Spark的SQL操作详解
DataFrame操作(untyped)
printSchema()
object DataframeOperationTest {def main(args: Array[String]): Unit = {val sparkSql = SparkSession.builder().appName("df operation").master("local[*]").getOrCreate()import sparkSql.implicits._val rdd = sparkSql.sparkContext.makeRDD(List((1,"zs",1000.0,true),(2,"ls",2000.0,false),(3,"ww",3000.0,false)))val df = rdd.toDF("id","name","salary","sex")// 打印df的结构df.printSchema()sparkSql.stop()}
}//-----------------------------------------------------------------------------
root|-- id: integer (nullable = false)|-- name: string (nullable = true)|-- salary: double (nullable = false)|-- sex: boolean (nullable = false)
show()
// 默认输出df中前20行数据
df.show()
//-----------------------------------------------------------------------------
+---+----+------+-----+
| id|name|salary| sex|
+---+----+------+-----+
| 1| zs|1000.0| true|
| 2| ls|2000.0|false|
| 3| ww|3000.0|false|
+---+----+------+-----+
Select()
// 查询指定的字段
// df.select("id","name","sex").show()
// $是另外一种写法[隐式转换] 字符串列名==>Column对象
df.select($"id",$"name",$"sex").show()
//-----------------------------------------------------------------------------
+---+----+-----+
| id|name| sex|
+---+----+-----+
| 1| zs| true|
| 2| ls|false|
| 3| ww|false|
+---+----+-----+
SelectExpr()
// 查询指定字段【表达式】
// df.selectExpr("name as username").show()
// df.selectExpr("sum(salary)").show()
df.selectExpr("id","name as username","salary","salary*12").show()//-----------------------------------------------------------------------------
+---+--------+------+-------------+
| id|username|salary|(salary * 12)|
+---+--------+------+-------------+
| 1| zs|1000.0| 12000.0|
| 2| ls|2000.0| 24000.0|
| 3| ww|3000.0| 36000.0|
+---+--------+------+-------------+
withColumn()
// 添加或者替换【列名相同】字段
df.select($"id",$"name",$"salary")// .withColumn("year_salary",$"salary"*12) // 添加列.withColumn("salary",$"salary"*12) // 替换已存在的列.show()//-----------------------------------------------------------------------------
+---+----+-------+
| id|name| salary|
+---+----+-------+
| 1| zs|12000.0|
| 2| ls|24000.0|
| 3| ww|36000.0|
+---+----+-------+
withColumnRenamed()
df.select($"id", $"name", $"salary")// .withColumn("year_salary",$"salary"*12) // 添加列.withColumn("salary", $"salary" * 12) // 替换已存在的列.withColumnRenamed("name","username").withColumnRenamed("id","user_id").show()//-----------------------------------------------------------------------------
+-------+--------+-------+
|user_id|username| salary|
+-------+--------+-------+
| 1| zs|12000.0|
| 2| ls|24000.0|
| 3| ww|36000.0|
+-------+--------+-------+
Drop()
df.select($"id", $"name", $"salary")// .withColumn("year_salary",$"salary"*12) // 添加列.withColumn("salary", $"salary" * 12) // 替换已存在的列.withColumnRenamed("name", "username").withColumnRenamed("id", "user_id").drop($"username").show()
//-----------------------------------------------------------------------------+-------+-------+
|user_id| salary|
+-------+-------+
| 1|12000.0|
| 2|24000.0|
| 3|36000.0|
+-------+-------+
DropDuplicates()
// 删除重复数据 DropDuplicates 类似于数据库中distinct【重复数据只保留一个】
val df2 = sparkSql.sparkContext.makeRDD(List((1, "zs", 1000.0, true), (2, "ls", 2000.0, false), (3, "ww", 2000.0, false),(4, "zl", 2000.0, false))).toDF("id","name","salary","sex")
df2.select($"id", $"name", $"salary",$"sex")
// .withColumn("year_salary",$"salary"*12) // 添加列.withColumn("salary", $"salary" * 12) // 替换已存在的列.withColumnRenamed("name", "username").withColumnRenamed("id", "user_id").dropDuplicates("salary","sex").show()//-----------------------------------------------------------------------------
+-------+--------+-------+-----+
|user_id|username| salary| sex|
+-------+--------+-------+-----+
| 2| ls|24000.0|false|
| 1| zs|12000.0| true|
+-------+--------+-------+-----+
OrderBy()| Sort()
// 排序OrderBy()| Sort()
df.select($"id", $"name", $"salary", $"sex")//.orderBy($"salary" desc)//.orderBy($"salary" asc)//.orderBy($"salary" asc,$"id" asc).sort($"salary" desc) // 等价于OrderBy.show()//-----------------------------------------------------------------------------
+---+----+------+-----+
