【Python有趣打卡】微博APP榜单爬虫,尽知天下事(一)
【Python有趣打卡】微博APP爬虫,尽知天下事
【Python有趣打卡】微博APP榜单爬虫,尽知天下事

今天要跟着罗罗攀(公众号:luoluopan1)学习Python有趣|微博APP爬虫,尽知天下事,每周都跟着罗老师学有趣的python案例,继续安利他这周的例子。
今天爬虫要用到一个小工具
!!! Fiddler!!!
官网:https://www.telerik.com/fiddler
下载后直接安装即可
配置fiddler:Tools→Option→如图→重启软件!!!!记得重启
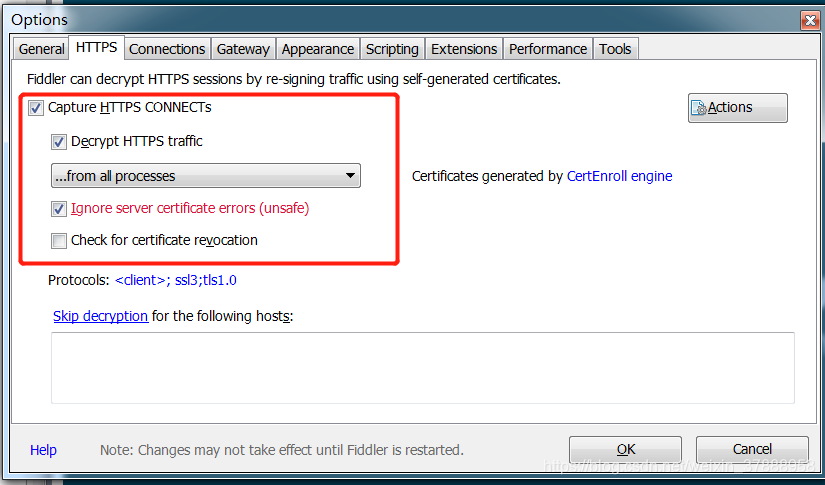
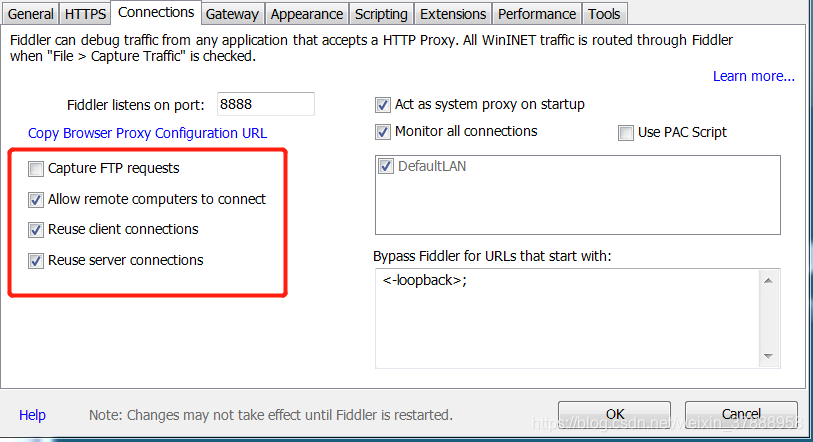
重启了吗??记得哦
配置手机:
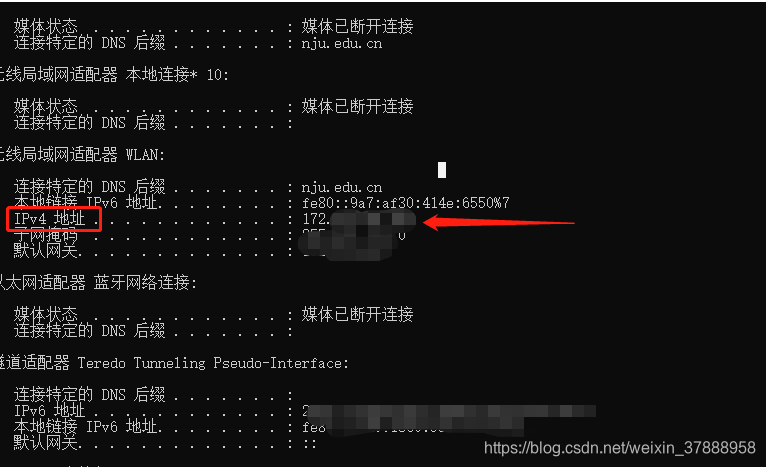
