淘宝搜索中基于embedding的召回
对于电商平台而言,商品搜索服务已经是人们日常购物中重中之重的服务了,商品的召回决定了搜索系统的质量。商品搜索需要从一个巨大的语料库中找到最相关的商品,同时还要保证个性化。目前很多论文都在探讨基于embedding的召回(EBR),这篇论文
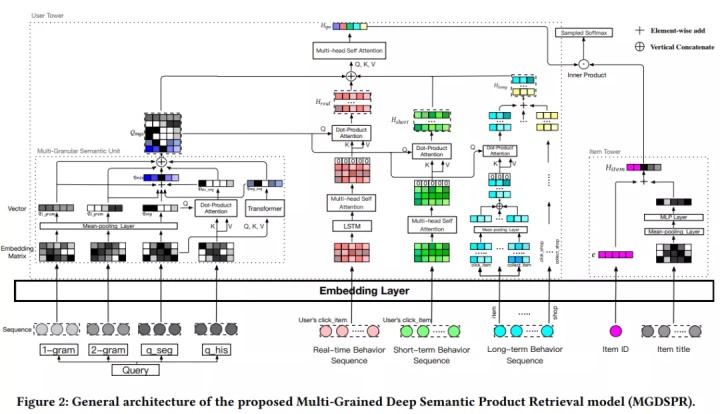
MGDSPR
我们先看下淘宝商品搜索系统的全貌,每个环都是一个阶段:
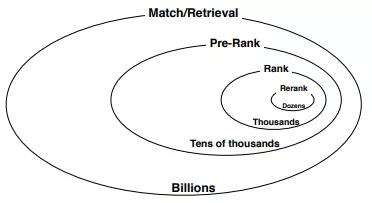
我们可以看到retrieval阶段有亿级别的商品,通过我们的深度语义召回系统最终召回上万个相关商品。接下来开始介绍深度语义商品召回模型,我们有用户全集U={u1,u2,...,UN},还有query集合Q={q1, q2, ..., qN},同时还有商品集合I={i1, i2, ..., iM}。我们把用户历史行为序列参照时间区间分到3个子集,实时集合R = {i1, i2, ..., iT},短期集合 S = {i1, i2, ..., iT},长期集合L = {i1, i2, ..., iT},所以任务就是给定一个用户u的(R,S,L),以及query,返回top-K items:
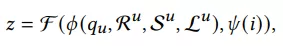
用户塔:淘宝中的query多为中文,在切词后平均长度小于3,因此我们提出了多粒度的语义单元,从不同的语义粒度挖掘query含义,提升query的表达精度。给定一个query的切词q={w1, ..., wn}(e.g. {红色,连衣裙}),每个单词可以拆成字粒度w = {c1, ..., cm},同时我们还能拿到历史query qhis= {q1, ..., qk},所以我们可以得到6种粒度的表达:
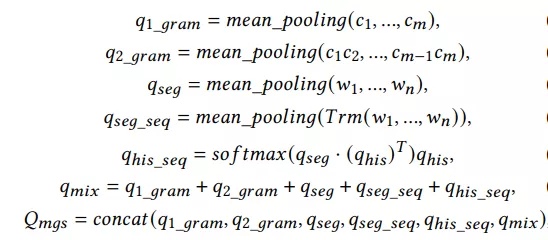
Trm用的transformer,最后把6种粒度的embedding都concat在一起。
用户行为注意力机制: 用户历史点击购买的items,和每个item的side information,都可以通过embedding的方式将每个item都映射成固定长度的向量,这里我们用query与历史行为items做attention,找到相关items。对于实时集合,使用LSTM进行编码,然后套用个self-attention层,并在序列最前面加上0向量(以防历史行为没一个相关的),最后用一个attention操作获得最终embedding,如下公式所示:

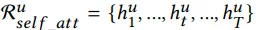
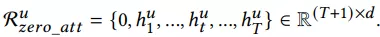
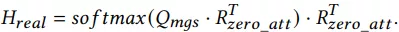
对于短期行为使用多头self-attention,头部添加0向量,并计算attention:
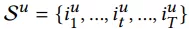
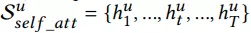
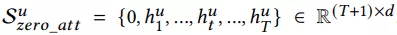
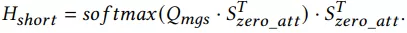
对于长期行为(一个月内)而言,分别对点击,购买,加购集合进行mean pooling,再与query进行attention:
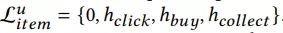

对长期行为的item的店铺,类目,品牌做同样的操作,最后把embeding进行sum pooling:
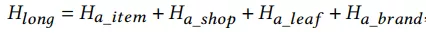
最后再把以上所有进行融合:
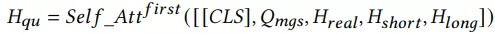
商品塔:商品塔只需要把itemID和标题进行融合得到最终embedding,如下式所示:

e表示商品embedding,wi表示标题切词,wt是转移矩阵。
综上整个模型如下所示:
论文分析到hing loss只能做local的比较,由此会产生预估与训练的diff,所以该文直接用softmax cross-entropy loss,定义如下:
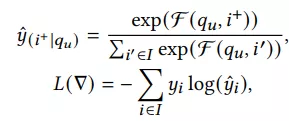
实践中论文使用的sampled softmax。
因为存在很多噪音数据,导致query和商品完全不相关,所以论文在softmax函数引入了一个温度:
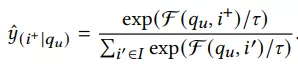
在样本上,需要构造强负例,本文提出的强负例构造方法是在样本空间中构造,给定训练样本(qu, i+, i-),i-是在样本池随机负采样,为了简化,i-在负样本池找到和qu点积最大的topN,并和i+进行融合成强负例,定义如下:
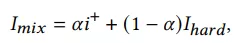
最终融合了强负例的softmax函数如下:

论文后面还有很多工程介绍,感兴趣可以参考原文。
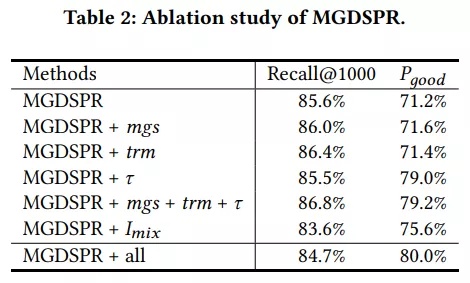
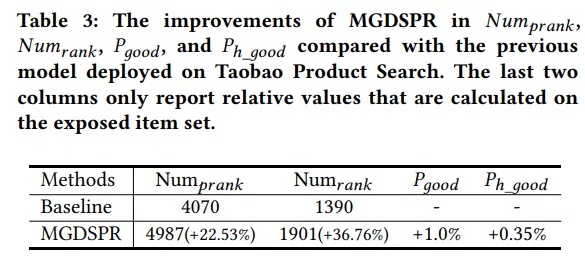
实验


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!