信息抽取(二)花了一个星期走了无数条弯路终于用TF复现了苏神的《Bert三元关系抽取模型》,我到底悟到了什么?
信息抽取(二)花了一个星期走了无数条弯路终于用TF复现了苏神的《Bert三元关系抽取》模型,我到底悟到了什么?
- 前言
- 数据格式与任务目标
- 模型整体思路
- 复现代码
- 数据处理
- 数据读取
- 训练数据处理
- 模型搭建
- 模型参数图
- Conditional_LayerNormalization
- SPO的抽取,评估并保存模型
- 模型训练
- 一些排坑
- 可能的优化方向
- 总结
前言
先上热菜致敬苏神:苏剑林. (2020, Jan 03). 《用bert4keras做三元组抽取 》[Blog post]. Retrieved from https://kexue.fm/archives/7161
建议大家先看苏神的原文,如果您能看懂思路和代码的话我的文章可能对你的帮助不大。
拜读这篇文章之后本人用TF + Transformers 复现了该baseline模型,并在其基础上进行了大量的尝试,直到心累也没有成功复现相同水平的结果,但也有所接近,因此用这篇文章复盘整个过程并分享一些收获和心得。
数据格式与任务目标
数据下载地址:https://ai.baidu.com/broad/download?dataset=sked
数据格式:
{"text": "查尔斯·阿兰基斯(Charles Aránguiz),1989年4月17日出生于智利圣地亚哥,智利职业足球运动员,司职中场,效力于德国足球甲级联赛勒沃库森足球俱乐部",
"spo_list":
[{"predicate": "出生地", "object_type": "地点", "subject_type": "人物", "object": "圣地亚哥", "subject": "查尔斯·阿兰基斯"},
{"predicate": "出生日期", "object_type": "Date", "subject_type": "人物", "object": "1989年4月17日", "subject": "查尔斯·阿兰基斯"}]}
简单来说给定一段文本,我们需要从中抽取出多组 S(subject) P(predicate) O(object_type)的关系。
例如:“查尔斯·阿兰基斯–出生日期–1989年4月17日”则是一组我们需要抽取出来的信息。而 P(需要预测的关系)已经给定范围,一共49类关系,具体见 all_50_schemas 。
模型整体思路
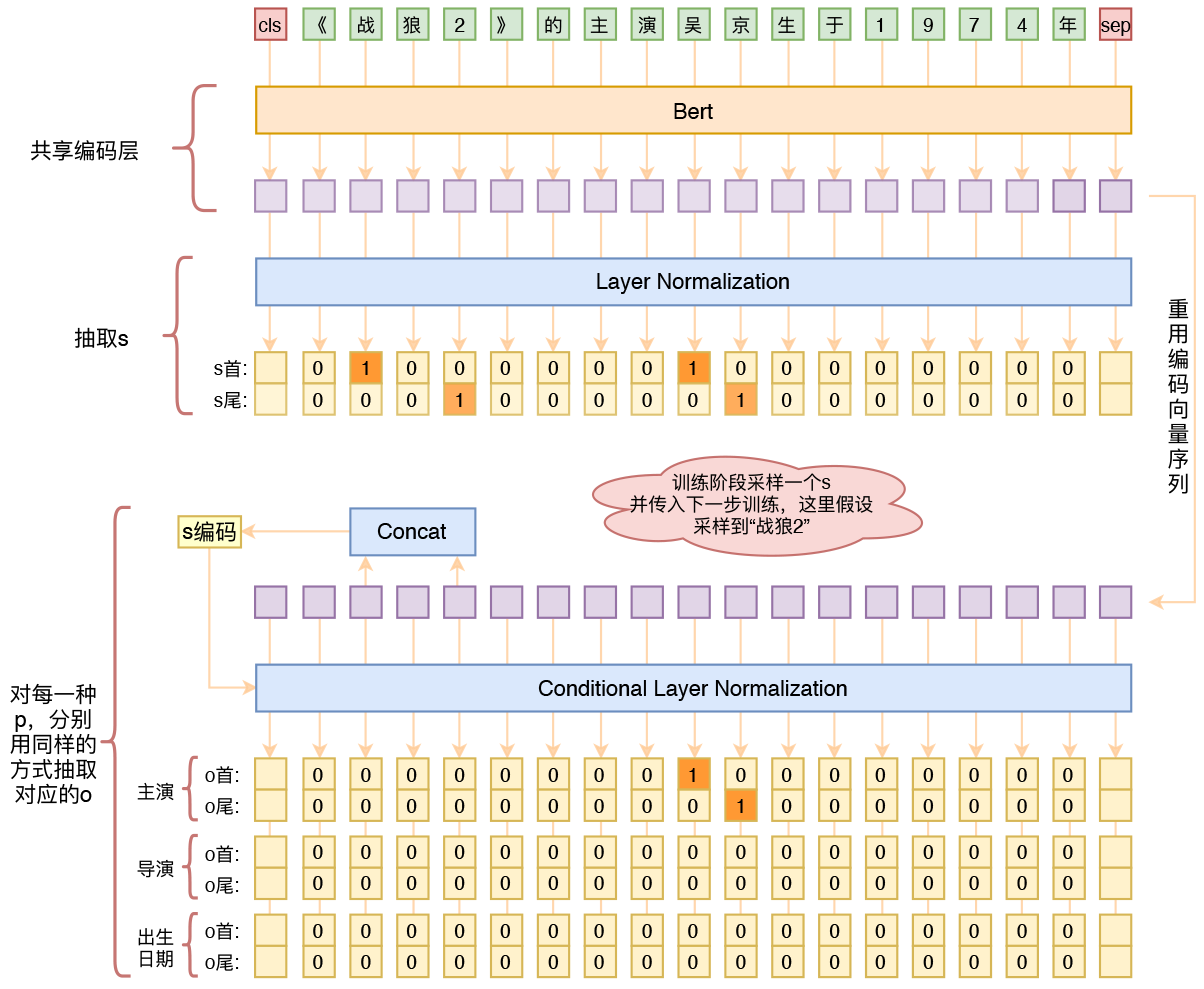
这个模型思路的精彩之处:
-
该任务本来应该分成两个模块完成:1.抽取实体(包括S和O)2.判断实体之间的关系,理应至少需要两个模型协同完成,但苏神将实体之间的关系类别预测隐性的放在了O抽取的过程中,即让模型在预测O的时候直接预测O与S的关系P。
-
指针标注:对每个span的start和end进行标记,对于多片段抽取问题转化为N个2分类(N为序列长度),如果涉及多类别可以转化为层叠式指针标注(C个指针网络,C为类别总数)。事实上,指针标注已经成为统一实体、关系、事件抽取的一个“大杀器”。
-
由于一个文本中可能存在多对SPO关系组,甚至可能存在S之间有Overlap,O之间有Overlap的情况,因此模型的输出层使用的是半指针-半标注的sigmoid(类似多标签预测实体的始末位置,与阅读理解相似)这样可以让模型同时标注多对S和O。
-
使用Conditional Layer Normalization 我们需要在预测PO时告诉模型,我们的S是什么,以至于使得模型学习到PO的预测是依赖于S的,而不是看见“日期”就认为是出生年月。具体的内部实现流程也可以参考我的代码,会有介绍。(这各地方也卡了我很久才跑通)最后评估下来这个方法有利也有弊。
复现代码
数据处理
数据读取
