[论文学习]Manifold Mixup和PatchUp的代码重新实现(实现即插即用且速度更快)
Manifold Mixup和PatchUp是对mixup数据增强算法的两种改进方法,作者都来自Yoshua Bengio团队。这两种方法都是mixup方法在中间隐层的推广,因此原文开源代码都需要对网络各层的内部代码进行修改,使用起来并不方便,不能做到即插即用。我用pytorch中的钩子方法(hook)对这两个方法进行重新实现,这样就可以实现即插即用,方便的应用到各种网络结构中,而且我实现的代码比原开源代码速度还能提高60%左右。
Manifold Mixup 论文:https://arxiv.org/abs/1806.05236
Manifold Mixup 官方开源:https://github.com/vikasverma1077/manifold_mixup
PatchUp 论文:https://arxiv.org/abs/2006.07794
PatchUp 官方开源:https://github.com/chandar-lab/PatchUp
一、Manifold Mixup简介及代码
manifold mixup是对mixup的扩展,把输入数据(raw input data)混合扩展到对中间隐层输出混合。至于对中间隐层混合更有效的原因,作者的解释比较深奥。首先给出了现象级的解释,即这种混合带来了三个优势:平滑决策边界、拉大低置信空间(拉开各类别高置信空间的间距)、展平隐层输出的数值。至于这三点为什么有效,从作者说法看这应该是一种业界共识。然后作者又从数学上分析了第三点,即为什么manifold mixup可以实现展平中间隐层输出。
由于需要修改网络中间层的输出张量,如果不修改网络内部,也可以使用钩子操作(hook)在外部进行。核心部分代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as npdef to_one_hot(inp, num_classes):y_onehot = torch.FloatTensor(inp.size(0), num_classes).to(inp.device)y_onehot.zero_()y_onehot.scatter_(1, inp.unsqueeze(1).data, 1)return y_onehotbce_loss = nn.BCELoss()
softmax = nn.Softmax(dim=1)class ManifoldMixupModel(nn.Module):def __init__(self, model, num_classes = 10, alpha = 1):super().__init__()self.model = modelself.alpha = alphaself.lam = Noneself.num_classes = num_classes##选择需要操作的层,在ResNet中各block的层名为layer1,layer2...所以可以写成如下。其他网络请自行修改self. module_list = []for n,m in self.model.named_modules():#if 'conv' in n:if n[:-1]=='layer':self.module_list.append(m)def forward(self, x, target=None):if target==None:out = self.model(x)return outelse:if self.alpha <= 0:self.lam = 1else:self.lam = np.random.beta(self.alpha, self.alpha)k = np.random.randint(-1, len(self.module_list))self.indices = torch.randperm(target.size(0)).cuda()target_onehot = to_one_hot(target, self.num_classes)target_shuffled_onehot = target_onehot[self.indices]if k == -1:x = x * self.lam + x[self.indices] * (1 - self.lam)out = self.model(x)else:modifier_hook = self.module_list[k].register_forward_hook(self.hook_modify)out = self.model(x)modifier_hook.remove()target_reweighted = target_onehot* self.lam + target_shuffled_onehot * (1 - self.lam)loss = bce_loss(softmax(out), target_reweighted)return out, lossdef hook_modify(self, module, input, output):output = self.lam * output + (1 - self.lam) * output[self.indices]return output
调用代码如下:
net = ResNet18()
net = ManifoldMixupModel(net,num_classes=10, alpha=args.alpha)
def train(epoch):net.train()for batch_idx, (inputs, targets) in enumerate(trainloader):inputs, targets = inputs.cuda(), targets.cuda()outputs, loss = net(inputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()def test(epoch):net.eval()with torch.no_grad():for batch_idx, (inputs, targets) in enumerate(testloader):inputs, targets = inputs.cuda(), targets.cuda()outputs = net(inputs)
二、PatchUp简介及代码
PatchUp方法在manifold mixup基础上,又借鉴了cutMix在空间维度剪裁的思路,对中间隐层输出也进行剪裁,对两个不同样本的中间隐层剪裁块(patches)进行互换或插值,文中称互换法为硬patchUp,插值法为软patchUp。试验发现互换法在识别精度上更好,插值法在对抗攻击的鲁棒性上更好。这篇论文中没有对方法理论进行深度解释,仅仅给出了一个现象级对比,就是patchUp方法的隐层激活值比较高。
使用hook实现的核心代码PatchUpModel类如下,注意在该代码中强制k=-1就可以变成CutMix:
