机器学习中的数据集建设
以下文章摘录自:
《机器学习观止——核心原理与实践》
京东: https://item.jd.com/13166960.html
当当:http://product.dangdang.com/29218274.html
(由于博客系统问题,部分公式、图片和格式有可能存在显示问题,请参阅原书了解详情)
————————————————
版权声明:本文为CSDN博主「林学森」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuesen_lin/
1.1 数据集建设的核心目标
因为业界还没有严格的数据集建设标准,所以我们主要是根据机器学习项目的经验来总结出它的核心目标,简单来讲在于:
提升训练数据集的质量和数量
其中有如下几个关注点:
l 数据量(Scale)
l 数据分布多样性(Diversity)
l 数据准确性(Accuracy)
做一个可能不太恰当的比喻,上述3个关注点或许和当今时代的主流择偶标准有类似之处——即高(数据量大)、富(数据分布广)、帅(数据准确,质量高)。
(1) 数据量
用于机器学习项目的数据量究竟应该是多大?很遗憾到目前为止还没有人可以给出准确的理论依据和解答。不过从实践角度来看,在保证数据质量的情况下,数据量大往往可以取得更好的业务效果。
下面我们通过几个例子来让大家对此有一个感性的认识。
l 深度学习理论其实在很多年前就已经出现了,但在当时却没有掀起太大的波澜。而在沉寂了若干年后,它突然于2012年左右火爆起来,其中的原因是什么呢?不难发现,除了计算能力的大幅提升外,另一个重要原因就在于数据集的建设达到了“质变”。特别是ImageNet提供的千万级别的高质量数据集,让学术界的算法模型(特别是以卷积神经网络为代表的深度学习模型)“打通了任督二脉”,从而爆发出了无穷无尽的力量
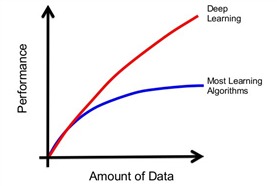
图 ‑ 算法与数据量的关系
l 2018年上半年的时候,Facebook利用Instagram上的几亿级别的用户标注图片,帮助其图像识别等算法精度达到了历史新高度。这就足以说明即便是达到亿+级别的超海量数据集,训练数据量的增加对于算法精度的提升仍然有帮助
另外,不同类型的算法对于数据量的需求显然也有差异。为此业界著名的scikit-learn还特意给开发人员提供了一份“小抄”(cheat sheet),参考下图:
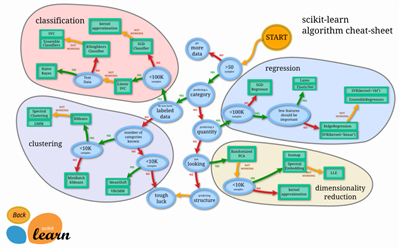
图 ‑ 数据量和算法类型的匹配关系
(2) 数据分布(多样性)
我们针对训练数据集的采样,理论上要能代表现实中所有数据的分布,这样可以尽可能保证训练出来的模型的泛化能力。举个简单的例子,我们需要训练一个识别人类的模型。那么以下两个数据集哪个更符合要求呢?