def load_data(path):text_list = []spo_list = []with open(path) as json_file:for i in json_file:text_list.append(eval(i)['text'])spo_list.append(eval(i)['spo_list'])return text_list,spo_listdef load_ps(path):with open(path,'r') as f:data = pd.DataFrame([eval(i) for i in f])['predicate']p2id = {}id2p = {}data = list(set(data))for i in range(len(data)):p2id[data[i]] = iid2p[i] = data[i]return p2id,id2p
训练数据处理
这里处理的思路和信息抽取(一)中处理的思路相似,有详细的代码注释:
信息抽取(一)机器阅读理解——样本数据处理与Baseline模型搭建训练(2020语言与智能技术竞赛)
这里主要介绍针对本次任务的几个细节和trick:
- 由于一段文本可能存在多个S,因此遍历一组数据里的所有SPO关系,将所有S的头尾位置放在一个01数组中。
- 对于存在多组SPO关系的样本,在标注PO时,我们只随机选取一个S,理由比较简单,你没办法一下子传入多个S给下一个模型。
- 抽取S时,随机选取一个S的首位置,从所有S的末位置中选取一个与之匹配,如果是完整的S,则对其所有的PO进行标注,否则跳过,该样本作为负样本。这是为了让模型学会并非所有抽取出来的S都有对应的PO关系。
- 由于限制了token长度,对于找不到S的样本最后去除,对于找不到P的样本保留,同样作为负样本。
def proceed_data(text_list,spo_list,p2id,id2p,tokenizer,MAX_LEN):id_label = {}ct = len(text_list)MAX_LEN = MAX_LENinput_ids = np.zeros((ct,MAX_LEN),dtype='int32')attention_mask = np.zeros((ct,MAX_LEN),dtype='int32')start_tokens = np.zeros((ct,MAX_LEN),dtype='int32')end_tokens = np.zeros((ct,MAX_LEN),dtype='int32')send_s_po = np.zeros((ct,2),dtype='int32')object_start_tokens = np.zeros((ct,MAX_LEN,len(p2id)),dtype='int32')object_end_tokens = np.zeros((ct,MAX_LEN,len(p2id)),dtype='int32')invalid_index = []for k in range(ct):context_k = text_list[k].lower().replace(' ','')enc_context = tokenizer.encode(context_k,max_length=MAX_LEN,truncation=True) if len(spo_list[k])==0:invalid_index.append(k)continuestart = []end = []S_index = []for j in range(len(spo_list[k])):answers_text_k = spo_list[k][j]['subject'].lower().replace(' ','')chars = np.zeros((len(context_k)))index = context_k.find(answers_text_k)chars[index:index+len(answers_text_k)]=1offsets = []idx=0for t in enc_context[1:]:w = tokenizer.decode([t])if '#' in w and len(w)>1:w = w.replace('#','')if w == '[UNK]':w = '。'