class PatchUpModel(nn.Module):def __init__(self, model, num_classes = 10, block_size=7, gamma=.9, patchup_type='hard',keep_prob=.9):super().__init__()self.patchup_type = patchup_typeself.block_size = block_sizeself.gamma = gammaself.gamma_adj = Noneself.kernel_size = (block_size, block_size)self.stride = (1, 1)self.padding = (block_size // 2, block_size // 2)self.computed_lam = Noneself.model = modelself.num_classes = num_classesself. module_list = []for n,m in self.model.named_modules():if n[:-1]=='layer':#if 'conv' in n:self.module_list.append(m)def adjust_gamma(self, x):return self.gamma * x.shape[-1] ** 2 / \(self.block_size ** 2 * (x.shape[-1] - self.block_size + 1) ** 2)def forward(self, x, target=None):if target==None:out = self.model(x)return outelse:self.lam = np.random.beta(2.0, 2.0)k = np.random.randint(-1, len(self.module_list))self.indices = torch.randperm(target.size(0)).cuda()self.target_onehot = to_one_hot(target, self.num_classes)self.target_shuffled_onehot = self.target_onehot[self.indices]if k == -1: #CutMixW,H = x.size(2),x.size(3)cut_rat = np.sqrt(1. - self.lam)cut_w = np.int(W * cut_rat)cut_h = np.int(H * cut_rat)cx = np.random.randint(W)cy = np.random.randint(H)bbx1 = np.clip(cx - cut_w // 2, 0, W)bby1 = np.clip(cy - cut_h // 2, 0, H)bbx2 = np.clip(cx + cut_w // 2, 0, W)bby2 = np.clip(cy + cut_h // 2, 0, H)x[:, :, bbx1:bbx2, bby1:bby2] = x[self.indices, :, bbx1:bbx2, bby1:bby2]lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (W * H))out = self.model(x)loss = bce_loss(softmax(out), self.target_onehot) * lam +\bce_loss(softmax(out), self.target_shuffled_onehot) * (1. - lam)else:modifier_hook = self.module_list[k].register_forward_hook(self.hook_modify)out = self.model(x)modifier_hook.remove()loss = 1.0 * bce_loss(softmax(out), self.target_a) * self.total_unchanged_portion + \bce_loss(softmax(out), self.target_b) * (1. - self.total_unchanged_portion) + \1.0 * bce_loss(softmax(out), self.target_reweighted)return out, lossdef hook_modify(self, module, input, output):self.gamma_adj = self.adjust_gamma(output)p = torch.ones_like(output[0]) * self.gamma_adjm_i_j = torch.bernoulli(p)mask_shape = len(m_i_j.shape)m_i_j = m_i_j.expand(output.size(0), m_i_j.size(0), m_i_j.size(1), m_i_j.size(2))holes = F.max_pool2d(m_i_j, self.kernel_size, self.stride, self.padding)mask = 1 - holesunchanged = mask * outputif mask_shape == 1:total_feats = output.size(1)else:total_feats = output.size(1) * (output.size(2) ** 2)total_changed_pixels = holes[0].sum()total_changed_portion = total_changed_pixels / total_featsself.total_unchanged_portion = (total_feats - total_changed_pixels) / total_featsif self.patchup_type == 'hard':self.target_reweighted = self.total_unchanged_portion * self.target_onehot +\total_changed_portion * self.target_shuffled_onehotpatches = holes * output[self.indices]self.target_b = self.target_onehot[self.indices]elif self.patchup_type == 'soft':self.target_reweighted = self.total_unchanged_portion * self.target_onehot +\self.lam * total_changed_portion * self.target_onehot +\(1 - self.lam) * total_changed_portion * self.target_shuffled_onehotpatches = holes * outputpatches = patches * self.lam + patches[self.indices] * (1 - self.lam)self.target_b = self.lam * self.target_onehot + (1 - self.lam) * self.target_shuffled_onehotelse:raise ValueError("patchup_type must be \'hard\' or \'soft\'.")output = unchanged + patchesself.target_a = self.target_onehotreturn output
调用过程同上,其中模型包装语句如下:
net = ResNet18()
net = PatchUpModel(net,num_classes=10, block_size=7, gamma=.9, patchup_type='hard')
三、在CIFAR-10上试验结果
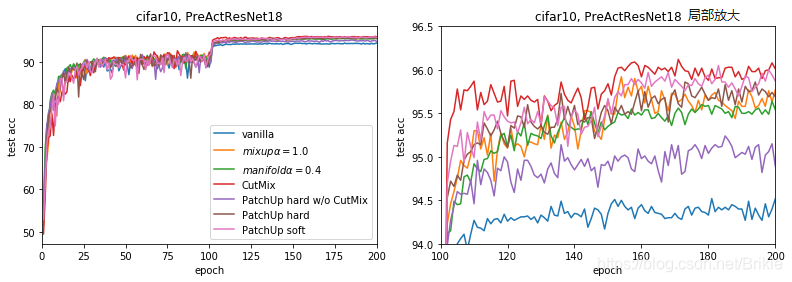
试验主要目的是验证代码可运行。仅靠在一个简单数据集上一次试验非常不充分,不能公平对比效果,所以不作为各方法的性能对比。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!