如何快速用LangChain打造一个智能问答小客服?仅需40行代码!(含代码)
我们该如何应用LangChain进行多种的开发呢?在写一些项目的时候我们经常离不开要阅读一些开源产品的代码,而这个智能问答小客服就是在LangChain源代码上进行微小改动写出来的,能够更加清晰LangChain的结构。一起来看看吧!希望通过这个例子能帮助大家更加理解LangChain。
框架设计
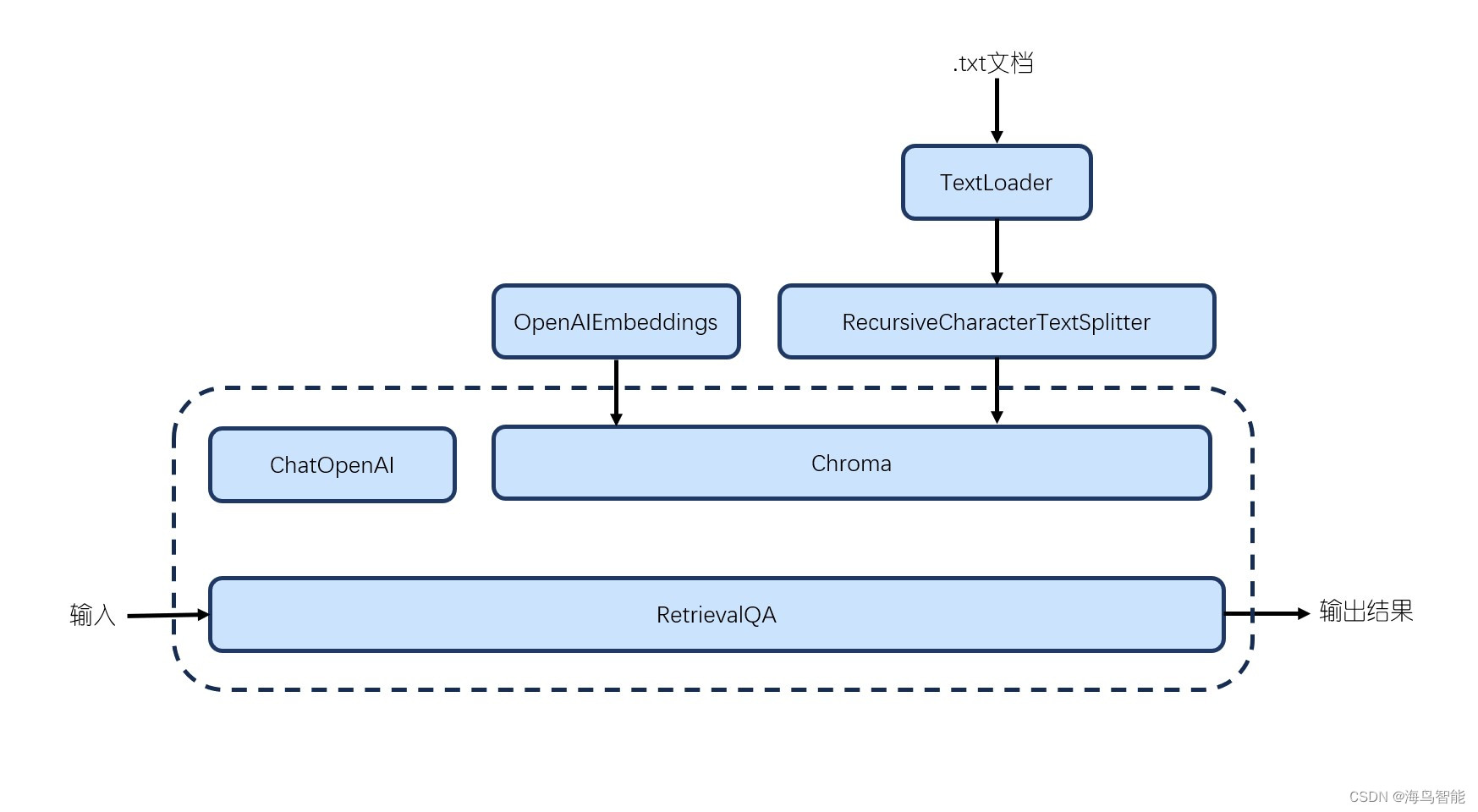
组件一览:
| 组件 | 类型 | 子类型 |
| TextLoader | 索引组件 | 文本加载器 |
| RecursiveCharacterTextSplitter | 索引组件 | 文本分割器 |
| RetrievalQA | 链组件 | 对话链 |
| ChatOpenAI | 模型组件 | LLM |
| OpenAIEmbeddings | 模型组件 | 文本嵌入模型 |
| Chroma | 索引组件 | VectorStores |
准备工作
安装依赖
pip install langchain
pip install openai
pip install chromadb
pip install tiktoken设置密钥
import os
import openai os.environ["OPENAI_API_KEY"] = 'your_openai_key'
os.environ['OPENAI_API_BASE'] = ''导入库和TXT加载器
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI开始编码
加载txt文本数据
使用TextLoader加载名为qa.txt的文本文件,并将其存储在data变量中。
loader = TextLoader('qa.txt')
data = loader.load()分割文本
使用RecursiveCharacterTextSplitter将文本数据分割成多个片段,存储在all_splits变量中。
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 50, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)chunk_size是将这个长字符串按照设置的字符数拆分。
chunk_overlap 参数用于指定文本切分时的重叠量(overlap),表示每个分块的前后两个分块之间会有多少个字符是重复的。这样做的目的是避免关键信息被切分。
创建向量存储器
创建一个Chroma向量存储器,并使用OpenAIEmbeddings作为嵌入器,将分割后的文本片段作为输入,存储在vectorstore变量中。
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())用户输入循环
进入一个无限循环,提示用户输入问题。
while True:print("请输入问题,例如:弦丝画制作的活动时长是多少?")query = input("请输入:")if "end" == query:breakquestion = queryprint(f"问题:{question}")创建问答链
创建一个ChatOpenAI实例,使用"GPT-3.5-turbo"模型和温度值为0。然后,使用RetrievalQA.from_chain_type方法,将ChatOpenAI实例和vectorstore作为检索器,创建一个问答链。
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)获取并打印回答
将用户输入的问题作为查询传递给问答链,并将结果存储在ret变量中。然后,打印出回答结果。
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever()) ret = qa_chain({"query": question})print(f"回答:{ret['result']}")运行主函数
如果当前文件被直接执行(而不是被导入为模块),则调用run()函数。
if '__main__' == __name__:run()qa.txt 内容
问题:扎染围巾的活动时长是多少?