数据集1:只提供了黑人的图片,数据量达到100万
数据集2:数据量同样是100万,但提供了黑人、白人、黄种人等各类人种的图片资源
显然我们更倾向于后者,因为它的分布更广,更能代表“人类”这个类别的通用特征。反之如果采用数据集1的话,那么训练出来的算法模型就有可能会错误地“学习”到“黑”这个特征,从而导致过拟合问题。
在数据分布问题上,我们主要关注:
l 数据的独立同分布
l 数据的多样性
等等
(3) 数据准确性
数据的准确性包括但不限于:
l 数据标签类型的合理性
l 数据标注信息的准确性
l 数据类别的均衡性
l 数据噪声问题
等等
接下来的几个小节我们围绕上述这些关注点做展开讨论。
1.2 数据采集和标注
1.2.1 数据从哪来
毫不夸张地说,在采用同一种算法的情况下,物体识别数据集的建设情况将直接影响图像物体识别结果的好坏。虽然业界和学术界已经有一些现成的图片数据库(ImageNet等), 但遗憾的是在实际工程项目中往往还是“杯水车薪”。因而如何建设属于自己的定制数据集就显得尤为重要了。
我们将在本小节介绍几种建设数据集的方法,供大家参考选择。
1.2.1.1 借助于专业的数据机构
俗语说,“术业有专攻”,而且“有需求就有市场”——机器学习领域的繁荣同时也带来了数据集建设方面的商机。仅国内而言目前已经涌现出了大大小小至少上百家数据集的供应商,其中比较有名的包括数据堂、MagicData等等。
另外,很多公司还提供定制化的人工服务。比如百度、阿里、Amazon等互联网巨头都推出了众包服务 (ImageNet也是依靠这种方式逐步发展起来的)。如下所示的是alibaba的数据标注服务:
图 ‑ Alibaba众包服务
如果大家有需要的话,建议可以针对感兴趣的几个平台进行实际试用后,再选择适合自己的数据标注服务提供商。
1.2.1.2 自己动手,丰衣足食
在实际项目中,能直接找到完全符合要求的数据集的情况并不多;而且因为涉及机密信息、费用、周期等很多可能的因素,数据标注外包也未必是最优的方式——此时我们可以选择自己动手来建立数据集。
幸运的是,业界也有不少开源的工具来帮助大家提高标注效率,而不是“一切从零开始”。比如labelimg就是在图像标注领域应用很广泛的一款开源小工具,大家可以参考:
https://github.com/tzutalin/labelImg
它的使用也很简单,通常只需要几步操作就可以完成一张图上的多种类别标注。
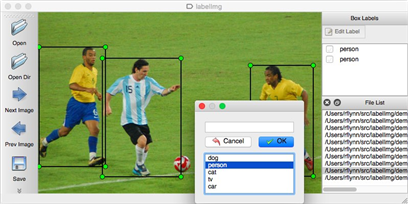
图 ‑ labelimg开源工具
上图所示例子中,我们首先通过拖拽鼠标来框选出原始图片中的目标物体。当鼠标释放后会自动弹出一个类别提示框,此时大家既可以直接选择预置的几种类别(可以配置),也支持输入新的类别。每张图都可以进行多类别的标注,它们最终会被汇总到一个xml格式的文件中,范例如下:
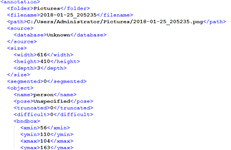
图 ‑ labelimg生成的xml文件格式
用于图像任务的深度神经网络所需的样本规模一般情况下都比较大,所以自建过程也通常不是一朝一夕就可以完成的。另外,如此规模的样本集还可能是由多人协同完成的。这就涉及到样本库的版本管理和人员协作的问题了。
对于版本管理,大家可以考虑采用和代码管理类似的方式来完成。比如常用的SVN、Git系统等等都可以胜任这一工作。在此基础上,我们还需要制定一定的规则来保证大家的标注工作可以有条不紊地开展起来。以笔者所在的项目组为例,多人标注可以选择两种协同方式:
l 流水线的方式
这是使用比较多的一种协同方式。具体而言,就是标注小组的所有人都要处理全部的样本图片,但每个人又都只负责其中的一部分类别(比如person、cat、dog等)。实践证明这种方式不但有助于提高整体标注效率(每个人只需要记住较少的类别,操作相对简单),而且还不容易出错(越简单的事情通常就越不容易出错,特别是当人从早到晚都在重复做一件事情的时候)。缺点也是有的,其中之一就是多人协同就必然存在冲突和需要合并的地方。
l “一人包干”的方式
这种方式也是比较常用的,即每个人都独立完成其中一部分图片的所有类别的标注。优缺点和前述方式基本上是反过来的。对于样本类别不多的场景,大家也可以尝试使用这种不需要解决冲突问题的标注协同手段
1.2.2 数据分布和多样性
1.2.2.1 数据的典型概率分布
由前面章节的学习,我们知道离散型随机变量的概率分布可以参考如下的定义:
