推荐算法炼丹笔记:非采样的负样本


最近推荐相关的研究主要集中在探索神经网络的结构等,然后采用负采样对模型进行高效的学习。然而,这么做会导致有两方面的问题没有被考虑仔细:
- 负采样会带来较大的波动;基于采样的方法很难获得最优的排序结果;
- 尽管heterogeneous的反馈在许多在线系统中被广泛使用,(例如view,click,purchase),大多数现有的方案只会使用用户的一种反馈,例如购买等;
本文提出了一个新的非采样的迁移学习解决方案,我们称其为 Efficient Heterogeneous Collaborative Filtering(EHCF)的Top-N推荐。它不仅可以对细粒度的用户项关系进行建模,而且能够以较低的时间复杂度从整个异构数据(包括所有未标记数据)中高效地学习模型参数。
在三个实际数据集上的大量实验表明,EHCF在传统(单一行为)和异构场景中都显著优于最先进的推荐方法。此外,EHCF在训练效率上有显著提高,使其更适用于实际的大型系统。
在之前的许多工作当中,有两个重要的问题还没有非充分考虑,
- 很多神经网络为了提升模型的训练效率,采用负采样,但是这么做会出现模型训练不稳定,对于采样的分布以及采样的比例较为敏感。
- 之前的工作缺乏用户行为之间的关系的深度探索,每个行为都会有自己对应的上下文以及非常强的迁移关系。
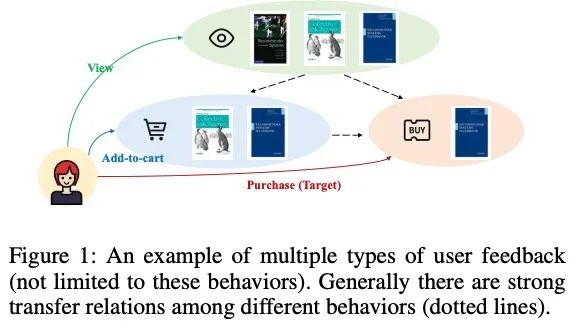

问题定义

模型一览
模型整体框架如下:
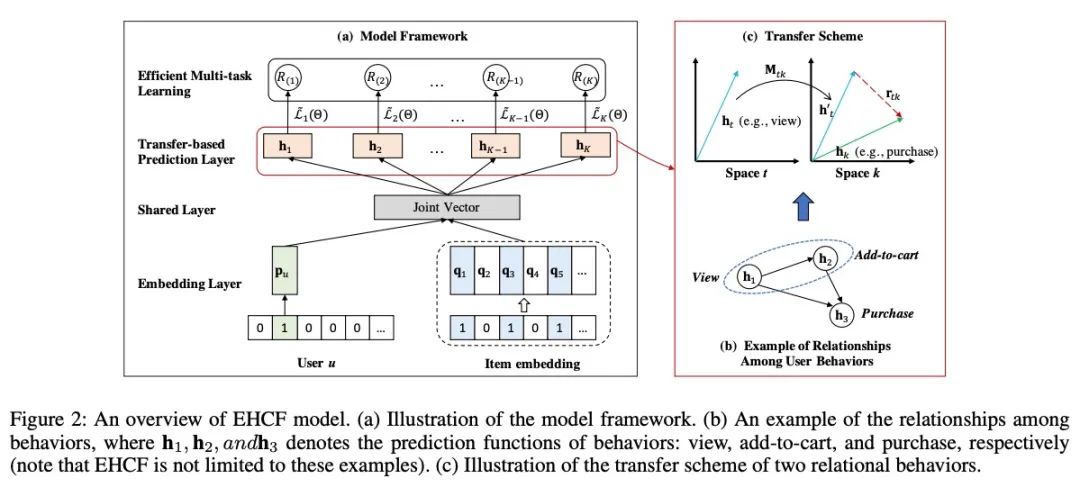
用户和商品会先被投影为一个dense向量表示,user-item的对(u,v),我们使用用户以及他对应的商品交互作为输入,此外,这边我们不进行采样,使用一种高效的优化方法。
对于每一个user-item的实例(u,v),映射函数可以定义为:
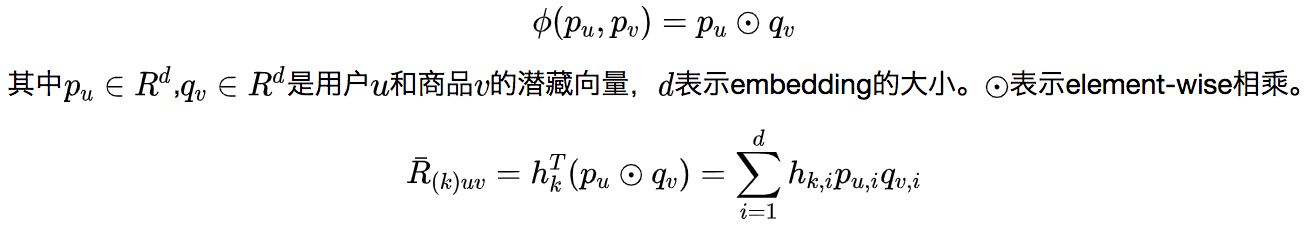
1. Transfer-based Multi-behavior Prediction
不同的行为之间是存在转化关系的,两个行为之间的关系可以通过下面的方式来定义:
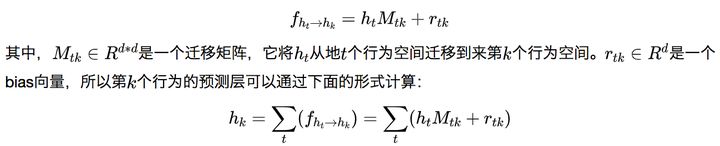
其中t表示第k个行为之前的行为,初始的行为是随机初始化的(在推荐里面就是view)。
2. Efficient Optimization without Sampling
此处我们使用加权的regression loss

