Transformer又又又升级了?
Transformer,一个nlp绕不开的话题,现在连推荐和图像也绕不开了。这么强大的模型倒不是没有缺点,例如训练预估慢就是它的硬伤,所以常常受资源/时间等限制,都会优先尝试tiny-bert等较小的模型去处理,但是论文表明这种处理对效果是有一定影响的。有没有又快又好的模型呢?它来了-Fastformer,不仅线性复杂度,还刷新了很多榜单。
fastformer
先温习下transformer中的self-attention,如下图所示:
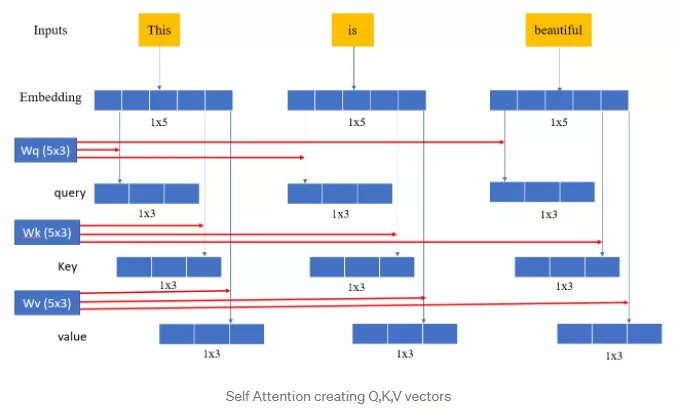
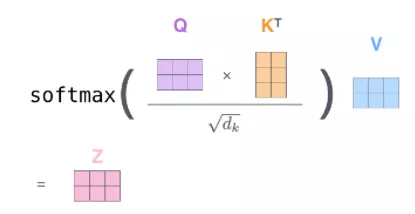
我们可以看到query中每个向量都需要与key中的向量做点积,才能最终得到最终向量。让我们再看看fastformer:
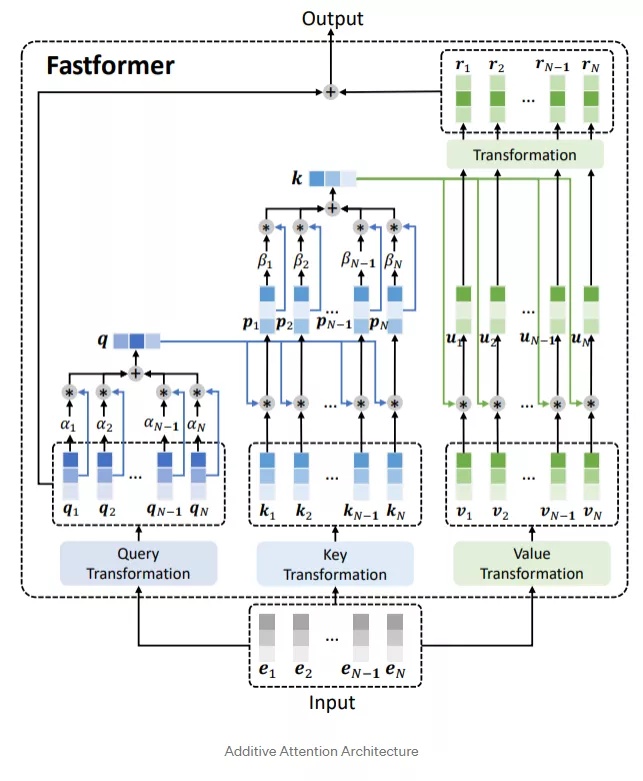
我们可以看到query中所有向量通过additive attention聚合成了一个全局向量,然后和key做element-wise乘法,又通过additive attention聚合成全局key向量,最后和value做element-wise后做线性变换得到r1~rN,最后输出q1+r1, q2+r2, q3+r3。
additive attention, wq和wk是可学习的参数:
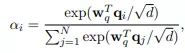
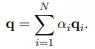
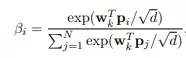
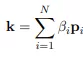
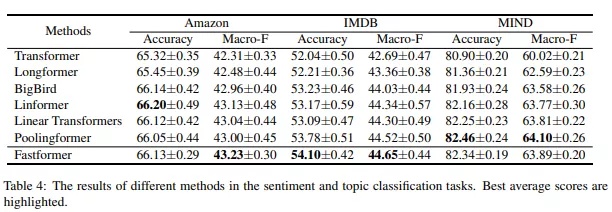
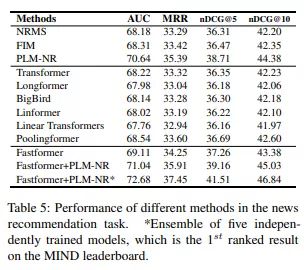
实验
参考文献
1、https://arxiv.org/pdf/2108.09084.pdf
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!