2020数字中国创新大赛—算法赛开源方案复盘笔记
DCIC 2020:智慧海洋建设 开源方案复盘笔记
一、赛题介绍
1.1 赛题背景
本赛题基于位置数据对海上目标进行智能识别和作业行为分析,要求选手通过分析渔船北斗设备位置数据,得出该船的生产作业行为,具体判断出是拖网作业、围网作业还是流刺网作业。初赛将提供11000条(其中7000条训练数据、2000条testA、2000条testB)渔船轨迹北斗数据。
1.2 赛题数据
初赛提供11000条渔船北斗数据,数据包含脱敏后的渔船ID、经纬度坐标、上报时间、速度、航向信息,由于真实场景下海上环境复杂,经常出现信号丢失,设备故障等原因导致的上报坐标错误、上报数据丢失、甚至有些设备疯狂上报等。
数据示例:

- 渔船ID:渔船的唯一识别,结果文件以此ID为标示
- x: 渔船在平面坐标系的x轴坐标
- y: 渔船在平面坐标系的y轴坐标
- 速度:渔船当前时刻航速,单位节
- 方向:渔船当前时刻航首向,单位度
- time:数据上报时刻,单位月日 时:分
- type:渔船label,作业类型
原始数据经过脱敏处理,渔船信息被隐去,坐标等信息精度和位置被转换偏移。 选手可通过学习围网、刺网、拖网等专业知识辅助大赛数据处理。
1.3 评估指标
提交结果与实际渔船作业类型结果进行对比,以3种类别的各自F1值取平均做为评价指标,结果越大越好,具体计算公式如下:
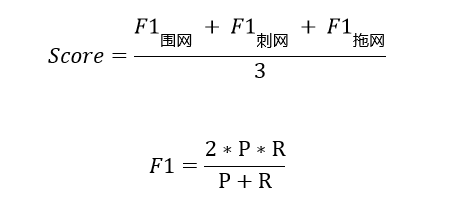
其中P为某类别的准确率,R为某类别的召回率,评测程序f1函数为sklearn.metrics.f1_score,average='macro'。
二、Baseline 1
2.1 Baseline 概况
Baseline Auhtor : 阿水
Baseline Address : Baseline
Baseline Star : 38
Baseline Score : 0.62
这个Baseline是本赛题比较有代表性的方案,代码风格简介,对于初学者比较友好。同时 数据->特征->算法 的框架方便特征工程的快速迭代。
2.2 代码结构
2.2.1 Import U need
import os, sys, glob
import numpy as np
import pandas as pdimport time
import datetimefrom joblib import Parallel, delayed
from sklearn.metrics import f1_score, log_loss, classification_report
