NVIDIA NGC使用记录
文章目录
- [NGC 介绍 参考](https://zhuanlan.zhihu.com/p/41153237)
- CUDA的deviceQuery命令
- triton-inference-server 启动记录
- 确定安装的容器版本
- 创建模型仓库
- 运行client 示例
- 模型仓库
- NGC 命令使用
- Riva 使用记录
NGC 介绍 参考
1,登陆(需要翻墙)
2,安装 NGC CLI


根据平台选择相应的下载,我是AMD64 先择执行下面的命令(关闭翻墙下载更快)
wget -O ngccli_cat_linux.zip https://ngc.nvidia.com/downloads/ngccli_cat_linux.zip && unzip -o ngccli_cat_linux.zip && chmod u+x ngc
md5sum -c ngc.md5
echo "export PATH=\"\$PATH:$(pwd)\"" >> ~/.bash_profile && source ~/.bash_profile
接下来需要获取AIPKEY
回到上面图片的页面


获取到KEY之后
继续执行
ngc config set
依次输入

docker login nvcr.io
Username: $oauthtoken
Password: <Your Key>
看到success 就成功了

CUDA的deviceQuery命令
yum install -y redhat-lsb
查看系统版本
lsb_release -a

cuda 安装路径 cd /usr/local/cuda-11.2
在这个目录下 cp -r ./samples/ /home/xxxx/
cd /home/xxxx/samples
make
make成功之后会得到一个bin文件,cd到bin路径下,可以看到好多可执行文件,其中就包括我们要使用的deviceQuery,执行./deviceQuery便可以看到你服务器上所有的GPU信息啦
cd bin/
cd x86_64/linux/release/
cp deviceQuery /usr/local/bin/
然后就可以直接在命令行使用deviceQuery 命令了
triton-inference-server 启动记录
确定安装的容器版本
根据support-matrix确定容器版本
我的系统确定的是21.02
使用GPU 推理必须安装NVIDIA Container Toolkit.
docker pull nvcr.io/nvidia/tritonserver:21.02-py3
docker pull nvcr.io/nvidia/tritonserver:21.02-py3-sdk创建模型仓库
git clone https://github.com/triton-inference-server/server.git
cd server/docs/examples
./fetch_models.sh
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/home/xxx/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:21.02-py3 tritonserver --model-repository=/models
输出如下:

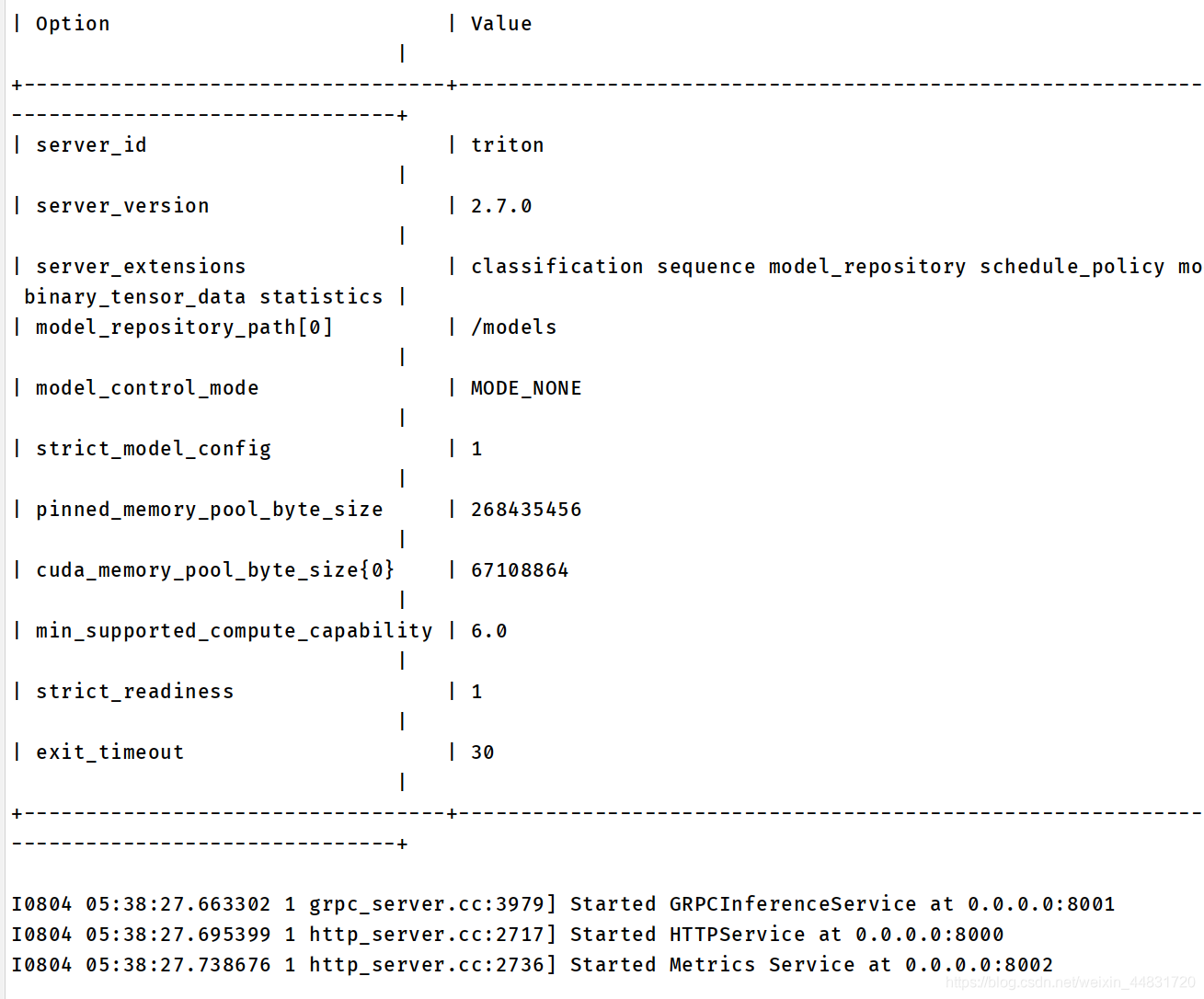
如果只用cpu,就去掉 --gpu
验证triton 是否正确运行
curl -v localhost:8000/v2/health/ready
正常输出如下
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
运行client 示例
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:21.02-py3-sdk
会进入容器,输入下面的命令
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
输出
Request 0, batch size 1
Image '/workspace/images/mug.jpg':15.346230 (504) = COFFEE MUG13.224326 (968) = CUP10.422965 (505) = COFFEEPOT
模型仓库
tritonserver启动的时候通过--model-repository指定模型仓库的路径
模型仓库的文件夹结构如下
model_repository/
├── densenet_onnx # 模型名称
│ ├── 1 # 版本
│ │ └── model.onnx #模型文件
│ ├── config.pbtxt #配置文件
│ └── densenet_labels.txt # 标签
└── simple_string├── 1│ └── model.graphdef└── config.pbtxt
config.pbtxt 是模型的配置文件,根据模型可选 ,更多时候可以triton自动生成
config.pbtxt 必须包含如下内容:
1,platform
1,For TensorRT, ‘platform’ must be set to tensorrt_plan. Currently, TensorRT backend does not support ‘backend’ field
2, For PyTorch, ‘backend’ must be set to pytorch or ‘platform’ must be set to pytorch_libtorch
3,For ONNX, ‘backend’ must be set to onnxruntime or ‘platform’ must be set to onnxruntime_onnx
