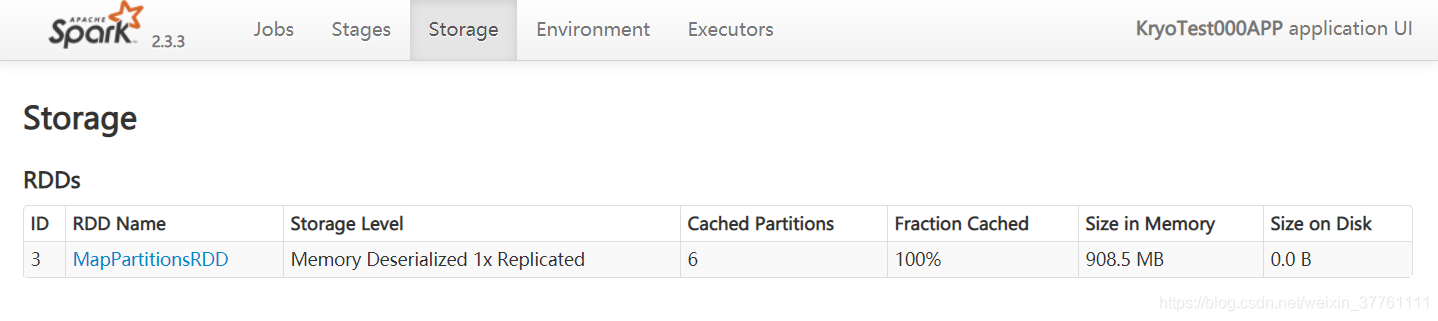
900多M,这简直恐怖
MEMORY_ONLY_SER 未使用kryo序列化
修改代码:

结果如下:
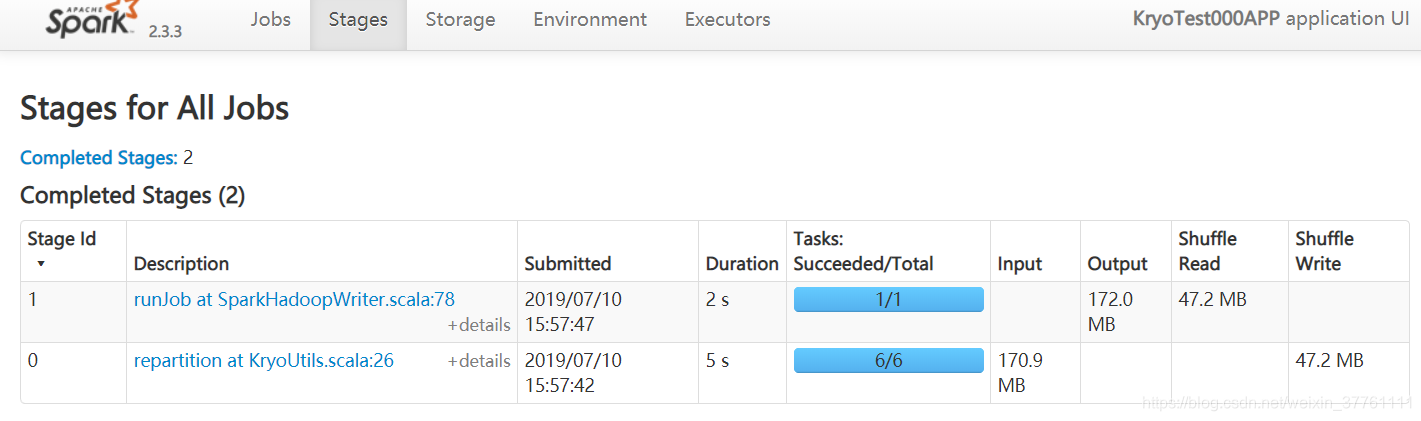
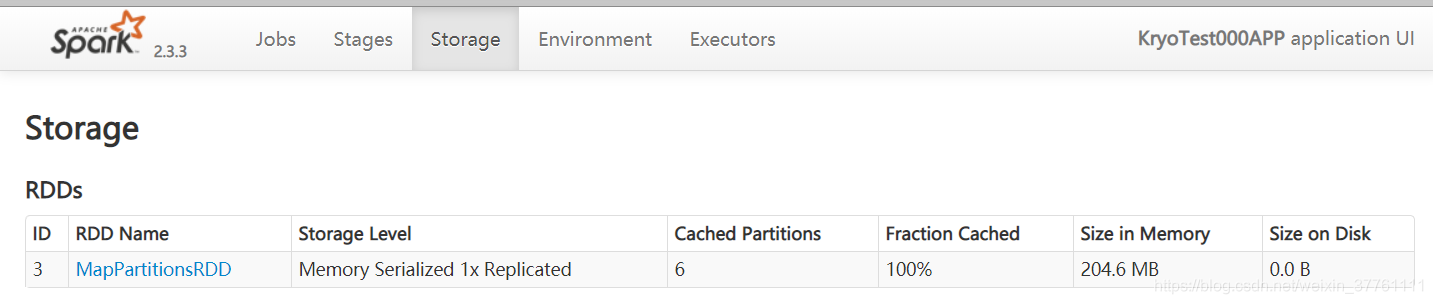
序列化后占用内存已经显著减小,耗时也减小为7s
MEMORY_ONLY_SER 使用kryo序列化未注册
代码修改如下:

结果如下:
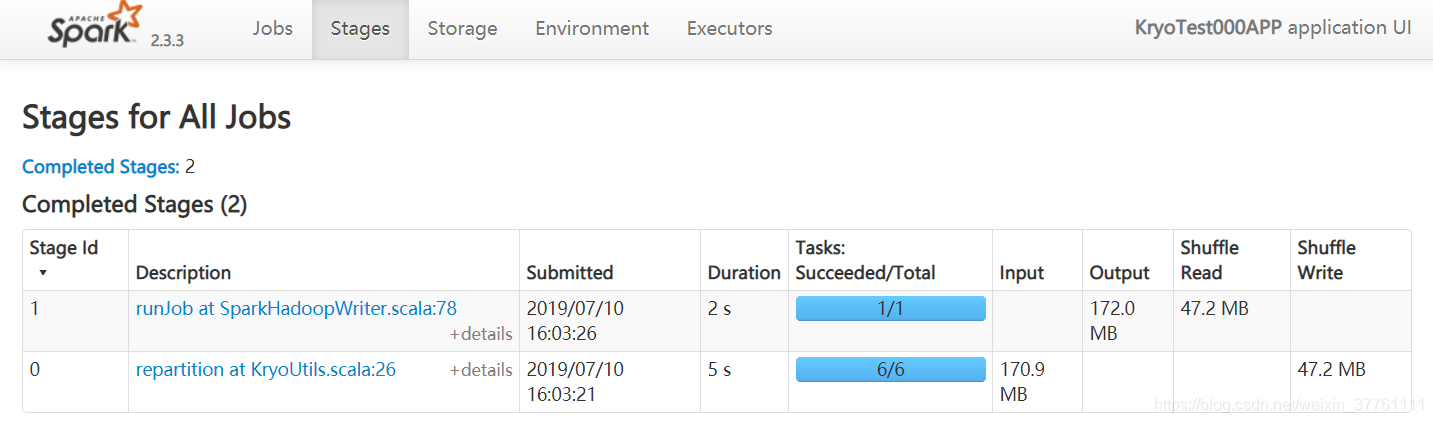
