Spring Data JPA——多表设计、一对多、多对多、多表查询
目录
- 一、多表设计
- 二、JPA中的一对多
- 1、一对多映射的注解说明
- 2、一对多的操作(添加、删除、级联)
- 三、JPA中的多对多
- 1、多对多映射的注解说明
- 2、多对多的操作(添加、删除、级联)
- 四、Spring Data JPA中的多表查询
- 五、总结
一、多表设计
1、表之间关系的划分
数据库中多表之间存在着三种关系,如图所示。
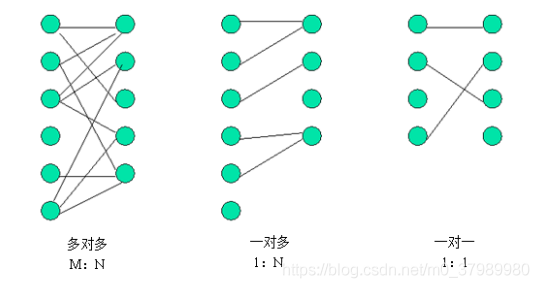
从图可以看出,系统设计的三种实体关系分别为:多对多、一对多和一对一关系。注意:一对多关系可以看为两种: 即一对多,多对一。所以说四种更精确。
实际开发中常用的关联关系,一对多和多对多。而一对一的情况,在实际开发中几乎不用。
2、在JPA框架中表关系的分析步骤
跳转到目录
在实际开发中,我们数据库的表难免会有相互的关联关系,在操作表的时候就有可能会涉及到多张表的操作。而在这种实现了ORM思想的框架中(如JPA),可以让我们通过操作实体类就实现对数据库表的操作。所以今天我们的学习重点是:掌握配置实体之间的关联关系。
第一步:首先确定两张表之间的关系。
- 如果关系确定错了,后面做的所有操作就都不可能正确。
第二步:在数据库中实现两张表的关系
第三步:在实体类中描述出两个实体的关系
第四步:配置出实体类和数据库表的关系映射(重点)
二、JPA中的一对多
跳转到目录
1、示例分析
我们采用的示例为客户和联系人。
客户:指的是一家公司,我们记为A。
联系人:指的是A公司中的员工。
在不考虑兼职的情况下,公司和员工的关系即为一对多。
2、表关系建立
一对多的关系中,
关系在一的一方
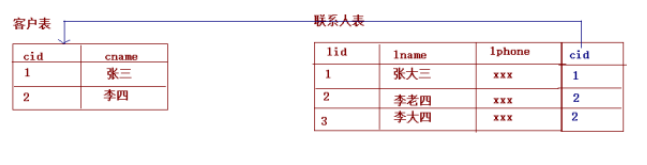
在一对多关系中,我们习惯把一的一方称之为主表,把多的一方称之为从表。在数据库中建立一对多的关系,需要使用数据库的外键约束。
什么是外键?
- 指的是
从表中有一列,取值参照主表的主键,这一列就是外键。
一对多数据库关系的建立,如下图所示
3、实体类关系建立以及映射配置
- 在实体类中,由于
客户是少的一方,它应该包含多个联系人,所以实体类要体现出客户中有多个联系人的信息,代码如下:
Customer
/*** 1.实体类和表的映射关系* @Eitity* @Table* 2.类中属性和表中字段的映射关系* @Id* @GeneratedValue* @Column*/
@Entity
@Table(name = "cst_customer")
public class Customer {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name="cust_id")private Long custId;@Column(name="cust_address")private String custAddress;@Column(name="cust_industry")private String custIndustry;@Column(name="cust_level")private String custLevel;@Column(name="cust_name")private String custName;@Column(name="cust_phone")private String custPhone;@Column(name="cust_source")private String custSource;// 配置客户和联系人之间的关系(一对多关系)// 客户 : 联系人 ==> 1 : n 的关系 ==> 关系在1的一方, 也就是说1的一方为主表, n的一方为// 从表; 而外键设置在从表上/*** 使用注解的形式配置多表关系* 1. 声明关系* 2. 配置外键(中间表)*/
// @OneToMany(targetEntity = LinkMan.class)
// @JoinColumn(name = "lkm_cust_id", referencedColumnName = "cust_id")/*** 放弃外键维护权* mappedBy: 对方配置关系的属性名称\* cascade : 配置级联(可以配置到设置多表的映射关系的注解上)* CascadeType.all : 所有* MERGE :更新* PERSIST :保存* REMOVE :删除** fetch : 配置关联对象的加载方式* EAGER :立即加载* LAZY :延迟加载*/@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL)private Set<LinkMan> linkMans = new HashSet<>();// 省略 getter/setter, toString方法
}
LinkMan
@Entity
@Table(name = "cst_linkman")
public class LinkMan {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "lkm_id")private Long lkmId; //联系人编号(主键)@Column(name = "lkm_name")private String lkmName;//联系人姓名@Column(name = "lkm_gender")private String lkmGender;//联系人性别@Column(name = "lkm_phone")private String lkmPhone;//联系人办公电话@Column(name = "lkm_mobile")private String lkmMobile;//联系人手机@Column(name = "lkm_email")private String lkmEmail;//联系人邮箱@Column(name = "lkm_position")private String lkmPosition;//联系人职位@Column(name = "lkm_memo")private String lkmMemo;//联系人备注/*** 配置联系人到客户的多对一关系* 使用注解的形式配置多对一关系* 1.配置表关系* @ManyToOne : 配置多对一关系* targetEntity:对方的实体类字节码* 2.配置外键(中间表)** * 配置外键的过程,配置到了多的一方,就会在多的一方维护外键*/@ManyToOne(targetEntity = Customer.class,fetch = FetchType.LAZY)@JoinColumn(name = "lkm_cust_id",referencedColumnName = "cust_id")private Customer customer;// 省略 getter/setter, toString方法
