Python实现词法分析(结合fastapi框架)
词法分析
一、实验目的
通过编写一个具体的词法分析程序,加深对词法分析原理的理解。掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数(整数和浮点数)、运算符(单符号运算符和组合运算符)、分隔符五大类。依次输出各个单词的内部编码及单词符号自身值。要能处理注释(/* …*/)。
二、实验预习提示
1、词法分析器的功能和输出格式
词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符号常常表示成以下的二元式(单词种别码,单词符号的属性值)。
2、单词的BNF表示
<标识符>----> <字母><字母数字串>
<无符号整数>----> <数字><数字串>
<加法运算符>----> +
<减法运算符>----> - 等等(需要大家自行找出各类单词的定义,可以是正规文法、有穷自动机或者正规式,最后都要转换成最小DFA再使用)
3、模块结构(见课本第四章)(适当修改)
三、实验过程和指导
(一)准备:
1.阅读课本有关章节,明确语言的语法,写出基本保留字、标识符、常数(整数,浮点数)、运算符、分隔符。
2.初步编制好程序。
3.准备好多组测试数据。
(二)上机:
(三)程序要求:
1.要求用可视化编程工具编写;要求可视化有界面(即一般windows下应用程序界面)。源程序可以放在文件里,打开可编辑;识别出的单词符号,可以输出到显示器上,并以文件形式存放。可以有“读入源程序”,“词法分析”等类似这样的功能按钮。
2.输入为c语言源代码。
程序输入/输出示例:
如源程序为C语言。输入如下一段:
main() /lex/
{
int a1,b2;
a1=10;
b2=a1+20.35;
/* com begin
Com end
/
123+++;
a1+=110;
1.2.3
}
要求输出如下(也可以以文件形式输出)。
(2,”main”)
(5,”(“)
(5,”)“)
(5,”{“}
(1,”int”)
(2,”a1”)
(5,”,”)
(2,”b2”)
(5,”;”)
(2,”a1”)
(4,”=”)
(3,”10”)
(5,”;”)
(2,”b2”)
(4,”=”)
(2,”a1”)
(4,”+”)
(3,”20.35”)
(5,”;”)
……
(5,”}“) 注:为右大括号
要求(可根据实际情况加以扩充和修改):
识别保留字:if、int、for、while、do、return、break、continue等等;单词种别码为1。
其他的都识别为标识符;单词种别码为2。
常数为无符号数;单词种别码为3。
运算符包括:+、-、、/、=、>、<等;可以考虑更复杂情况>=、<=、!= ;单词种别码为4。
分隔符包括: “,”“;”“(”“)”“{”“}”等; 单词种别码为5。
(四)程序思路(仅供参考):
0.定义部分:定义常量、变量、数据结构。
1.初始化:从文件将源程序输入到字符缓冲区中。
2.取单词前:去掉多余空白。调用过程GETNB();
3.提取字符组成单词,利用课本介绍的转换图构,造单词扫描过程SCAN(),可根据实际情况加以修改。
4.判断单词的种别码,调用过程LOOKUP();
5.显示(导出)结果。
四、实验原理
本实验通过有限状态机实现对用户输入的程序代码进行词法分析并打印出来。
当程序获取用户输入后,首先将输入的代码程序进行单词分离,对每一个单词依次加入到有限状态机中进行分析。
状态机工作流程如下图所示:
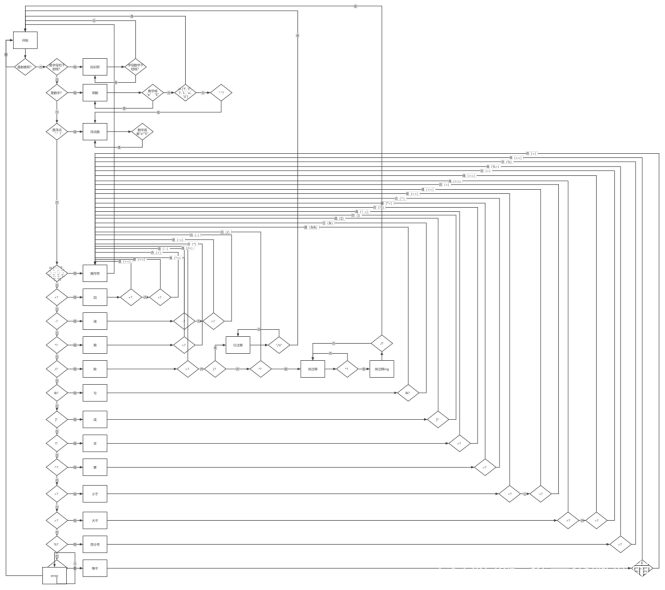
程序界面(效果图)
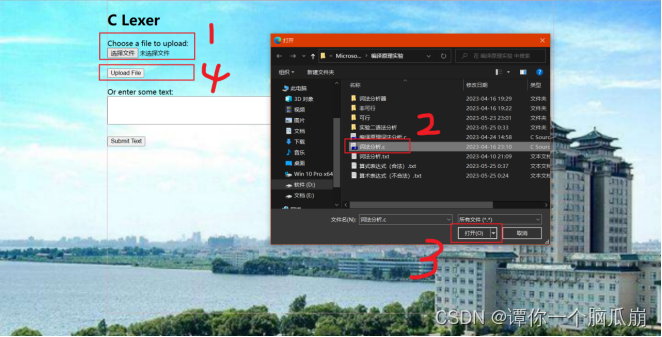
运行代码后访问网址:http://127.0.0.1:8000
按如下图中步骤,可对文件中的C语言程序进行词法分析
如下图为词法分析结果:
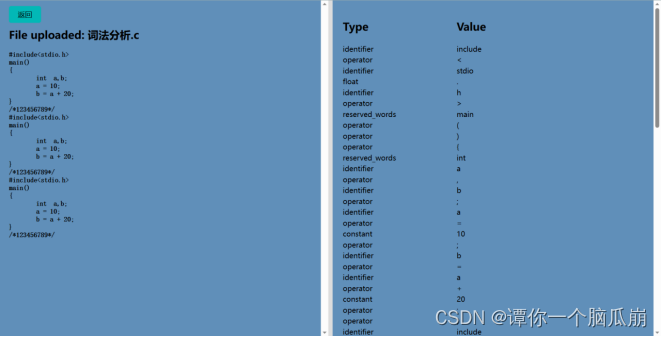
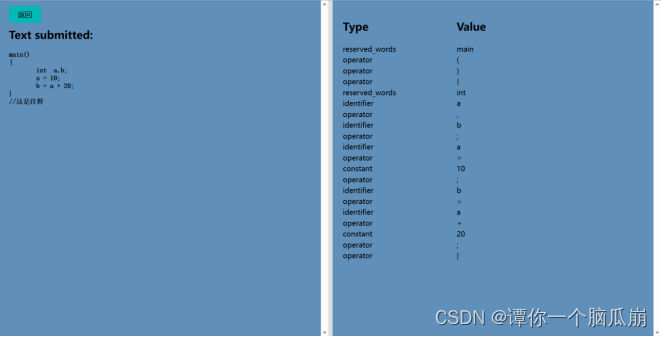
或者如下图选择自己手动需要进行词法分析的程序

分析结果如下:
程序代码
main.py
from fastapi import FastAPI, Request, Form, File, UploadFile
from fastapi.templating import Jinja2Templates
import uvicorn
app = FastAPI()
templates = Jinja2Templates(directory="templates")
from fastapi import Responsereserved_words = ['main','if','int','for','while','do','return','break','continue','auto','break','case','char','const','continue','default','do','double','else','enum','extern','float','for','goto','if','int','long','register','return','short','signed','sizeof','static','struct','switch','typedef','union','unsigned','void','volatile','while'
]# C语言词法分析器状态机
class LexerStateMachine:def __init__(self):self.current_state = 'start'self.current_token = ''self.tokens = []# 状态转移函数def transition(self, char):#首先在start状态时遇到各种字符应该怎么跳转if self.current_state == 'start':if char in ['#',' ','\t', '\n', '\r']:pass # 空格、制表符、换行符和回车符不是单词的一部分,忽略它们elif char.isalpha() or char == '_':self.current_state = 'identifier'self.current_token += charelif char.isdigit():self.current_state = 'constant'self.current_token += char#小数浮点数elif char in ['.']:self.current_state = 'float'self.current_token += charelif char in ['~', '?', ':', ',', ';', '.', '(', ')', '[', ']', '{', '}']:self.tokens.append(('operator', char))self.current_state = 