offsets.append((idx,idx+len(w)))idx += len(w)toks = []for i,(a,b) in enumerate(offsets):sm = np.sum(chars[a:b])if sm>0: toks.append(i) input_ids[k,:len(enc_context)] = enc_contextattention_mask[k,:len(enc_context)] = 1if len(toks)>0:start_tokens[k,toks[0]+1] = 1end_tokens[k,toks[-1]+1] = 1start.append(toks[0]+1)end.append(toks[-1]+1)S_index.append(j)#随机抽取可以作为负样本提高准确率(不认同)if len(start) > 0:start_np = np.array(start)end_np = np.array(end)start_ = np.random.choice(start_np)end_ = np.random.choice(end_np[end_np >= start_])send_s_po[k,0] = start_send_s_po[k,1] = end_s_index = start.index(start_)#随机选取object的首位,如果选取错误,则作为负样本if end_ == end[s_index]:for index in range(len(start)):if start[index] == start_ and end[index] == end_:object_text_k = spo_list[k][S_index[index]]['object'].lower().replace(' ','')predicate = spo_list[k][S_index[index]]['predicate']p_id = p2id[predicate]chars = np.zeros((len(context_k)))index = context_k.find(object_text_k)chars[index:index+len(object_text_k)]=1offsets = [] idx=0for t in enc_context[1:]:w = tokenizer.decode([t])if '#' in w and len(w)>1:w = w.replace('#','')if w == '[UNK]':w = '。'offsets.append((idx,idx+len(w)))idx += len(w)toks = []for i,(a,b) in enumerate(offsets):sm = np.sum(chars[a:b])if sm>0: toks.append(i) if len(toks)>0:id_label[p_id] = predicateobject_start_tokens[k,toks[0]+1,p_id] = 1object_end_tokens[k,toks[-1]+1,p_id] = 1else:invalid_index.append(k)return input_ids,attention_mask,start_tokens,end_tokens,send_s_po,object_start_tokens,object_end_tokens,invalid_index,id_label
def proceed_var_data(text_list,spo_list,tokenizer,MAX_LEN):ct = len(text_list)MAX_LEN = MAX_LENinput_ids = np.zeros((ct,MAX_LEN),dtype='int32')attention_mask = np.zeros((ct,MAX_LEN),dtype='int32')for k in range(ct):context_k = text_list[k].lower().replace(' ','')enc_context = tokenizer.encode(context_k,max_length=MAX_LEN,truncation=True) input_ids[k,:len(enc_context)] = enc_contextattention_mask[k,:len(enc_context)] = 1return input_ids,attention_mask