}
4、一对多映射的注解说明
跳转到目录
@OneToMany:作用:建立一对多的关系映射属性:targetEntityClass:指定多的多方的类的字节码mappedBy:指定从表实体类中引用主表对象的名称。cascade:指定要使用的级联操作fetch:指定是否采用延迟加载orphanRemoval:是否使用删除@ManyToOne作用:建立多对一的关系属性:targetEntityClass:指定一的一方实体类字节码cascade:指定要使用的级联操作fetch:指定是否采用延迟加载optional:关联是否可选。如果设置为false,则必须始终存在非空关系。@JoinColumn作用:用于定义主键字段和外键字段的对应关系。属性:name:指定外键字段的名称referencedColumnName:指定引用主表的主键字段名称unique:是否唯一。默认值不唯一nullable:是否允许为空。默认值允许。insertable:是否允许插入。默认值允许。updatable:是否允许更新。默认值允许。columnDefinition:列的定义信息。
5、一对多的操作(添加、删除、级联)
跳转到目录
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class OneToManyTest {@Autowiredprivate CustomerDao customerDao;@Autowiredprivate LinkManDao linkManDao;/*** 保存一个客户,保存一个联系人* 效果:客户和联系人作为独立的数据保存到数据库中* 联系人的外键为空* 原因?* 实体类中没有配置关系*/@Test@Transactional // 配置事务@Rollback(false) // 不自动回滚public void testAdd() {// 创建一个客户, 创建一个联系人Customer customer = new Customer();customer.setCustName("阿里");LinkMan linkMan = new LinkMan();linkMan.setLkmName("小桂");/*** 配置了客户到联系人的关系* 从客户的角度上:发送两条insert语句,发送一条更新语句更新数据库(更新外键)* 由于我们配置了客户到联系人的关系:客户可以对外键进行维护*/customer.getLinkMans().add(linkMan);customerDao.save(customer);linkManDao.save(linkMan);}@Test@Transactional // 配置事务@Rollback(false) // 不自动回滚public void testAdd2() {// 创建一个客户, 创建一个联系人Customer customer = new Customer();customer.setCustName("阿里");LinkMan linkMan = new LinkMan();linkMan.setLkmName("小桂");/*** 配置联系人到客户的关系(多对一)* 只发送了两条insert语句* 由于配置了联系人到客户的映射关系(多对一)*/linkMan.setCustomer(customer);customerDao.save(customer);linkManDao.save(linkMan);}/*** 会有一条多余的update语句* * 由于一的一方可以维护外键:会发送update语句* * 解决此问题:只需要在一的一方放弃维护权即可**/@Test@Transactional //配置事务@Rollback(false) //不自动回滚public void testAdd3() {//创建一个客户,创建一个联系人Customer customer = new Customer();customer.setCustName("百度");LinkMan linkMan = new LinkMan();linkMan.setLkmName("小阳");linkMan.setCustomer(customer);//由于配置了多的一方到一的一方的关联关系(当保存的时候,就已经对外键赋值)customer.getLinkMans().add(linkMan);//由于配置了一的一方到多的一方的关联关系(发送一条update语句)customerDao.save(customer);linkManDao.save(linkMan);}/*** 级联添加:保存一个客户的同时,保存客户的所有联系人* 需要在操作主体的实体类上,配置casacde属性*/@Test@Transactional //配置事务@Rollback(false) //不自动回滚public void testCascadeAdd() {Customer customer = new Customer();customer.setCustName("百度1");LinkMan linkMan = new LinkMan();linkMan.setLkmName("小李1");linkMan.setCustomer(customer);customer.getLinkMans().add(linkMan);customerDao.save(customer);}/*** 级联删除:* 删除1号客户的同时,删除1号客户的所有联系人* (测试的时候, 将配置文件中 create 改为update*/@Test@Transactional //配置事务@Rollback(false) //不自动回滚public void testCascadeRemove() {//1.查询1号客户Customer customer = customerDao.findOne(1L);//2.删除1号客户customerDao.delete(customer);}}