'start'self.current_token = ''#此后为对运算符的详细状态转换elif char == '+':self.current_state = '加'self.current_token += charelif char == '-':self.current_state = '减'self.current_token += charelif char == '*':self.current_state = '乘'self.current_token += charelif char == '/':self.current_state = '除'self.current_token += charelif char == '&':self.current_state = '&'self.current_token += charelif char == '|':self.current_state = '或'self.current_token += charelif char == '!':self.current_state = '非'self.current_token += charelif char == '^':self.current_state = '幂'self.current_token += charelif char == '<':self.current_state = '小于'self.current_token += charelif char == '>':self.current_state = '大于'self.current_token += charelif char == '%':self.current_state = '百分号'self.current_token += charelif char == '=':self.current_state = '等于'self.current_token += char#以上是对运算符的详细else:self.tokens.append(('error', char))self.current_state = 'start'self.current_token = ''#以下是对运算符的二次判断elif self.current_state == '加':if char =='+':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''elif char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''# elif char.isdigit():# self.current_token += char# self.current_state = 'constant'else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '减':if char =='-':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''elif char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''# elif char.isdigit():# self.current_token += char# self.current_state = 'constant'else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '乘':if char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '除':if char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''elif char == '/':self.current_state = 'line_comment'elif char == '*':self.current_state = 'block_comment'else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '与':if char =='&':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '或':if char =='|':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '幂':if char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '非':if char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '百分号':if char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '小于':if char =='<':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''elif char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '大于':if char =='>':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''elif char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符elif self.current_state == '等于':if char =='=':self.current_token += charself.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('operator', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符#以上是对运算符的二次判断#当处于inentifier状态时转换elif self.current_state == 'identifier':if char.isalnum() or char == '_':self.current_token += charelse:if self.current_token in reserved_words:self.tokens.append(('reserved_words', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符else:self.tokens.append(('identifier', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符#当处于constant状态时转换elif self.current_state == 