模型搭建
模型与上文给出的模型示意图结构一致,也是该思路下最基本的baseline模型,后面还尝试使用了不同的隐藏层和多种不同连接层,均没有得到理想的提升,具体会在文末介绍。
Trick:为了改善类别不平和的问题(正样本远少于负样本)对于sigmoid之后输出的概率值作n次方,思路与focal_loss类似但不用自己调参数。关于n的取值,以下是苏神给出的解释:

def extract_subject(inputs):"""根据subject_ids从output中取出subject的向量表征"""output, subject_ids = inputsstart = tf.gather(output,subject_ids[:,0],axis=1,batch_dims=0)end = tf.gather(output,subject_ids[:,1],axis=1,batch_dims=0)subject = tf.keras.layers.Concatenate(axis=2)([start, end])return subject[:,0]'''output.shape = (None,128,768)subjudec_ids.shape = (None,2)start.shape = (None,None,768)subject.shape = (None,None,1536)subject[:,0].shape = (None,1536)这一部分给出各个变量的shape应该一目了然'''def build_model_2(pretrained_path,config,MAX_LEN,p2id):ids = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)att = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)s_po_index = tf.keras.layers.Input((2,), dtype=tf.int32)config.output_hidden_states = Truebert_model = TFBertModel.from_pretrained(pretrained_path,config=config,from_pt=True)x, _, hidden_states = bert_model(ids,attention_mask=att)layer_1 = hidden_states[-1]start_logits = tf.keras.layers.Dense(1,activation = 'sigmoid')(layer_1)start_logits = tf.keras.layers.Lambda(lambda x: x**2)(start_logits)end_logits = tf.keras.layers.Dense(1,activation = 'sigmoid')(layer_1)end_logits = tf.keras.layers.Lambda(lambda x: x**2)(end_logits)subject_1 = extract_subject([layer_1,s_po_index])Normalization_1 = LayerNormalization(conditional=True)([layer_1, subject_1])op_out_put_start = tf.keras.layers.Dense(len(p2id),activation = 'sigmoid')(Normalization_1)op_out_put_start = tf.keras.layers.Lambda(lambda x: x**4)(op_out_put_start)op_out_put_end = tf.keras.layers.Dense(len(p2id),activation = 'sigmoid')(Normalization_1)op_out_put_end = tf.keras.layers.Lambda(lambda x: x**4)(op_out_put_end)model = tf.keras.models.Model(inputs=[ids,att,s_po_index], outputs=[start_logits,end_logits,op_out_put_start,op_out_put_end])model_2 = tf.keras.models.Model(inputs=[ids,att], outputs=[start_logits,end_logits])model_3 = tf.keras.models.Model(inputs=[ids,att,s_po_index], outputs=[op_out_put_start,op_out_put_end])return model,model_2,model_3
模型参数图
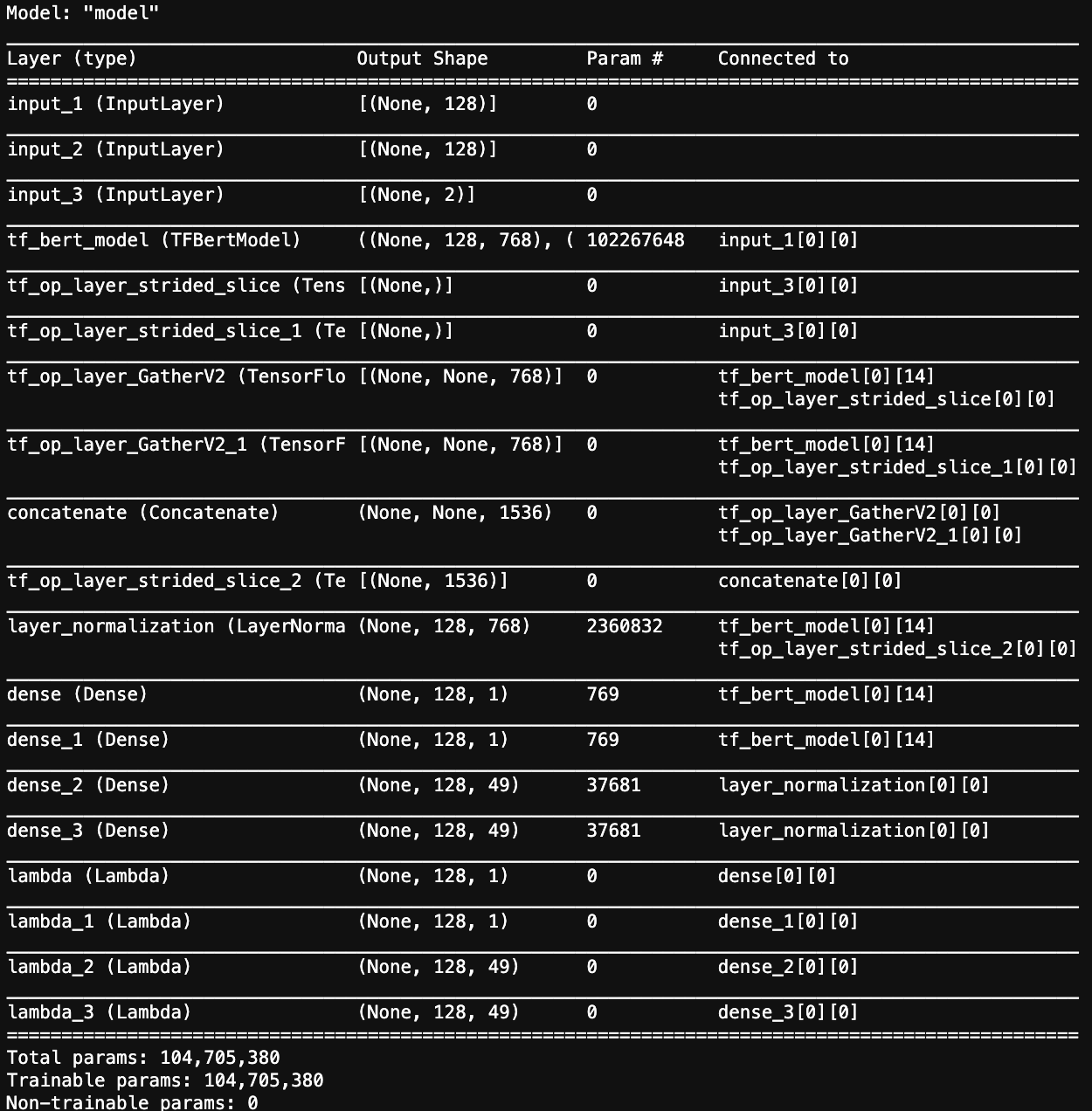
Conditional_LayerNormalization
这一部分直接拿的原码,把keras换成tf,其他没有作太大的改动,基本的思路是通过两个Dense层将extract_subject出来的向量进行矩阵变换,得到LayerNormalization的beta和gamma,而这个矩阵变化的参数是模型学出来的。
对于Conditional_LayerNormalization的介绍见上文链接。
class LayerNormalization(tf.keras.layers.Layer):"""(Conditional) Layer Normalizationhidden_*系列参数仅为有条件输入时(conditional=True)使用"""def __init__(self,center=True,scale=True,epsilon=None,conditional=False,hidden_units=None,hidden_activation='linear',hidden_initializer='glorot_uniform',**kwargs):super(LayerNormalization, self).__init__(**kwargs)self.center = centerself.scale = scaleself.conditional = conditionalself.hidden_units = hidden_unitsself.hidden_activation = activations.get(hidden_activation)self.hidden_initializer = initializers.get(hidden_initializer)self.epsilon = epsilon or 1e-12def compute_mask(self, inputs, mask=None):if self.conditional:masks = mask if mask is not None else []masks = [m[None] for m in masks if m is not None]if len(masks) == 0:return Noneelse:return K.all(K.concatenate(masks, axis=0), axis=0)else:return maskdef build(self, input_shape):super(LayerNormalization, self).build(input_shape)if self.conditional:shape = (input_shape[0][-1],)else:shape = (input_shape[-1],)if self.center:self.beta = self.add_weight(shape=shape, initializer='zeros', name='beta')if