NLP炼丹笔记:Switch Transformers 朴实无华 大招秒杀

Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Google Brain科学家Barret Zoph表示,他们设计了一个名叫「Switch Transformer」的简化稀疏架构,可以将语言模型的参数量扩展至 1.6 万亿。万万没想到,模型规模的演进如此之快,没几个月的时间,就从千亿走向了万亿,当我们还在研究BERT的各种迭代时,世界上那批顶尖的人已经开启了另一扇“暴力美学”的大门。而这,才是真正的深度领域的“军备竞赛“。

对于长文没有阅读习惯的朋友,可以直接读一下本文摘要。
1)Switch Transformer在网络结构上最大的改进是Sparse routing的稀疏结构,相比于OpenAI在GPT-3里所使用的Sparse Attention,需要用到稀疏算子而很难发挥GPU、TPU硬件性能的问题。Switch Transformer不需要稀疏算子,可以更好的适应GPU、TPU等硬件
2)Switch Transformer虽然有1.6万亿参数,但通过Sparse routing的改进,每轮迭代只会触发部分Expert的计算,而每个token也只会路由给一个Expert,所以对算力的需求并没有随着参数量的增加而大幅增长,使得这个模型更加容易训练。
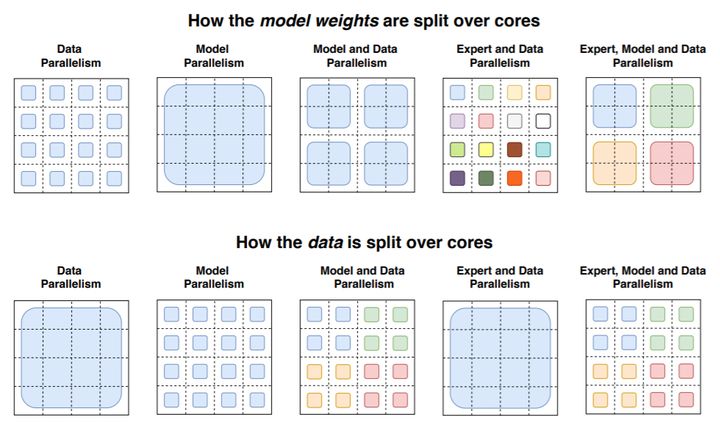
3)数据并行、模型并行、Expert并行的并行策略设计,在MoE网络结构上能够获得更低的通信开销,提高并行的效率。

在深度学习中,模型通常对所有输入重复使用相同的参数。而MoE模型则是为每个例子选择不同的参数。于是一个稀疏激活的模型(参数数量惊人但计算成本不变)诞生了。然而,尽管取得了一些显著的成功,但由于复杂性、通信成本和训练的不稳定性,模型广泛采用仍需优化。
我们用Switch Transformer来解决这些问题。同时,我们简化了MoE路由算法,设计了直观的改进模型,降低了通信和计算成本。我们提出的训练方法减轻了不稳定性,并且我们首次展示了用较低精度(bfloat16)格式训练大型稀疏模型的可能性。
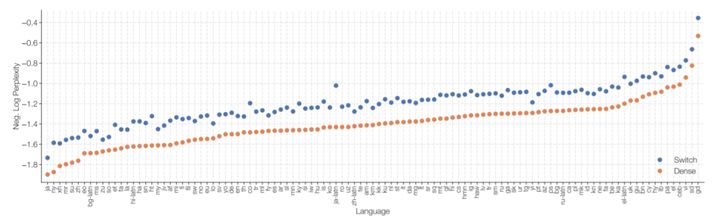
同时,基于T5 Base和T5 Large(Raffel et al.,2019)设计模型,以在相同计算资源的情况下获得高达7倍的预训练速度。这些改进扩展到多语言设置中,我们在所有101种语言中测量mT5基本版本的增益。最后,通过在“巨大的干净的爬虫语料库”上预训练多达万亿个参数的模型,提高了当前语言模型的规模,并实现了比T5-XXL模型4倍的加速。