注意:
删除操作的说明如下:
删除从表数据:可以随时任意删除。
删除主表数据:
有从表数据
1、在默认情况下,它会把外键字段置为null,然后删除主表数据。如果在数据库的表 结构上,外键字段有非空约束,默认情况就会报错了。
2、如果配置了放弃维护关联关系的权利,则不能删除(与外键字段是否允许为null, 没有关系)因为在删除时,它根本不会去更新从表的外键字段了。
3、如果还想删除,使用级联删除引用
没有从表数据引用:随便删
在实际开发中,级联删除请慎用!(在一对多的情况下)
三、JPA中的多对多
跳转到目录
1、示例分析
我们采用的示例为用户和角色。用户:指的是咱们班的每一个同学。角色:指的是咱们班同学的身份信息。比如A同学,它是我的学生,其中有个身份就是学生,还是家里的孩子,那么他还有个身份是子女。同时B同学,它也具有学生和子女的身份。那么任何一个同学都可能具有多个身份。同时学生这个身份可以被多个同学所具有。所以我们说,用户和角色之间的关系是多对多。
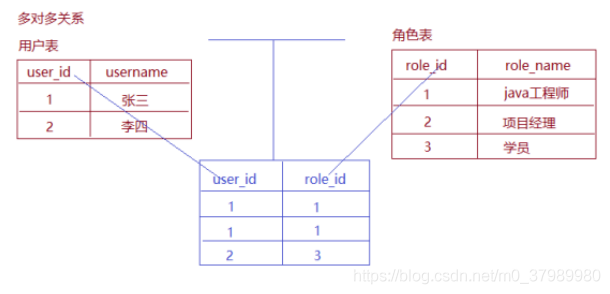
2、表关系建立
多对多的表关系建立靠的是中间表,其中用户表和中间表的关系是一对多,角色表和中间表的关系也是一对多,如下图所示:
3、实体类关系建立以及映射配置
一个用户可以具有多个角色,所以在用户实体类中应该包含多个角色的信息,代码如下:
UserDao
public interface UserDao extends JpaRepository<User, Long>, JpaSpecificationExecutor<User> {
}
RoleDao
public interface RoleDao extends JpaRepository<Role, Long>, JpaSpecificationExecutor<Role> {
}
User
@Entity
@Table(name = "sys_user")
public class User {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name="user_id")private Long userId;@Column(name="user_name")private String userName;@Column(name="age")private Integer age;/*** 配置用户到角色的多对多关系* 配置多对多的映射关系* 1.声明表关系的配置* @ManyToMany(targetEntity = Role.class) //多对多* targetEntity:代表对方的实体类字节码* 2.配置中间表(包含两个外键)* @JoinTable* name : 中间表的名称* joinColumns:配置当前对象在中间表的外键* @JoinColumn的数组* name:外键名* referencedColumnName:参照的主表的主键名* inverseJoinColumns:配置对方对象在中间表的外键*/@ManyToMany(targetEntity = Role.class, cascade = CascadeType.ALL)@JoinTable(name = "sys_user_role",joinColumns = {@JoinColumn(name = "sys_user_id", referencedColumnName = "user_id")},inverseJoinColumns = {@JoinColumn(name = "sys_role_id", referencedColumnName = "role_id")})private Set<Role> roles = new HashSet<Role>();
}
Role
@Entity
@Table(name = "sys_role")
public class Role {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "role_id")private Long roleId;@Column(name = "role_name")private String roleName;//配置多对多
// @ManyToMany(targetEntity = User.class)
// @JoinTable(name = "sys_user_role",
// joinColumns = {@JoinColumn(name = "sys_role_id", referencedColumnName = "role_id")},
// inverseJoinColumns = {@JoinColumn(name = "sys_user_id", referencedColumnName = "user_id")}
// )@ManyToMany(mappedBy = "roles") //配置多表关系private Set<User> users = new HashSet<User>();
}
4、多对多映射的注解说明
跳转到目录
