搜索推荐炼丹笔记:融合GNN、图谱、多模态的推荐

说到推荐系统,就不得不面对数据稀疏和冷启动问题,怎么解决呢?美团这篇论文《Multi-Modal Knowledge Graphs for Recommender Systems》说,我们不仅要加数据,而且是各种类型的都加。很多论文提出了用知识图谱作为推荐系统的辅助信息,而忽视了文本和图像,美团这篇论文,是第一个把知识图谱,多模态,attention都用来构建推荐系统的。模型模型也很霸气,叫MKGAT。GNN,知识图谱,多模态,推荐体系统在这篇论文里应有尽有。
知识图谱与推荐系统
知识图谱也算是火了很久,也已经广泛应用于学术界,工业界。知识图谱能给推荐系统提供丰富的特征和信息,有效的缓解了数据稀疏和冷启动。然而图片和文本会对推荐效果产生重大影响。举个 ,在看一部电影前,用户倾向于看海报和影评。在选择吃什么前,都会在大众点评上浏览各种美食图片。所以美团觉得,把这些多模态数据融入知识图谱,会对推荐系统产生很大的正面影响。一个简单的多模态知识图谱如下图:
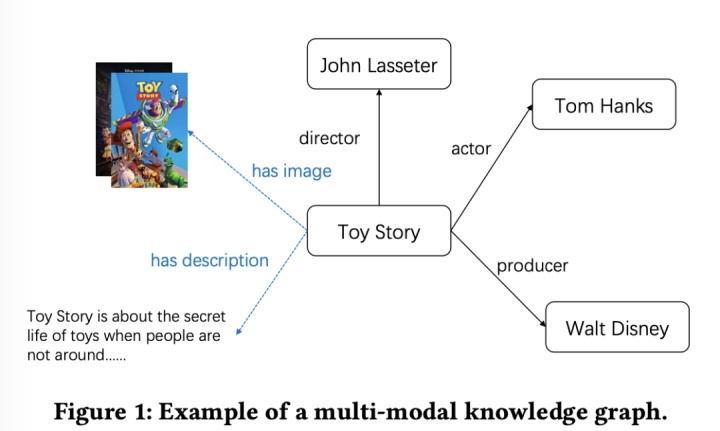
这张图,其实是很难作为推荐系统的输入的,所以往往是通过GNN等方式,学习图上每个实体的embedding,然后把和推荐上下文相关实体的embeding发送给下游辅助模型学习。学习多模态知识图谱的表达,有两种方法:
- 基于特征的方法:把多模态信息作为实体额外的信息,然而这需要数据源中每个实体都有多模态相关信息。
- 基于实体的方法:把各种多模态信息,都当作一个单独的实体,和其他实体建立联系。如上图"Toy Story" 和"电影海报"的关系是有一张图片。基于实体的方法就是分别用迁移模型和CNN等方法学习3元祖(h,r,t)的embedding,h为head,r为relation,t为tail。上图就有很多三元祖(Toy Story, has image, 海报),(Toy Story, director, John Lasseter)等等。