答案:扎染围巾的活动时长是1.5—2小时。
问题:扎染围巾的价格是多少元一位?
答案:扎染围巾的价格是120元/人。
问题:制作土耳其水拓画的活动时长是多少?
答案:制作土耳其水拓画的活动时长是1.5—2小时。
问题:制作土耳其水拓画的价格是多少元一位?
答案:制作土耳其水拓画的价格是100元/人。
问题:北京绢人(标准版)的制作价格是多少元一位?
答案:北京绢人(标准版)的制作价格是150元/人。
问题:北京绢人(唐人坊精装版)的制作价格是多少元一位?
答案:北京绢人(唐人坊精装版)的制作价格是200元/人。
问题:捕梦网的制作活动时长是多少?
答案:捕梦网的制作活动时长是1—1.5小时。
问题:捕梦网的制作价格是多少元一位?
答案:捕梦网的制作价格是130元/人。
问题:马卡龙塑料框的光影纸雕灯制作价格是多少元一位?
答案:马卡龙塑料框的光影纸雕灯制作价格是160元/人。
问题:木框的光影纸雕灯制作价格是多少元一位?
答案:木框的光影纸雕灯制作价格是180元/人。
问题:弦丝画制作的活动时长是多少?
答案:弦丝画制作活动时长是2—3小时。
问题:用弦丝画制作福字是多少元一位?
答案:用弦丝画制作福字、旺字等单字款价格120元/人。
问题:用弦丝画制作旺字是多少元一位?
答案:用弦丝画制作福字、旺字等单字款价格120元/人。
问题:用弦丝画制作喜字是多少元一位?
答案:用弦丝画制作福字、旺字等单字款价格120元/人,其他图案款请咨询详谈。
问题:端午节香囊的制作价格是多少元一位?
答案:端午节香囊价格100元/人。
问题:中秋节月饼的制作价格是多少元一位?
答案:中秋节月饼价格120元/人。执行结果演示
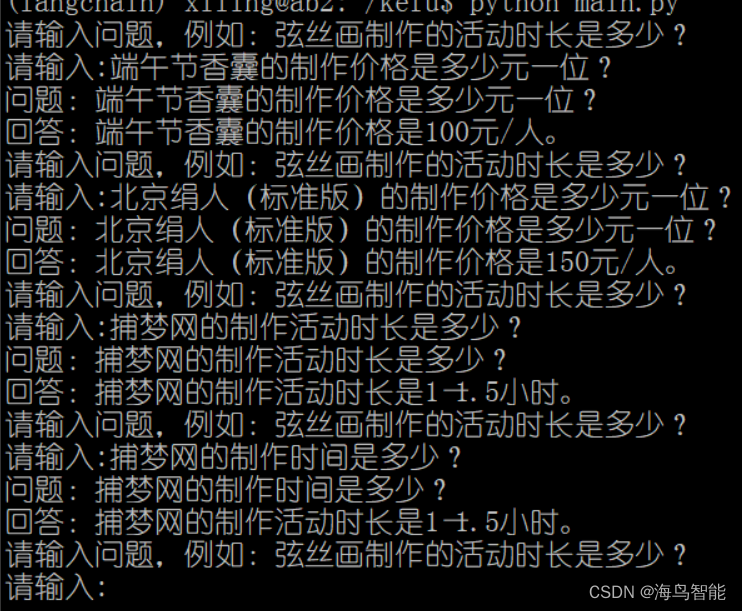
(可以换种问法尝试,我把“活动时长”改为“时间”尝试了一下)
报错与解决
在运行代码中遇到过两种问题:
报错1:Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1
解决办法:增加txt文本的长度或减少切割长度

报错2:(无关紧要,可以忽略)python3.10/site-packages/sklearn/svm/_classes.py:32: FutureWarning: The default value of dual will change from True to 'auto' in 1.5. Set the value of dual explicitly to suppress the warning.
warnings.warn(
解决办法:加入代码
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)完整代码(点击即可进入)
小结
以上就是我在配置并使用用LangChain打造一个智能问答小客服分享,希望可以帮到各位!欢迎关注或发私信与我共同讨论更多大模型领域知识~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!