from sklearn.model_selection import StratifiedKFoldimport lightgbm as lgb%pylab inline2.2.2 特征工程
def read_feat(path, test_mode=False):df = pd.read_csv(path)df = df.iloc[::-1]if test_mode:df_feat = [df['渔船ID'].iloc[0], df['type'].iloc[0]]df = df.drop(['type'], axis=1)else:df_feat = [df['渔船ID'].iloc[0]]df['time'] = df['time'].apply(lambda x: datetime.datetime.strptime(x, "%m%d %H:%M:%S"))df_diff = df.diff(1).iloc[1:]df_diff['time_seconds'] = df_diff['time'].dt.total_seconds()df_diff['dis'] = np.sqrt(df_diff['x']**2 + df_diff['y']**2)df_feat.append(df['time'].dt.day.nunique())df_feat.append(df['time'].dt.hour.min())df_feat.append(df['time'].dt.hour.max())df_feat.append(df['time'].dt.hour.value_counts().index[0])# 此处省略 N 段代码return df_feat由于本赛题每个ID都独立成一个csv文件,可以看到阿水把利用文件名传参的方式对每个ID进行独立的特征处理。
2.2.3 并行化特征获取
train_feat = Parallel(n_jobs=10)(delayed(read_feat)(path, True) for path in glob.glob('../input/hy_round1_train_20200102/*')[:])
train_feat = pd.DataFrame(train_feat)test_feat = Parallel(n_jobs=10)(delayed(read_feat)(path, False) for path in glob.glob('../input/hy_round1_testA_20200102/*')[:])
