内容流推荐中的个性化标题生成框架
最近读了两篇微软亚研院的论文,关于新闻内容流推荐的,简单分享一下,主要包含两部分,第一部分《NPA: Neural News Recommendation with Personalized Attention》主要是怎么实现个性化新闻推荐,第二部分《PENS: A Dataset and Generic Framework for Personalized News Headline Generation》阐述怎么实现个性化标题的生成。
对于个性化标题生成的在业务中的真实作用,实践过的人都会有自己的看法,笔者在这里不做过多评价了,从学习或者了解的角度出发,我们来看看这个方向的研究。

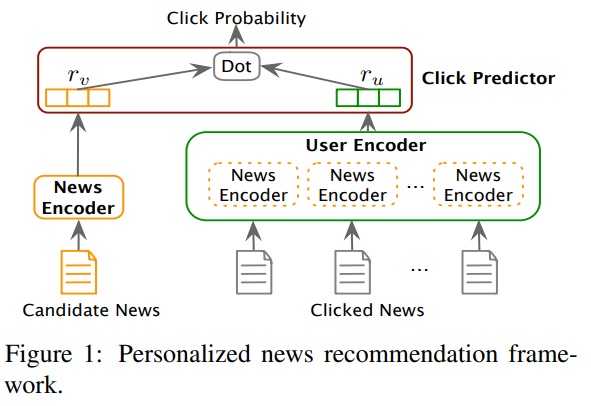
内容推荐作为一个推荐系统的一个子任务,常规推荐的思路,例如协同过滤等当然可以用于内容召回以及候选内容的排序。但是,与传统的稳态推荐任务不同,内容推荐有其特有的挑战。尤其是在新闻内容上,大部分会因为时效性原因无法再被推荐出来,同时会快速地出现新内容,急需推送给需要它的读者,这就带来了严重的Item冷启动问题。这也使得基于协同过滤的方法直接应用于新闻推荐的场景时,有了诸多问题。
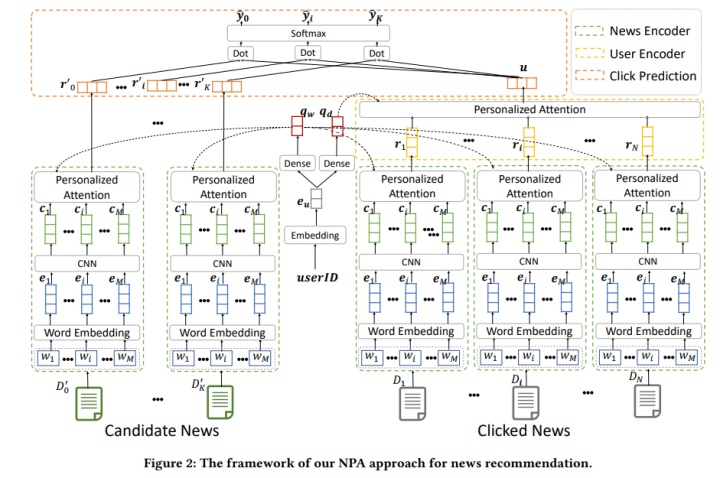
在了解上图的基于个性化注意力机制的新闻推荐之前,我们先从可视化的角度来看看论文中一些关于Attention有意思的展示。


从图中可以发现,基于个性化注意力机制的新闻推荐模型能识别和选择重要的Words和News。例如,football、nba这样的词语对于推测新闻的主题很有帮助,因此被高亮,而像 every这样的词语则信息量较低。对于新闻而言,例如第4条新闻被高亮,因为它能够很好地反映用户的兴趣,而如第3和第5条新闻则可能被各种类型的用户浏览,没有兴趣区分度,因此获得了较低的权重。
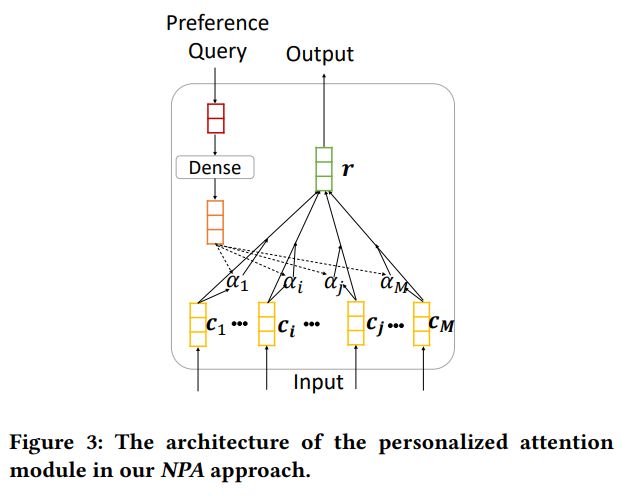
回过头我们来看看模型架构层面,比较简单,一个将词语序列转化为语义向量序列的词嵌入层,一个用于建模局部上下文的 CNN 层,和一个Word级的Self-Attention,后面是通过內积计算得到候选集中的Item预测分数。负采样方面,将每个用户点击的新闻(视为正样本)搭配 K 个在同一个会话内展示而没有被用户点击的新闻视为负样本。对于这种采样,笔者之前写过挺多的对比总结性文章,有兴趣的同学可以翻翻以往文章,看看这里是不是还有提升改进的可能性。