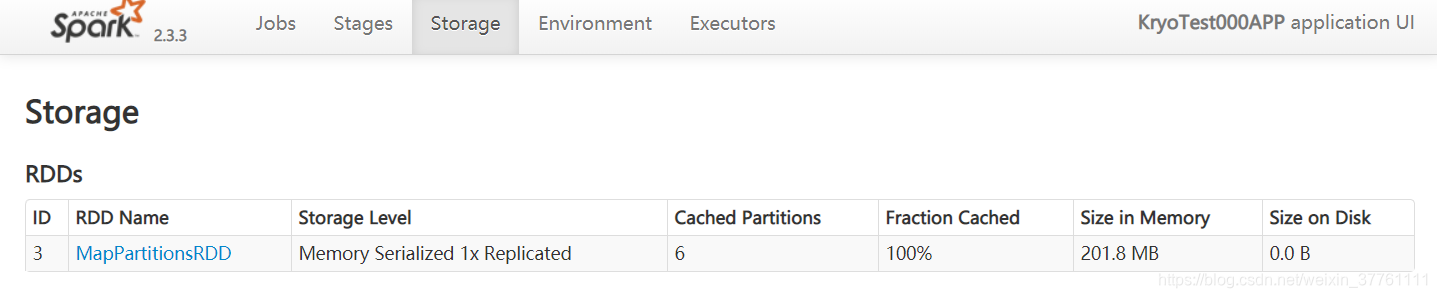
耗时差不多,都是7s,但是内存占用稍微减小
MEMORY_ONLY_SER 使用kryo序列化并注册
修改代码如下:

结果如图所示:
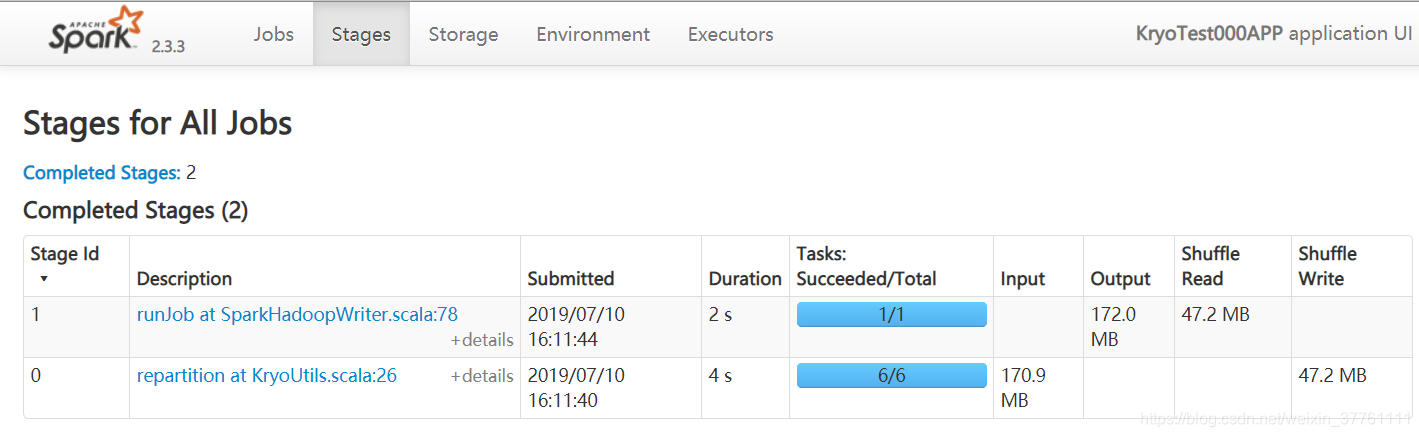
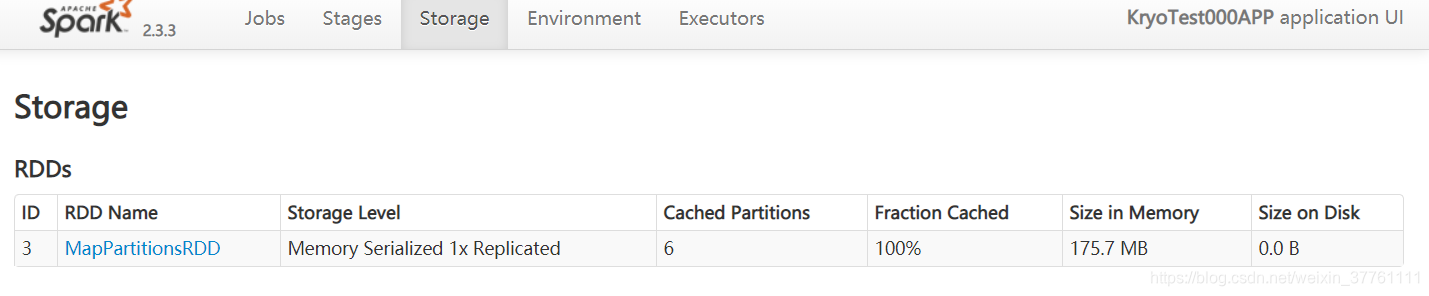
可以看到速度,内存占用都是以上几组测试用最优的
注册kryo序列化并开启RDD压缩
这个测试是网上看来的
注意:RDD压缩只能存在于序列化的情况下
修改代码如图:

运行结果如图:
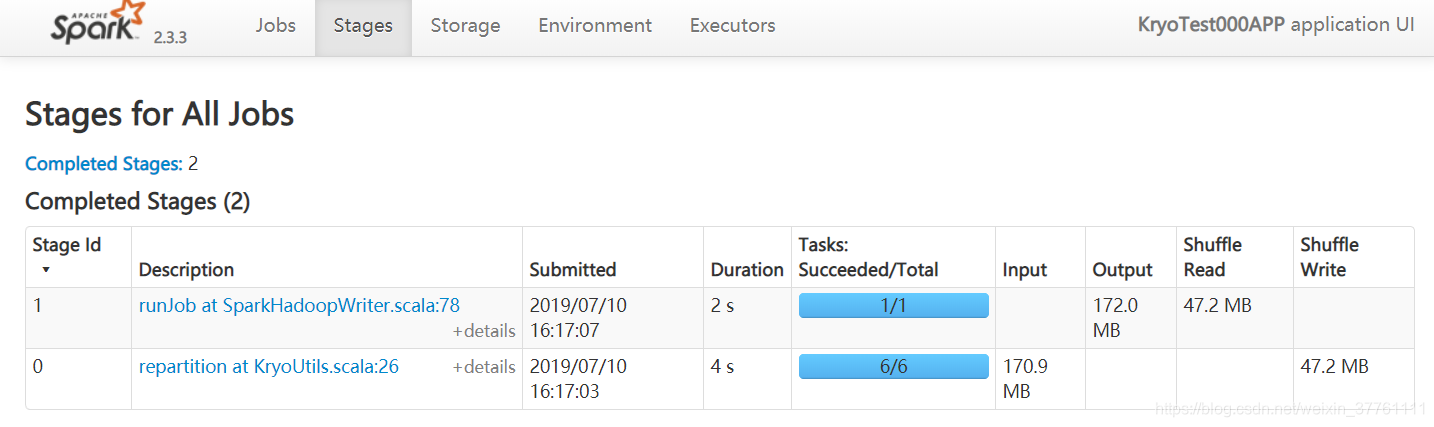
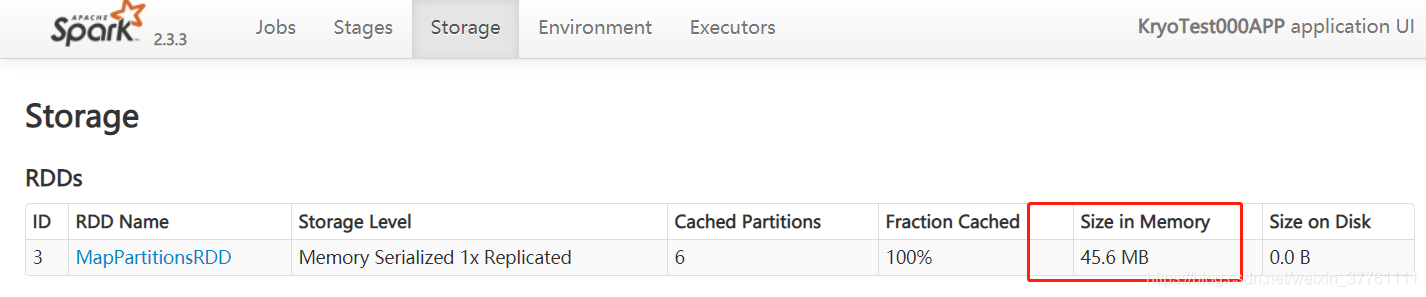
持久化的内存占用大小仅为45M左右!!!
spark.rdd.compress
这个参数决定了RDD Cache的过程中,RDD数据在序列化之后是否进一步进行压缩再储存到内存或磁盘上。当然是为了进一步减小Cache数据的尺寸,对于Cache在磁盘上而言,绝对大小大概没有太大关系,主要是考虑Disk的IO带宽。而对于Cache在内存中,那主要就是考虑尺寸的影响,是否能够Cache更多的数据,是否能减小Cache数据对GC造成的压力等。
这两者,前者通常不会是主要问题,尤其是在RDD Cache本身的目的就是追求速度,减少重算步骤,用IO换CPU的情况下。而后者,GC问题当然是需要考量的,数据量小,占用空间少,GC的问题大概会减轻,但是是否真的需要走到RDD Cache压缩这一步,或许用其它方式来解决可能更加有效。
所以这个值默认是关闭的,但是如果在磁盘IO的确成为问题或者GC问题真的没有其它更好的解决办法的时候,可以考虑启用RDD压缩。
以上
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!