test_feat = pd.DataFrame(test_feat)
test_feat = test_feat.sort_values(by=0)train_feat[1] = train_feat[1].map({'围网':0,'刺网':1,'拖网':2})这里利用Parallel进行了并行化处理,提升了计算效率。
2.2.4 LightGBM 10折
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import f1_scoren_fold = 10
skf = StratifiedKFold(n_splits = n_fold, shuffle = True)
eval_fun = f1_scoredef run_oof(clf, X_train, y_train, X_test, kf):# 此处省略N行return preds_train, preds_testparams = {# 此处省略N行}train_pred, test_pred = run_oof(lgb.LGBMClassifier(**params), train_feat.iloc[:, 2:].values, train_feat.iloc[:, 1].values, test_feat.iloc[:, 1:].values, skf)小结
笔者在此开源的基础上,只修改了部分特征工程,线上可以有 0.8913 的分数,同时并行化也使得线下迭代验证效率得到了保障。
三、Baseline 2
3.1 Baseline 概况
Baseline Auhtor : 蔡君洋jioooo~
Baseline Address :Baseline
Baseline Star :18
Baseline Score :0.8729
相对于Baseline 1,该Baseline的亮点在于做了一些EDA工作,对于理解题目很有帮助。
3.2 数据探查
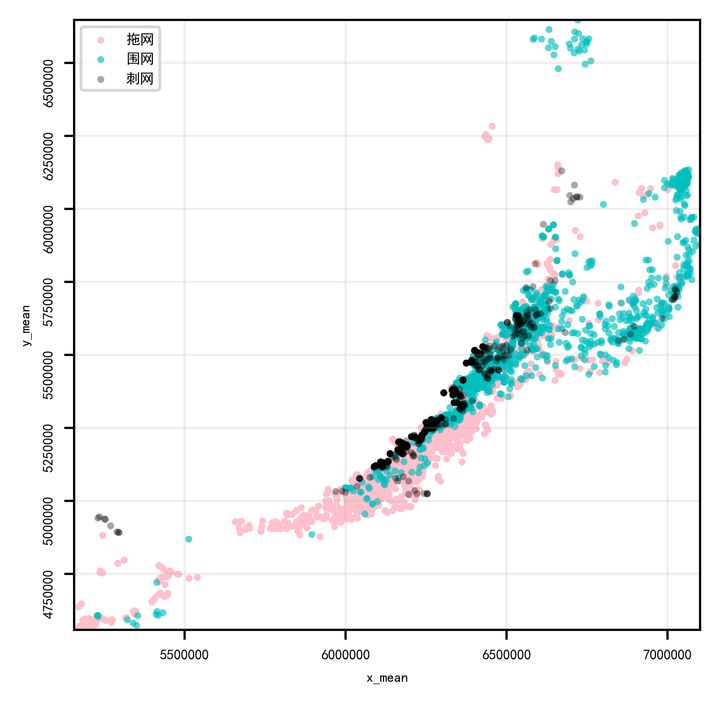
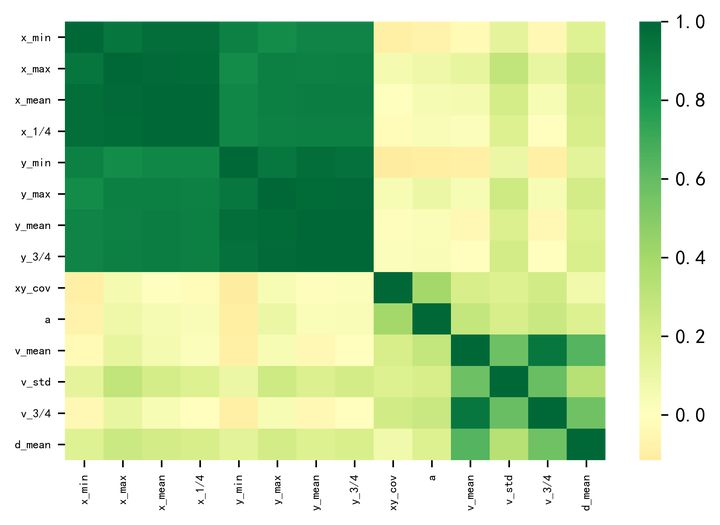
- 对不同标签的的(x,y)位置可视化我们可以发现,这基本就是沿海的轮廓。 - 同时,不同标签在坐标上的区分度还是较为明显的。
3.3 多模型对比
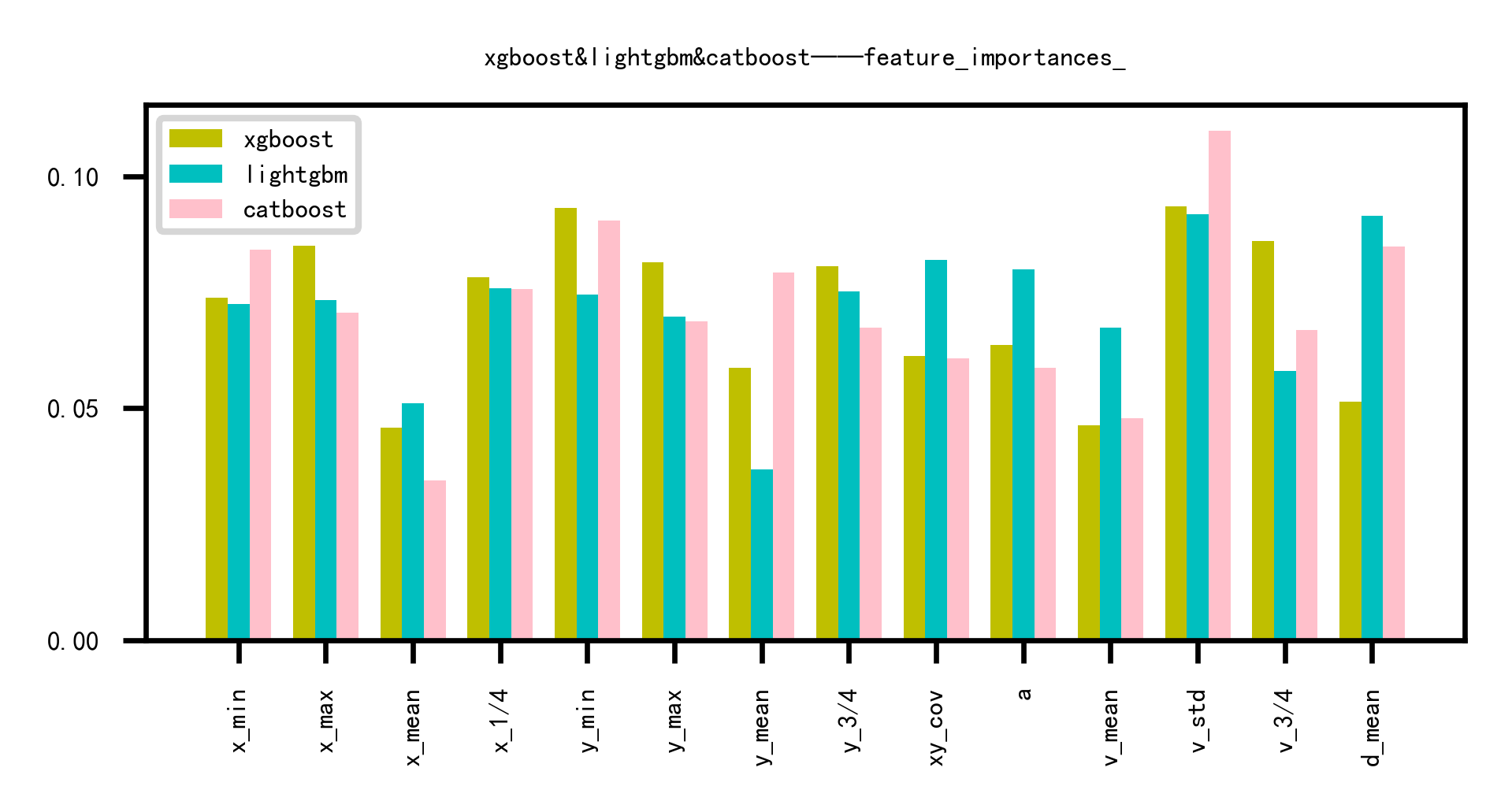
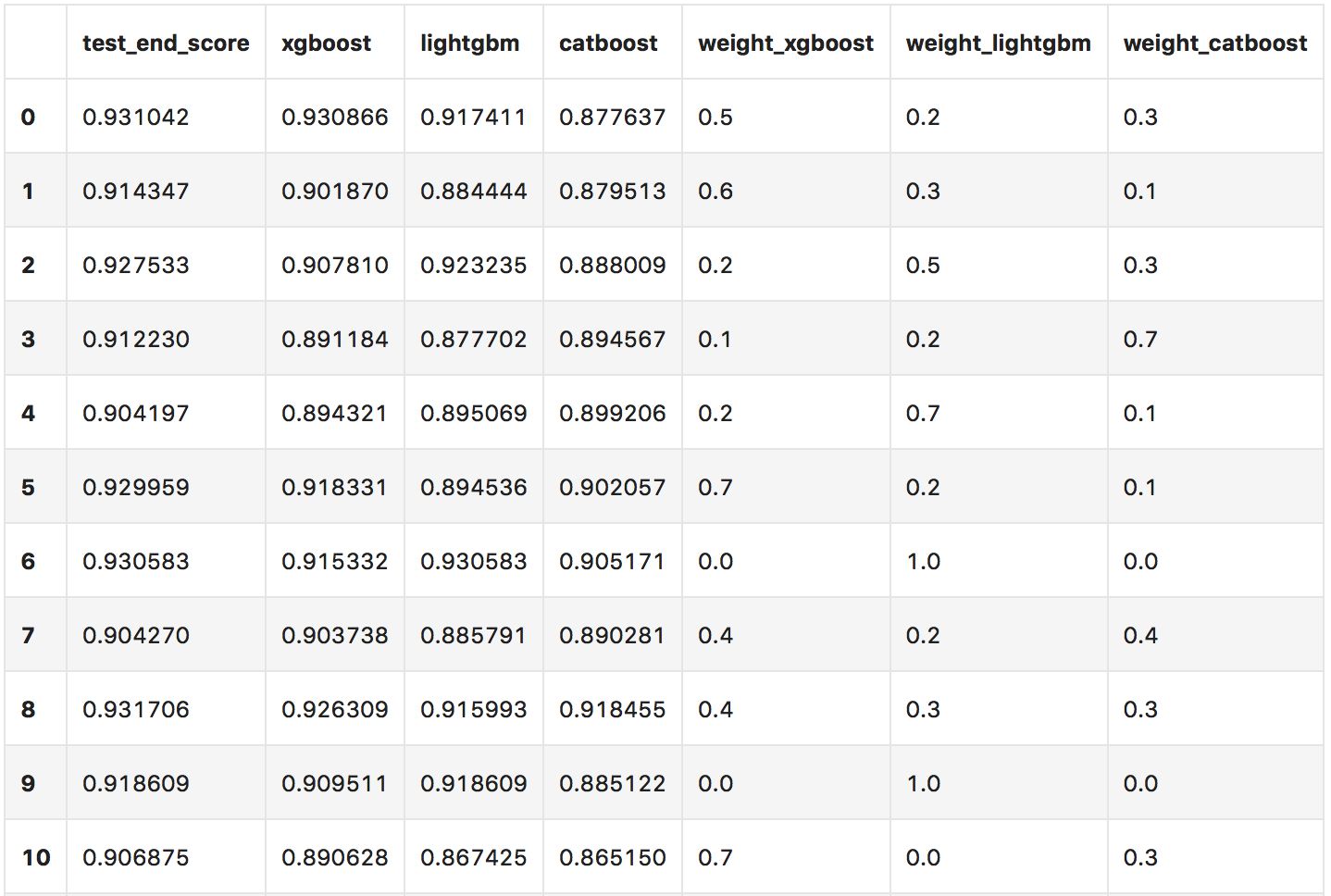