@ManyToMany作用:用于映射多对多关系属性:cascade:配置级联操作。fetch:配置是否采用延迟加载。targetEntity:配置目标的实体类。映射多对多的时候不用写。@JoinTable作用:针对中间表的配置属性:nam:配置中间表的名称joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段 inverseJoinColumn:中间表的外键字段关联对方表的主键字段@JoinColumn作用:用于定义主键字段和外键字段的对应关系。属性:name:指定外键字段的名称referencedColumnName:指定引用主表的主键字段名称unique:是否唯一。默认值不唯一nullable:是否允许为空。默认值允许。insertable:是否允许插入。默认值允许。updatable:是否允许更新。默认值允许。columnDefinition:列的定义信息。
5、多对多的操作(增加、删除、级联)
跳转到目录
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class ManyToManyTest {@Autowiredprivate RoleDao roleDao;@Autowiredprivate UserDao userDao;/*** 保存一个用户,保存一个角色** 多对多放弃维护权:被动的一方放弃(用户可以选择角色,所以角色是被动的)*/@Test@Transactional@Rollback(false)public void testAdd() {User user = new User();user.setUserName("阳仔");Role role = new Role();role.setRoleName("Java程序员");// 配置用户到角色关系, 可以对中间表的数据进行维护 1-1user.getRoles().add(role);// 配置用户到角色关系, 可以对中间表的数据进行维护 1-1role.getUsers().add(user);userDao.save(user);roleDao.save(role);}//测试级联添加(保存一个用户的同时保存用户的关联角色)@Test@Transactional@Rollback(false)public void testCasCadeAdd() {User user = new User();user.setUserName("小李");Role role = new Role();role.setRoleName("java程序员");//配置用户到角色关系,可以对中间表中的数据进行维护 1-1user.getRoles().add(role);//配置角色到用户的关系,可以对中间表的数据进行维护 1-1role.getUsers().add(user);userDao.save(user);}/*** 案例:删除id为1的用户,同时删除他的关联对象* (需要将配置文件中修改为: update )*/@Test@Transactional@Rollback(false)public void testCasCadeRemove() {//查询1号用户User user = userDao.findOne(1L);//删除1号用户userDao.delete(user);}}
四、Spring Data JPA中的多表查询
跳转到目录
对象导航查询:
对象图导航检索方式是根据已经加载的对象,导航到他的关联对象。它利用类与类之间的关系来检索对象。
例如:我们通过ID查询方式查出一个客户,可以调用Customer类中的getLinkMans()方法来获取该客户的所有联系人。对象导航查询的使用要求是:两个对象之间必须存在关联关系。
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class ObjectQueryTest {@Autowiredprivate CustomerDao customerDao;@Autowiredprivate LinkManDao linkManDao;//could not initialize proxy - no Session//测试对象导航查询(查询一个对象的时候,通过此对象查询所有的关联对象)@Test@Transactional // 解决在java代码中的no session问题public void testQuery1() {//查询id为1的客户Customer customer = customerDao.getOne(1L);//对象导航查询,此客户下的所有联系人Set<LinkMan> linkMans = customer.getLinkMans();for (LinkMan linkMan : linkMans) {System.out.println(linkMan);}}/*** 对象导航查询:* 默认使用的是延迟加载的形式查询的* 调用get方法并不会立即发送查询,而是在使用关联对象的时候才会差和讯* 延迟加载!* 修改配置,将延迟加载改为立即加载* fetch,需要配置到多表映射关系的注解上*/@Test@Transactional // 解决在java代码中的no session问题public void testQuery2() {//查询id为1的客户Customer customer = customerDao.findOne(1l);//对象导航查询,此客户下的所有联系人Set<LinkMan> linkMans = customer.getLinkMans();System.out.println(linkMans.size());}/*** 从联系人对象导航查询他的所属客户* * 默认 : 立即加载* 延迟加载*/@Test@Transactional // 解决在java代码中的no session问题public void testQuery3() {LinkMan linkMan = linkManDao.findOne(2L);//对象导航查询所属的客户Customer customer = linkMan.getCustomer();System.out.println(customer);}}
对象导航查询的问题分析
问题1:我们查询客户时,要不要把联系人查询出来?