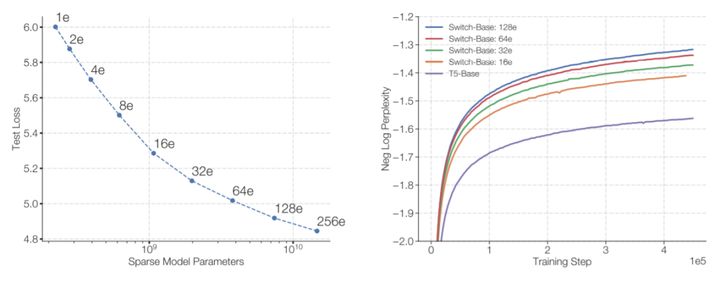
大规模训练是实现灵活和强大的神经语言模型的有效途径。虽然有效,但计算量也非常大(Strubell等人,2019年)。为了提高计算效率,我们提出了一种稀疏激活模型:Switch Transformer。在我们的例子中,稀疏性来自于为每个传入的例子激活一个子集的神经网络权重。
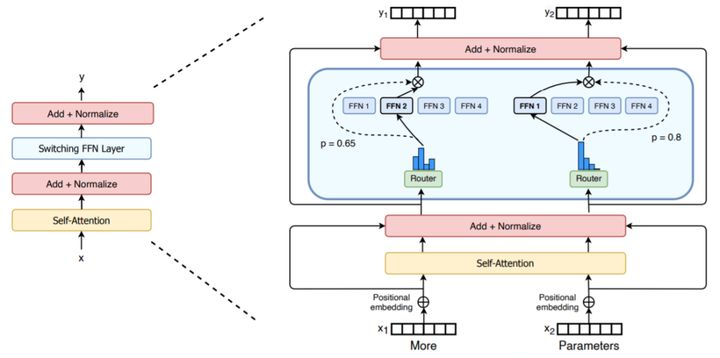

Switch Transformer在Mix of Expert的基础上,采用sparsely activated方法,只使用了模型权重的子集,转换模型内输入数据的参数达成相同的效果。

MoE(Mix of Expert)是一种神经网络,也属于一种combine的模型,上个世纪90年代被提出。适用于数据集中的数据产生方式不同。不同于一般的神经网络的是它根据数据进行分离训练多个模型,各个模型被称为专家,而门控模块用于选择使用哪个专家,模型的实际输出为各个模型的输出与门控模型的权重组合。各个专家模型可采用不同的函数(各种线性或非线性函数)。混合专家系统就是将多个模型整合到一个单独的任务中。

在分布式训练设置中,模型将不同的权重分配到不同的设备上,虽然权重会随着设备数量的增加而增加,但每个设备可以保持内存和计算足迹的自我管理。

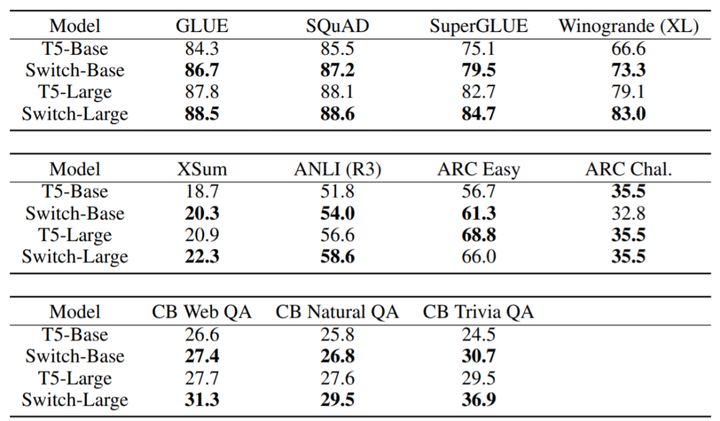

Switch Transformer在许多任务上的效果有提升。
(1)在使用相同数量的计算资源的情况下,它可以使预训练的速度提高了7倍以上。
(2)大型稀疏模型可以用来创建更小、更稠密的模型,这些模型可以对任务进行微调,其质量增益只有大型模型的30% 。
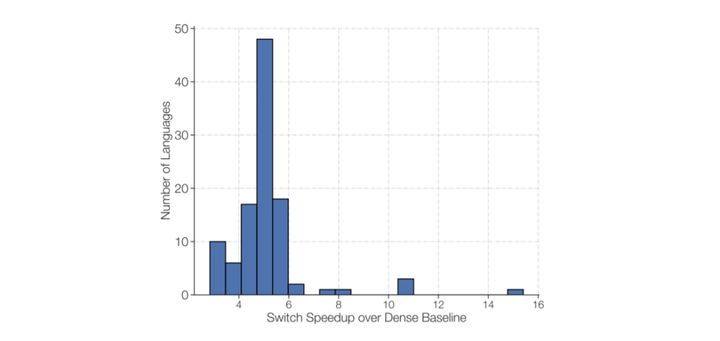
(3)Switch Transformer 模型在100多种不同的语言之间进行翻译,研究人员观察到其中101种语言都得到提升 ,而其中91% 超过基线模型4倍以上的速度。