第一步:为了让Fiddler截取手机的包,需要让手机和电脑在同一个ip下,在电脑端的cmd中输入:ipconfig,获取电脑ip地址。
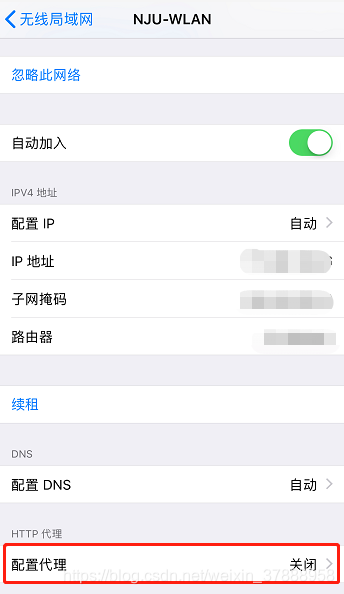
第二步:打开手机共同连接的无线网络,手动配置代理,电脑的iP地址配置好
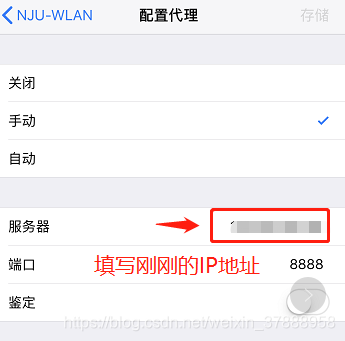
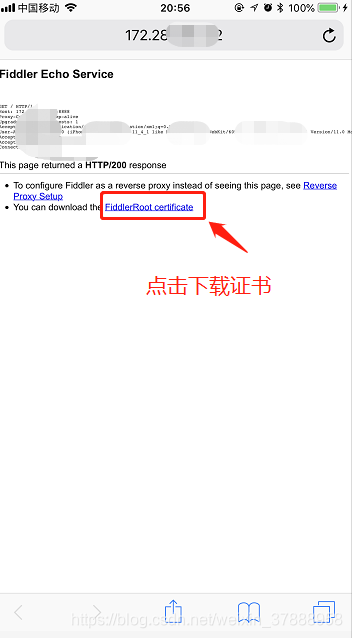
第三步:用手机浏览器打开网址:http://192.168.0.144 :8888,写你自己的IP地址,然后下载证书。
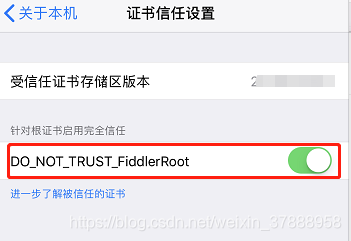
IPhone手机还需要在关于本机中,设置中信任证书。
这样就搞定啦~可以开始抓包啦
fiddler用法
先来看下fiddler工具怎么用吧~
