双塔模型中的负采样
推荐模型中双塔模型早已经普及.一个塔学用户表达.一个塔学item表达.很多双塔模型用各种各样的in-batch负采样策略.十方也是如此.往往使用比较大的batchsize,效果会比较好,但是由于内存限制,训练效率会比较低.这篇论文《Cross-Batch Negative Sampling for Training Two-Tower Recommenders》发现encoder的输出在warming up的训练过程后就比较稳定了,基于此提出一个高效负采样的方法Cross Batch Negative Sampling (CBNS),该方法充分使用了最近编码过的item embedding来加速训练过程.
CBNS
关于问题定义就不赘述了,双塔已经写了很多了,计算用户与item相似度也是用简单的点积。loss最典型的就是用sampled softmax:
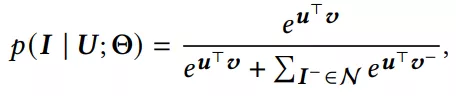
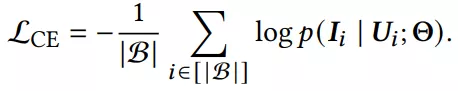
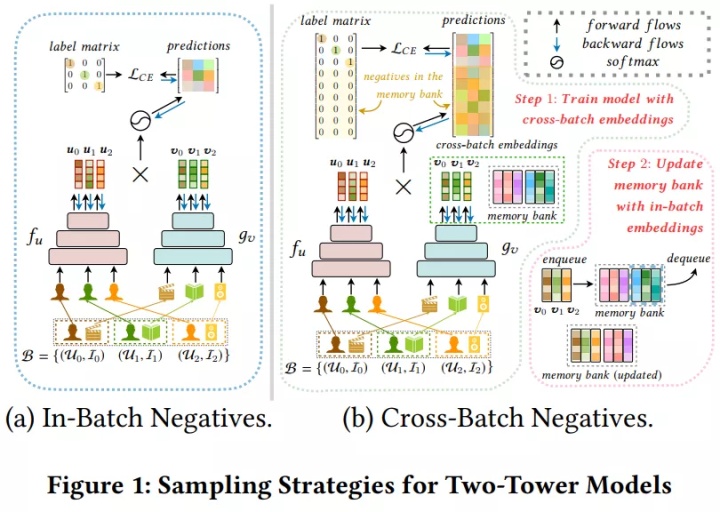
提升训练效率,最好使的就是batch内负采样了,如下图(a)所示。
参考sampled softmax机制,论文修改上述公式为:
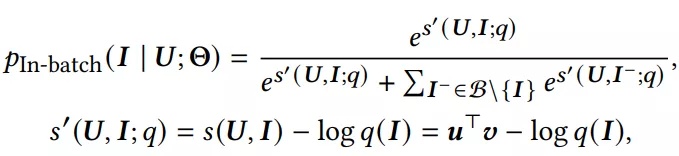
其中q(I)为采样偏差。接下来就要说到cross-batch negative sampling,这个方法可以解决in-batch负采样中,存在batch size受到gpu显存大小,从而影响模型效果。在训练过程中,我们往往认为过去训练过的mini-batches是无用废弃的,论文中则认为这些信息可以反复利用在当前负采样中因为encoder逐渐趋于稳定。论文中用下式评估item encoder特征的偏移:
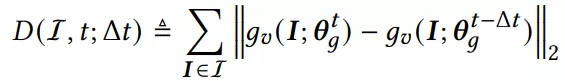
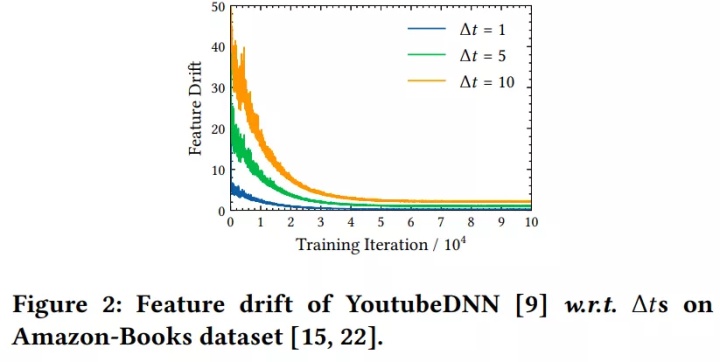
如上图(b)所示,在早期学习率较大的时候,encoder编码相同item的变化是很大的,随着训练过程的推进,学习率逐渐降低,特征逐渐趋向于稳定,如下图所示
这时候我们可以充分利用稳定的embedding作为负样本。但是用历史的embedding会给梯度带来偏差,论文有证明这个偏差影响是很小的:

考虑到训练前期embedding波动较大,在warm up过程中先使用简单的in-batch内负采样,然后使用一个FIFO memory bank,存放M个历史item embedding
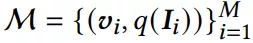
q(I)表示第i个item的采样概率。CBNS的softmax如下式所示:
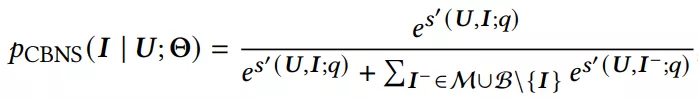
在每次迭代结束,都会把当前mini-batch的embedding和采样概率加入memory bank.在下次训练过程中,除了使用batch内负样本,同时也会从memory bank中拉取负样本.