'constant':if char.isdigit() or char in ['e', 'E']:self.current_token += charelif char in ['.']:self.current_state = 'float'self.current_token += charelif char in ['f', 'F', 'l', 'L', 'u', 'U']:self.current_token += charself.tokens.append(('constant', self.current_token))self.current_state = 'start'self.current_token = ''else:self.tokens.append(('constant', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符#浮点数elif self.current_state == 'float':if char.isdigit() or char in ['e', 'E', '+', '-']:self.current_token += char# elif char in ['.']:# self.current_state = 'error'# self.current_token += charelse:self.tokens.append(('float', self.current_token))self.current_state = 'start'self.current_token = ''#处理一个空格防止前后连一起self.transition(' ')self.transition(char) # 处理当前字符# #error# elif self.current_state == 'error':# if char in [' ','\t', '\n', '\r']:# self.tokens.append(('error', self.current_token))# self.current_state = 'start'# self.current_token = ''# else:# self.current_state = 'error'# self.current_token += charelif self.current_state == 'line_comment':if char == '\n':self.current_state = 'start'else:self.current_state = 'line_comment'#块注释elif self.current_state == 'block_comment':if char == '*':self.current_state = 'block_comment_ending'else:self.current_state = 'block_comment'#elif self.current_state == 'block_comment_ending':if char == '/':self.current_state = 'start'self.current_token = ''else:self.current_state = 'block_comment'self.transition(char) # 处理当前字符else:self.tokens.append(('error', self.current_token))self.current_state = 'start'self.current_token = ''self.transition(char) # 处理当前字符# 分离单词def tokenize(self, code):for char in code:# print(char)self.transition(char)return self.tokens@app.get("/")
def index(request: Request):return templates.TemplateResponse("index.html", {"request": request})@app.post("/lex")
async def analyze(request: Request,file: UploadFile = File(None)):# 文件类型数据contents = await file.read()text = contents.decode("utf-8")+" "lexer = LexerStateMachine()tokens = lexer.tokenize(text)# print(tokens)return templates.TemplateResponse("lex.html", {"request": request, "tokens": tokens,"text1":text,"file":file})@app.post("/lex2")
async def analyze(request: Request,text: str = Form(None)):# 文本类型数据text1 = text+" "# print(type(text1))# print(text1)lexer = LexerStateMachine()tokens = lexer.tokenize(text1)# print(tokens)return templates.TemplateResponse("lex.html", {"request": request, "tokens": tokens,"text":text})if __name__ == '__main__':uvicorn.run(app)"""
完结!可实现状态机并在html显示
""""""
加等,乘等,浮点数1.2.3应该为1.2和.3
"""
index.html
DOCTYPE html>
<html><head><title>C Lexertitle>head><style>body{width: 1000px;height:700px;border: rgb(216, 168, 184) 1px solid;margin: auto;background-image: url(https://gss0.baidu.com/-4o3dSag_xI4khGko9WTAnF6hhy/zhidao/wh%3D600%2C800/sign=c9b07a5777899e5178db32127297f50b/0823dd54564e92582d432f449082d158ccbf4e21.jpg);background-size: cover;}textarea {resize: both;}style><body><h1>C Lexerh1><form action="/lex" method="post" enctype="multipart/form-data"><label for="file">Choose a file to upload:label><br><input type="file" id="file" name="file"><br><br><button type="submit">Upload Filebutton>form><br><form action="/lex2" method="post"><label for="text">Or enter some text:label><br><textarea id="text" name="text" rows="4" cols="50">textarea><br><br><button type="submit">Submit Textbutton>form>body>
