推荐算法炼丹笔记:如何让你的推荐系统具有可解释性?
作者:一元, 公众号:炼丹笔记
可解释性和有效性是构建推荐系统的两大关键成份,之前的工作主要关注通过引入辅助信息来获得更好的推荐效果。但这些方法会存在下面的两个问题:
- 基于神经网络的embedding方法很难解释和debug;
- 基于图的方法需要人工以及领域知识来定义模式和规则,并且会忽略商品的相关类型;(可替代并且互补)
本文提出了一种新的联合学习框架,我们将知识图中可解释规则的归纳与规则引导的神经推荐模型的构建相结合;该框架鼓励两个模块可以互相补并生成有效的可解释的推荐。
- 归纳规则:从商品为中心的知识图谱中挖掘, 总结出用于推断不同商品关联的常见多跳关系模式,并为模型预测提供人类可理解的解释;
- 通过引入规则对推荐模块进行扩充,使其在处理冷启动问题时具有更好的泛化能力;
所以本文是希望通过联合训练推荐和知识图谱来给出既准确又可解释的推荐。
背景知识
问题定义
1. 商品推荐(Item Recommendation)
给定用户U和商品I, 商品的推荐任务就是基于用户和商品的历史交互找出最适合每个用户的商品;用户会通过购买或者对某个商品打分的形式表述他的喜好, 这些交互可以通过矩阵进行表示,最具代表的方法就是:将用户和商品embed到低维度的潜在空间中,然后使用用户-商品交互的结果来进行推荐。
2. 知识图谱(Knowledge graph)
知识图谱是由实体(节点)和关系(边)构成的多关系图,我们可以使用多个三元组(头部实体E1, 关系类型r1, 尾部实体E2)来表示知识图谱的事实。
3. 知识图的归纳规则
知识图谱中两个实体之间可能有许多路径,一条路径由关系类型构成(例如P(k)=E1r1E2r2E3就是两个实体E1和的E2路径);规则由两个实体的关系序列定义,例如,路径和规则的区别在于规则更多关注关系类型而不是实体。
4. 问题定义
给定用户U,商品I,用户和商品的交互,商品关联以及知识图谱,我们的联合训练框架目的在于:
- 基于商品的关系学习商品之间的规则;
- 学习推荐系统推荐对每个用户基于规则R以及他的交互历史Iu推荐商品;
该框架输出一套规则R 以及推荐商品的列表I'.
推荐基础模型
此处介绍两种基础的模型。
1. BPRMF:贝叶斯个性化排序矩阵分解

2. NCF(Neural Collaborative Filtering):神经网络协同过滤

RULEREC框架
带有rule learning的推荐主要由下面两个子任务组成:(1). 基于商品的关系从知识图谱中进行规则学习; (2). 对每个用户基于他的购买历史和得到的规则推荐商品;我们将其建模为多任务学习,于是我们有:

异构图构建
我们构建异对于推荐和知识图谱的商品的异构图,具体如下:
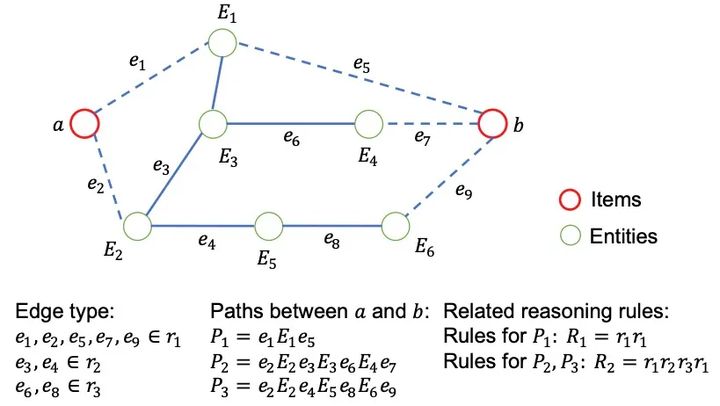
规则学习模块
规则学习模块的目的是在异构图中找到与给定项目关联A相关联的可靠规则集。
1. 规则学习


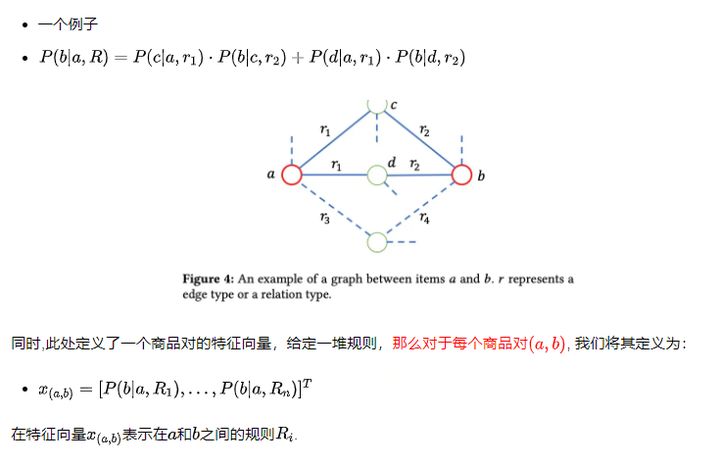
2. 规则选择
- Hard selection method:硬选择方法通过设置一个超参数来决定我们首先要选择多少条规则。
- Soft selection method:利用基于学习的目标函数的方法是将每个规则的权重作为对推荐模块中规则权重的约束。这样就不会从规则集中删除任何规则,也不会引入额外的超参数。
Item推荐模块