self.scale:self.gamma = self.add_weight(shape=shape, initializer='ones', name='gamma')if self.conditional:if self.hidden_units is not None:self.hidden_dense = tf.keras.layers.Dense(units=self.hidden_units,activation=self.hidden_activation,use_bias=False,kernel_initializer=self.hidden_initializer)if self.center:self.beta_dense = tf.keras.layers.Dense(units=shape[0], use_bias=False, kernel_initializer='zeros')if self.scale:self.gamma_dense = tf.keras.layers.Dense(units=shape[0], use_bias=False, kernel_initializer='zeros')def call(self, inputs):"""如果是条件Layer Norm,则默认以list为输入,第二个是condition"""if self.conditional:inputs, cond = inputsif self.hidden_units is not None:cond = self.hidden_dense(cond)for _ in range(K.ndim(inputs) - K.ndim(cond)):cond = K.expand_dims(cond, 1)if self.center:beta = self.beta_dense(cond) + self.betaif self.scale:gamma = self.gamma_dense(cond) + self.gammaelse:if self.center:beta = self.betaif self.scale:gamma = self.gammaoutputs = inputsif self.center:mean = K.mean(outputs, axis=-1, keepdims=True)outputs = outputs - meanif self.scale:variance = K.mean(K.square(outputs), axis=-1, keepdims=True)std = K.sqrt(variance + self.epsilon)outputs = outputs / stdoutputs = outputs * gammaif self.center:outputs = outputs + betareturn outputs
SPO的抽取,评估并保存模型
这一部分的方法是自己写的,也最有可能是因为抽取方法和评估方法与原文有不同之处,导致一直拿不到最好的结果。看个思路就好。
对于S和O的分数阈值的选择,这里S和O分别为0.5和0.4,这两个值还需要通过多次实验验证来调整。需要注意的是:因为模型输出时对sigmoid后的概率值作了2次和4次方,因此输出的值会偏小,设置较高的阈值会提高精确度,但难免会牺牲一定的召回率。
class Metrics(tf.keras.callbacks.Callback):def __init__(self,model_2,model_3,id2tag,va_spo_list,va_input_ids,va_attention_mask,tokenizer):super(Metrics, self).