如果离散型随机变量R的所有可能值是r1, r2, r3, r4…rn,那么
P{R = rk} = pk (k = 1, 2, … n)
称为随机变量R的概率分布,有时也简称为分布列或者分布律。
另外,离散型随机变量的概率分布有很多种类型,常见的有二项分布、伯努利分布(又名两点分布或0-1分布)、泊松分布等。
为了保持阅读的连贯性,下面我们再复习一下之前学习的内容。
以两点分布为例,如果随机变量的概率分布满足如下条件:
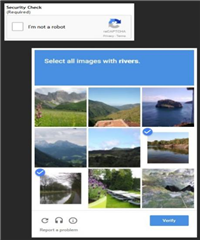
P{R = k} = pkq1-k, k=0, 1 (0 那么我们称之为两点分布。换句话说,这种情况下试验结果只有两种可能性,比如射击是否上靶,天气预报是否下雨等等。 连续型随机变量的情况稍微复杂一些,我们首先需要了解概率密度函数。 它的定义如下: 如果存在某函数f(x),使得随机变量X在任一(a, b)区间的概率可以表示为 P{a 那么这一随机变量X就是连续型的随机变量,且f(x)是它的概率密度函数。显然根据场景的不同,f(x)也有很多种类型,包括但不限于:指数分布、均匀分布、正态分布(Normal distribution)等等。以正太分布(又名高斯分布)为例,它是由德国数学家Moivre在18世纪提出来的,其所对应的概率密度函数为: 其中 1.2.2.2 IID (Independent Identically Distributed) IID,即独立同分布理论最早出现于概率和统计学科,不过它在机器学习、信号处理、数据挖掘等领域中也得到了广泛的应用。 独立同分布简单来讲是指“随机过程中的任何时刻的取值都为随机变量。而如果这些随机变量服从同一分布,并且互相独立,那么它们就服从独立同分布”——IID理论是机器学习可以得到好的学习效果的一个基础保证。 (1) 数据独立性 从概率的角度来说,独立性意味着一个事件A的发生并不依赖于另一事件B,也就是说它们同时发生的概率等于两个事件各自发生的概率之积: P(A x B) = P(A) * P(B) (2) 数据同分布 根据实践经验来看,我们认为“同分布”的概念可以从两个角度来理解: l 样本之间符合同种分布 l 样本具备总体代表性 打个比方来说,假设我们的目标是统计全国人民的身高分布,如果你选取的大部分样本来自于“模特圈”,那么显然得出来的身高分布与真实情况有偏差;同理,如果你只以小学生做为样本,那么也一样会“有失偏颇” 图 ‑ 部分概率分布图示 独立同分布理论上可以降低样本中个例的情况,使得数据尽可能具备多样性,从而有效提升训练出来的算法模型的泛化能力。 1.2.2.3 图像数据的多样性衡量 虽然到目前为止,还没有出现可用于计算图像数据多样性的统一公式,不过业界有一些方法大家倒是可以尝试一下。例如Stanford在构建ImageNet时,就特别关注diversity这个指标。参见《ImageNet: A Large-Scale Hierarchical Image Database》论文中的如下描述: “ImageNet is constructed with the goal that objects in images should have variable appearances, positions, view points, poses as well as background clutter and occlusions.” 而且ImageNet的作者们认为——相比于业界当前各种类别的其它图像数据集,ImageNet的Diversity也是略胜一畴的。 但是如何证明呢? 论文中给出的方法是利用求同一类别下所有图片的平均值,然后再计算结果值大小来衡量。详细描述如下所示: “In an attempt to tackle the difficult problem of quantifying image diversity, we compute the average image of each synset and measure lossless JPG file size which reflects the amount of information in an image. Our idea is that a synset containing diverse images will result in a blurrier average