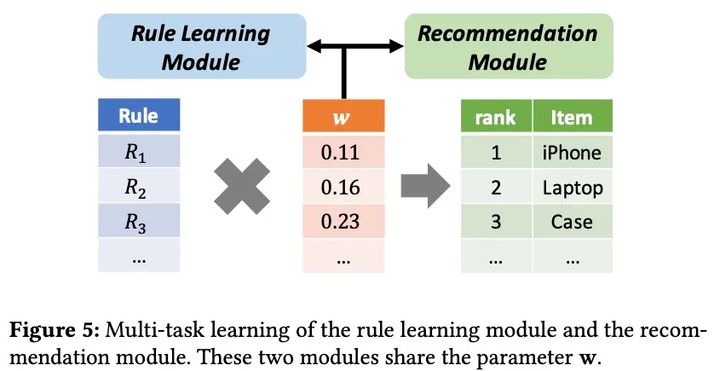
多任务学习
此处我们采用多任务目标函数进行优化:

模型效果
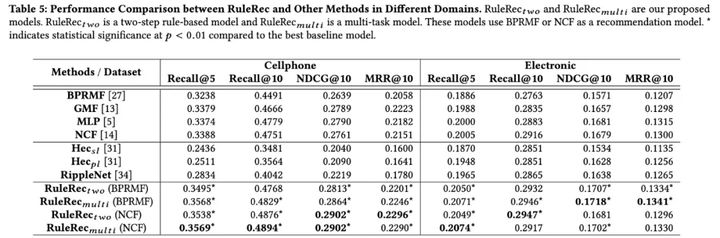
- 在加权的训练中结合推荐损失和规则选择损失可以提高推荐效果;
- 从知识图谱中抽取得到的规则对于商品对的特征向量学习是非常有价值的,学习得到的向量可以加强多个基本的推荐模型;
- 多任务学习的方式对于推荐和规则选择比规则加权学习贡献更多;因为提出框架的灵活性,提出的规则能够和其它推荐算法结合进一步提升模型的效果.
案例研究&效果比较
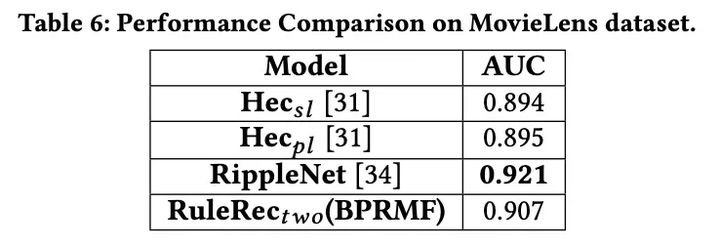
- 提出的模型比HERec好,但比RippleNet差。
有两个原因:1)关系类型在这个数据集中非常有限(只有7个),因此RuleRec中推荐规则选择的能力在这种情况下是有限的。2) MovieLens-1M不同于的真实知识图数据集(它是通过将项目链接到Freebase来构建的),它的连接覆盖非常完美,RippleNet从中受益匪浅。结果表明,所提出的算法能够在紧凑异构图中取得显著的性能;
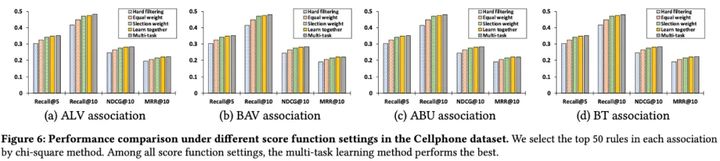
- 多任务学习方法在所有指标上都取得了最好的性能,并且改进效果显著,这表明多任务学习在规则权重学习中非常有助于获得更好的推荐结果。
- 由于硬过滤方法可能同时忽略负项目和正项目(从表3中,我们可以看到,有时正项目和项目采购历史之间没有规则)。
- 虽然选择权重有助于推荐(更好同样的重量),它仍然比一起学习模式更糟糕。
- 对于由四个关联中的任何一个导出的规则,使用BPRMF的RuleRec_{multi}明显优于BPRMF算法。
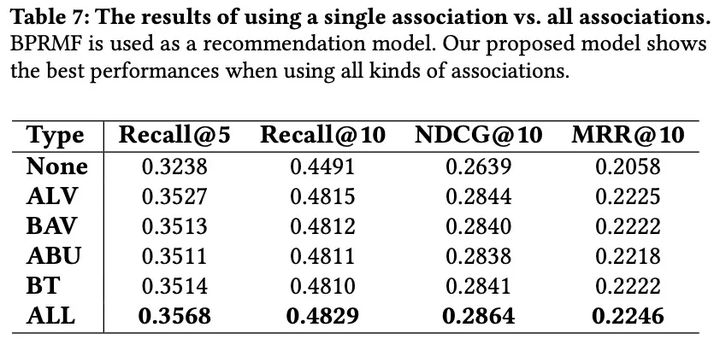
- 使用不同的关联可以得到相似的结果,但它们对于挖掘项目关系以提高推荐结果都是有价值的。
- 在推荐中当我们使用更多规则的时候,整体效果没有变得更好;(可能随着规则的个数增加,很多不好的规则也被带入到模型中);
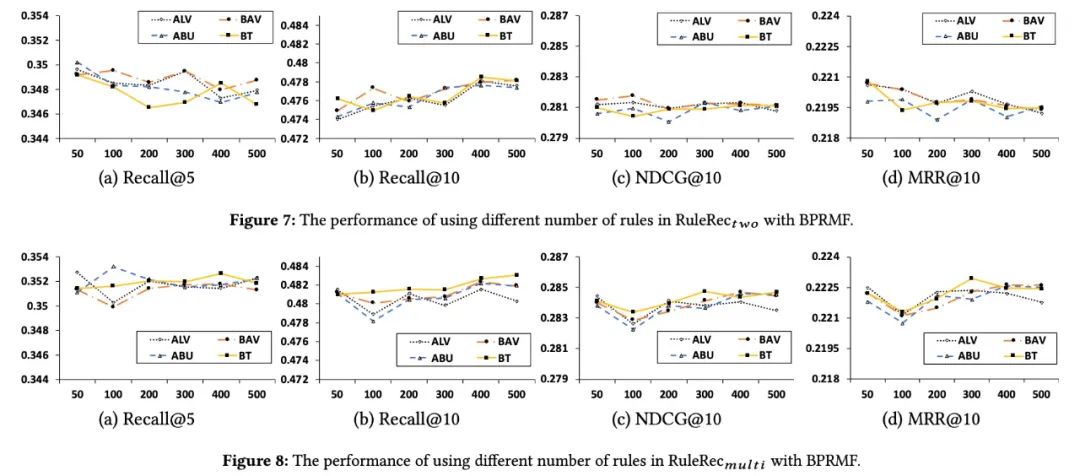
- 由于在多任务学习算法中考虑了规则的选择,我们发现规则集的性能与随着规则数的增加,BPRMF算法表现出更好的性能;
