推荐系统炼丹笔记:RecSys2020-SSE-PT解锁序列数据挖掘新姿势
作 者:一元
公众号:炼丹笔记背景
现在诸多的推荐算法在处理时间信息上, 除了在自然语言常用的RNN,CNN等模型, 就是基于Transformer的模型,但是和SASRec类似, 效果不错,但是缺少个性化,而且没有加入基于个性化的用户embedding。为了克服这种问题,本文提出来一种个性化的Transformer(SSE-PT),该方法相较于之前的方案提升了5%。
方案
模型框架
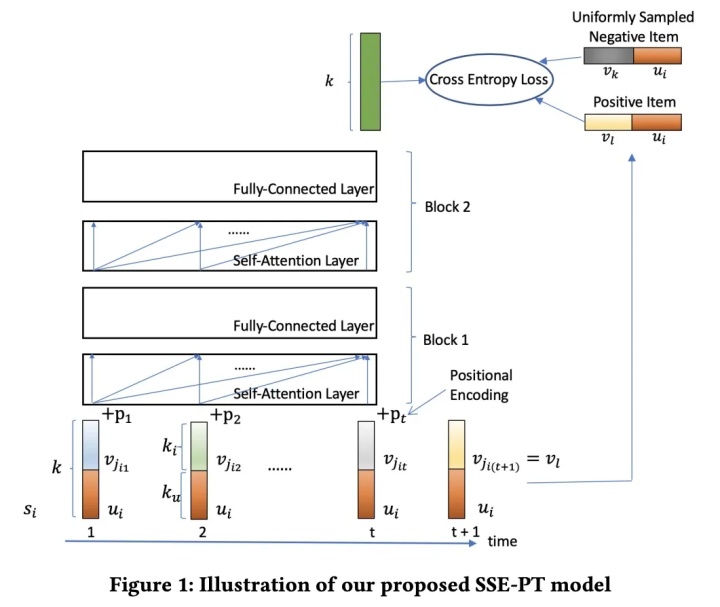
序列化推荐

个性化Transformer架构
SSE-PT使用随机共享embedding技术,
1. Embedding 层

2. Transformer的Encoder
这一块和之前的许多Transformer Encoder是类似的,所以此处我们跳过。
3. 预测层

4. 随机共享Embedding
对于提出的SSE-PT算法最为重要的正则技术是SSE(Stochastic Shared Embedding), SSE的主要思想是在SGD过程中随机地用另一个具有一定概率的Embedding来代替现在的Embedding,从而达到正则化嵌入层的效果。在没有SSE的情况下,现有的所有正则化技术,如层规范化、丢失和权重衰减等都会失效,不能很好地防止模型在引入用户嵌入后的过拟合问题。
- SSE_PE: 以概率p均匀地使用另外一个embedding替代当前的embedding;
在本文中,有三处不同的地方可以使用SSE-SE, 我们对输入/输出的用户embedding, 输入的商品embedding以及输出的商品embedding分别以概率pu,pi,以及py进行替换。
我们注意到输入用户embedding和输出用户embedding同时被SSE概率代替。经验上,我们发现SSE-SE在用户的embedding和输出项的embedding总是有帮助的,但是SSE-SE到输入项的embedding只有在平均序列长度较大时才有用,例如Movielens1M和Movielens10M都超过100。
处理长序列的SSE-PT++

实验
1. 效果比较
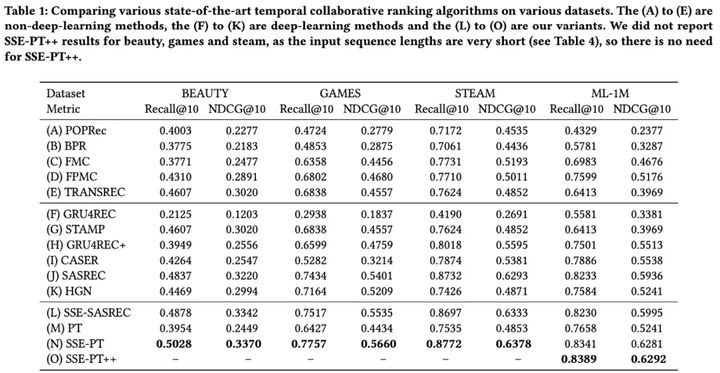
- SSE-PT算法在所有的4个数据集上的效果都好于其它的算法;
2. 正则化方案的比较