html>lex.html
DOCTYPE html>
<html>
<head><title>C词法分析器title><style>body {margin: 0;padding: 0;height: 100vh;display: flex;flex-direction: row;}.left {flex: 1;min-width: 300px;max-width: 50%;overflow-y: scroll;background-color: #608FB9;padding: 20px;}.right {flex: 1;overflow-y: scroll;background-color: #608FB9;padding: 20px;}.splitter {position: relative;width: 10px;cursor: col-resize;background-color: #ddd;z-index: 1;}thead th {position: sticky;top: 0;background-color: #608FB9;}table {width: auto;min-width: 400px;table-layout: fixed;}td, th {text-align: left;}/* 定义按钮样式 */.my-button {background-color: #02B8B6; /* 设置背景颜色 */color: black; /* 设置文本颜色 */font-family: Arial, sans-serif; /* 设置字体 */padding: 10px 20px; /* 设置填充 */border-radius: 5px; /* 设置圆角 */text-decoration: none; /* 移除下划线 */}/* 鼠标悬停时更改样式 */.my-button:hover {background-color: #0F8FAA; /* 更改背景颜色 */color: white; /* 更改文本颜色 */}style>
head>
<body><div class="left"><a href="/" class="my-button">返回a><tr>{% if file %}<h2>File uploaded: {{ file.filename }}h2><h3><pre>{{ text1 }}pre>h3>{% endif %}{% if text %}<h2>Text submitted:h2><h3><pre>{{ text }}pre>h3>{% endif %}tr>table>div><div class="splitter">div><div class="right"><table><thead><tr><th><h2>Typeh2>th><th><h2>Valueh2>th>tr>thead><tbody>{% for token in tokens %}<tr><td>{{ token[0] }}td><td>{{ token[1] }}td>tr>{% endfor %}tbody>table>div>body>
<script >
const splitter = document.querySelector('.splitter');
const leftPanel = document.querySelector('.left');
const rightPanel = document.querySelector('.right');let isResizing = false;splitter.addEventListener('mousedown', function (e) {isResizing = true;
});document.addEventListener('mousemove', function (e) {if (!isResizing) {return;}const x = e.pageX;const leftWidth = x - leftPanel.getBoundingClientRect().left;const rightWidth = rightPanel.getBoundingClientRect().right - x;leftPanel.style.flex = leftWidth;rightPanel.style.flex = rightWidth;
});document.addEventListener('mouseup', function (e) {isResizing = false;
});
script>
html>
实验结果分析及心得体会
通过编写词法分析程序,我深入理解了词法分析的原理,并掌握了将程序设计语言源程序进行扫描的过程,将其分解为各类单词的词法分析方法。
在实验中,我首先编制了一个获取用户输入的前端,用于获取用户想要进行词法分析的程序代码,然然后对程序代码进行词法分析并打印出来,根据实验要求,我将单词分为基本保留字、标识符、常数、浮点数、运算符(单符号运算符和组合运算符)以及注释(行注释和块注释)。
在编写词法分析程序的过程中,我学会了使用适当的有限状态自动机来匹配和识别不同类型的单词。通过定义合适的模式和规则,我能够准确地提取出源程序中的各个单词。
在实验过程中,我还遇到了处理注释(// 和/* … */)的情况。为了正确处理注释,我设计了相应的算法,在扫描源程序时跳过注释部分,并确保注释不会干扰到单词的识别和分析过程。
通过完成这个实验,我对词法分析的概念和技术有了更深入的了解。我认识到词法分析是程序设计语言编译过程中的重要一步,它为后续的语法分析和语义分析提供了基础数据。同时,我也体会到了编写一个高效而准确的词法分析程序的挑战,需要仔细设计和测试各种正则表达式和模式,以确保对源程序的扫描和分析能够正确无误。
通过这个实验,我不仅加深了对词法分析原理的理解,还掌握了在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。这将对我今后的编译器设计和程序分析任务有很大的帮助。
原创出品,如有不足,欢迎指正
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!