- 使用BPRMF的的性能明显优于和BPRMF(对不同规则计数的实验结果进行配对双样本t检验)的性能。p<0.01)。结果表明,基于多任务学习的算法能够处理大量的规则,即使存在一些无用的规则;
小结
本文提出了一种新的、有效的联合优化框架,用于从包含商品的知识图中归纳出规则,并基于归纳出的规则进行推荐。该框架由两个模块组成:规则学习模块和推荐模块。规则学习模块能够在具有不同类型商品关联的知识图中导出有用的规则,推荐模块将这些规则引入到推荐模型中以获得更好的性能。此外,有两种方法来实现这个框架:两步学习和联合学习。
本文研究使用大型知识图Freebase进行规则学习。该框架能够灵活地支持不同的推荐算法。我们修改了两种推荐算法,一种是经典的矩阵分解算法(BPRMF)和一种基于神经网络的推荐算法(NCF)。所提出的四种规则增强推荐算法在多个领域都取得了显著的效果,并优于所有的基线模型,表明了本文框架的有效性。此外,推导出的规则还能够解释我们为什么要向用户推荐这个项目,同时也提高了推荐模型的可解释性。进一步的分析表明,我们基于多任务学习的组合方法(带有BPRMF的和NCF的$RuleRec_{two})在不同规则数下的性能优于两步法。不同关联规则的组合有助于获得更好的推荐结果。
参考文献
- Jointly Learning Explainable Rules for Recommendation with Knowledge Graph:https://arxiv.org/pdf/1903.03714.pdf
- https://blog.csdn.net/qq_41621342/article/details/104188843
后续我们会筛选出在我们实践中带来提升或者启发的工作进行细致的解读与探讨,欢迎关注我们的公众号,也欢迎多交流,我是三品炼丹师: 一元。

炼丹笔记
推荐算法炼丹笔记:序列化推荐系统
推荐算法炼丹笔记:电商搜索推荐业务词汇表
推荐算法炼丹笔记:推荐系统采样评估指标及线上线下一致性问题
推荐算法炼丹笔记:CTR点击率预估系列入门手册
推荐算法炼丹笔记:科学调参在模型优化中的意义
推荐算法炼丹笔记:如何让你的推荐系统具有可解释性?
2020年推荐系统工程师炼丹手册
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!