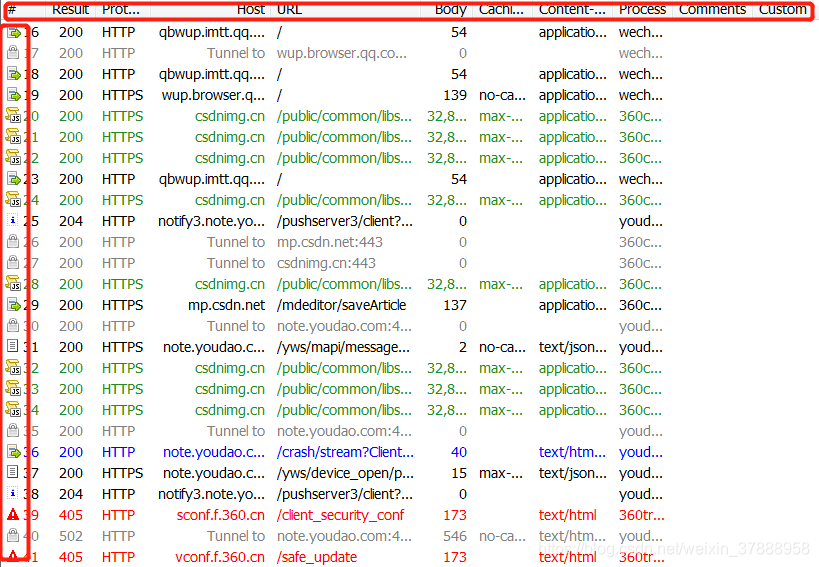
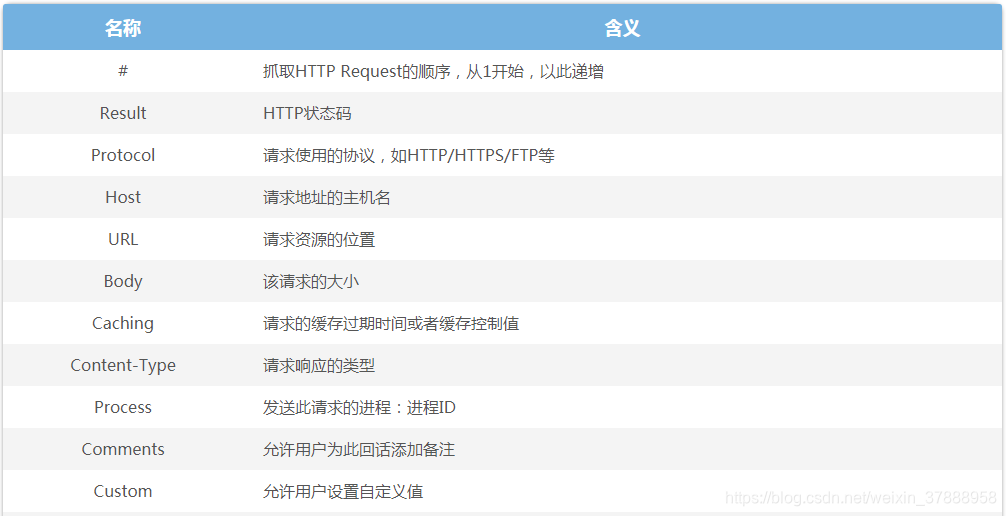


Statistics:关于HTTP请求的性能以及数据分析
Inspectors:用于查看会话的内容,上半部分是请求的内容,下半部分是响应的内容。
请求区中的"raw"(原始数据)是最常用也是最详细的,一般我们要抓包模拟都是从这里复制数据,然后修改的,其它的项是分析请求中的某一种数据;
Fiters:过滤请求用的,由于左边的窗口不断的更新,你刷新一下浏览器,一大片不知道哪来请求,它还一直刷新。这个时候通过过滤规则来过滤掉那些不想看到的请求。
设置过滤
手机上完成配置后,fiddler抓到的除了手机还有PC端的,如果PC也在打开网址的话,那会有很多干扰信息,因此我们要设置过滤功能。
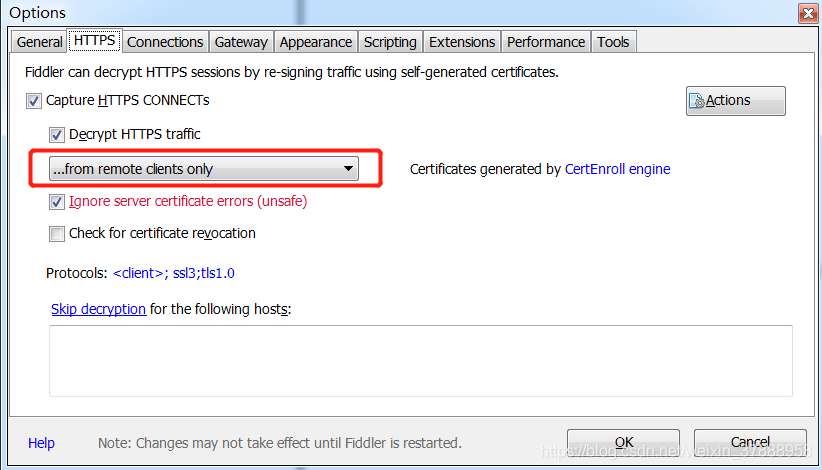