__init__()self.model_2 = model_2self.model_3 = model_3self.id2tag = id2tagself.va_input_ids = va_input_idsself.va_attention_mask = va_attention_maskself.va_spo_list = va_spo_listself.tokenizer = tokenizerdef on_train_begin(self, logs=None):self.val_f1s = []self.best_val_f1 = 0def get_same_element_index(self,ob_list):return [i for (i, v) in enumerate(ob_list) if v == 1]def evaluate_data(self):question=[]answer=[]Y1 = self.model_2.predict([self.va_input_ids,self.va_attention_mask])for i in range(len(Y1[0])):for z in self.va_spo_list[i]:question.append((z['subject'][0],z['subject'][-1],z['predicate'],z['object'][0],z['object'][-1]))x_ = [self.tokenizer.decode([t]) for t in self.va_input_ids[i]]x1 = np.array(Y1[0][i]>0.5,dtype='int32')x2 = np.array(Y1[1][i]>0.5,dtype='int32')union = x1 + x2index_list = self.get_same_element_index(list(union))start = 0S_list=[]while start+1 < len(index_list):S_list.append((index_list[start],index_list[start+1]+1))start += 2for os_s,os_e in S_list:S = ''.join(x_[os_s:os_e])Y2 = self.model_3.predict([[self.va_input_ids[i]],[self.va_attention_mask[i]],np.array([[os_s,os_e]])])for m in range(len(self.id2tag)):x3 = np.array(Y2[0][0][:,m]>0.4,dtype='int32')x4 = np.array(Y2[1][0][:,m]>0.4,dtype='int32')if sum(x3)>0 and sum(x4)>0:predict = self.id2tag[m]union = x3 + x4index_list = self.get_same_element_index(list(union))start = 0P_list=[]while start+1 < len(index_list):P_list.append((index_list[start],index_list[start+1]+1))start += 2for os_s,os_e in P_list:if os_e>=os_s:P = ''.join(x_[os_s:os_e])answer.append((S[0],S[-1],predict,P[0],P[-1]))Q = set(question)S = set(answer)f1 = 2*len(Q&S)/(len(Q)+len(S))return f1def on_epoch_end(self, epoch, logs=None):logs = logs or {}_val_f1 = self.evaluate_data()self.val_f1s.append(_val_f1)logs['val_f1'] = _val_f1if _val_f1 > self.best_val_f1:self.model.save_weights('./model_/02_f1={}_model.hdf5'.format(_val_f1))self.best_val_f1 = _val_f1print("best f1: {}".format(self.best_val_f1))else:print("val f1: {}, but not the best f1".format(_val_f1))return