该Baseline对Xgboost,LightGBM,CatBoost模型做了融合,同时做了加权融合。
四、Baseline 3
4.1 Baseline 概况
Baseline Auhtor : wbbhcb
Baseline Address :Baseline
Baseline Star : 21
Baseline Score : 0.5
相对于Baseline 1和2,该Baseline的亮点在于提供了一个NN版的思路,虽然该思路的做法,用图片的形式进行分类,损失了很多特征信息,但是依旧不妨碍作为一个Baseline思路的存在。
3.2 部分代码概况
def train_epoch(model, optimizer, criterion, train_dataloader, epoch, lr, best_f1, batch_size):model.train()f1_meter, loss_meter, it_count = 0, 0, 0tq = tqdm.tqdm(total=len(train_dataloader)*batch_size)tq.set_description('folds: %d, epoch %d, lr %.4f, best_f:%.4f' % (fold_+1, epoch, lr, best_f1))for i, (inputs, target) in enumerate(train_dataloader):inputs = inputs.to(device)target = target.to(device)# zero the parameter gradientsoptimizer.zero_grad()# forwardoutput = model(inputs)output = F.softmax(output, dim=1)loss = criterion(output, target)loss.backward()optimizer.step()loss_meter += loss.item()it_count += 1f1 = calc_f1(target, output)f1_meter += f1tq.update(batch_size)tq.set_postfix(loss="%.4f f1:%.3f" % (loss.item(), f1))tq.close()return loss_meter / it_count, f1_meter / it_count本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!