打开fiddler>Tools>Fiddler Options>HTTPS>…from remote clients only,勾选这个选项就可以了
…from all processes :抓所有的请求
…from browsers only :只抓浏览器的请求
…from non-browsers only :只抓非浏览器的请求
…from remote clients only:只抓远程客户端请求
(注意:如果手机设置代理后,测玩之后记得恢复原样,要不然手机无法正常上网。)
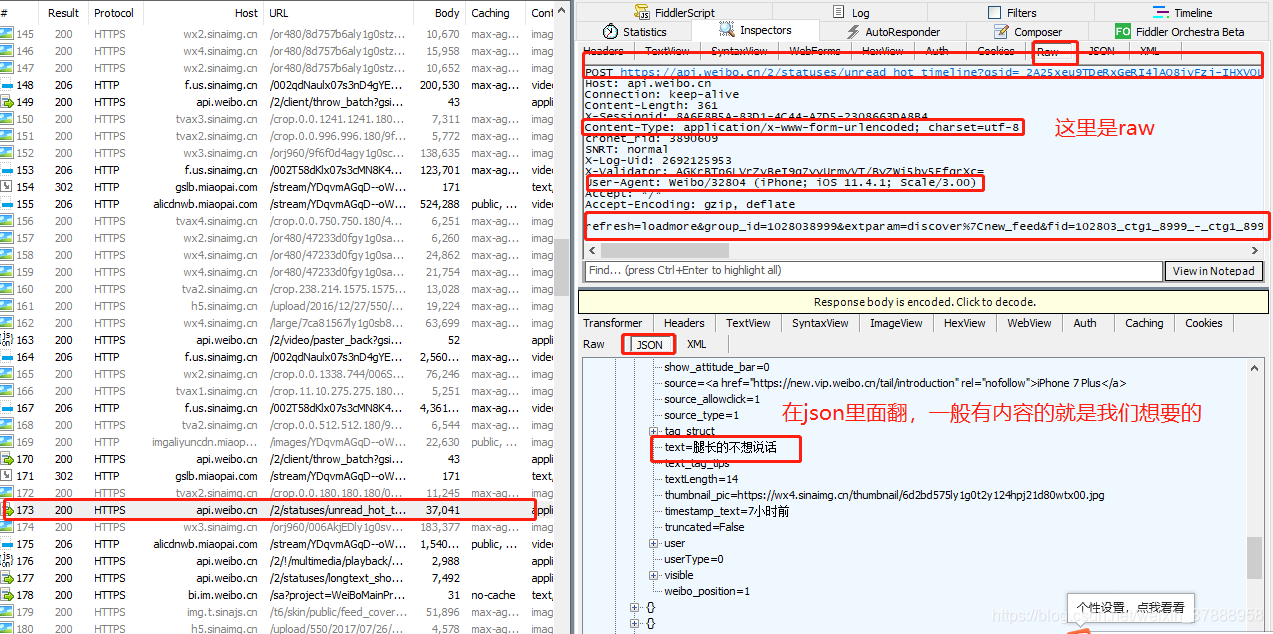
多找几个,发现“refresh”那段语句的规律
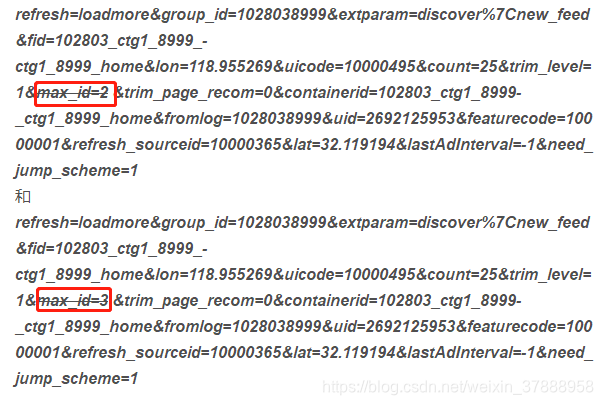
这里是有规律的,这里就是可以不停的往下滑的原因!
找到我们要的一些字段后,我们开始写代码吧!