基于内积乘法操作的decouple的操作,
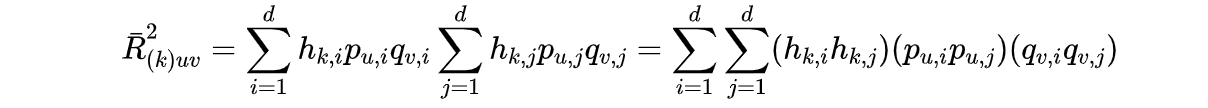
我们将上式代入得到:
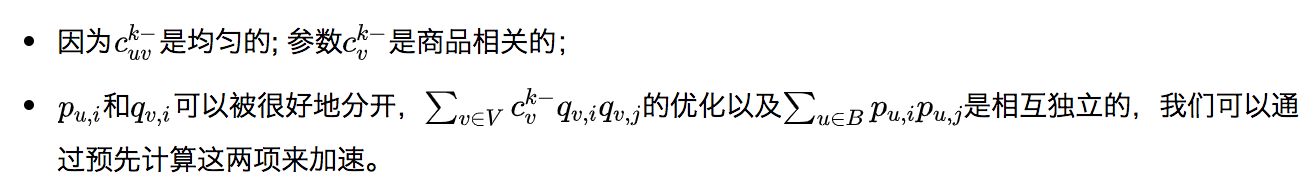
最终对于单个第k个行为的整个数据集的loss就是:
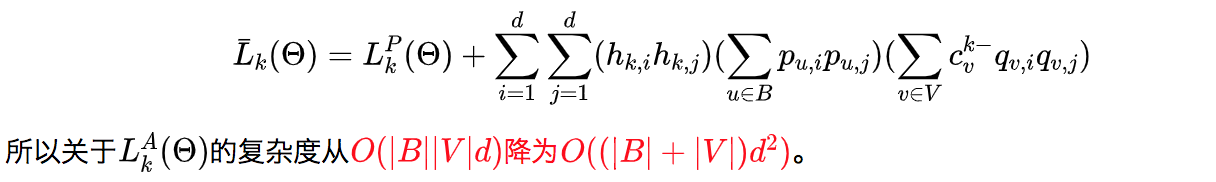
3. Multi-Task Learning

讨论


1. 效果比较
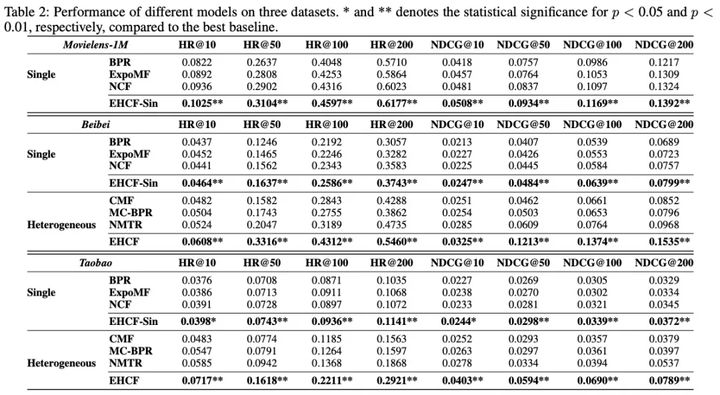
- 使用异质反馈的方法通常优于仅利用购买行为的方法,这表明了用户异质反馈的互补性;
- 使用全数据学习策略的方法通常比基于样本的方法表现更好;
2. 解耦实验