模型训练
K.clear_session()
model,model_2,model_3 = build_model_2(pretrained_path,config,MAX_LEN,p2id)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-5)
model.compile(loss={'lambda': new_loss,'lambda_1': new_loss,'lambda_2': new_loss,'lambda_3': new_loss},optimizer=optimizer)
model.fit([input_ids,attention_mask,send_s_po],\[start_tokens,end_tokens,object_start_tokens,object_end_tokens], \epochs=20, batch_size=32,callbacks=[Metrics(model_2,model_3,id2tag,va_spo_list,va_input_ids,va_attention_mask,tokenizer)])
最终F1只到了0.772,相比原文中的0.822还有一定距离,主要原因可能在于
- 对于验证集上SPO的抽取写的有问题,抽取不完全且可能出错
- 在计算F1时,得到的SP结果直接通过decode得到,而不是原文中通过在原文中的index切片得到,会导致部分字符不匹配。
一些排坑
- 对于单个S,一定要把他所有的OP信息都标注在C*N的矩阵里,事实证明这必只抽取一组SPO关系效果有明显的提升(F1:0.65-0.77)
- 对于该模型的loss,特别是OP矩阵部分的loss一定要重新定义!如果直接使用loss=‘binary_crossentropy’ 会使得整体Loss极小,导致梯度过小,更新缓慢且训练不充分。
def new_loss(true,pred):true = tf.cast(true,tf.float32)loss = K.sum(K.binary_crossentropy(true, pred))return loss
- Conditional_LayerNorm层使用的Bert隐藏层需要和推理S的层一致,可能原因是模型在拟合S时,离S最近的最外层最能表达S在句中的语义,因此通过在该层上进行Conditional_LayerNorm再进一步推理PO,信息更完全。本人尝试了用最外的隐藏层和次外的隐藏层分别推理S和PO,发现效果不佳。
- Conditional_LayerNorm后不要接卷积!尝试了和阅读理解中的方法,通过对隐藏层进行卷积来推理实体,但这似乎与Conditional_LayerNorm无法匹配。
可能的优化方向
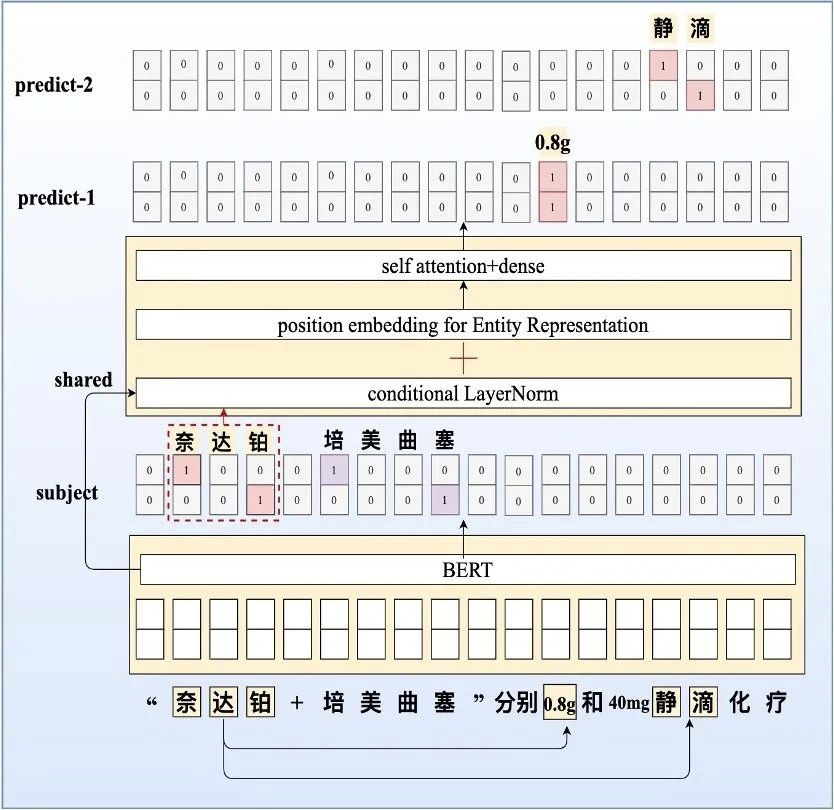
- 在Conditional_LayerNorm之后接position_embedding和self_attention如下图所示:
- 不随机选择S(subject),⽽是遍历所有不同主语的标注样本构建训练集。
- 多头标注代替指针标注,具体见论文
总结
先做个承诺上述三个优化方向和上文提到的F1计算和SPO抽取方法都会重新做一遍,因此总结等我优化完再来一次性说啦~
完整代码地址: https://github.com/zhengyanzhao1997/TF-NLP-model/blob/main/model/train/Three_relation_extract.py
参考文章:
- 苏剑林. (2020, Jan 03). 《用bert4keras做三元组抽取 》[Blog post]. Retrieved from https://kexue.fm/archives/7161
- 一人之力,刷爆三路榜单!信息抽取竞赛夺冠经验分享
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!