测试:
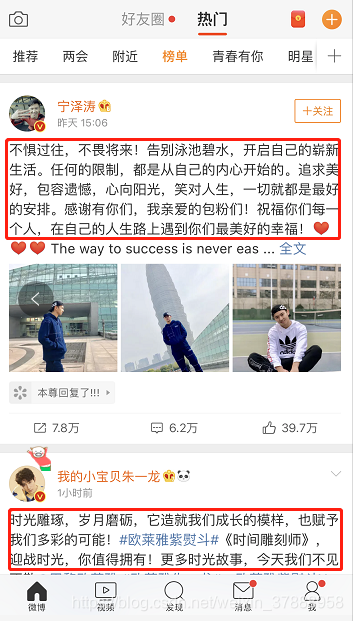
爬取的微博的热门榜单(果真前几个就有我居居老师,(▽))
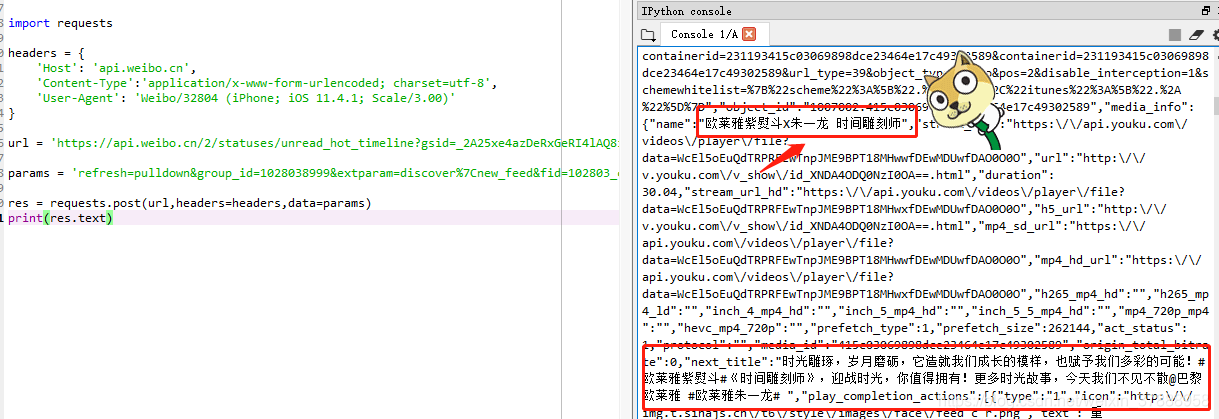
import requestsheaders = {'Host': 'api.weibo.cn','Content-Type':'application/x-www-form-urlencoded; charset=utf-8','User-Agent': ''
}url = 'https://api.weibo.cn/2/statuses/unread_hot_timeline?gsid=_2A25xe4azDeRxGeRI4lAQ8ivFzj-IHXVQEJ17rDV6PUJbj9AKLXPikWpNUpLIXjE6dkUbQEoplTVGDUCxFq-S35cC&sensors_mark=1&wm=3333_2001&i=697de05&sensors_is_first_day=false&from=1092093010&b=0&c=iphone&networktype=wifi&skin=default&v_p=71&s=8320ffff&v_f=1&sensors_device_id=91929DA9-0D9A-4797-9C3D-142DFA76645E&lang=zh_CN&sflag=1&ua=iPhone9,2__weibo__9.2.0__iphone__os11.4.1&ft=11&aid=01Ai8m72R0Bt8X3v0E7b5ZAzGeH5PjXOXLOEu3OPjR1LJ_YPA'params = 'refresh=pulldown&group_id=1028038999&extparam=discover%7Cnew_feed&fid=102803_ctg1_8999_-_ctg1_8999_home&lon=118.955266&uicode=10000495&count=25&trim_level=1&trim_page_recom=0&containerid=102803_ctg1_8999_-_ctg1_8999_home&fromlog=1028038999&uid=2692125953&featurecode=10000001&refresh_sourceid=10000365&preAdInterval=-1&lat=32.119211&since_id=0&need_jump_scheme=1'res = requests.post(url,headers=headers,data=params)
print(res.text)
测试成功,表示已经爬取到榜单啦~
由于我们需要的内容都在statuses里,由大到小,先选取这块内容
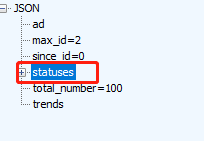
同时,我需要找我所要的字段,一般我都会把它写进txt里,然后用https://www.json.cn/ 打开,方便我去查看我要的数据所在位置。
import json
json_data = json.loads(res.text)
statuses = json_data['statuses'][0]
data = json.dumps(statuses,indent=2,ensure_ascii=False) #ensure_ascii=False :防止将文字转成unicoe
print(data)
with open(r'C:\Users\小笼包\Desktop\data.txt','w',encoding='utf-8') as f:f.write(data)
把txt的内容复制到网页中,不要的就—掉就会看起来很简洁,如图所示:
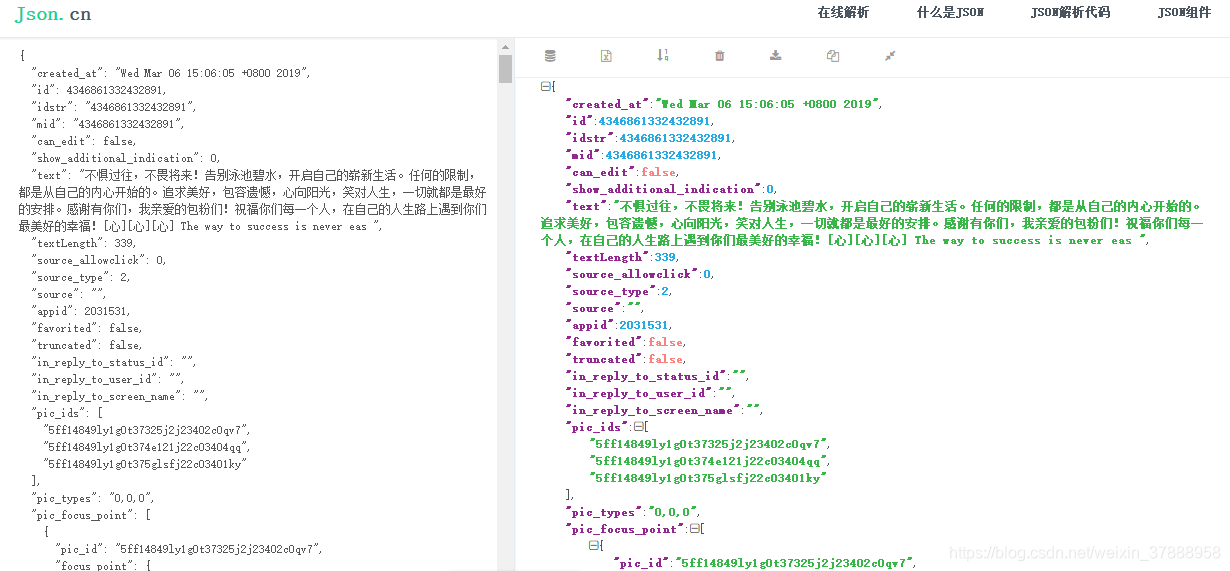
需要的字段有
| 字段 | 位置 |
|---|---|
| 微博用户 |  |
| 地理位置 | 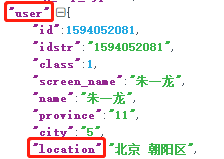 |
| 性别 |  |
| 转发 |  |
| 内容 |  |
就不一一列出啦,你想爬什么只要找到字段就可以了