- 将View数据和购物车数据添加到我们的模型中都会带来改进,从而验证了辅助行为对用户偏好建模的有效性。
- 我们的方法的显著改进也表明了应用非抽样策略从异质反馈中学习的必要性。此外,没有迁移和没有MTL的变体的性能都比完整的EHCF模型差,这验证了所提出的基于迁移的预测层和多任务训练组件的有效性;
3. 效率分析
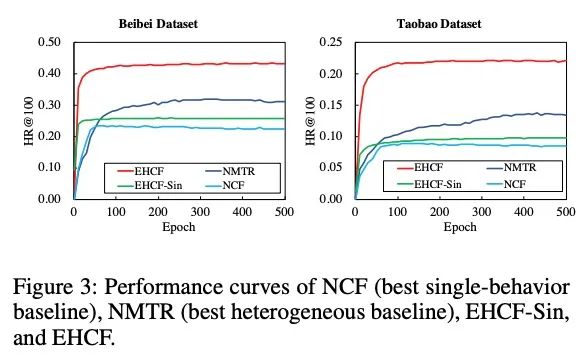
- EHCF比NCF和NMTR在单个行为数据以及heterogeneous数据上的效果都好;
4. 解决数据稀疏问题
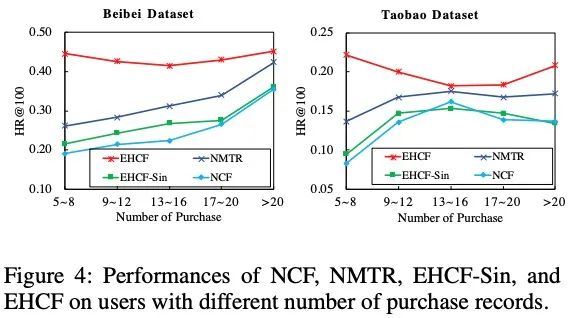
- 使用其它的信息可以缓解数据标签稀疏的问题(例如购买等);
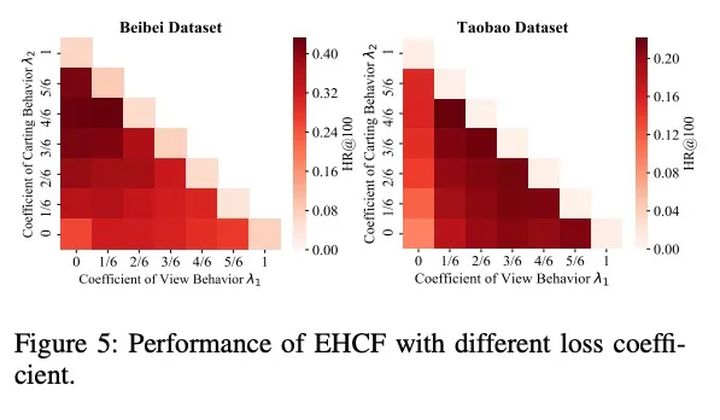
5. 参数的影响

本文提出了一种新的端到端推荐模型EHCF。所提出的EHCF具有两个关键特性:
- 采用新设计的优化方法进行高效的基于全数据的模型学习;
- 通过传递方式关联每个行为的预测,捕捉不同行为之间的复杂关系。
在三个真实数据集上的大量实验表明,EHCF不仅比现有的推荐模型有很大的提高,而且训练过程也相当快。这项工作补充了主流的基于样本的神经网络推荐模型和隐式反馈,为神经推荐模型的研究开辟了一条新的途径。所设计的高效的基于整体数据的策略有可能使许多人受益只观察到正面数据的任务。未来的工作包括在网络嵌入和多标签分类等其他相关任务中探索我们的EHCF模型。我们还将尝试扩展我们的优化方法,使它适用于学习非线性模型。
参考文献
1、看了很多负采样的论文,最后我选择不采样了。
2、Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation:http://www.thuir.cn/group/~mzhang/publications/AAAI2020-Chenchong.pdf
3、https://github.com/chenchongthu/EHCF/blob/master/code/EHCF.py
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!