论文提到,基于实体的方法关注点是实体直接的联系,而非多模态数据,因此需要更显示的表达多模态信息相关实体,这时候MKGAT隆重登场。
问题定义
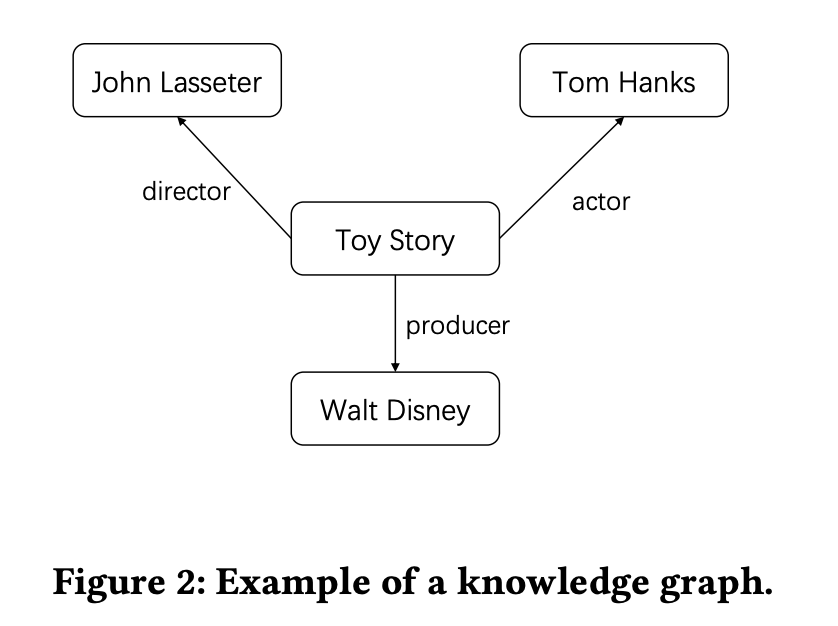
一个简单的知识图谱,就是由节点和边构成,G=(V,E)。从上图可知,这是个有向图,一条边r表达了head和tail的关系 ,如(Toy Story, actor, Tom Hanks)。多模态知识图谱中,图片文本就成了一等公民,成为了图中的实体。
联合知识图谱(collaborative knowledge graph),如下图:
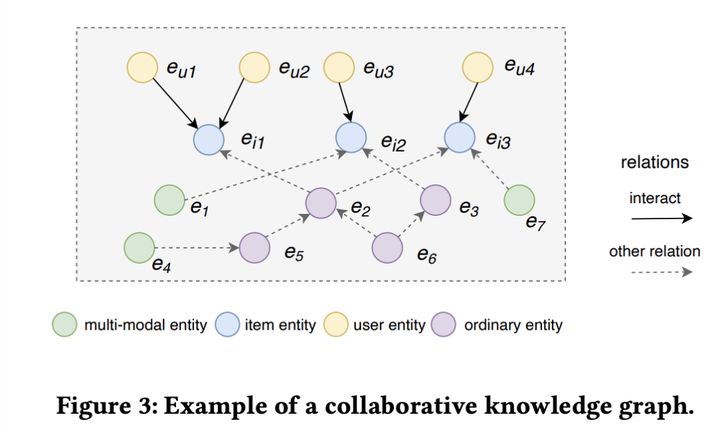
eu表示用户实体,ei表示item实体,绿色点就是多模态的实体,紫色点就是一般的实体。这张图箭头有实线,有虚线。实线表示某个用户对某个实体产生了某种交互(点击,购买等),虚线表示各种非人实体之间其他关系。这篇论文的输入就是上图,输出是用户会和某个item交互的概率。
MKGAT
先看下整体模型架构:
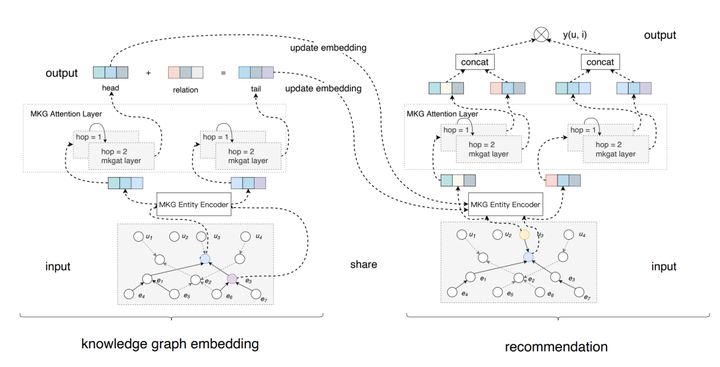
MKGAT可以拆解为两个子模块,多模态embeding模块和推荐模块。在介绍各个子模块前,我们先介绍两个小的模块:
- 多模态图谱实体编码器: 给不同类型实体编码
- 多模态图谱注意力层:用注意力机制,融合所有邻居节点的信息,学习新实体的embedding。
多模态embeding把联合知识图谱作为输入,充分利用上面提到的两个小模块,去学习各个entity的表达。再用各个实体embeding的表达,去学习图谱之间的关系。推荐模块充分利用知识图谱学到的embedding ,和联合知识图谱去丰富用户和items的表达,从而提升推荐效果。