- SSE-SE+dropout+weight decay是正则化里面最好的。
3. 模型训练速度
- SSE-PT和SSE-PT++模型的训练速度与SASRec相当,其中SSE-PT++是速度最快、性能最好的模型。很明显,使用相同的训练时间,我们的SSE-PT和SSE-PT++比我们的基准SASRec取得了更好的排名性能.
4. 解耦研究
4.1 SSE概率
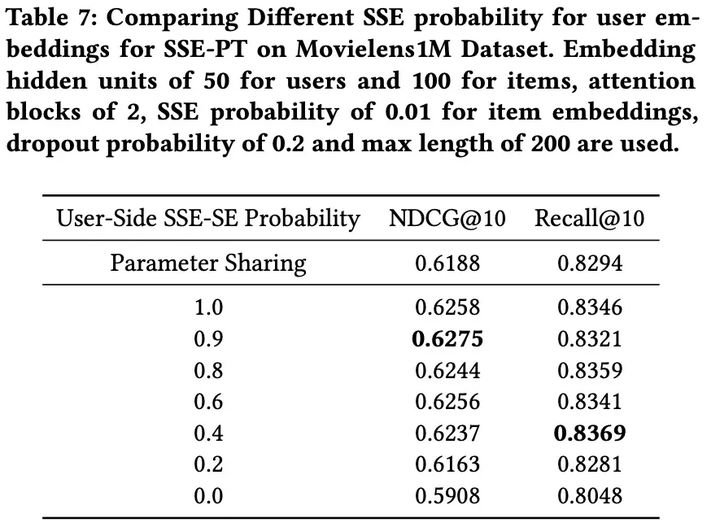
鉴于SSE正则化对于我们的SSE-PT模型的重要性,我们仔细检查了输入用户嵌入的SSE概率。我们发现适当的超参数SSE概率不是很敏感:在0.4到1.0之间的任何地方都能得到很好的结果,比参数共享和不使用SSE-SE要好。
4.2 采样概率
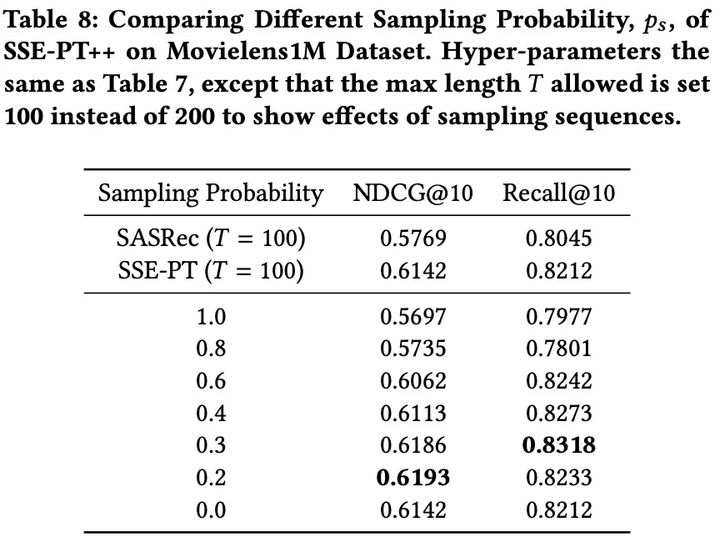
- 当最大长度相同时,使用适当的抽样概率(如0.2→0.3)将使其优于SSE-PT。
4.3 Attention Block的个数
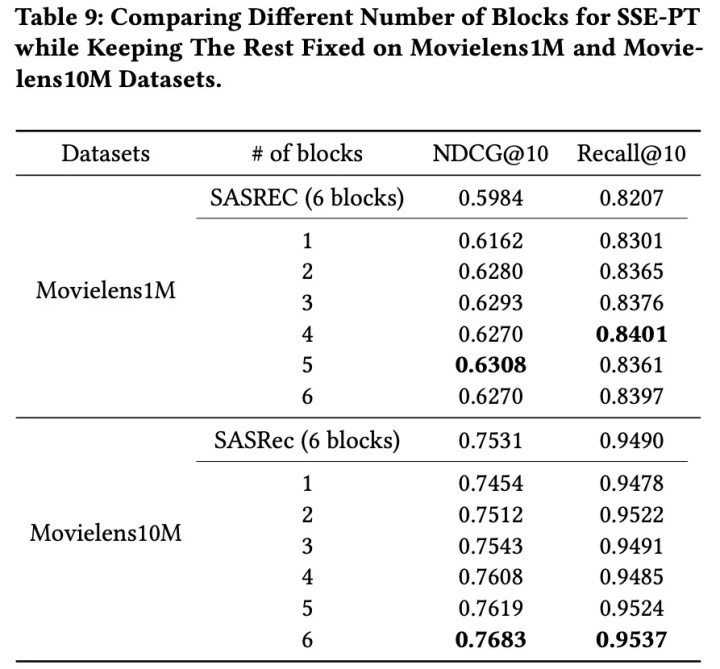
- 对于Movielens1M数据集,在B=4或5时达到最佳排序性能,对于Movielens10M数据集,在B=6时达到最佳排序性能
4.4 个性化以及负样本的采样个数
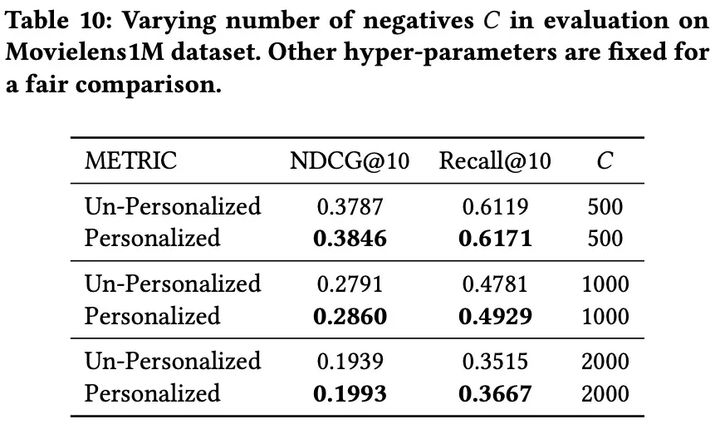
- 当我们使用相同的正则化技术时,个性化模型总是优于非个性化模型。不管在评估过程中采样了多少个负数或者使用了什么排名标准,这都是正确的。
小结
在这篇论文中,作者提出了一个新的神经网路架构-Personal Transformer来解决时间协同排序问题。它拥有个性化模型的好处,比目前最好的个人用户获得更好的排名结果。通过研究推理过程中的注意机制,该模型比非个性化的深度学习模型更具解释性,并且更倾向于关注长序列中的最近项目。
参考文献
- SSE-PT: Sequential Recommendation Via Personalized Transformer:https://dl.acm.org/doi/pdf/10.1145/3383313.3412258
- https://github.com/SSE-PT/SSE-PT


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!