for statuse in statuses:user = statuse['user']['name']location = statuse['user']['location']gender = statuse['user']['gender']followers = statuse['user']['followers_count']text = statuse['text']created_time = statuse['created_at']comments = statuse['comments_count']good = statuse['attitudes_count']print(user,location,gender,followers,text,created_time,comments,good)

ok!字段也搞定啦,只要把它写进csv里就可以啦,下面是完成版代码!
import requests
import json
import csv
import timefp = open('weibo.csv','w',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(['user','location','gender','followers','text','created_time','comments','good'])url = 'https://api.weibo.cn/2/statuses/。。。。。。。。'headers = {'Host': 'api.weibo.cn','Content-Type':'application/x-www-form-urlencoded; charset=utf-8','User-Agent': 'Weibo/29278 (iPhone; iOS 11.4.1; Scale/2.00)'
}params = ['refresh=loadmore&group_id=1028038999&extparam=discover%7Cnew_feed&fid=102803_ctg1_8999_-_ctg1_8999_home&uicode=10000495&count=25&trim_level=1&max_id={}&trim_page_recom=0&containerid=102803_ctg1_8999_-_ctg1_8999_home&fromlog=1028038999&uid=5288491078&luicode=10000001&featurecode=10000001&refresh_sourceid=10000365&lastAdInterval=-1&lfid=10000001&need_jump_scheme=1'.format(str(i)) for i in range(1,16)]for param in params:res = requests.post(url,headers=headers,data=param)json_data = json.loads(res.text)statuses = json_data['statuses']for statuse in statuses:user = statuse['user']['name']location = statuse['user']['location']gender = statuse['user']['gender']followers = statuse['user']['followers_count']text = statuse['text']created_time = statuse['created_at']comments = statuse['comments_count']good = statuse['attitudes_count']print(user,location,gender,followers,text,created_time,comments,good)writer.writerow([user,location,gender,followers,text,created_time,comments,good])time.sleep(2)
数据弄下来了,下次我们在学数据分析~~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!