4,For TensorFlow, 'platform must be set to tensorflow_graphdef or tensorflow_savedmodel. Optionally ‘backend’ can be set to tensorflow
2,name
可选,不设置会自动以文件夹名为文件名
3,max_batch_size
NGC 命令使用
https://docs.ngc.nvidia.com/cli/cmd.html
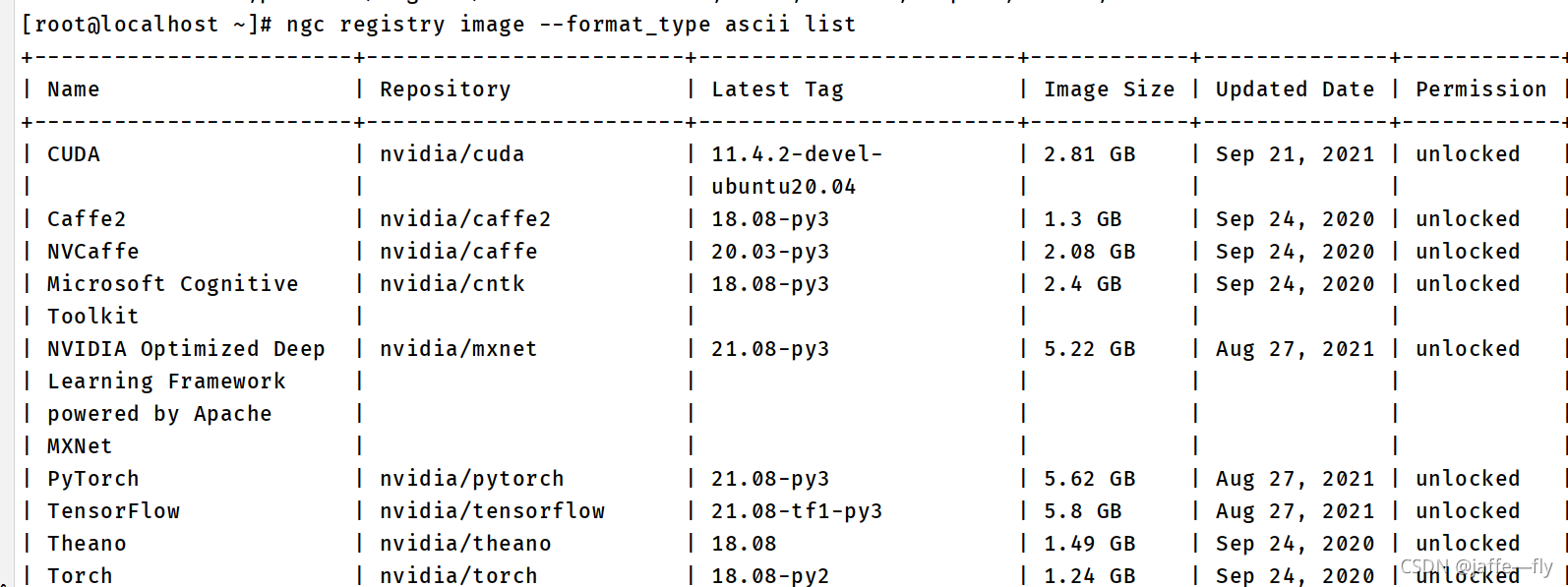
1,查看镜像列表(–format_type 可选: ascii, csv, json)
ngc registry image --format_type ascii list
2,查看某一镜像tag的详细信息
ngc registry image --format_type json info nvidia/pytorch
3,下载NGC镜像
ngc registry image pull [镜像路径]:[镜像tag]
4,下载安装包
ngc registry resource download-version "nvidia/riva/riva_quickstart:1.5.0-beta"
Riva 使用记录
介绍
文档
1,安装
ngc registry resource download-version "nvidia/riva/riva_quickstart:1.5.0-beta"
cd riva_quickstart_v1.5.0-beta
修改 config.sh 中要下载的模型,例如 ,我是用ASR模型
service_enabled_nlp=false
service_enabled_tts=false
模型下载到docker volume的位置
查看docker volume的位置
cat /etc/docker/daemon.json

之后
bash riva_init.sh
bash riva_start.sh
使用
启动一个示例client,查看notebook
bash riva_start_client.sh
jupyter notebook --ip=0.0.0.0 --allow-root --notebook-dir=/work/notebooks
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!