多模态图谱实体编码器其实很简单,如下图所示:
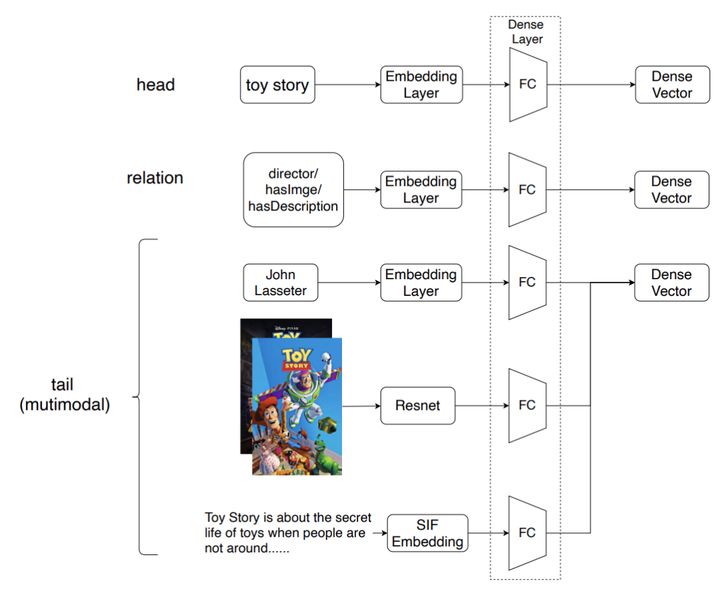
不同类型的数据用不同的embeding,一般的实体就是直接embeding+FC,图像就是CNN(Resnet)+FC,文本就是SIF+FC。
多模态图谱注意力层,看过GAT论文应该很熟悉,每个实体的embeding按照不同权重,聚合邻居节点。然而GAT忽视了KG节点直接关系是不同的,所以论文对此做了改进。如下图所示:
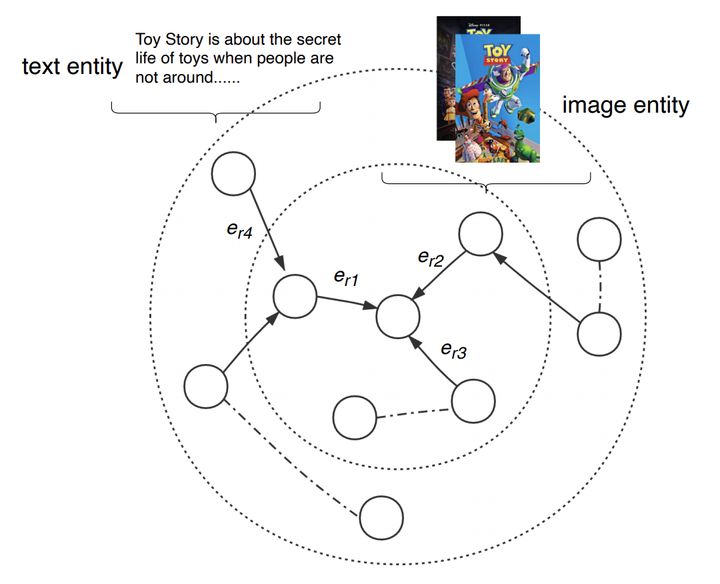
假设有个实体h,我们要学习(h,r,t),在transE模型中认为h+r=t,但是实体h连接了很多多模态邻居节点,我们可以融合这些邻居信息去丰富h,最终得到eagg,如下公式所示:
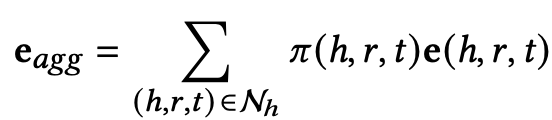
传播层:Nh就是h和所有邻居节点形成的三元祖,e(h,r,t)是三元祖的embeding,前面乘的是该三元祖的attention分数。如下定义
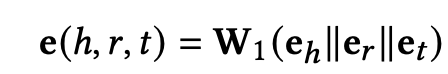
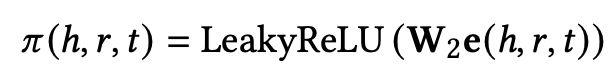
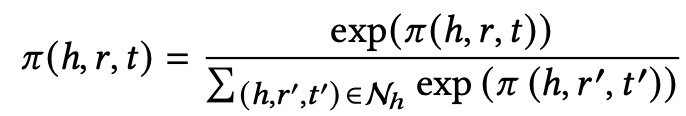
融合层:得到eagg后如何融合原本实体的向量eh呢?论文给出了两种方法:
加法融合:先对eh做线性变换到公共空间,然后直接相加(借鉴残差网络)
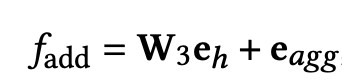
concat融合:
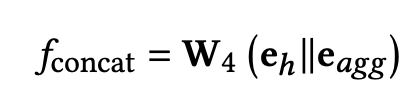
传播层和融合层在知识图谱中可以多次操作,以挖掘更深的信息,比如我们可以对邻居的邻居做传播融合,得到邻居的embeding后在做一次传播融合,得到该实体的embeding。
得到embeding后,就要确定目标函数了,该文用了一个pairwise ranking loss,其中t'是随机采样的实体,不满足(h,r,t')的关系,如下式所示:
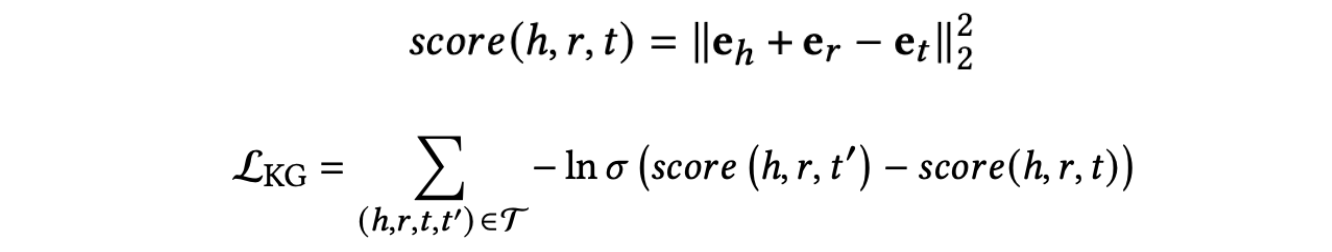
推荐模块
上一节只是把embeding学好了,但我们最终目标是给用户推荐商品。在推荐模块中,attention层依然可以复用,去融合邻居节点的信息。
对于一个用户(知识图谱中的一个实体),他已经有一个向量e0,我们可以通过他的邻居,用attention的方式,再给他生成另一个向量e1,用他邻居和他邻居的邻居再生成向量e2,依此类推,最后把这些向量concat在一起,就是用户最终向量。推荐的item同理,如下式:
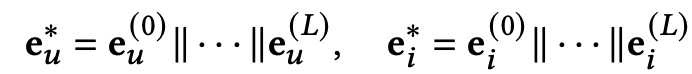
最终得到eu*和ei*后,直接点积再接BPR loss即可,如下式子:
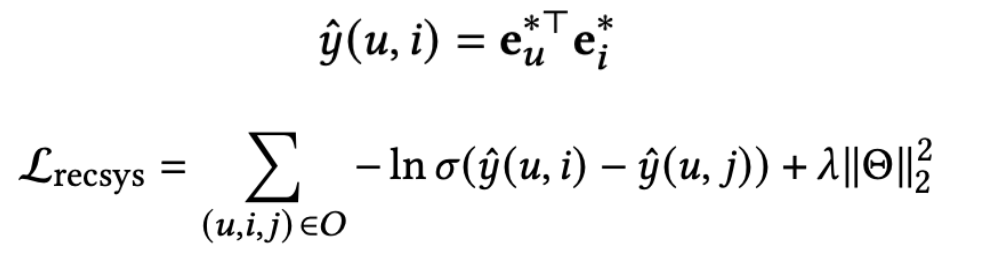
实验
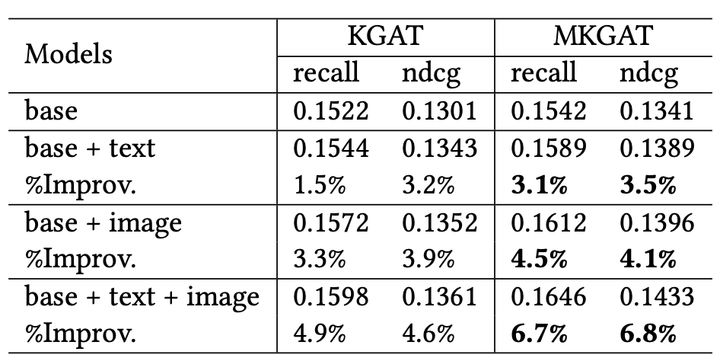
对比了目前一些算法,该MKGAT表现无论是在recall指标还是ndcg,都优于现有算法。
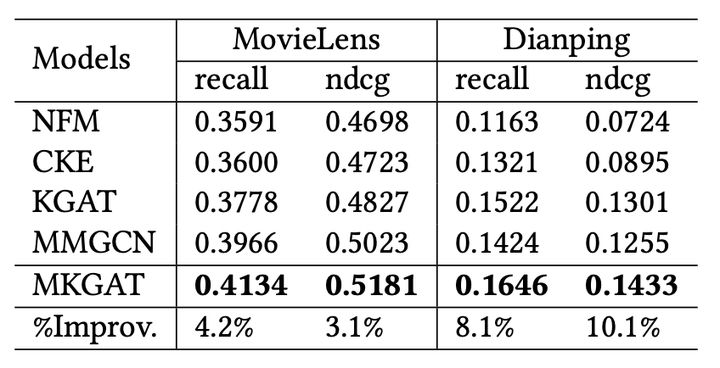
论文还提到,多模态相比于没有多模态的图谱,对推荐效果的提升也是显而易见的。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!