| id|name|salary| sex|
+---+----+------+-----+
| 3| ww|3000.0|false|
| 2| ls|2000.0|false|
| 1| zs|1000.0| true|
+---+----+------+-----+
GroupBy ()
// 分组groupBy()
df.groupBy($"sex").sum("salary").show()
//-----------------------------------------------------------------------------
+-----+-----------+
| sex|sum(salary)|
+-----+-----------+
| true| 1000.0|
|false| 5000.0|
+-----+-----------+
Agg()
// agg 聚合操作
var df3 = List((1, "zs", true, 1, 15000),(2, "ls", false, 2, 18000),(3, "ww", false, 2, 14000),(4, "zl", false, 1, 18000),(4, "zl", false, 1, 16000))
.toDF("id", "name", "sex", "dept", "salary")
import org.apache.spark.sql.functions._
df3.groupBy("sex")// .agg(max("salary"), min("salary"), avg("salary"), sum("salary"), count("salary")).agg(Map(("salary", "max"))) // 另外的一种写法【局限性 只支持单个字段的聚合查询】.show()
//-----------------------------------------------------------------------------
+-----+-------------+
| sex|count(salary)|
+-----+-------------+
| true| 1|
|false| 4|
+-----+-------------+
Limit()
// limit 限制返回的结果条数
df.limit(2).show()
//-----------------------------------------------------------------------------
+---+----+------+-----+
| id|name|salary| sex|
+---+----+------+-----+
| 1| zs|1000.0| true|
| 2| ls|2000.0|false|
+---+----+------+-----+
Where()
val df4=List((1,"zs",true,1,15000),(2,"ls",false,2,18000),(3,"ww",false,2,14000),(4,"zl",false,1,18000),(5,"win7",false,1,16000)).toDF("id","name","sex","dept","salary")df4.select($"id",$"name",$"sex",$"dept",$"salary")//where("(name like '%s%' and salary > 15000) or name = 'win7'").where(($"name" like "%s%" and $"salary" > 15000) or $"name" ==="win7" ).show()
//--------------------------------------------------------------------------------------
+---+----+-----+----+------+
| id|name| sex|dept|salary|
+---+----+-----+----+------+
| 2| ls|false| 2| 18000|
| 5|win7|false| 1| 16000|
+---+----+-----+----+------+
Pivot() 【透视】
var scoreDF=List((1,"math",85),(1,"chinese",80),(1,"english",90), (2,"math",90), (2,"chinese",80)).toDF("id","course","score")scoreDF.groupBy($"id").pivot($"course") // 行转列【重点】.max("score").show()//--------------------------------------------------------------------------------------
+---+-------+-------+----+
| id|chinese|english|math|
+---+-------+-------+----+
| 1| 80| 90| 85|
| 2| 80| null| 90|
+---+-------+-------+----+
na()
对空值的一种处理方式
na().fill 填充 null赋予默认值
na().drop 删除为null的一行内容
scoreDF.groupBy($"id").pivot($"course") // 行转列【重点】.max("score")//.na.fill(Map("english" -> 59)) // 为空值赋予一个默认值.na.drop() // 删除包含空值的一行记录.show()
//--------------------------------------------------------------------------------------
+---+-------+-------+----+
| id|chinese|english|math|
+---+-------+-------+----+
| 1| 80| 90| 85|
+---+-------+-------+----+
over()
窗口函数:
- 聚合函数
- 排名函数
- 分析函数
作用: 窗口函数使用over,对一组数据进行操作,返回普通列和聚合列
val w1 = Window
.partitionBy(“分区规则”)
.orderBy($“列” asc| desc)
.rangeBetween | rowsBetween
窗口函数名 over(w1)
t_userid name salary sex dept1 zs 1000 true 12 ls 2000 false 23 ww 2000 false 1// 查询用户信息(id,name,salary,用户所在部门的平均工资)SQL: select id,name,salary,(select avg(salary) from t_user group by dept) as avg_salary from t_userid name salaray avg_salary1 zs 1000 15002 ls 2000 20003 ww 2000 1500spark sql 窗口函数 简化如上查询语义: select id,name,salary,avg(salary) over(partition by dept order by ...) from t_user具体使用方法:
count(...) over(partition by ... order by ...) --求分组后的总数。
sum(...) over(partition by ... order by ...) --求分组后的和。
max(...) over(partition by ... order by ...)--求分组后的最大值。
min(...) over(partition by ... order by ...)--求分组后的最小值。
avg(...) over(partition by ... order by ...)--求分组后的平均值。
rank() over(partition by ... order by ...)--rank值可能是不连续的。
dense_rank() over(partition by ... order by ...)--rank值是连续的。
first_value(...) over(partition by ... order by ...)--求分组内的第一个值。
last_value(...) over(partition by ... order by ...)--求分组内的最后一个值。
lag() over(partition by ... order by ...)--取出前n行数据。
lead() over(partition by ... order by ...)--取出后n行数据。
ratio_to_report() over(partition by ... order by ...)--Ratio_to_report() 括号中就是分子,over() 括号中就是分母。
percent_rank() over(partition by ... order by ...)