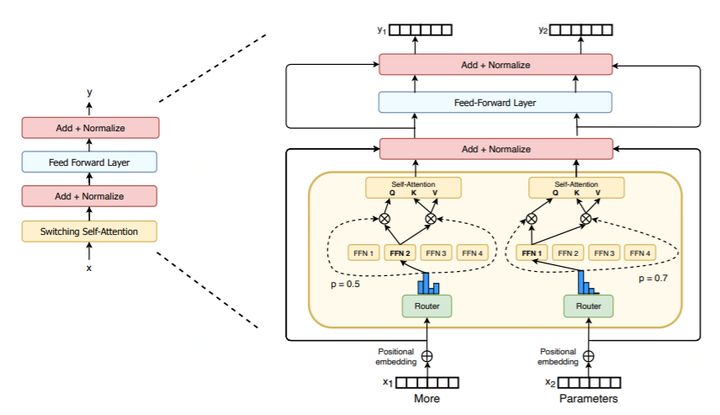
Shazeer(2018)和Lepikhin(2020)通过将MoE层添加到Transformer的密集前馈网络(FFN)计算中,设计了MoE变压器(Shazeer et al.,2017)。同样,我们的工作也替换了变压器中的FFN层,但在此简要探讨了另一种设计。我们将开关层添加到Transformer自我注意层中。为此,我们将生成查询、键和值的可训练权重矩阵替换为交换层。

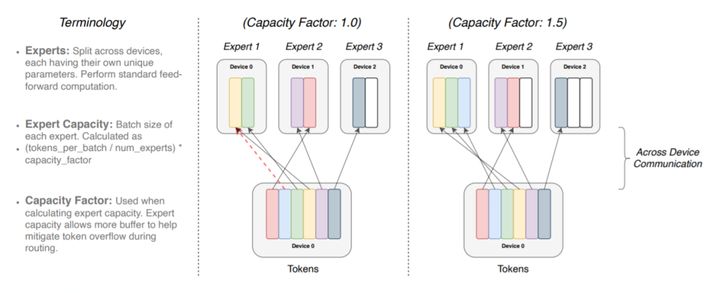
由于TPU加速器的限制,我们的张量的形状必须是静态的。因此,每个expert都有处理token表示的有限且固定的能力。然而,这为我们的模型提出了一个问题,该模型在运行时动态路由token,这可能导致在exper上的不均匀分布。
如果发送给exper的token数小于exper容量,那么计算可能只是简单地进行填充——这是对硬件的低效使用,但在数学上是正确的。但是,当发送给exper的令牌数大于其容量(exper溢出)时,需要一个协议来处理这个问题。Lepikhin等人(2020年)采用了exper模型的混合模型,并通过将其表示传递到下一层来解决exper溢出问题,而无需通过我们也遵循的剩余连接进行处理。

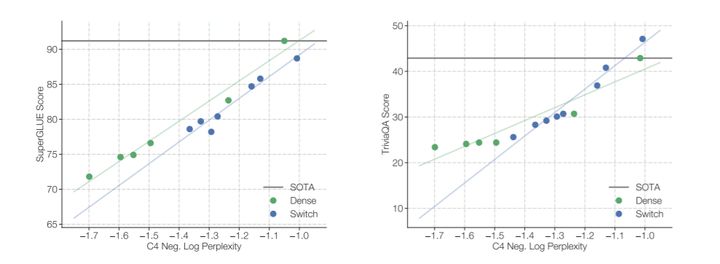
不能保证一个模型在训练前目标上的效果会转化为下游任务的结果。下图显示了上游模型质量的相关性,包括稠密模型和非稠密模型和Switch模型,在C4预训练任务上使用两个下游任务度量:平均SuperGLUE性能和TriviaQA分数。我们选择这两个任务作为一个探索模型的推理和其他事实知识。





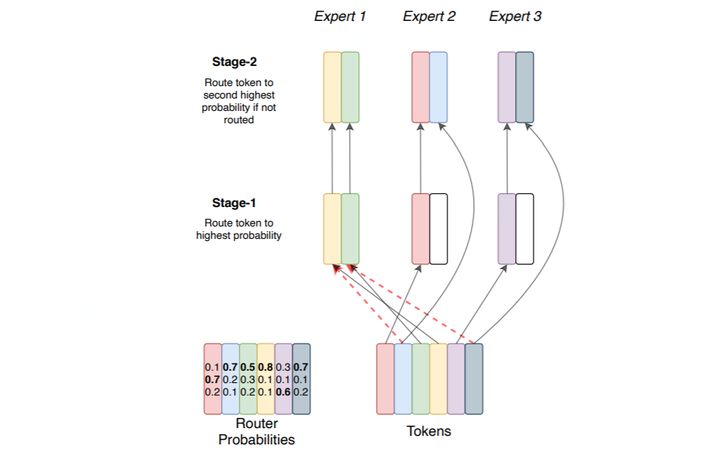
总结来说,Switch Transformers模型有两个创新:
(1)基于Transformer MoE网络结构,简化了MoE的routing机制,降低了计算量;
(2)进一步通过数据并行、模型并行、Expert并行的方式降低了训练通信量,提升训练性能。
参考文献
1. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity:https://arxiv.org/pdf/2101.03961.pdf
传送门:Google Brain:从不废话,直接扔大
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!