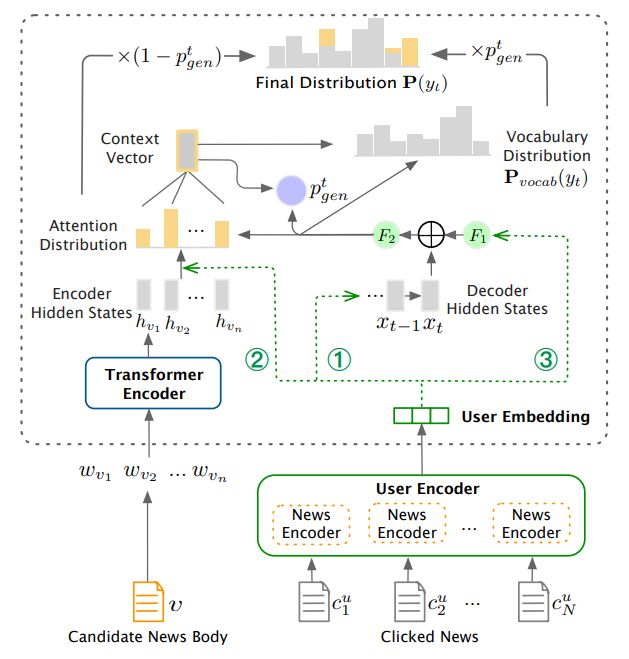
先放框架,再来聊一聊,从上图比较清晰的发现,左侧Transformer Encoder编码候选集合中的文本信息,然后通过Attention学习正文单词的隐藏表示。而在右侧,就是通过用户点击过的内容得到User Embedding,而个性化层面架构中给出了3种方式,第一种是将User Embedding作为指针网络解码器的初始隐藏状态Decoder Hidden States;第二种是加入左侧的Attention的计算中,区分用户对内容的关注程度;第三种是最右侧的方式,将User Embedding加入到Pgen的计算中。
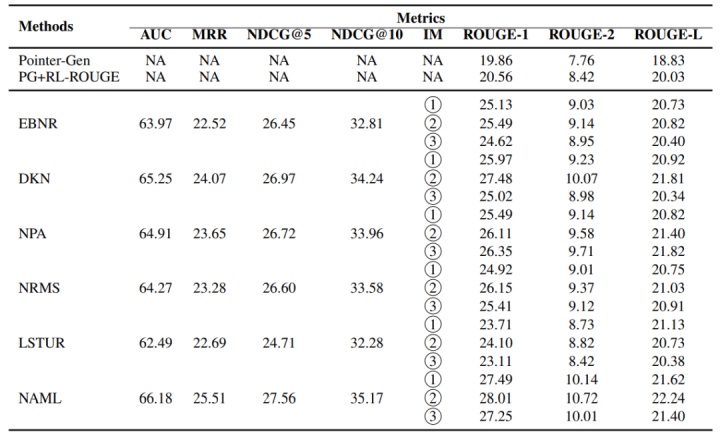
三种方式的效果如下:
参考资料
- https://www.zhihu.com/question/23644385/answer/914251962
- https://www.microsoft.com/en-us/research/uploads/prod/2021/06/ACL2021_PENS_Camera_Ready_1862_Paper.pdf
- https://zhuanlan.zhihu.com/p/396306358
- https://arxiv.org/pdf/1907.05559.pdf
- GitHub地址:https://msnews.github.io/pens.html
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!