image, the extreme being a gray image, whereas a synset with little diversity will result in a more structured, sharper average image. We therefore expect to see a smaller JPG file size of the average image of a more diverse synset” 最后的实验结果(lossless JPG file sizes of average images)参见下图所示: 图 ‑ ImageNet和其它数据集平台的diversity对比 大家可以结合项目实际情况,判断ImageNet的diversity计算方式是否符合要求。 1.2.2.4 数据采集规划 在开展数据采集工作之前,建议大家先围绕项目的诉求,做一个完整的采集规划。因为实际执行数据采集的人往往不是算法工程师或者开发人员自己,所以清晰准确的采集需求从全局来看可以极大的缩减项目周期。 同时,提前做好采集规划也可以让算法工程师针对问题本身展开全面思考,从这个角度来看也是大有裨益的。 下面是数据采集规划应该注意的几个点,供大家参考: l 需要什么类型的数据(比如图片,文字等等) l 需要多大的数据量(也可以分期迭代进行) l 如何采集,除了人工外是否可以实现自动化,从而提升效率 l 重点思考如何提升数据多样性的问题 等等 1.2.3.1 结合业务特点扩大数据量 结合项目的实际特点,我们有可能在较小的资源投入情况下获得数据集规模的快速增长。例如前面提及到的Facebook在2018上半年改变了通过人工标注图片来产生训练数据的方式,而利用instagram用户上传的带标签图片来产生亿+级的有监督学习数据,助力它的图像识别等算法精度提升到了历史新高度。 Google结合验证码业务来辅助构建带标签数据集,也给我们提供了一个很好的范例。它的验证码服务reCAPTCHA的思路最早是由CMU提出来的——通过在验证码中放置还没有被识别出的古籍扫描件、街景图片等数据,从而让人们在完成验证操作的同时,也顺便为机器学习标注工作贡献了一分力量。 图 ‑ reCAPTCHA验证码服务 这种“一箭双雕”甚至“一箭多雕”的方法,有的时候可以极大的促进我们的数据集建设效率,因而值得大家去思考落地。 1.2.3.2 数据增强 如果样本数量太少,那么很可能得不到好的机器学习效果。除了投入大量人力物力增加数据集外,如果数据本身具有一定特点的话,我们还可以选择“人工制造”出很多样本数据。这种方法在学术上也被称为data augmentation,其中一些常用的手段包括但不限于: l 旋转变换(Rotation) 根据一定算法来旋转图像 l 翻转变换(Flip) 沿着水平或者垂直方向翻转原始图像 l 对比度变换(Contrast) 根据需求和一定算法改变原始图像的对比度 l 亮度变换(Lightness) 根据需求和一定算法改变原始图像的亮度 l 饱和度变换(Saturation) 根据需求和一定算法改变原始图像的饱和度 l 缩放变换(Zoom) 按照一定的比例放大或者缩小图像 l 颜色变换(Color) 根据需要改变原始图像各像素的颜色值 l 噪声扰动(Noise) 对图像的每个像素RGB进行随机扰动, 比如使用常用的高斯噪声模式 l 平移变换(Shift) 根据需要对原始图像进行一定程度的平移 l 随机裁减(Random Crop) 采用随机图像差值算法对原始图像进行裁剪、缩放等操作。包括但不限于Scale Jittering(VGG及ResNet模型使用)或者尺度和长宽比的增强变换 等等 另外,开发者还可以根据项目的实际情况来考虑是否需要将多种增强手段组合起来,从而产生更多有效的样本数据。我们在后续章节中针对data augmentation还会有更多阐述,大家可以结合起来阅读。![]()
![]() 是位置参数,
是位置参数,![]() 为尺度参数。当这两个参数的值分别为0和1时,正态分布也被称为标准的正态分布。
为尺度参数。当这两个参数的值分别为0和1时,正态分布也被称为标准的正态分布。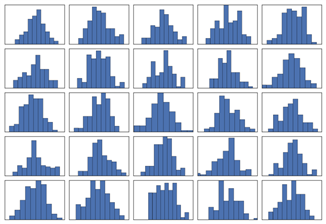

1.2.3 如何扩大数据量
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!