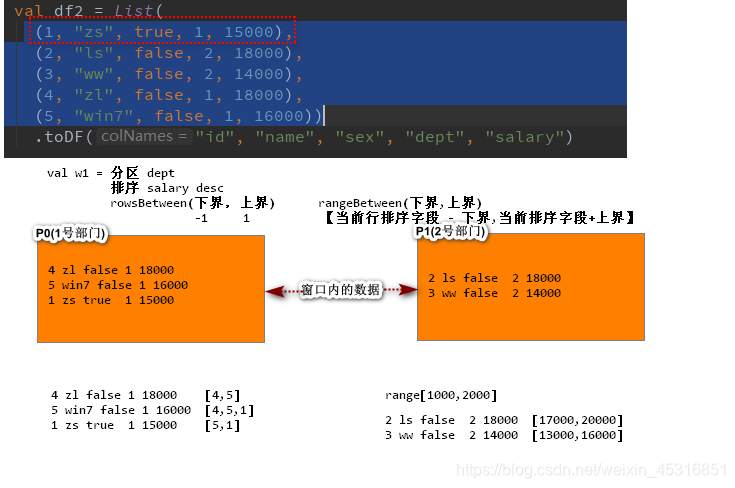
//------------------------------------------------------------
val df2 = List((1, "zs", true, 1, 15000),(2, "ls", false, 2, 18000),(3, "ww", false, 2, 14000),(4, "zl", false, 1, 18000),(5, "win7", false, 1, 16000))
.toDF("id", "name", "sex", "dept", "salary")// 定义窗口函数
val w1 = Window
.partitionBy($"dept") // 根据部门dept进行分区: 部门相同的数据划分到同一个分区.orderBy($"salary" asc) // 对分区内的数据 按照工资salary进行降序排列// .rangeBetween(0, 2000) // 窗口数据可视范围 【基于数据范围】// .rowsBetween(0, 1) // 窗口数据可视范围.rowsBetween(Window.unboundedPreceding,Window.unboundedFollowing) // 窗口数据可视范围【基于行 使用行的偏移量】import org.apache.spark.sql.functions._ // 导入隐式转换函数df2.select($"id", $"name", $"sex", $"dept", $"salary")
.withColumn("sum_id", sum("id") over (w1))
.show()
Join()
val userInfoDF= sparkSql.sparkContext.makeRDD(List((1,"zs"),(2,"ls"),(3,"ww"))).toDF("id","name")
val orderInfoDF= sparkSql.sparkContext.makeRDD(List((1,"iphone",1000,1),(2,"mi9",999,1),(3,"连衣裙",99,2))).toDF("oid","product","price","uid")// join DF连接操作
userInfoDF.join(orderInfoDF,$"id"===$"uid","inner").show()
//-----------------------------------------------------------------
+---+----+---+-------+-----+---+
| id|name|oid|product|price|uid|
+---+----+---+-------+-----+---+
| 1| zs| 1| iphone| 1000| 1|
| 1| zs| 2| mi9| 999| 1|
| 2| ls| 3| 连衣裙| 99| 2|
+---+----+---+-------+-----+---+
cube(多维度)
cube多维度查询 尝试根据多个分组可能继续数据查询
cube(A,B)
group by A null
group by null B
group by null null
group by AB
import org.apache.spark.sql.functions._
List((110,50,80,80),(120,60,95,75),(120,50,96,70))
.toDF("height","weight","IQ","EQ")
.cube($"height",$"weight") // spark sql尝试根据元组第一个和第二个值 进行各种可能分组操作,这种操作的好处,如果以后有任何第一个和第二个值的分区操作,都将出现在cube的结果表中
.agg(avg("IQ"),avg("EQ")) .show()
DataSet操作(typed)
在实际开发中,我们通常使用的是DataFrame API,这种Dataset强类型的操作几乎不使用
package com.baizhi.sql.operation.typedimport org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.scalalang.typed/*** ds 强类型操作** spark context :rdd* spark streaming context : streaming* spark session : sql*/
object DatasetWithTypedOpt {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("typed opt").getOrCreate()spark.sparkContext.setLogLevel("ERROR")import spark.implicits._val ds = spark.sparkContext.makeRDD(List("Hello Hadoop", "Hello Scala")).flatMap(_.split(" ")).map((_, 1)).toDSds.groupByKey(t => t._1) // 根据单词进行分组操作.agg(typed.sum[(String, Int)](t => t._2)) // 对单词初始值进行聚合.withColumnRenamed("TypedSumDouble(scala.Tuple2)", "num").show()spark.stop()}
}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!