分析:如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。如果我们查出来的,不使用时又会白白的浪费了服务器内存。
解决:采用延迟加载的思想。通过配置的方式来设定当我们在需要使用时,发起真正的查询。
/*** 在客户对象的@OneToMany注解中添加fetch属性* FetchType.EAGER :立即加载* FetchType.LAZY :延迟加载*/
@OneToMany(mappedBy="customer",fetch=FetchType.EAGER)
private Set<LinkMan> linkMans = new HashSet<>(0);
问题2:我们查询联系人时,要不要把客户查询出来?
分析:例如:查询联系人详情时,肯定会看看该联系人的所属客户。如果我们不查的话,在用的时候还要自己写代码,调用方法去查询。如果我们查出来的话,一个对象不会消耗太多的内存。而且多数情况下我们都是要使用的。
解决: 采用立即加载的思想。通过配置的方式来设定,只要查询从表实体,就把主表实体对象同时查出来
/*** 在联系人对象的@ManyToOne注解中添加fetch属性* FetchType.EAGER :立即加载* FetchType.LAZY :延迟加载*/
@ManyToOne(targetEntity=Customer.class,fetch=FetchType.EAGER)
@JoinColumn(name="cst_lkm_id",referencedColumnName="cust_id")
private Customer customer;
五、总结
跳转到目录
回顾i.springDatajpa,jpa规范,hibernate三者之间的关系code -- > springDatajpa --> jpa规范的API --> hibernateii.符合springDataJpa规范的dao层接口的编写规则1.需要实现两个接口(JpaRepository,JapSpecificationExecutor)2.提供响应的泛型iii.运行过程* 动态代理的方式:动态代理对象iiii.查询第一 Specifications动态查询JpaSpecificationExecutor 方法列表T findOne(Specification<T> spec); //查询单个对象List<T> findAll(Specification<T> spec); //查询列表//查询全部,分页//pageable:分页参数//返回值:分页pageBean(page:是springdatajpa提供的)Page<T> findAll(Specification<T> spec, Pageable pageable);//查询列表//Sort:排序参数List<T> findAll(Specification<T> spec, Sort sort);long count(Specification<T> spec);//统计查询* Specification :查询条件自定义我们自己的Specification实现类实现//root:查询的根对象(查询的任何属性都可以从根对象中获取)//CriteriaQuery:顶层查询对象,自定义查询方式(了解:一般不用)//CriteriaBuilder:查询的构造器,封装了很多的查询条件Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb); //封装查询条件第二 多表之间的关系和操作多表的操作步骤表关系一对一一对多:一的一方:主表多的一方:从表外键:需要再从表上新建一列作为外键,他的取值来源于主表的主键多对多:中间表:中间表中最少应该由两个字段组成,这两个字段做为外键指向两张表的主键,又组成了联合主键讲师对学员:一对多关系实体类中的关系包含关系:可以通过实体类中的包含关系描述表关系继承关系分析步骤1.明确表关系2.确定表关系(描述 外键|中间表)3.编写实体类,再实体类中描述表关系(包含关系)4.配置映射关系第三 完成多表操作i.一对多操作案例:客户和联系人的案例(一对多关系)客户:一家公司联系人:这家公司的员工一个客户可以具有多个联系人一个联系人从属于一家公司分析步骤1.明确表关系一对多关系2.确定表关系(描述 外键|中间表)主表:客户表从表:联系人表* 再从表上添加外键3.编写实体类,再实体类中描述表关系(包含关系)客户:再客户的实体类中包含一个联系人的集合联系人:在联系人的实体类中包含一个客户的对象4.配置映射关系* 使用jpa注解配置一对多映射关系级联:操作一个对象的同时操作他的关联对象级联操作:1.需要区分操作主体2.需要在操作主体的实体类上,添加级联属性(需要添加到多表映射关系的注解上)3.cascade(配置级联)级联添加,案例:当我保存一个客户的同时保存联系人级联删除案例:当我删除一个客户的同时删除此客户的所有联系人ii.多对多操作案例:用户和角色(多对多关系)用户:角色:分析步骤1.明确表关系多对多关系2.确定表关系(描述 外键|中间表)中间间表3.编写实体类,再实体类中描述表关系(包含关系)用户:包含角色的集合角色:包含用户的集合4.配置映射关系iii.多表的查询1.对象导航查询查询一个对象的同时,通过此对象查询他的关联对象案例:客户和联系人从一方查询多方* 默认:使用延迟加载(****)从多方查询一方* 默认:使用立即加载本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!