实验
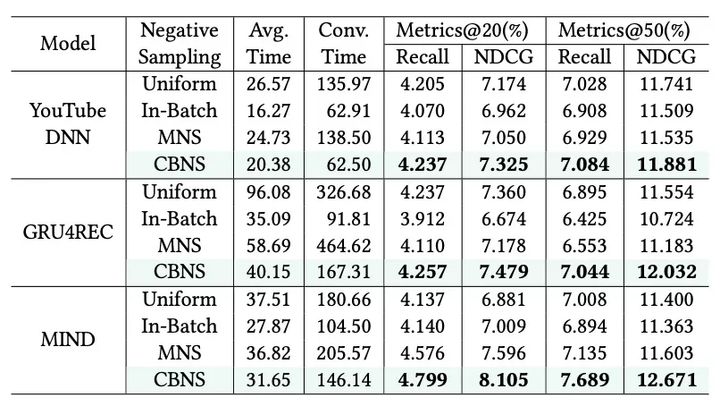
对比不同采样策略下的表现:
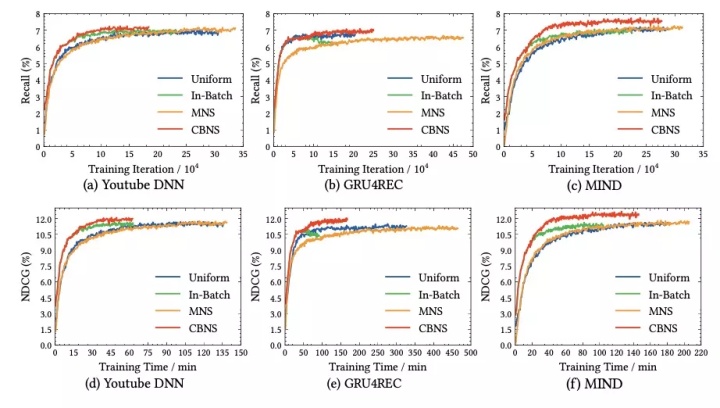
以及在不同模型下验证集的召回和NDCG曲线:
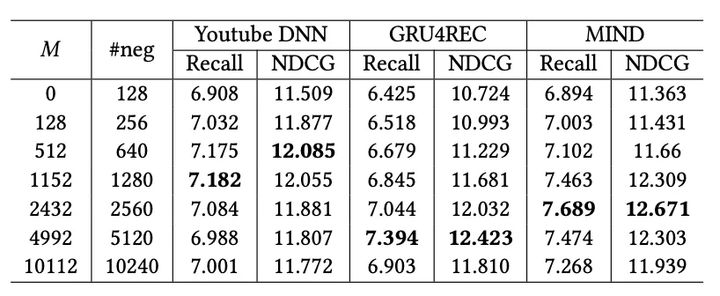
同时论文还对比了M大小/负样本数对效果的影响:
参考文献
双塔模型中的负采样

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!